Comprendre les performances
Cette page décrit les performances approximatives que Bigtable peut atteindre dans des conditions optimales, les facteurs susceptibles d'affecter ces performances ainsi que des conseils pour les tests et la résolution des problèmes associés.
Performances pour des charges de travail types
Bigtable offre des performances hautement prévisibles, à l'évolutivité linéaire. Si vous évitez les causes de ralentissement décrites ci-dessous, chaque nœud Bigtable peut offrir le débit approximatif ci-après, suivant le type de stockage utilisé par le cluster :
| Type de stockage | Lecture | Écriture | Analyses | ||
|---|---|---|---|---|---|
| SSD | jusqu'à 17 000 lignes par seconde | ou | jusqu'à 14 000 lignes par seconde | ou | jusqu'à 220 Mo/s |
| HDD | jusqu'à 500 lignes par seconde | ou | jusqu'à 10 000 lignes par seconde | ou | jusqu'à 180 Mo/s |
Ces estimations supposent que chaque ligne contient 1 Ko de données.
En général, les performances d'un cluster évoluent linéairement au fur et à mesure de l'ajout de nœuds au cluster. Par exemple, si vous créez un cluster SSD avec 10 nœuds, le cluster peut accepter jusqu'à 140 000 lignes par seconde pour une charge de travail type de lecture seule ou d'écriture seule.
Planifier la capacité Bigtable
Lorsque vous planifiez vos clusters Bigtable, décidez si vous souhaitez optimiser pour la latence ou le débit. Par exemple, pour une tâche de traitement de données par lot, vous pouvez vous soucier davantage du débit que de la latence. À l'inverse, pour un service en ligne qui traite les requêtes des utilisateurs, vous devrez peut-être donner la priorité à une latence plus faible. Vous pouvez atteindre les chiffres de la section Performances pour des charges de travail classiques lorsque vous optimisez pour le débit.
Utilisation du processeur
Dans presque tous les cas, nous vous recommandons d'utiliser l'autoscaling, qui permet à Bigtable d'ajouter ou de supprimer des nœuds en fonction de votre utilisation. Pour en savoir plus, consultez la section Autoscaling.
Suivez les instructions suivantes lorsque vous configurez vos cibles d'autoscaling ou si vous choisissez d'allouer manuellement des nœuds. Ces consignes s'appliquent quel que soit le nombre de clusters de votre instance. Pour un cluster avec allocation manuelle des nœuds, vous devez surveiller l'utilisation du processeur du cluster afin de maintenir l'utilisation du processeur en dessous de ces valeurs pour des performances optimales.
| Objectif d'optimisation | Utilisation maximale du processeur |
|---|---|
| Débit | 90 % |
| Latence | 60 % |
Pour en savoir plus sur la surveillance, consultez la section Surveillance.
Utilisation du stockage
Le stockage est une autre considération à prendre en compte lors de la planification des capacités. La capacité de stockage d'un cluster est déterminée par le type de stockage et le nombre de nœuds dans le cluster. Lorsque la quantité de données stockées dans un cluster augmente, Bigtable optimise le stockage en répartissant la quantité de données sur tous les nœuds du cluster.
Vous pouvez déterminer l'utilisation du stockage par nœud en divisant l'utilisation du stockage (octets) du cluster par le nombre de nœuds qu'il comporte. Prenons l'exemple d'un cluster comportant trois nœuds HDD et 9 To de données. Chaque nœud stocke environ 3 To, ce qui correspond à 18,75 % de la limite de stockage HDD par nœud, c'est-à-dire 16 To.
Lorsque l'utilisation du stockage augmente, les charges de travail peuvent rencontrer une latence accrue dans le traitement des requêtes, même si le cluster dispose de suffisamment de nœuds pour répondre aux besoins généraux en termes de processeur. En effet, plus l'espace de stockage par nœud est élevé, plus cela nécessite de travail en arrière-plan, par exemple pour l'indexation. L'augmentation du travail d'arrière-plan nécessaire pour gérer un espace de stockage important peut entraîner une latence plus élevée et un débit inférieur.
