このドキュメントは、データストアとして Bigtable を使用する既存のアプリケーションの移行や新しいアプリケーションの設計を行うソフトウェア デベロッパーとデータベース管理者を対象としています。このドキュメントでは、Apache Cassandra の知識を Bigtable の使用に適用します。
Bigtable と Cassandra は、分散型のデータベースです。どちらのデータベースにも、数万の秒間クエリ数(QPS)をサポートできる多次元の Key-Value ストア、ペタバイト規模のデータまでスケールアップできるストレージ、ノード障害に対する耐性が実装されています。
両データベースの一連の機能は、見かけは似ていますが、その根底にあるアーキテクチャと動作の細部は異なっており、それを理解することが重要です。このドキュメントでは、2 つのデータベース システムの類似点と相違点に焦点を当てて説明します。
Bigtable が Cassandra ワークロードの適切なデスティネーションとなる場合
Cassandra ワークロードに最適な Google Cloud サービスは、移行の目標と、移行後に必要な Cassandra 機能によって異なります。
Bigtable は、読み取りと同様に書き込みのスループットとレイテンシが重要な場合に最適です。Bigtable の結果整合性、高速なローカル書き込み、カスタム タイムスタンプの使用、柔軟なスキーマ(更新可能なコレクション タイプなど)、さまざまなクラスタ トポロジにより、Bigtable は進化するアプリケーションをサポートし、低レイテンシを費用対効果よく提供できます。
コードを変更せずにアプリケーションを移行するには、GKE で Cassandra をセルフマネージするか、DataStax や ScyllaDB などの Google Cloudパートナーを使用します。アプリケーションで読み取りが頻繁に行われ、リレーショナル データベースの機能と強整合性を実現するためにコードをリファクタリングする意向がある場合は、Spanner を検討してください。
このドキュメントでは、Cassandra ワークロードの移行先として Bigtable を選択した場合に、アプリケーションをリファクタリングする際に考慮すべき点について説明します。
このドキュメントの使用方法
このドキュメントは、初めから終わりまで読む必要はありません。このドキュメントでは、2 つのデータベースを比較して説明しますが、ユースケースや関心に合うトピックに絞って確認することもできます。
成熟した 2 つのデータベースの比較は、一筋縄ではいきません。この目的を達成するために、このドキュメントでは次のことを行います。
- 2 つのデータベースで使用される用語の違いを比較します。
- 2 つのデータベース システムの概要を説明します。
- 設計に関するさまざまな考慮事項を把握するために、各データベースによるデータ モデリングの扱い方を確認します。
- 書き込み時および読み取り時のデータの経路を比較します。
- 物理的なデータの配置を調べ、データベース アーキテクチャの側面を把握します。
- 要件を満たすように地理的レプリケーションを構成する方法と、クラスタのサイズ設定を行う際の考え方について説明します。
- クラスタの管理、モニタリング、セキュリティの詳細を確認します。
用語の比較
Bigtable と Cassandra で使用されているコンセプトの多くは類似していますが、コンセプトの名前や意味には、それぞれのデータベースで微妙な違いがあります。
どちらのデータベースにも、中核となる構成要素の 1 つに、ソートされた文字列テーブル(SSTable)があります。SSTables は、どちらのアーキテクチャでも、読み取りクエリへのレスポンスに使用するデータを保持するために作成されます。
ブログ投稿(2012)で、Ilya Grigorik は次のように述べています。「SSTable は、高スループットの順次読み取り / 書き込みワークロードを最適化しながら、大量の Key-Value ペアを効率的に保存するシンプルな抽象化です。」
次の表では、各プロダクトで使用されている共通のコンセプトと、対応する用語を取り上げて説明します。
| Cassandra | Bigtable |
|---|---|
|
主キー: データの配置と順序を決定する一意の単一フィールドまたはマルチフィールドの値。 パーティション キー: コンシステント ハッシュによってデータの配置を決定する単一フィールドまたはマルチフィールドの値。 クラスタリング列: パーティション内のデータの辞書的な並びを決める単一フィールドまたはマルチフィールドの値。 |
行キー: 辞書順で並べ替えられたデータの配置を決める、一意の単一バイト文字列。複合キーは、共通の区切り文字(例: ハッシュ(#)やパーセント(%)記号)を使用して複数の列のデータを結合することで代用されます。 |
| ノード: 一連の主キー パーティション ハッシュ範囲に関連付けられたデータを読み取りおよび書き込みするマシン。Cassandra では、ノードサーバーにアタッチされたブロックレベルのストレージにデータが保存されます。 | ノード: 一連の行キー範囲に関連付けられたデータを、読み取りおよび書き込みする仮想コンピューティング リソース。Bigtable では、データはコンピューティング ノードと同じ場所には配置されません。代わりに、Google の分散ファイル システム Colossus に保存されます。ノードには、オペレーション負荷とクラスタ内の他のノードの正常性に基づいてさまざまなデータを扱う一時的な役割が与えられます。 |
|
データセンター: Cassandra ではトポロジのいくつかの側面とレプリケーション方針が構成可能なことを除き、Bigtable のクラスタに似ています。 ラック: データセンター内のノードをグループ化したもので、レプリカの配置に影響を与えます。 |
クラスタ: レイテンシとレプリケーションの問題に対応するために、地理的に同じGoogle Cloud ゾーンに配置されたノードのグループ。 |
| クラスタ: データセンターの集合で構成される Cassandra デプロイメント。 | インスタンス: レプリケーションや接続ルーティングが相互間で発生するさまざまな Google Cloud ゾーンまたはリージョンの Bigtable クラスタのグループ。 |
| vnode: 特定の物理ノードに割り当てられたハッシュ値の固定範囲。vnode のデータは、一連の SSTable の Cassandra ノードに物理的に保存されます。 | tablet: 辞書順で並べ替えられた、連続する行キー範囲のすべてのデータが含まれる SSTable。タブレットは、Bigtable のノードではなく、Colossus 上の一連の SSTable に保存されます。 |
