Leistung nachvollziehen
Auf dieser Seite finden Sie Informationen zur ungefähren Leistung, die Bigtable unter optimalen Bedingungen bereitstellen kann, zu Faktoren, die sich auf die Leistung auswirken können, und Tipps zum Testen und Beheben von Leistungsproblemen in Bigtable.
Leistung bei typischer Arbeitslast
Bigtable bietet eine äußerst vorhersehbare Leistung, die linear skalierbar ist. Wenn Sie die nachfolgend beschriebenen Ursachen einer niedrigeren Leistung vermeiden, kann jeder Bigtable-Knoten den folgenden ungefähren Durchsatz bereitstellen, je nachdem, welchen Speichertyp der Cluster verwendet:
| Speichertyp | Lesevorgänge | Schreibvorgänge | Scans | ||
|---|---|---|---|---|---|
| SSD | bis zu 17.000 Zeilen pro Sekunde | oder | bis zu 14.000 Zeilen pro Sekunde | oder | bis zu 220 MB/s |
| HDD | bis zu 500 Zeilen pro Sekunde | oder | bis zu 10.000 Zeilen pro Sekunde | oder | bis zu 180 MB/s |
Bei diesen Schätzwerten wird davon ausgegangen, dass jede Zeile 1 KB Daten enthält.
Grundsätzlich erhöht sich die Leistung eines Clusters linear mit der Anzahl der Knoten im Cluster. Wenn Sie beispielsweise einen SSD-Cluster mit 10 Knoten erstellen, kann der Cluster bei einer typischen Arbeitslast mit ausschließlich Lese- oder Schreibvorgängen bis zu 140.000 Zeilen pro Sekunde unterstützen.
Bigtable-Kapazität planen
Entscheiden Sie bei der Planung Ihrer Bigtable-Cluster, ob Sie sie für Latenz oder Durchsatz optimieren möchten. Bei einem Batch-Verarbeitungsjob ist Ihnen beispielsweise der Durchsatz wichtiger als die Latenz. Bei einem Onlinedienst, der Nutzeranfragen verarbeitet, können Sie dagegen eine niedrigere Latenz dem Durchsatz vorziehen. Die Zahlen im Abschnitt Leistung bei typischen Arbeitslasten werden erreicht, wenn Sie den Durchsatz optimieren.
CPU-Auslastung
In fast allen Fällen empfehlen wir die Verwendung von Autoscaling. So können Sie mit Bigtable je nach Nutzung Knoten hinzufügen oder entfernen. Weitere Informationen finden Sie unter Autoscaling.
Beachten Sie die folgenden Richtlinien, wenn Sie Ihre Autoscaling-Ziele konfigurieren oder die manuelle Knotenzuweisung auswählen. Diese Richtlinien gelten unabhängig von der Anzahl der Cluster Ihrer Instanz. Bei einem Cluster mit manueller Knotenzuweisung müssen Sie die CPU-Auslastung des Clusters überwachen, um die CPU-Auslastung für eine optimale Leistung unter diesen Werten zu halten.
| Optimierungsziel | Maximale CPU-Auslastung |
|---|---|
| Durchsatz | 90 % |
| Latenz | 60 % |
Weitere Informationen zum Monitoring finden Sie unter Monitoring.
Speicherauslastung
Ein weiterer Aspekt bei der Kapazitätsplanung ist der Speicher. Die Speicherkapazität eines Clusters wird durch den Speichertyp und die Anzahl der Knoten im Cluster bestimmt. Wenn die Menge der in einem Cluster gespeicherten Daten zunimmt, optimiert Bigtable den Speicher, indem die Datenmenge auf alle Knoten im Cluster verteilt wird.
Sie können die Speichernutzung pro Knoten ermitteln, indem Sie die Speicherauslastung (Byte) des Clusters durch die Anzahl der Knoten im Cluster teilen. Beispiel: Ein Cluster hat drei HDD-Knoten und 9 TB an Daten. Jeder Knoten speichert ungefähr 3 TB, was 18,75 % des HDD-Speicherlimits pro Knoten von 16 TB entspricht.