Commencez par les éléments suivants lorsque vous configurez vos paramètres d'autoscaling. Si vous choisissez l'allocation manuelle des nœuds, surveillez l'utilisation de l'espace de stockage du cluster et ajoutez ou supprimez des nœuds pour maintenir les éléments suivants.
| Objectif d'optimisation | Utilisation maximale de l'espace de stockage |
|---|---|
| Débit | 70 % |
| Latence | 60 % |
Pour en savoir plus, consultez la section Stockage par nœud.
Exécuter vos charges de travail types sur Bigtable
Exécutez toujours vos propres charges de travail types sur un cluster Bigtable lorsque vous planifiez la capacité afin de déterminer la meilleure allocation de ressources pour vos applications.
L'outil PerfKit Benchmarker de Google utilise YCSB pour évaluer les services cloud. Vous pouvez suivre le tutoriel de PerfKitBenchmarker pour Bigtable afin de créer des tests pour vos propres charges de travail. Vous devez alors régler les paramètres des fichiers de configuration d'analyse comparative yaml pour vous assurer que le benchmark généré reflète les caractéristiques suivantes au sein de votre production :
- Taille totale de votre table. La taille peut être proportionnelle, mais vous devez utiliser au moins 100 Go.
- Forme des données de ligne (taille des clés de ligne, nombre de colonnes, tailles des données de ligne, etc.)
- Modèle d'accès aux données (distribution des clés de ligne)
- Combinaison de lectures et écritures
Pour en savoir plus sur les bonnes pratiques, consultez la page Tester les performances avec Bigtable.
Causes de ralentissement des performances
Plusieurs facteurs peuvent ralentir les performances de Bigtable par rapport aux estimations ci-dessus :
- Vous lisez un grand nombre de clés de lignes ou de plages de lignes non contiguës dans une seule requête de lecture. Bigtable analyse la table et lit les lignes demandées de manière séquentielle. Ce manque de parallélisme affecte la latence globale, et toutes les lectures qui atteignent un nœud à chaud peuvent augmenter la latence de queue. Pour en savoir plus, consultez la section Lectures et performances.
- Le schéma de la table n'est pas conçu correctement. Pour obtenir de bonnes performances de Bigtable, il est essentiel de concevoir un schéma permettant de répartir les lectures et les écritures de manière uniforme sur chaque table. De plus, les hotspots d'une table peuvent affecter les performances des autres tables de la même instance. Pour en savoir plus, consultez les bonnes pratiques de conception de schémas.
- Les lignes de votre table Bigtable contiennent de grandes quantités de données. Les estimations de performances présentées ci-dessus supposent que chaque ligne contient 1 Ko de données. Vous pouvez lire et écrire de plus grandes quantités de données par ligne, mais augmenter le nombre de données par ligne réduira également le nombre de lignes par seconde.
- Les lignes de votre table Bigtable contiennent un très grand nombre de cellules. Bigtable prend du temps pour traiter chaque cellule d'une ligne. En outre, chaque cellule accroît la quantité de données stockées dans la table et envoyées sur le réseau. Par exemple, si vous stockez 1 Ko (1 024 octets) de données, il est beaucoup plus économe en espace de stocker ces données dans une seule cellule plutôt que de répartir les données sur 1 024 cellules contenant chacune 1 octet. Si vous répartissez vos données sur plus de cellules que nécessaire, vous risquez de ne pas obtenir les meilleures performances possibles. Si les lignes contiennent un grand nombre de cellules car les colonnes contiennent plusieurs versions horodatées des données, envisagez de ne conserver que la valeur la plus récente. Pour une table qui existe déjà, une autre option consiste à envoyer une suppression pour toutes les versions précédentes à chaque réécriture.
Le cluster ne comporte pas assez de nœuds. Les nœuds d'un cluster fournissent des ressources de calcul permettant au cluster de gérer les lectures et les écritures entrantes, le suivi de l'espace de stockage, et les tâches de maintenance telles que le compactage. Vous devez vous assurer que votre cluster dispose de suffisamment de nœuds pour satisfaire aux limites recommandées en termes de calcul et de stockage. Utilisez les outils de surveillance pour vérifier si le cluster est surchargé.