| レプリケーション係数: データセンター内のすべてのノードで維持される vnode のレプリカ数。レプリケーション係数は、データセンターごとに個別に構成されます。 | レプリケーション: Bigtable に保存されたデータをインスタンス内のすべてのクラスタに複製するプロセス。ゾーンクラスタ内でのレプリケーションは、Colossus ストレージ レイヤで処理されます。 |
| テーブル(旧称: 列ファミリー): 一意の主キーによってインデックス付けされた値の論理構成。 | テーブル: 一意の行キーによってインデックス付けされた値の論理構成。 |
| キースペース: 対象テーブルに含まれるテーブルのレプリケーション係数を定義する論理テーブル名前空間。 | 該当なし。Bigtable では、キースペースに関する事項は透過的に処理されます。 |
| マップ: Key-Value ペアを保持する Cassandra コレクション タイプ。 | 列ファミリー: より効率よく読み取りおよび書き込みするために列修飾子をグループ化するユーザー指定の名前空間。 SQL を使用して Bigtable にクエリを実行する場合、列ファミリーは Cassandra のマップのように扱われます。 |
| マップキー: Cassandra マップ内の Key-Value エントリを一意に識別するキー | 列修飾子: 一意の行キーでインデックス付けされてテーブルに保存されている値のラベル。 SQL を使用して Bigtable にクエリを実行すると、列はマップのキーのように扱われます。 |
| 列: 一意の主キーでインデックス付けされてテーブルに保存されている値のラベル。 | 列: 一意の行キーでインデックス付けされてテーブルに保存されている値のラベル。列名は、列ファミリーと列修飾子を組み合わせて作られます。 |
| セル: テーブル内で列と主キーの交差に関連付けられたタイムスタンプ値。 | セル: テーブル内で列名と行キーの交差に関連付けられたタイムスタンプ値。各セルに対してタイムスタンプ付きのバージョンを複数保存することや、取得することが可能です。 |
| カウンタ: 整数の合計演算用に最適化されたインクリメント可能なフィールド タイプ。 | カウンタ: 整数の合計演算に特殊なデータ型を使用するセル。詳細については、カウンタを作成して更新するをご覧ください。 |
| 負荷分散ポリシー: クラスタ内でオペレーションを適切なノードに転送するように、アプリケーション ロジックで構成するポリシー。このポリシーでは、データセンターのトポロジと vnode トークンの範囲が考慮されます。 | アプリケーション プロファイル: クライアント API 呼び出しをインスタンス内の適切なクラスタに転送する方法を Bigtable に指示する設定。タグとして使用することで、指標をセグメント化することもできます。アプリケーション プロファイルは、サービス内に構成します。 |
| CQL: Cassandra のクエリ言語。テーブルの作成、スキーマの変更、行ミューテーション、クエリに使用される SQL などの言語。 | Bigtable API: インスタンスとクラスタの作成、テーブルと列ファミリーの作成、行のミューテーション、クエリに使用されるクライアント ライブラリと gRPC API。 Bigtable の SQL API は、CQL ユーザーに馴染みのある API です。 |
プロダクトの概要
以降のセクションでは、Bigtable と Cassandra の設計思想と主な特性について概説します。
Bigtable
Bigtable は、Bigtable: 構造化データ向けの分散ストレージ システムの論文で説明されているさまざまな核となる機能を備えています。Bigtable では、クライアント リクエストを処理するコンピューティング ノードが、基盤となるストレージ管理から分離されています。データは、Colossus に保存されます。ストレージ レイヤは、データを自動的に複製し、標準的な Hadoop 分散ファイル システム(HDFS)の 3 方向レプリケーションがもたらすレベルを超える耐久性を実現します。
このアーキテクチャでは、クラスタ内で読み取りと書き込みが一貫して行われ、ストレージの再分配コストなしでスケールアップとスケールダウンが行われます。また、クラスタやスキーマを変更せずにワークロードを再調整できます。データ処理ノードで障害が発生した場合は、Bigtable サービスによって透過的にノードが置き換えられます。Bigtable は、非同期レプリケーションもサポートしています。
Bigtable では、gRPC とさまざまなプログラミング言語のクライアント ライブラリに加え、オープンソースの Apache HBase Java クライアント ライブラリ(Bigtable 論文の代替オープンソース データベース エンジン実装)との互換性が維持されています。
次の図は、Bigtable が処理ノードとストレージ レイヤを物理的に分離する仕組みを示しています。
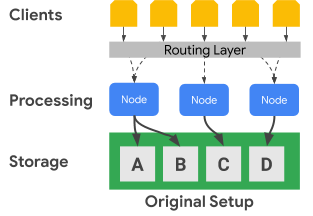
上の図において、中央の処理ノードは、ストレージ レイヤ内の C データセットのデータ リクエストを処理することのみを受け持っています。ストレージ レイヤが処理レイヤから分離されているため、Bigtable によってデータセットに対する範囲割り当ての再調整が必要と判断された場合、処理ノードのデータ範囲は簡単に変更できます。
次の図は、キー範囲の再調整とクラスタのサイズ変更を簡略化して示しています。
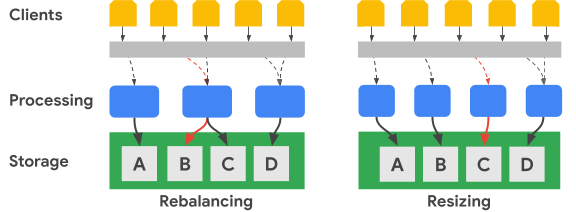
再調整の図は、左端の処理ノードが受信する A データセットに対するリクエスト数が増加した後の Bigtable クラスタの状態を示しています。再調整が行われた後、左端のノードではなく中央のノードが、B のデータセット向けのデータ リクエストを処理します。左端のノードは、引き続き A のデータセット向けのリクエストを処理します。
Bigtable は、数を増やした使用可能な処理ノード全体でデータセットの範囲を調整するために、行キーの範囲を再編成できます。Resizing の図は、ノードを 1 つ追加した後の Bigtable クラスタの状態を示していす。
Cassandra