Wenn die Speicherauslastung zunimmt, können Arbeitslasten eine höhere Latenz bei der Abfrageverarbeitung aufweisen, auch wenn der Cluster genügend Knoten hat, um die gesamten CPU-Anforderungen zu erfüllen. Das liegt daran, das umso mehr Hintergrundarbeit wie für die Indexierung erforderlich ist, je größer der Speicher pro Knoten ist. Die Erhöhung der Hintergrundarbeit, um mehr Speicher zu bewältigen, kann zu einer höheren Latenz und einem geringeren Durchsatz führen.
Beginnen Sie mit den folgenden Schritten, um die Autoscaling-Einstellungen zu konfigurieren. Wenn Sie die manuelle Knotenzuweisung auswählen, überwachen Sie die Speicherauslastung des Clusters und fügen Sie Knoten hinzu oder entfernen Sie sie, um Folgendes zu gewährleisten:
| Optimierungsziel | Maximale Speicherauslastung |
|---|---|
| Durchsatz | 70 % |
| Latenz | 60 % |
Weitere Informationen finden Sie unter Speicherplatz pro Knoten.
Typische Arbeitslasten in Bigtable ausführen
Führen Sie für die Kapazitätsplanung immer Ihre eigenen typischen Arbeitslasten in einem Bigtable-Cluster aus, damit Sie die beste Ressourcenzuweisung für Ihre Anwendungen finden.
PerfKit Benchmarker von Google nutzt YCSB, um Cloud-Dienste zu vergleichen. Folgen Sie der PerfKitBenchmarker-Anleitung für Bigtable, um Tests für Ihre eigenen Arbeitslasten zu erstellen. Dabei sollten Sie die Parameter in den yaml-Benchmarking-Konfigurationsdateien anpassen, damit die generierte Benchmark die folgenden Eigenschaften in Ihrer Produktion widerspiegelt:
- Gesamtgröße Ihrer Tabelle. Dieser Wert kann proportional sein, sollte aber mindestens 100 GB umfassen.
- Zeilendatenform (Zeilenschlüsselgröße, Anzahl der Spalten, Zeilendatengrößen usw.)
- Datenzugriffsmuster (Verteilung der Zeilenschlüssel)
- Mischung aus Lese- und Schreibvorgängen
Weitere Best Practices finden Sie unter Leistungstest mit Bigtable.
Ursachen einer niedrigeren Leistung
Wenn Bigtable eine geringere Leistung erzielt, als in den obigen Schätzwerten angegeben, kann dies mehrere Gründe haben.
- Sie lesen eine große Anzahl nicht zusammenhängender Zeilenschlüssel oder Zeilenbereiche in einer einzigen Leseanfrage. Bigtable scannt die Tabelle und liest die angeforderten Zeilen sequenziell. Diese fehlende Parallelität wirkt sich auf die gesamte Latenz aus und alle Lesevorgänge, die einen Hot-Knoten erreichen, können die tail-Latenz erhöhen. Weitere Informationen finden Sie unter Lesevorgänge und Leistung.
- Das Schema der Tabelle ist nicht korrekt entworfen. Für eine gute Schreibleistung von Bigtable ist es entscheidend, ein Schema zu entwerfen, mit dem Lese- und Schreibvorgänge gleichmäßig auf alle Tabellen verteilt werden können. Außerdem können Hotspots in einer Tabelle die Leistung anderer Tabellen in derselben Instanz beeinträchtigen. Weitere Informationen finden Sie unter Best Practices für das Schemadesign.
- Die Zeilen der Bigtable-Tabelle enthalten große Datenmengen. Bei den oben genannten Leistungsschätzwerten wird davon ausgegangen, dass jede Zeile 1 KB Daten enthält. Sie können größere Datenmengen pro Zeile lesen und schreiben, eine höhere Datenmenge pro Zeile reduziert jedoch die Anzahl an Zeilen pro Sekunde.