- Calcul : si le processeur de votre cluster Bigtable est surchargé, l'ajout de nœuds peut améliorer les performances en répartissant la charge de travail sur davantage de nœuds.
- Stockage : si l'utilisation du stockage par nœud dépasse la valeur recommandée, vous devez ajouter des nœuds supplémentaires pour maintenir une latence et un débit optimaux, même si le cluster dispose de suffisamment de ressources processeur pour traiter les requêtes. En effet, l'augmentation de l'espace de stockage par nœud requiert davantage de travail de maintenance en arrière-plan par nœud. Pour en savoir plus, consultez la section Compromis entre utilisation du stockage et performances.
Le cluster Bigtable a été récemment étendu ou réduit. Une fois que vous avez augmenté le nombre de nœuds d'un cluster, un délai allant jusqu'à 20 minutes peut être noté avant que vous constatiez une amélioration significative des performances du cluster. Bigtable fait évoluer les nœuds d'un cluster en fonction de la charge qu'il subit.
Lorsque vous réduisez le nombre de nœuds d'un cluster, ne réduisez pas la taille du cluster de plus de 10% sur une période de 10 minutes afin de minimiser les pics de latence.
Le cluster Bigtable utilise des disques durs. Dans la plupart des cas, votre cluster doit utiliser des disques SSD, dont les performances sont nettement meilleures que celles des disques durs. Pour plus de détails, consultez la page Choisir entre le stockage SSD et HDD.
La connexion réseau rencontre des problèmes. Des problèmes de réseau peuvent réduire le débit et accroître la durée des lectures et des écritures. Vous pouvez notamment rencontrer des problèmes si les clients ne s'exécutent pas dans la même zone que le cluster Bigtable ou s'ils s'exécutent en dehors de Google Cloud.
Vous utilisez la réplication, mais votre application utilise une bibliothèque cliente obsolète. Si vous constatez une latence accrue après avoir activé la réplication, assurez-vous que la bibliothèque cliente Cloud Bigtable utilisée par votre application est à jour. Les anciennes versions des bibliothèques clientes peuvent ne pas être optimisées pour assurer la réplication. Consultez la page Bibliothèques clientes Cloud Bigtable pour trouver le dépôt GitHub de votre bibliothèque cliente, dans lequel vous pouvez vérifier la version et la mettre à niveau si nécessaire.
Vous avez activé la réplication, mais vous n'avez pas ajouté de nœuds à vos clusters. Dans une instance qui utilise la réplication, chaque cluster doit gérer le travail de réplication en plus de la charge qu'il reçoit des applications. Des clusters sous-provisionnés peuvent entraîner une latence accrue. Vous pouvez le vérifier en consultant les graphiques d'utilisation du processeur de l'instance dans la console Google Cloud .
Étant donné que différentes charges de travail peuvent entraîner une variation des performances, vous devez effectuer des tests avec vos propres charges de travail pour obtenir les repères les plus précis.
Démarrages à froid et faible nombre de requêtes par seconde
Les démarrages à froid et les faibles RPS peuvent augmenter la latence. Bigtable fonctionne mieux avec les tables volumineuses fréquemment consultées. Par conséquent, si vous commencez à envoyer des requêtes après une période d'inactivité (démarrage à froid), vous constaterez peut-être une latence élevée pendant que Bigtable rétablit les connexions. La latence est également plus élevée lorsque le nombre de requêtes par seconde est faible.
Si votre QPS est faible ou si vous savez que vous allez parfois envoyer des requêtes à une table Bigtable après une période d'inactivité, vous pouvez essayer les stratégies suivantes pour garder votre connexion à chaud et éviter cette latence élevée.
- Envoyez un faible trafic artificiel à tout moment sur la table.
- Configurez le pool de connexions pour vous assurer que le nombre de RPS stables reste actif.
Lors des périodes de faible nombre de requêtes par seconde, le nombre d'erreurs renvoyées par Bigtable est plus pertinent que le pourcentage d'opérations renvoyant une erreur.
Démarrage à froid au moment de l'initialisation du client. Si vous utilisez une version antérieure à la version 2.18.0 du client Cloud Bigtable pour Java, vous pouvez activer l'actualisation des canaux. Dans les versions ultérieures, l'actualisation des chaînes est activée par défaut. L'actualisation des canaux a deux effets:
- Lorsque le client est initialisé, il prépare le canal avant d'envoyer les premières requêtes.