Apache Cassandra は、Bigtable 論文のコンセプトから部分的に影響を受けているオープンソース データベースです。分散型ノード アーキテクチャが使用され、ストレージがデータ操作に応答するサーバーと同じ場所に配置されます。各サーバーには、一連の仮想ノード(vnode)がランダムに割り当てられ、クラスタ キースペースの一部を担います。
データは、パーティション キーに基づいて vnode に保存されます。通常、コンシステント ハッシュ関数を使用してトークンが生成され、それによってデータの配置が決まります。Bigtable と同様、トークン生成用の順序保持パーティショナが使用でき、これはデータの配置にも利用できます。ただし、Cassandra のドキュメントによると、この方法は、クラスタのバランスが崩れる可能性があり、解決が困難になるため、推奨されていません。このため、このドキュメントでは、一貫したハッシュ方針を使用して、ノード間でデータを分散するトークンを生成することを前提としています。
Cassandra では、調整可能な整合性レベルに関連する可用性レベルによってフォールト トレラントを実現し、1 つ以上のノードで障害が発生しても、クラスタがクライアントにサービスを提供できるようにします。レプリケーションの地理的な側面は、構成可能なデータ レプリケーション トポロジ方針で定義します。
整合性のレベルは、オペレーションごとに指定します。通常の設定は、QUORUM(または特定の複数データセンター トポロジの場合は LOCAL_QUORUM)です。この整合性レベルの設定でオペレーションが成功したと見なされるには、レプリカノードの過半数がコーディネーター ノードに応答する必要があります。クラスタ内の各データセンターに保存されるデータレプリカの数は、すべてのキースペースに対して構成するレプリケーション係数によって決まります。たとえば、通常は、レプリケーション係数値 3 を使用して、耐久性とストレージ ボリュームの現実的なバランスが確保されます。
次の図は、各ノードのキー範囲が 5 つの vnode に分割された 6 つのノードのクラスタを簡略化したものです。実際には、さらにノードを追加でき、vnode の数は増加すると考えられます。

上の図では、書き込みオペレーションのパスに整合性レベル QUORUM が設定されており、それがクライアント アプリケーションまたはサービス(クライアント)から発信されていることが確認できます。この図では、キー範囲をアルファベットの範囲として示しています。実際には、主キーのハッシュによって生成されるトークンは、非常に大きい符号付き整数です。
この例では、キーのハッシュは M で、M の vnode はノード 2、4、6 にあります。コーディネーターは、書き込みが処理されるように、キーのハッシュ範囲がローカルに格納されている各ノードにアクセスする必要があります。整合性レベルが QUORUM のため、書き込みの完了は、2 つのレプリカ(過半数)がコーディネーター ノードに応答した後、クライアントに通知する必要があります。
Bigtable とは異なり、Cassandra でキー範囲を移動や変更するには、ノード間でデータを物理的にコピーする必要があります。特定のトークン ハッシュ範囲に対するリクエストで 1 つのノードが過負荷状態になった場合、そのトークン範囲を追加する処理は、Cassandra では Bigtable よりも複雑になります。
地理的レプリケーションと整合性
Bigtable と Cassandra では、地理的(マルチリージョン)レプリケーションと整合性の扱いが異なります。Cassandra クラスタは、ラックにグループ分けされた処理ノードで構成され、ラックはデータセンターにグループ分けされています。Cassandra では、構成したネットワーク トポロジ方針を使用して、データセンターの複数のホストに vnode レプリカをどのように分散するかを決定します。この方針では、Cassandra のルートを物理的なオンプレミス データセンターに当初デプロイされたデータベースとして公表します。また、この構成では、クラスタ内の各データセンターのレプリケーション係数も指定します。
Cassandra では、データセンターとラック構成を使用して、データレプリカのフォールト トレラントを向上させます。読み取りおよび書き込みオペレーション中に、トポロジでは、整合性の保証に必要な参加ノードが決定されます。クラスタを作成または拡張する場合、ノード、ラック、データセンターは手動で構成する必要があります。クラウド環境内での通常の Cassandra デプロイでは、クラウドゾーンをラック、クラウド リージョンをデータセンターとして扱います。
読み取りや書き込みのオペレーションごとの整合性の保証は、Cassandra のクォーラム コントロールを使用して調整できます。結果整合性の強度はオプションにより異なります。単一のレプリカノード(ONE)、単一データセンター レプリカノード マジョリティ(LOCAL_QUORUM)、またはすべてのデータセンターのすべてのレプリカノードのマジョリティ(QUORUM)を必要とする各オプションなどがあります。
Bigtable では、クラスタはゾーンリソースです。Bigtable インスタンスには単一のクラスタを含めることも、完全にレプリケートされたクラスタのグループを含めることもできます。インスタンス クラスタは、 Google Cloud が提供する任意のリージョンの、任意のゾーンの組み合わせに配置できます。インスタンス内のクラスタは、そのインスタンスの他のクラスタへの影響を最小限に抑えながら追加や削除できます。
Bigtable では、書き込みは(書き込んだものは読み取れる一貫性を有して)単一クラスタで実行され、最終的に他のインスタンス クラスタでも整合性が保たれます。個々のセルはタイムスタンプでバージョニングされるため、書き込みが失われることはなく、各クラスタは利用可能な最新のタイムスタンプを持つセルを提供します。
このサービスでは、クラスタの整合性ステータスが公開されます。テーブルレベルの整合性トークンを取得するメカニズムが、Cloud Bigtable API によって提供されます。このトークンを使用することで、トークンが作成される前にそのテーブルに対して行われたすべての変更が完全にレプリケートされたかどうかを確認できます。
トランザクション サポート
複雑な複数行トランザクションは、どちらのデータベースでもサポートされませんが、どちらも一定のトランザクションをサポートしています。
Cassandra の軽量トランザクション(LWT)方式では、単一パーティションの列の値の更新に対してアトミック性が提供されます。また、Cassandra には、行の読み取りオペレーションと値の比較が完了した後に書き込みを開始する compare と set のセマンティクスもあります。