- Die Zeilen der Bigtable-Tabelle enthalten sehr viele Zellen. Bigtable benötigt Zeit für die Verarbeitung der einzelnen Zellen in einer Zeile. Außerdem bedeutet jede Zelle eine zusätzliche Datenmenge, die in der Tabelle gespeichert und über das Netzwerk gesendet wird. Wenn Sie beispielsweise 1 KB (1.024 Byte) Daten speichern, ist es sehr viel platzsparender, diese Daten in einer einzelnen Zelle zu speichern als in 1.024 Zellen mit jeweils 1 Byte. Wenn Sie die Daten auf mehr Zellen als nötig aufteilen, erhalten Sie ggf. nicht die bestmögliche Leistung. Wenn Zeilen eine große Anzahl Zellen enthalten, da Spalten mehrere Zeitstempelversionen beinhalten, sollten Sie nur den aktuellsten Wert beibehalten. Eine weitere Option für bereits vorhandene Tabellen wäre es, bei jedem Umschreiben alle vorherigen Versionen zu löschen.
Der Cluster hat nicht genug Knoten. Die Knoten eines Clusters bieten Rechenleistung für den Cluster, um eingehende Lese- und Schreibvorgänge zu verarbeiten, den Speicher zu verfolgen und Wartungsaufgaben wie die Verdichtung durchzuführen. Achten Sie darauf, dass Ihr Cluster genügend Knoten hat, um die empfohlenen Limits für Computing und Speicher einzuhalten. Mit den Monitoringtools sehen Sie, ob Ihr Cluster überlastet ist.
- Compute: Wenn die CPU Ihres Bigtable-Clusters überlastet ist, kann die Leistung durch das Hinzufügen weiterer Knoten verbessert werden, indem die Arbeitslast auf mehr Knoten verteilt wird.
- Speicher: Wenn Ihre Speichernutzung pro Knoten höher geworden ist als empfohlen, müssen Sie weitere Knoten hinzufügen, um eine optimale Latenz und einen optimalen Durchsatz zu gewährleisten, auch wenn der Cluster genügend CPU hat, um Anfragen zu verarbeiten. Dies liegt daran, dass durch Erhöhen des Speichers pro Knoten die Hintergrundwartungsarbeit pro Knoten erhöht wird. Weitere Informationen finden Sie unter Kompromisse zwischen Speichernutzung und Leistung.
Der Bigtable-Cluster wurde vor kurzer Zeit vergrößert oder verkleinert. Nachdem die Anzahl der Knoten in einem Cluster erhöht wurde, kann es unter Last bis zu 20 Minuten dauern, bis Sie eine signifikante Verbesserung der Clusterleistung feststellen. Bigtable skaliert die Knoten in einem Cluster basierend auf der Auslastung.
Wenn Sie die Anzahl der Knoten in einem Cluster verringern, um sie herunterzuskalieren, versuchen Sie, die Clustergröße in einem Zeitraum von 10 Minuten nicht um mehr als 10% zu reduzieren, um Latenzspitzen zu minimieren.
Der Bigtable Cluster nutzt HDD-Festplatten. In den meisten Fällen sollte Ihr Cluster SSD-Festplatten verwenden, die eine deutlich bessere Leistung als HDD-Festplatten liefern. Genaueres erfahren Sie unter Zwischen SSD- und HDD-Speicher wählen.
Es liegen Probleme mit der Netzwerkverbindung vor. Netzwerkprobleme können den Durchsatz reduzieren und dazu führen, dass Lesen und Schreiben länger als gewöhnlich dauert. Probleme treten insbesondere dann auf, wenn die Clients nicht in derselben Zone wie der Bigtable-Cluster oder außerhalb von Google Cloudausgeführt werden.
Sie verwenden die Replikation, aber Ihre Anwendung verwendet eine veraltete Clientbibliothek. Wenn Sie nach dem Aktivieren der Replikation eine erhöhte Latenz beobachten, prüfen Sie, ob die von Ihrer Anwendung verwendete Cloud Bigtable-Clientbibliothek auf dem neuesten Stand ist. Ältere Versionen der Clientbibliotheken sind möglicherweise nicht für die Unterstützung der Replikation optimiert. Unter Cloud Bigtable-Clientbibliotheken finden Sie das GitHub-Repository Ihrer Clientbibliothek, wo Sie die Version prüfen und bei Bedarf ein Upgrade ausführen können.
Sie haben die Replikation aktiviert, aber keine weiteren Knoten zu Ihren Clustern hinzugefügt. In einer Instanz mit Replikation muss jeder Cluster zusätzlich zu der von Anwendungen empfangenen Last die Arbeit der Replikation bewältigen. Unzureichend konfigurierte Cluster können zu erhöhter Latenz führen. Sie können dies in den Diagrammen der Instanz zur CPU-Nutzung in der Google Cloud Console überprüfen.