- Le serveur déconnecte les connexions de longue durée toutes les heures. L'amorçage de canal remplace de manière préventive les chaînes qui expirent.
Toutefois, cela ne permet pas de maintenir la chaîne active en cas de périodes d'inactivité.
Comment Bigtable optimise vos données au fil du temps
Pour stocker les données sous-jacentes de chacune de vos tables, Bigtable les partage en plusieurs tablets, qui peuvent être déplacés entre les nœuds du cluster Bigtable. Cette méthode de stockage permet à Bigtable d'appliquer deux stratégies différentes pour optimiser les données au fil du temps :
- Bigtable tente de stocker à peu près la même quantité de données sur chaque nœud.
- Bigtable tente de répartir équitablement les lectures et les écritures sur tous les nœuds.
Parfois, ces stratégies sont en conflit. Par exemple, si les lignes d'un tablet sont lues très fréquemment, Bigtable peut stocker ce tablet sur son propre nœud, même si de ce fait, certains nœuds stockent plus de données que d'autres.
Dans le cadre de ce processus, Bigtable peut également fractionner un tablet en au moins deux tablets plus petits, pour réduire la taille de tablet ou pour isoler les lignes actives dans un tablet existant.
Les sections suivantes expliquent chacune de ces stratégies plus en détail.
Répartir la quantité de données entre les nœuds
Lorsque vous écrivez des données sur une table Bigtable, Bigtable segmente les données de la table en tablets. Chaque tablet contient une plage contiguë de lignes de la table.
Si vous avez écrit moins de plusieurs Go de données dans la table, Bigtable stocke tous les tablets sur un seul nœud de votre cluster:
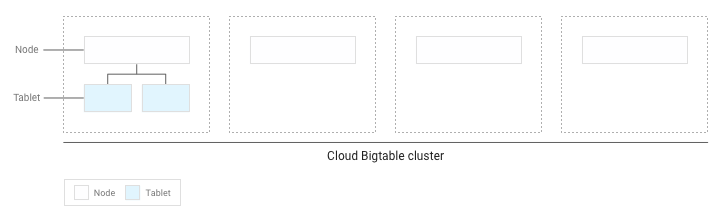
Au fur et à mesure que les tablets s'accumulent, Bigtable en déplace certains vers d'autres nœuds du cluster afin que la quantité de données soit répartie plus équitablement sur le cluster:
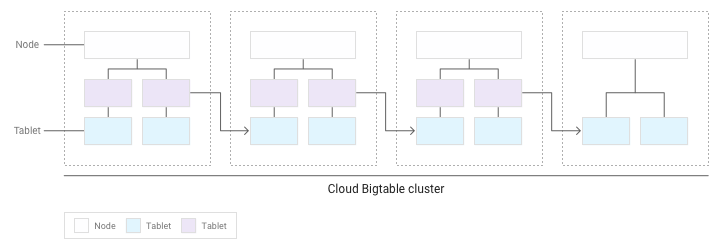
Répartir uniformément les lectures et les écritures entre les nœuds
Si vous avez conçu votre schéma correctement, les lectures et les écritures doivent être réparties de manière assez uniforme sur l'ensemble de la table. Cependant, dans certains cas, vous ne pouvez pas éviter d'accéder à certaines lignes plus souvent que d'autres. Bigtable vous aide à gérer ces cas en prenant en compte les lectures et les écritures lorsqu'il équilibre les tablets entre les nœuds.