Bigtable では、クラスタ内で完全に一貫した単一行の書き込みがサポートされます。単一行トランザクションは、読み取り - 変更 - 書き込みオペレーションと確認 - 変更オペレーションを通じてさらに有効性が向上します。マルチクラスタのルーティング アプリケーション プロファイルでは、単一行トランザクションはサポートされていません。
データモデル
Bigtable と Cassandra のどちらも、検索と範囲スキャンをサポートするテーブルに、行の一意の識別子を使用してデータを整理します。両システムは、NoSQL のワイドカラム型ストアに分類されます。
Cassandra では、主キーの定義および列の名前と型などの完全なテーブル スキーマを、CQL を使用してあらかじめ作成しておく必要があります。Cassandra の主キーは、必須のパーティション キーとオプションのクラスタキーで構成される一意の複合値です。パーティション キーは行のノード配置を決め、クラスタキーはパーティション内の並び順を決めます。スキーマを作成する際は、単一パーティション内での効率的なスキャンの実行と、大規模なパーティションの維持に関するシステムコストとの間に発生し得るトレードオフを認識する必要があります。
Bigtable では、テーブルを作成し、その列ファミリーを事前に定義することだけが必要です。テーブルの作成時には列が宣言されませんが、アプリケーション API 呼び出しでテーブルの行にセルを追加すると作成されます。
行キーは、Bigtable クラスタ全体で辞書順に並べられます。Bigtable 内のノードでは、ノードが対応するキー範囲(タブレットと呼ばれることが多く、スプリットとも呼ばれることもある)が自動的に調整されます。多くの場合、Bigtable の行キーは、ユーザーが選択した広く使用されている区切り文字(パーセント記号など)を使用して結合される複数のフィールド値で構成されます。分離する場合、個々の文字列コンポーネントは Cassandra 主キーのフィールドに似ています。
行キーの設計
Bigtable では、テーブル行の一意の識別子は行キーです。行キーは、1 つのテーブル全体で 1 つの一意の値にする必要があります。共通の区切り文字で区切られた異なる複数の要素を連結することで、マルチパート キーを作成できます。行キーによって、テーブル内でのグローバル データの並び順が決まります。各ノードに割り当てられているキー範囲は、Bigtable サービスによって動的に決められます。
パーティション キーのハッシュが行の配置を決定し、クラスタリング列が順序を決定する Cassandra とは異なり、Bigtable の行キーは、ノードの割り当てと順序付けの両方を備えています。Cassandra と同様、Bigtable においても、一緒に取得する行は一緒に保存されるように、行キーを設計する必要があります。ただし、Bigtable では、テーブルを使用する前に行キーの配置と順序付けを設計する必要はありません。
データ型
Bigtable サービスでは、クライアントが送信した列データ型が強制適用されることはありません。クライアント ライブラリには、バイト、UTF-8 エンコード文字列、ビッグ エンディアンのエンコードされた 64 ビット整数としてセル値を記述するヘルパー メソッドが用意されています(アトミックなインクリメント演算には、ビッグ エンディアンでエンコードされた整数が必要です)。
列ファミリー
Bigtable では、テーブル内で一緒に保存および取得される列は、列ファミリーによって決まります。各テーブルには少なくとも 1 つの列ファミリーが必要です(テーブルには多くの場合もっと多くの列ファミリーがあります。各テーブルの上限は 100 列ファミリーです)。アプリケーションがオペレーションで列ファミリーを使用できるようにするには、明示的に列ファミリーを作成しておく必要があります。
列修飾子
行キーでテーブルに保存される個々の値は、列修飾子と呼ばれるラベルに関連付けられます。列修飾子はラベルにすぎないため、列ファミリー内の列の数に実際の上限はありません。列修飾子は、Bigtable でアプリケーション データを表すためによく使用されます。
セル
Bigtable では、セルは行キーと列名の交差(列ファミリーと列修飾子を組み合わせた部分)です。各セルには、クライアントによって提供されるか、サービスによって自動的に適用される、タイムスタンプ付きの 1 つ以上の値が含まれます。古いセルの値は、列ファミリー レベルで構成されたガベージ コレクション ポリシーに基づいて再利用されます。
セカンダリ インデックス
Bigtable では、セカンダリ インデックスはサポートされていません。インデックスが必要な場合は、異なる行キーを持つ第 2 のテーブルを使用するテーブル設計を採用することをおすすめします。
クライアントの負荷分散とフェイルオーバー
Cassandra では、クライアントがリクエストの負荷分散を制御します。クライアント ドライバは、セッションの作成時に、構成の一部として、またはプログラムで指定されるポリシーを設定します。アプリケーションに最も近いデータセンターに関するそのポリシーは、クラスタによって通知されます。クライアントは、これらのデータセンターからノードを特定してオペレーションを実行します。
Bigtable サービスは、各オペレーションで提供されるパラメータ(アプリケーション プロファイル ID)に基づいて、宛先クラスタへの API 呼び出しを転送します。アプリケーション プロファイルは、Bigtable サービス内で維持され、プロファイルを選択していないクライアント オペレーションでは、デフォルトのプロファイルが使用されます。
Bigtable には、2 種類のアプリケーション プロファイル ルーティング ポリシー(単一クラスタとマルチクラスタ)があります。マルチクラスタ プロファイルは、オペレーションを、使用可能で最も近いクラスタに転送します。オペレーション ルーターの観点からは、同じリージョン内にあるクラスタは、等距離とみなされます。リクエストされたキー範囲を受け持つノードが過負荷になっている場合や、クラスタで一時的に利用できない場合、このプロファイル タイプにより自動フェイルオーバーが行われます。
Cassandra では、マルチクラスタ ポリシーにより、データセンターで認識されている負荷分散ポリシーのフェイルオーバーが提供されます。
単一クラスタ ルーティングを持つアプリケーション プロファイルでは、すべてのトラフィックが 1 つのクラスタに転送されます。強力な行整合性と単一行トランザクションは、単一クラスタ ルーティングを使用するプロファイルでのみ使用できます。