Da verschiedene Arbeitslasten Leistungsschwankungen verursachen können, sollten Sie Tests mit Ihren eigenen Arbeitslasten ausführen, um die genauesten Vergleichswerte zu erhalten.
Kaltstarts und niedrige QPS-Werte
Kaltstarts und niedrige QPS-Werte können die Latenz erhöhen. Bigtable funktioniert am besten mit großen Tabellen, auf die häufig zugegriffen wird. Wenn Sie nach einem Zeitraum der Nichtnutzung Anfragen senden, kann es daher zu hoher Latenz kommen, während Bigtable Verbindungen wiederherstellt. Außerdem ist die Latenz höher, wenn die QPS niedrig ist.
Wenn Ihre QPS niedrig ist oder Sie wissen, dass Sie nach einer Inaktivitätsphase manchmal Anfragen an eine Bigtable-Tabelle senden, können Sie mit den folgenden Strategien Ihre Verbindung warm halten und diese hohe Latenz vermeiden.
- Senden Sie jederzeit eine niedrige Rate künstlicher Zugriffe an die Tabelle.
- Konfigurieren Sie den Verbindungspool, um dafür zu sorgen, dass stabile Abfragen pro Sekunde den Pool aktiv halten.
Bei Zeiten mit geringem QPS-Wert ist die Anzahl der Fehler, die Bigtable zurückgibt, relevanter als der Prozentsatz der Vorgänge, die einen Fehler zurückgeben.
Kaltstart bei der Clientinitialisierung Wenn Sie eine Version des Cloud Bigtable-Clients für Java verwenden, die älter als Version 2.18.0 ist, können Sie die Aktualisierung des Kanals aktivieren. In neueren Versionen ist die Kanalaktualisierung standardmäßig aktiviert. Die Kanalaktualisierung hat zwei Vorteile:
- Bei der Initialisierung des Clients wird der Kanal vorbereitet, bevor die ersten Anfragen gesendet werden.
- Der Server trennt langlebige Verbindungen jede Stunde. Bei der Kanalinitialisierung werden die ablaufenden Kanäle vorzeitig ausgetauscht.
Das hält den Kanal aber nicht aktiv, wenn es Phasen der Inaktivität gibt.
Wie Bigtable meine Daten mit der Zeit optimiert
Zum Speichern der zugrunde liegenden Daten für jede Ihrer Tabellen teilt Bigtable die Daten in mehrere Tabellenreihen, die zwischen Knoten in Ihrem Bigtable-Cluster verschoben werden können. Durch diese Speichermethode kann Bigtable zwei verschiedene Strategien zur Optimierung Ihrer Daten im Zeitverlauf verwenden:
- Bigtable versucht, ungefähr die gleiche Datenmenge auf jedem Bigtable-Knoten zu speichern.
- Bigtable versucht, die Lese- und Schreibvorgänge gleichmäßig auf alle Bigtable-Knoten zu verteilen.
Manchmal stehen diese Strategien im Widerspruch zueinander. Wenn beispielsweise die Zeilen einer Tabellenreihe sehr häufig gelesen werden, könnte Bigtable diese Tabellenreihe auf einem eigenen Knoten speichern, auch wenn das dazu führt, dass auf einigen Knoten mehr Daten als auf anderen gespeichert werden.
Als Teil dieses Vorgangs könnte Bigtable auch eine Tabellenreihe in zwei oder mehr kleinere Tabellenreihen aufspalten, entweder um die Größe zu reduzieren oder um häufig genutzte Zeilen innerhalb einer Tabellenreihe zu isolieren.
Im folgenden Teil werden diese Strategien detaillierter erläutert.
Datenmenge auf Knoten verteilen
Wenn Sie Daten in eine Bigtable-Tabelle schreiben, teilt Bigtable die Daten in Tabellenreihen. Jede Tabellenreihe enthält einen fortlaufenden Bereich an Zeilen innerhalb der Tabelle.