Par exemple, supposons que 25 % des lectures se rapportent à un petit nombre de tablets dans un cluster, et que les lectures sont réparties uniformément sur tous les autres tablets :
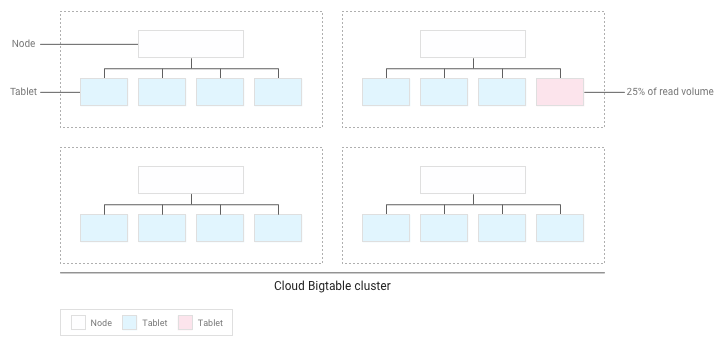
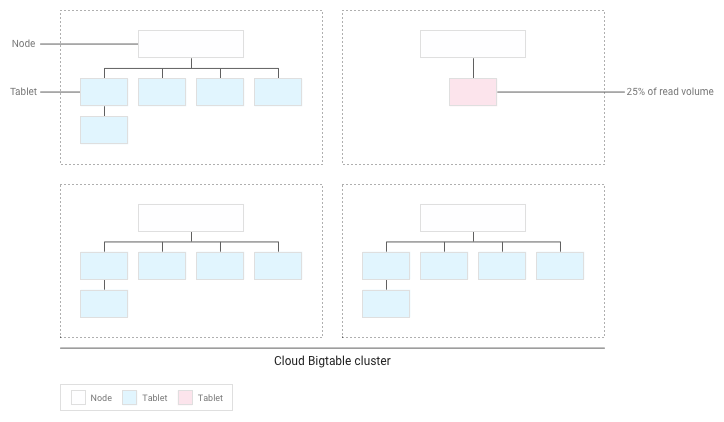
Bigtable redistribue les tablets existants afin que les lectures soient réparties aussi uniformément que possible sur l'ensemble du cluster :
Tester les performances avec Bigtable
Si vous exécutez un test de performances pour une application qui dépend de Bigtable, suivez ces instructions lorsque vous planifiez et exécutez votre test :
- Ayez un volume de données suffisant pour le test.
- Si le volume total de données dans les tables de votre instance de production est de 100 Go ou moins par nœud, effectuez votre test avec une table hébergeant un volume de données comparable.
- Si les tables contiennent plus de 100 Go de données par nœud, effectuez votre test avec une table contenant au moins 100 Go de données par nœud. Par exemple, si votre instance de production présente un cluster à quatre nœuds et que les tables de l'instance contiennent au total 1 To de données, utilisez une table d'au moins 400 Go dans le cadre de votre test.
- Utilisez une table unique pour le test.
- Restez en dessous de l'utilisation de stockage recommandée par nœud. Pour plus d'informations, consultez la page Utilisation du stockage par nœud.
- Avant le test, effectuez un prétest intensif pendant plusieurs minutes. Cette étape permet à Bigtable d'équilibrer les données entre les nœuds en fonction des modèles d'accès observés.
- Exécutez le test pendant au moins 10 minutes. Cette étape permet à Bigtable d'optimiser davantage les données, et de vous assurer que le test porte à la fois sur les lectures du disque et sur les lectures mises en cache à partir de la mémoire.
Résoudre les problèmes liés aux performances
Si vous pensez que Bigtable est susceptible de brider les performances de votre application, appliquez tous les conseils suivants :
- Examinez les analyses Key Visualizer pour votre table. L'outil Key Visualizer pour Bigtable génère de nouvelles données d'analyse toutes les 15 minutes et affiche les modèles d'utilisation de chaque table d'un cluster. Key Visualizer permet de vérifier si vos tendances d'utilisation génèrent des résultats indésirables, tels que du hotspotting sur des lignes spécifiques ou une utilisation excessive du processeur. Lisez la présentation Premiers pas avec Key Visualizer.
- Essayez d'insérer des marques de commentaire sur le code qui effectue les lectures et les écritures Bigtable. Si le problème de performances disparaît, vous utilisez probablement Bigtable d'une manière qui entraîne des performances réduites. Si le problème de performances persiste, il n'est probablement pas lié à Bigtable.
Créez le moins de clients possible. La création d'un client pour Bigtable est une opération relativement coûteuse. Par conséquent, vous devez créer le plus petit nombre possible de clients :
- Si vous avez recours à la réplication ou à des profils d'application pour identifier les différents types de trafic vers votre instance, créez un client par profil d'application et partagez les clients dans l'ensemble de l'application.