単一クラスタ方式の欠点は、フェイルオーバーにおいて、アプリケーションが別のアプリケーション プロファイル ID を使用して再試行する必要があることや、影響を受ける単一クラスタ ルーティング プロファイルのフェイルオーバーを手動で実行する必要があることです。
オペレーション ルーティング
Cassandra と Bigtable では、読み取りおよび書き込みオペレーションの処理ノードを選択するために、異なるメソッドが使用されます。Cassandra ではパーティション キーが特定され、Bigtable では行キーが使用されます。
Cassandra では、クライアントはまず負荷分散ポリシーを検査します。このクライアント側オブジェクトによって、オペレーションが転送されるデータセンターが決まります。
データセンターが特定されると、Cassandra はコーディネーター ノードにアクセスしてオペレーションを管理します。ポリシーがトークンを認識する場合、コーディネーターはターゲット vnode パーティションからデータを提供するノードです。トークンを認識しない場合、コーディネーターはランダムなノードです。コーディネーター ノードは、オペレーション パーティション キーのデータ レプリカが存在するノードを識別し、そのオペレーションを実行するようにそれらのノードに指示します。
Bigtable では、前述のように、各オペレーションにアプリケーション プロファイル ID が含まれています。アプリケーション プロファイルは、サービスレベルで定義されます。Bigtable ルーティング レイヤでは、プロファイルを検査して、オペレーションに適した宛先クラスタを選択します。つづいて、オペレーションの行キーを使用してオペレーションが正しい処理ノードに到達するためのパスを提供します。
データの書き込みプロセス
どちらのデータベースも高速書き込み用に最適化されており、同様のプロセスを使用して書き込みを行います。ただし、データベースでの手順は若干異なります。特に Cassandra のオペレーションの整合性レベルによっては、追加のパーティシパント ノードとの通信が必要になる場合があります。
書き込みリクエストが適切な複数のノード(Cassandra)や 1 つのノード(Bigtable)に転送されると、書き込みデータは、まず commit ログ(Cassandra)または共有ログ(Bigtable)のディスクに順次保持されます。次に、書き込みは、SSTable のように順序付けられたメモリ内テーブル(memtable とも呼ばれます)に挿入されます。
上述の 2 つの処理の後、書き込みが完了したことを示すレスポンスがノードによって返されます。Cassandra では、コーディネーターが書き込みが完了したことをクライアントに通知する前に、複数のレプリカが(各オペレーションで指定された整合性レベルに応じて)応答する必要があります。Bigtable では、各行のノードが一度に 1 つのノードのみに割り当てられるため、書き込みが成功したかどうかを確認に必要なものは、ノードからのレスポンスだけです。
必要であれば、後で memtable を新しい SSTable の形式でディスクにフラッシュできます。Cassandra では、commit ログが最大サイズに達するか、memtable が構成したしきい値を超えるとフラッシュが発生します。Bigtable では、memtable がサービスで指定された最大サイズに到達すると、新しいimmutableの SSTable の作成を行うためのフラッシュが開始されます。定期的に、コンパクション プロセスで、指定したキー範囲の SSTable が 1 つの SSTable にマージされます。
データの更新
データの更新は、どちらのデータベースでも同じように処理されます。ただし、Cassandra が各セルに対して 1 つの値しか使用できない一方で、Bigtable では各セルに対してバージョニングされた値を大量に保持できます。
一意の行識別子と列が交差する値が変更されると、データ書き込みプロセスセクションで説明したように、更新が保持されます。書き込みタイムスタンプは、SSTable 構造内の値と一緒に保存されます。
更新されたセルを SSTable にフラッシュしていない場合は、memtable にセル値のみを保存できますが、データベースは保存されている内容によって異なります。Cassandra では memtable の最新値のみが保存されますが、Bigtable では memtable のすべてのバージョンが保存されます。
また、別の SSTable で 1 つ以上のバージョンのセル値をディスクにフラッシュした場合、データベースではそのデータのリクエストの処理方法が異なります。セルが Cassandra からリクエストされた場合は、タイムスタンプに従って最新の値のみが返されます。つまり、最後の書き込みが優先されます。Bigtable では、フィルタを使用して、読み取りリクエストで返されるセルのバージョンを制御します。
行の削除
どちらのデータベースも、不変の SSTable ファイルを使用してディスクにデータを保持しているため、すぐに行を削除することはできません。行が削除された後にクエリが正しい結果を返すようにするには、両方のデータベースが同じ仕組みを使用して削除を処理するようにします。まず、マーカー(Cassandra では tombstone と呼ばれます)が memtable に追加されます。最終的に、新しく書き込まれた SSTable では、一意の行識別子が削除され、クエリ結果で返されないことを示すタイムスタンプ付きのマーカーが含まれます。
有効期間
2 つのデータベースの有効期間(TTL)機能は、1 つの相違を除いて類似しています。Cassandra では、列またはテーブルに TTL を設定できますが、Bigtable では TTL は列ファミリーに対してのみ設定できます。Bigtable には、セルレベルの TTL をシミュレートできるメソッドは存在します。
ガベージ コレクション
前述したように、不変の SSTable では、即時にデータの更新や削除ができないため、プロセス中のガベージ コレクション(コンパクション)が行われます。このプロセスでは、クエリ結果に対応しないセルや行が削除されます。
ガベージ コレクション プロセスでは、SSTable をマージするときに、行やセルを除外します。行にマーカーや tombstone がある場合、結果の SSTable にその行は含まれません。セルは、どちらのデータベースでも、マージされた SSTable から除外できます。セルのタイムスタンプが TTL 条件を超えた場合、データベースはそのセルを除外します。特定のセルにタイムスタンプ付きのバージョンが 2 つある場合、Cassandra では、最新の値のみをマージされた SSTable に含めます。