Sollten Sie weniger als mehrere GB Daten in die Tabelle geschrieben haben, speichert Bigtable alle Tabellenreihen auf einem einzigen Knoten in Ihrem Cluster:
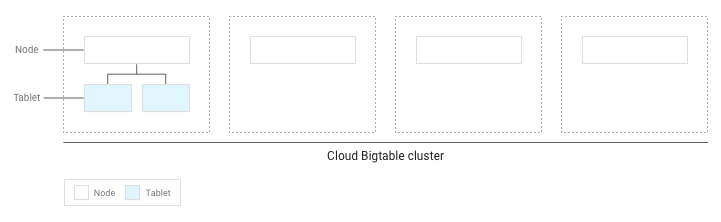
Nachdem sich mehr Tabellenreihen angesammelt haben, wird Bigtable einige von ihnen zu anderen Knoten verschieben, sodass die Datenmenge gleichmäßiger über den Cluster verteilt ist:
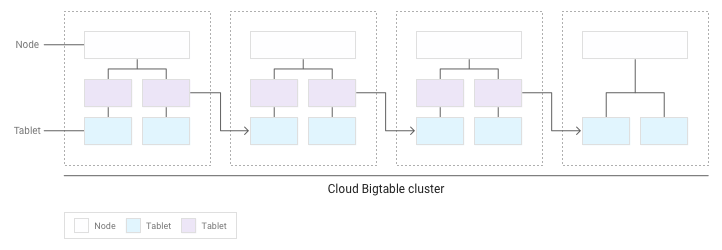
Lese- und Schreibvorgänge gleichmäßig auf Knoten verteilen
Wenn Sie Ihr Schema korrekt entworfen haben, sollten Lese- und Schreibvorgänge gleichmäßig auf die gesamte Tabelle verteilt sein. Es gibt aber Fälle, in denen Sie es nicht verhindern können, auf manche Zeilen öfter zuzugreifen als auf andere. Bigtable hilft Ihnen an dieser Stelle, da es Lese- und Schreibvorgänge berücksichtigt, wenn es Tabellenreihen auf Knoten verteilt.
Nehmen wir beispielsweise an, 25 % der Lesevorgänge betreffen eine kleine Zahl der Tabellenreihen in einem Cluster und Lesevorgänge wären in allen anderen Tabellenreihen gleichmäßig verteilt:
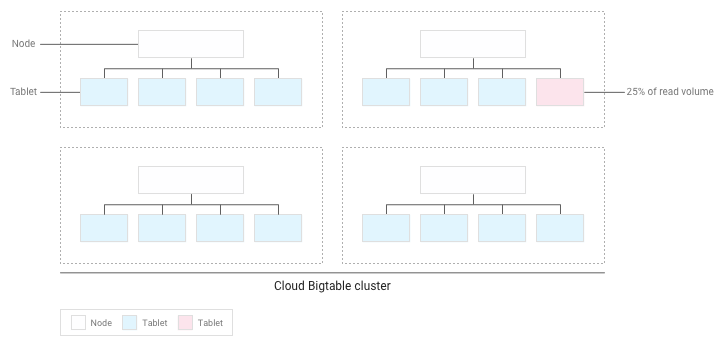
Bigtable wird die vorhandenen Tabellenreihen umverteilen, sodass Lesevorgänge so gleichmäßig wie möglich auf den gesamten Cluster verteilt sind:
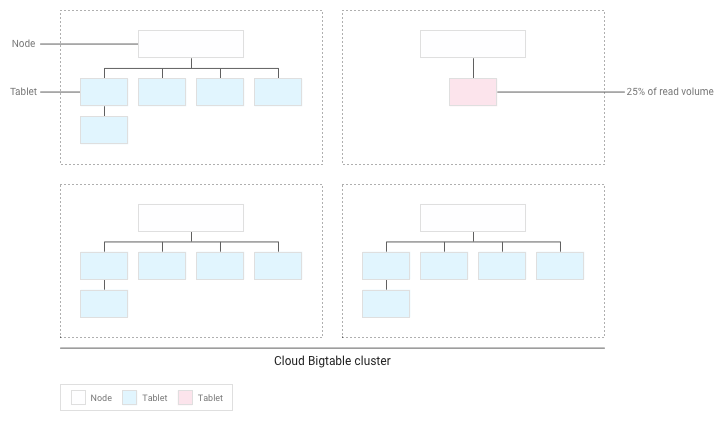
Leistung mit Bigtable testen
Wenn Sie einen Leistungstest für eine Anwendung ausführen, die von Bigtable abhängig ist, beachten Sie beim Planen und Ausführen des Tests die folgenden Richtlinien:
- Testen Sie mit genügend Daten.