- Si vous n'utilisez pas la réplication ou les profils d'application, créez un client unique et partagez-le dans l'ensemble de l'application.
Si vous utilisez le client HBase pour Java, vous créez un objet
Connectionplutôt qu'un client. Vous devez donc créer le moins de connexions possible.Veillez à lire et à écrire de nombreuses lignes différentes dans votre table. Bigtable fonctionne au mieux lorsque les lectures et les écritures sont réparties uniformément dans la table, ce qui permet à Bigtable de répartir la charge de travail sur tous les nœuds du cluster. Si les lectures et les écritures ne peuvent pas être réparties sur tous les nœuds Bigtable, les performances en pâtissent.
Si vous constatez que vous ne lisez et écrivez qu'un petit nombre de lignes, vous devrez peut-être concevoir à nouveau votre schéma afin que les lectures et les écritures soient réparties plus uniformément.
Vérifiez que les performances sont similaires pour les lectures et les écritures. Si vous trouvez que les lectures sont beaucoup plus rapides que les écritures, vous essayez peut-être de lire des clés de ligne inexistantes ou une large plage de clés de ligne ne contenant qu'un petit nombre de lignes.
Pour établir une comparaison valable entre les lectures et les écritures, vous devez viser au moins 90 % de vos lectures renvoyant des résultats valides. De même, si vous lisez une grande plage de clés de ligne, mesurez les performances en fonction du nombre réel de lignes dans cette plage, plutôt que du nombre maximal de lignes pouvant exister.
Utilisez le type de requêtes d'écriture approprié pour vos données. Le choix de la méthode optimale pour écrire vos données permet de maintenir des performances élevées.
Vérifiez la latence d'une seule ligne. Si vous constatez une latence inattendue lors de l'envoi de requêtes
ReadRows, vous pouvez vérifier la latence de la première ligne de la requête pour identifier la cause. Par défaut, la latence globale d'une requêteReadRowsinclut la latence de chaque ligne de la requête, ainsi que le temps de traitement entre les lignes. Si la latence globale est élevée, mais que celle de la première ligne est faible, cela signifie que la latence est due au nombre de requêtes ou au temps de traitement, plutôt qu'à un problème lié à Bigtable.Si vous utilisez la bibliothèque cliente Bigtable pour Java, vous pouvez afficher la métrique
read_rows_first_row_latencydans l'explorateur de métriques de la consoleGoogle Cloud après avoir activé les métriques côté client.Utilisez un profil d'application distinct pour chaque charge de travail. Si vous rencontrez des problèmes de performances après avoir ajouté une charge de travail, créez un profil d'application pour la nouvelle charge de travail. Vous pouvez ensuite surveiller les métriques de vos profils d'application séparément pour poursuivre le dépannage. Consultez la section Fonctionnement des profils d'application pour savoir pourquoi il est recommandé d'utiliser plusieurs profils d'application.
Activez les métriques côté client. Vous pouvez configurer des métriques côté client pour vous aider à optimiser et à résoudre les problèmes de performances. Par exemple, comme Bigtable fonctionne mieux avec un RPS élevé et uniformément réparti, une latence P100 (max.) accrue pour un petit pourcentage de requêtes n'indique pas nécessairement un problème de performances plus important avec Bigtable. Les métriques côté client peuvent vous indiquer quelle partie du cycle de vie de la requête peut être à l'origine de la latence.
Assurez-vous que votre application consomme les requêtes de lecture avant qu'elles n'expirent. Si votre application traite des données pendant un flux de lecture, vous risquez que la requête expire avant que vous n'ayez reçu toutes les réponses de l'appel. Cela génère un message
ABORTED. Si cette erreur s'affiche, réduisez la quantité de traitement pendant le flux de lecture.
Étape suivante
- Apprenez à concevoir un schéma Bigtable.
- Découvrez comment surveiller les performances de Bigtable.
- Apprenez à résoudre les problèmes liés à Key Visualizer.
- Découvrez un exemple de code permettant d'ajouter de manière automatisée des nœuds à un cluster Bigtable.