データの読み取りパス
読み取りオペレーションが適切な処理ノードに到達すると、クエリ結果を満たすデータを取得するための読み取りプロセスは、両方のデータベースで同じになります。
クエリ結果を含む可能性のあるディスクの各 SSTable で、Bloom フィルタがチェックされ、返される行が各ファイルに含まれているかどうかが判定されます。Bloom フィルタでは偽陰性が発生しないことが保証されているため、すべての適格な SSTable が候補リストに追加され、その後の読み取り結果処理に含まれます。
読み取りオペレーションは、memtable から作成された結合ビューとディスク上の SSTable 候補を使用して実行されます。すべてのキーは、辞書順に並べられるため、スキャンされた結合ビューを取得してクエリ結果を取得する方が効率的です。
Cassandra では、オペレーションの整合性レベルによって決定される一連の処理ノードは、オペレーションに参加する必要があります。Bigtable では、キー範囲を担当するノードのみが利用される必要があります。Cassandra では、それぞれの読み取りは複数のノードで処理される可能性が高いため、コンピューティングのサイズへの影響を考慮する必要があります。
読み取り結果は、処理ノードで若干異なる方法で制限できます。Cassandra では、CQL クエリの WHERE 句で返される行が制限されます。この制限では、主キーまたはセカンダリ インデックス内の列を使用して結果を制限することがあります。
Bigtable では、読み取りクエリが取得する行またはセルに影響を与えるフィルタの豊富な組み合わせを提供します。
フィルタには、次の 3 つのカテゴリがあります。
- 制限フィルタ。レスポンスに含める行またはセルを制御します。
- 変更フィルタ。個別のセルのデータまたはメタデータに影響します。
- 合成フィルタ。複数のフィルタを 1 つに結合できます。
制限フィルタは最も広く使用され、列ファミリーの正規表現や列修飾子の正規表現などがあります。
物理データ ストレージ
Bigtable と Cassandra はどちらも、SSTable にデータを保存し、コンパクション フェーズで定期的にマージされます。SSTable データ圧縮を使用すると、ストレージ サイズの縮小と同様のメリットが得られます。ただし、圧縮は、Bigtable では自動的に適用され、Cassandra では構成オプションです。
2 つのデータベースを比較する場合は、次の点において異なった方法で、各データベースでデータが物理的にどのように保存されるかを理解する必要があります。
- データの分散方法
- 利用可能なセルバージョンの数
- ストレージ ディスクタイプ
- データの耐久性とレプリケーションの仕組み
データの分散
Cassandra では、主キーのパーティション列の一貫したハッシュが、クラスタノードで配信されるさまざまな SSTable 全体でのデータ分散を決定するために推奨される方法です。
Bigtable では、SSTable に辞書順にデータを配置するために、完全な行キーに対して変数の接頭辞を使用します。
セルのバージョン
Cassandra では、有効なセル値のバージョンが 1 つだけ保持されます。1 つのセルに対して 2 つの書き込みが行われる場合、最後の書き込みを優先するポリシーによって、1 つの値のみが返されるようになります。
Bigtable では、各セルのタイムスタンプ付きバージョンの数は制限されません。他の行サイズの上限が適用される場合があります。クライアント リクエストで設定しない場合、タイムスタンプは、処理ノードがミューテーションを受け取った時点で Bigtable サービスによって決定されます。セルのバージョンは、各テーブルの列ファミリーごとに異なる可能性のあるガベージ コレクション ポリシーを使用してプルーニングできます。また、API を使用したクエリ結果のセットからフィルタリングすることもできます。
ディスク ストレージ
Cassandra では、各クラスタノードにアタッチされているディスクに SSTable を保存します。Cassandra 内のデータを再調整するには、サーバー間でファイルを物理的にコピーする必要があります。
Bigtable では、Colossus を使用して SSTable を保存します。Bigtable では、この分散ファイル システムを使用するため、Bigtable サービスは、ほとんど間を置かずに別のノードに SSTable を再割り当てできます。
データの耐久性とレプリケーション
Cassandra はレプリケーション係数設定を使用してデータの耐久性を実現します。レプリケーション係数によって、クラスタ内の異なるノードに保存されている SSTable コピーの数が決まります。レプリケーション係数の一般的な設定は 3 です。これにより、ノードに障害が発生した場合でも QUORUM や LOCAL_QUORUM とのより強い整合性保証が継続して得られます。
Bigtable では、高いデータ耐久性保証が Colossus が提供するレプリケーションを通じて提供されます。
次の図は、Bigtable の物理データ レイアウト、コンピューティング処理ノード、ルーティング レイヤを示しています。

Colossus ストレージ レイヤでは、一連の SSTable に保存されているデータを処理するように各ノードが割り当てられます。これらの SSTable には、各ノードに動的に割り当てられる行キー範囲のデータが含まれています。この図では、ノードごとに 3 つの SSTable が示されていますが、ノードがデータに対する新しい変更を受け取るたびに SSTable が継続的に作成されるため、さらに多くの SSTable が存在する場合があります。
各ノードには共有ログがあります。各ノードで処理された書き込みは、クライアントが書き込み確認応答を受け取る前に直ちに共有ログに保存されます。Colossus への書き込みは、繰り返しレプリケートされるため、行範囲の SSTable にデータが保存される前にノードのハードウェア障害が発生した場合でも、耐久性が保証されます。
アプリケーション インターフェース
当初、Cassandra データベースへのアクセスは、Thrift API を使用して公開されましたが、この方法によるアクセスは非推奨になりました。CQL を通じたクライアント インタラクションを推奨します。