- Wenn die Tabellen in Ihrer Produktionsinstanz insgesamt maximal 100 GB Daten pro Knoten enthalten, testen Sie mit einer Tabelle mit derselben Datenmenge.
- Wenn die Tabellen mehr als 100 GB Daten pro Knoten enthalten, testen Sie sie mit einer Tabelle, die mindestens 100 GB Daten pro Knoten enthält. Wenn die Produktionsinstanz beispielsweise einen Cluster mit vier Knoten hat und die Tabellen in der Instanz insgesamt 1 TB Daten enthalten, führen Sie den Test mit einer Tabelle von mindestens 400 GB aus.
- Testen Sie mit einer einzelnen Tabelle.
- Unter der empfohlenen Speicherauslastung pro Knoten bleiben. Weitere Informationen finden Sie unter Speicherauslastung pro Knoten.
- Einen intensiven Vortest ausführen. Dieser Schritt gibt Bigtable die Möglichkeit, Daten basierend auf den Zugriffsmustern, die es beobachtet, auf die Knoten zu verteilen.
- Den Test mindestens 10 Minuten ausführen. Dieser Schritt ermöglicht die weitere Optimierung Ihrer Daten durch Bigtable. Außerdem wird dafür gesorgt, dass sowohl Lesevorgänge von der Festplatte als auch im Cache gespeicherte Lesevorgänge aus dem Arbeitsspeicher getestet werden.
Leistungsprobleme beheben
Wenn Sie der Meinung sind, dass Bigtable möglicherweise einen Leistungsengpass in Ihrer Anwendung verursacht, prüfen Sie Folgendes:
- Sehen Sie sich die Key Visualizer-Scans für die Tabelle an. Das Key Visualizer-Tool für Bigtable generiert alle 15 Minuten neue Scandaten, die die Nutzungsmuster der einzelnen Tabellen in einem Cluster anzeigen. Mit Key Visualizer können Sie überprüfen, ob die Nutzungsmuster die Ursache von unerwünschten Ergebnissen sind, z. B. Hotspots bei bestimmten Zeilen oder eine übermäßig hohe CPU-Auslastung. Einstieg in Key Visualizer
- Versuchen Sie, den Code, der die Lese- und Schreibvorgänge von Bigtable durchführt, auszukommentieren. Wenn sich das Leistungsproblem löst, nutzen Sie Bigtable wahrscheinlich auf eine Art, die in unzulänglicher Leistung resultiert. Wenn das Leistungsproblem weiterhin besteht, liegt das Problem wahrscheinlich nicht an Bigtable.
Achten Sie darauf, möglichst wenig Clients zu erstellen. Das Erstellen eines Clients für Bigtable ist ein relativ teurer Vorgang. Deshalb sollten Sie so wenig Clients wie möglich erstellen.
- Wenn Sie die Replikation verwenden oder mithilfe von Anwendungsprofilen unterschiedliche Arten von Traffic für die Instanz ermitteln möchten, erstellen Sie einen Client pro Anwendungsprofil und geben die Clients für die gesamte Anwendung frei.
- Wenn Sie keine Replikation und keine Anwendungsprofile verwenden, erstellen Sie einen einzigen Client und geben Sie ihn in Ihrer gesamten Anwendung frei.
Wenn Sie den HBase-Client für Java verwenden, erstellen Sie ein
Connection-Objekt anstelle eines Clients, deshalb sollten Sie möglichst wenig Verbindungen erstellen.Schreiben und lesen Sie in möglichst vielen verschiedenen Zeilen Ihrer Tabelle. Bigtable funktioniert am besten, wenn Lese- und Schreibvorgänge gleichmäßig auf die ganze Tabelle verteilt sind. Dies hilft Bigtable dabei, die Arbeitslast auf alle Knoten im Cluster zu verteilen. Wenn Lese- und Schreibvorgänge nicht auf alle Knoten in Bigtable verteilt werden können, beeinträchtigt das die Leistung.