Cassandra の元の Thrift API と同様、Bigtable データベース アクセスは、指定された行キーに基づいてデータの読み取りと書き込みを行う API によって実現されます。
Cassandra のように、Bigtable には、cbt CLI というコマンドライン インターフェースと、多くの一般的なプログラミング言語をサポートするクライアント ライブラリの両方があります。これらのライブラリは、gRPC API と REST API の上に構築されています。Hadoop 用に記述され、Java 用のオープンソースの Apache HBase ライブラリを使用するアプリケーションは、大きな変更を行わずに Bigtable に接続できます。HBase の互換性が不要なアプリケーションでは、組み込みの Bigtable Java クライアントを使用することをおすすめします。
Bigtable の Identity and Access Management(IAM)制御は、 Google Cloudに完全に統合されており、BigQuery から外部データソースとしてテーブルを使用することもできます。
データベースの設定
Cassandra クラスタを設定する際には、いくつかの構成に関する意思決定を行い、手順を実行する必要があります。まず、サーバーノードを構成して、コンピューティング容量を確保し、ローカル ストレージをプロビジョニングする必要があります。3 つのレプリケーション係数を使用する場合、最もよく使用されている推奨の設定では、クラスタで保持する想定の 3 倍のデータ量を保存するストレージをプロビジョニングする必要があります。また、vnodes、ラック、レプリケーションの構成を決定し、設定する必要があります。
Bigtable では、ストレージとコンピューティングが分離されていることにより、Cassandra と比較してクラスタのスケールアップとスケールダウンが簡素化されています。通常運用されているクラスタで一般的に考慮するべきなのは、マネージド テーブルによって使用されている合計ストレージ量です。これにより、最小のノード数が決定され、現在の QPS を維持するのに十分なノードを確保できます。
本番環境の負荷に対してクラスタが過剰にプロビジョニングされている場合や、プロビジョニングが不足している場合は、Bigtable クラスタのサイズを速やかに調整できます。
Bigtable ストレージ
Bigtable インスタンスを作成する際は、初期クラスタの地理的位置のほか、ストレージ タイプを選択する必要があります。Bigtable のストレージには、ソリッド ステート ドライブ(SSD)とハードディスク ドライブ(HDD)の 2 つの選択肢が用意されています。インスタンス内のすべてのクラスタは、同じストレージ タイプを共有する必要があります。
Bigtable でストレージのニーズを検討する際は、Cassandra クラスタのサイズを設定する場合と同様、ストレージ レプリカを考慮する必要はありません。Cassandra のように、フォールト トレランスを実現するためにストレージの密度が失われることはありません。また、ストレージを明示的にプロビジョニングする必要がないため、使用中のストレージに対してのみ課金されます。
SSD
ほとんどのワークロードで推奨される SSD ノードの容量である 5 TB は、各ノードの実効最大ストレージ密度が 2 TB 未満である Cassandra マシンの推奨構成と比較して高いストレージ密度を提供しています。ストレージ容量のニーズを評価する際は、Bigtable ではデータのコピーが 1 つのみカウントされることに注意してください。これに対して、Cassandra はほとんどの構成で 3 つのデータのコピーを考慮する必要があります。
SSD の書き込み QPS は HDD とほぼ同じですが、SSD の方が HDD よりも読み取り QPS が大幅に優れています。SSD ストレージの料金は、プロビジョニングされた SSD 永続ディスクの料金に近い料金設定がされており、リージョンによって異なります。
HDD
HDD ストレージ タイプでは、ノードあたり 16 TB という密度がかなり大きいストレージを使用できます。それと引き換えランダム読み取りは大幅に遅く、ノードごとに 1 秒あたり 500 行の読み取りしかサポートされません。HDD は、読み取りがバッチ処理に関連する範囲スキャンであることが想定される、書き込み頻度が高いワークロードに適しています。HDD ストレージの料金は、Cloud Storage に関連する料金に近い料金設定がされており、リージョンによって異なります。
クラスタサイズに関する考慮事項
Cassandra ワークロードの移行に備えて Bigtable インスタンスのサイズを調整する際は、単一データセンターの Cassandra クラスタを単一クラスタの Bigtable インスタンスと比較する場合と、マルチデータ センターの Cassandra クラスタをマルチクラスタの Bigtable インスタンスと比較する場合の考慮事項があります。以下のガイドラインでは、移行のためにデータモデルを大きく変更する必要はなく、Cassandra と Bigtable の間で同等のストレージ圧縮が行われていることを前提とします。
単一のデータセンターのクラスタ
単一データセンターのクラスタを単一クラスタの Bigtable インスタンスと比較する場合は、まずストレージ要件を考慮する必要があります。各キースペースの複製されていないサイズを見積もるには、nodetool tablestats コマンドを使用し、フラッシュされた合計ストレージ サイズをキースペースのレプリケーション係数で除算します。次に、すべてのキースペースの複製されていないストレージ量を 3.5 TB(5 TB × .70)で割って、ストレージを単独で処理するための SSD ノードの推奨数を決定します。前述したように、Bigtable では、ユーザーにとって透過的な別個の階層内のストレージ レプリケーションと耐久性を扱います。
次に、ノード数のコンピューティング要件を検討する必要があります。Cassandra サーバーとクライアント アプリケーションの指標を調べることで、実行された持続的な読み取りと書き込みのおおよその数を取得できます。ワークロードを実行する SSD ノードの最小数を見積もるには、その指標を 10,000 で割ります。低レイテンシ クエリの結果を必要とするアプリケーションでは、より多くのノードが必要になる可能性があります。ワークロードで実現可能なノード単位の QPS の指標を設定するには、代表的なデータとクエリを使って Bigtable のパフォーマンスをテストすることをおすすめします。
クラスタに必要なノード数は、ストレージで必要な数とコンピューティングで必要な数のうちの大きい方にする必要があります。保存容量やスループットのニーズが不確かな場合は、Bigtable ノードの数と標準的な Cassandra マシンの数を一致させます。Bigtable クラスタをスケールアップまたはスケールダウンして、ワークロードのニーズが最小限の労力とゼロ ダウンタイムに一致するようにします。
マルチ データセンターのクラスタ
複数データセンターからなるクラスタでは、Bigtable インスタンスの構成を決定することがより難しくなります。Cassandra トポロジ内のすべてのデータセンター用のインスタンスにクラスタを配置することをおすすめします。インスタンスの各 Bigtable クラスタでは、インスタンス内のすべてのデータを保存する必要があり、クラスタ全体の挿入速度に対応できる必要があります。インスタンス内のクラスタは、世界中のサポートされているクラウド リージョンに作成できます。
ストレージのニーズを見積もる手法は、単一データセンター クラスタの方法に似ています。nodetool を使用して、Cassandra クラスタ内の各キースペースのストレージ サイズを取得し、そのサイズをレプリカの数で割ります。テーブルのキースペースでは、データセンターごとにレプリケーション係数が異なる可能性があるので注意してください。
クラスタの停止中にサービスレベル目標(SLO)を維持するためには、インスタンス内の各クラスタのノードの数で、クラスタ全体でのすべての書き込みと、2 つ以上のデータセンターへのすべての読み取りを処理できる必要があります。一般的なアプローチは、Cassandra クラスタ内で最もビジーなデータセンターと同等のノード容量を持つすべてのクラスタで開始することです。インスタンス内の Bigtable クラスタは、ワークロードのニーズをゼロ ダウンタイムに一致させるために、個別にスケールアップまたはスケールダウンできます。
管理
Bigtable は、Cassandra で実行される共通の管理機能用のフルマネージド コンポーネントを備えています。
バックアップと復元
Bigtable では、Bigtable バックアップとマネージド データ エクスポートという 2 つの一般的なバックアップ ニーズに対応しています。
Bigtable のバックアップは、Cassandra の nodetool スナップショット機能のマネージド バージョンと同じように考えることができます。Bigtable のバックアップでは、クラスタのメンバー オブジェクトとして保存する、テーブルの復元可能なコピーが作成されます。バックアップを開始したクラスタ内の新しいテーブルとしてバックアップを復元できます。このバックアップは、アプリケーション レベルの破損が発生したときに復元ポイントを作成するように設計されています。このユーティリティを使用して作成するバックアップは、ノードリソースを消費せず、Cloud Storage の料金に近い料金設定がされています。Bigtable のバックアップは、プログラムや Bigtable の Google Cloud コンソールから呼び出せます。
Bigtable をバックアップする別の方法には、Cloud Storage へのマネージド データ エクスポートを使用する手法もあります。Avro、Parquet、または Hadoop のシーケンス ファイル形式にエクスポートできます。Bigtable バックアップと異なり、エクスポートでは Dataflow を使用するため、エクスポートの実行に時間がかかり、追加のコンピューティング料金が発生します。ただし、このエクスポートを行うと、オフラインでのクエリ実行や、別のシステムへのインポートができるポータブル データファイルが作成されます。
サイズ変更
Bigtable では、ストレージとコンピューティングが分離されるため、クエリに対する需要に応じて Cassandra におけるよりもシームレスに Bigtable ノードを追加または削除できます。Cassandra の同種のアーキテクチャでは、クラスタ内のマシン間でノード(または vnode)を再調整する必要があります。
クラスタサイズは、Google Cloud コンソールから手動で変更するか、Cloud Bigtable API を使用してプログラムで変更できます。クラスタにノードを追加すると、数分でパフォーマンスが大きく向上します。一部のお客様において、オープンソースの Spotify が開発したオートスケーラーがうまく使用されています。
内部メンテナンス
Bigtable サービスは、OS のパッチ適用、ノードの復旧、ノードの修復、ストレージ コンパクションのモニタリング、SSL 証明書のローテーションなどの一般的な Cassandra 内部メンテナンス タスクをシームレスに処理します。
モニタリング
Bigtable を指標の可視化やアラートに接続すると、管理や開発の手間がかかりません。Bigtable の Google Cloud コンソールのページには、インスタンス、クラスタ、テーブルレベルでスループットと使用率の指標を追跡する事前構築されたダッシュボードが用意されています。カスタムビューとアラートは、Cloud Monitoring ダッシュボードで作成できます。ここでは自動的に指標が利用可能になります。
Google Cloud コンソールのモニタリング機能である Bigtable Key Visualizer を使用すると、高度なパフォーマンス調整を行うことができます。
IAM とセキュリティ
Bigtable では、承認はGoogle Cloudの IAM フレームワークに完全に統合されており、必要な設定とメンテナンスは最小限です。ローカル ユーザー アカウントとパスワードはクライアント アプリケーションと共有されません。代わりに、組織レベルのユーザーとサービス アカウントにきめ細かい権限とロールが付与されます。
BigQuery ではすべての保存データと転送中データが自動的に暗号化されます。この機能は、無効にできません。すべての管理者アクセスは、すべてログに記録されます。VPC Service Controls を使用すると、Bigtable インスタンスへの承認済みネットワークの外部からのアクセスを制御できます。
次のステップ
- Bigtable のスキーマ設計について確認する。
- Cassandra ユーザー向け Bigtable の Codelab を試す。
- Bigtable エミュレータについて確認する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。