Wenn Sie feststellen, dass Sie nur eine kleine Anzahl von Zeilen lesen und schreiben, müssen Sie möglicherweise das Schema so neu entwerfen, dass Lese- und Schreibvorgänge gleichmäßiger verteilt sind.
Prüfen Sie, ob Sie die gleiche Leistung für Lese- und Schreibvorgänge sehen. Wenn Sie feststellen, dass Lesevorgänge viel schneller als Schreibvorgänge sind, versuchen Sie möglicherweise, Zeilenschlüssel zu lesen, die nicht vorhanden sind, oder einen großen Bereich von Zeilenschlüsseln zu lesen, der nur eine geringe Anzahl von Zeilen enthält.
Für einen fundierten Vergleich zwischen Lese- und Schreibvorgängen sollten Sie dafür sorgen, dass mindestens 90 % Ihrer Lesevorgänge gültige Ergebnisse zurückgeben. Außerdem sollten Sie beim Lesen einer großen Anzahl an Zeilenschlüsseln die Leistung anhand der tatsächlichen Anzahl an Zeilen in dem Bereich messen und nicht anhand der maximalen Anzahl an Zeilen, die existieren könnten.
Verwenden Sie die richtigen Schreibanfragen für Ihre Daten. Durch Auswahl des optimalen Schreibvorgangs Ihrer Daten können Sie eine hohe Leistung erzielen.
Prüfen Sie die Latenz für eine einzelne Zeile. Wenn beim Senden von
ReadRows-Anfragen unerwartete Latenzen auftreten, können Sie die Latenz der ersten Zeile der Anfrage prüfen, um die Ursache einzugrenzen. Standardmäßig umfasst die Gesamtlatenz für eineReadRows-Anfrage die Latenz für jede Zeile in der Anfrage sowie die Verarbeitungszeit zwischen Zeilen. Wenn die Gesamtlatenz hoch ist, aber die Latenz der ersten Zeile niedrig ist, lässt dies darauf schließen, dass die Latenz durch die Anzahl der Anfragen oder durch die Verarbeitungszeit und nicht durch ein Problem mit Bigtable verursacht wird.Wenn Sie die Bigtable-Clientbibliothek für Java verwenden, können Sie den Messwert
read_rows_first_row_latencyim Google Cloud Metrics Explorer der Console nach dem Aktivieren der clientseitigen Messwerte ansehen.Separates Anwendungsprofil für jede Arbeitslast verwenden Wenn nach dem Hinzufügen einer neuen Arbeitslast Leistungsprobleme auftreten, erstellen Sie ein neues Anwendungsprofil für die neue Arbeitslast. Anschließend können Sie die Messwerte für Ihre Anwendungsprofile separat überwachen, um weitere Fehler zu beheben. Unter Funktionsweise von Anwendungsprofilen erfahren Sie, warum es sich empfiehlt, mehrere Anwendungsprofile zu verwenden.
Aktivieren Sie clientseitige Messwerte. Sie können clientseitige Messwerte einrichten, um die Leistung zu optimieren und Leistungsprobleme zu beheben. Da Bigtable beispielsweise am besten mit gleichmäßig verteilten, hohen QPS funktioniert, ist eine erhöhte P100-Latenz (max.) für einen kleinen Prozentsatz der Anfragen nicht unbedingt ein Hinweis auf ein größeres Leistungsproblem mit Bigtable. Clientseitige Messwerte können Aufschluss darüber geben, welcher Teil des Anfragelebenszyklus die Latenz verursacht.
Achten Sie darauf, dass Ihre Anwendung Leseanfragen vor Ablauf des Zeitlimits verarbeitet. Wenn Ihre Anwendung während eines Lesestreams Daten verarbeitet, besteht die Gefahr, dass die Anfrage abläuft, bevor Sie alle Antworten vom Aufruf erhalten haben. Dies führt zu einer
ABORTED-Meldung. Wenn dieser Fehler auftritt, reduzieren Sie die Verarbeitungsmenge während des Lesestreams.
Nächste Schritte
- Bigtable-Schema erstellen
- Bigtable-Leistung beobachten
- Probleme in Key Visualizer beheben
- Sehen Sie sich Beispielcode für das programmatische Hinzufügen von Knoten zu einem Bigtable-Cluster an