Este documento destina-se a programadores de software e administradores de bases de dados que querem migrar aplicações existentes ou criar novas aplicações para utilização com o Bigtable como um arquivo de dados. Este documento aplica os seus conhecimentos sobre o Apache Cassandra à utilização do Bigtable para descrever conceitos que deve compreender antes da migração. Para ver informações sobre ferramentas de código aberto que pode usar para concluir a migração, consulte o artigo Migrar do Cassandra para o Bigtable.
O Bigtable e o Cassandra são bases de dados distribuídas. Implementam armazenamentos de chave-valor multidimensionais que podem suportar dezenas de milhares de consultas por segundo (CPS), armazenamento que é dimensionado até petabytes de dados e tolerância a falhas de nós.
Quando é que o Bigtable é um bom destino para cargas de trabalho do Cassandra
O melhor Google Cloud serviço para a sua carga de trabalho do Cassandra depende dos seus objetivos de migração e da funcionalidade do Cassandra de que precisa após a migração.
Se uma ou mais das seguintes condições se aplicarem, o Bigtable é ideal:
- Quer um serviço totalmente gerido sem janelas de manutenção e com elevada disponibilidade.
- Precisa de um dimensionamento elástico que responda automaticamente às alterações no tráfego do servidor.
- Usar tipos de coleções, contadores ou vistas materializadas do Cassandra, além dos tipos escalares.
- Tem uma aplicação que usa o parâmetro
USING TIMESTAMP. - A taxa de transferência de escrita e a latência são tão importantes como as leituras.
- Confia num dos modelos de replicação eventualmente consistentes do Cassandra.
- O seu exemplo de utilização requer armazenamento rentável.
Para migrar aplicações sem alterações ao código, pode optar por gerir o Cassandra de forma autónoma no GKE ou usar um Google Cloud parceiro, como a DataStax ou a ScyllaDB. Se a sua aplicação for de leitura intensiva e quiser refatorar o seu código para obter capacidades de base de dados relacional e uma forte consistência, pode considerar o Spanner.
Este documento fornece sugestões sobre o que ter em consideração ao refatorizar a sua aplicação, se escolher o Bigtable como o destino da migração para as suas cargas de trabalho do Cassandra.
Como usar este documento
Não precisa de ler este documento do início ao fim. Embora este documento forneça uma comparação das duas bases de dados, também pode focar-se em tópicos que se aplicam ao seu exemplo de utilização ou interesses.
Para ajudar a comparar o Bigtable e o Cassandra, este documento faz o seguinte:
- Compara a terminologia, que pode diferir entre as duas bases de dados.
- Fornece uma vista geral dos dois sistemas de base de dados.
- Analisa a forma como cada base de dados processa a modelagem de dados para compreender diferentes considerações de design.
- Compara o caminho percorrido pelos dados durante as gravações e as leituras.
- Examina a disposição física dos dados para compreender aspetos da arquitetura da base de dados.
- Descreve como configurar a replicação geográfica para cumprir os seus requisitos e como abordar o dimensionamento do cluster.
- Reveja os detalhes sobre a gestão, a monitorização e a segurança de clusters.
Comparação de terminologia
Embora muitos dos conceitos usados no Bigtable e no Cassandra sejam semelhantes, cada base de dados tem convenções de nomenclatura ligeiramente diferentes e diferenças subtis.
Um dos elementos essenciais de ambas as bases de dados é a tabela de strings ordenadas (SSTable). Em ambas as arquiteturas, as SSTables são criadas para persistir os dados que são usados para responder a consultas de leitura.
Numa publicação no blogue (2012), Ilya Grigorik escreveu o seguinte: "Uma SSTable é uma abstração simples para armazenar eficientemente um grande número de pares chave-valor, ao mesmo tempo que otimiza o elevado débito, as cargas de trabalho de leitura ou escrita sequenciais."
A tabela seguinte descreve os conceitos partilhados e a terminologia correspondente que cada produto usa:
| Cassandra | Bigtable |
|---|---|
|
chave primária: um valor único de um ou vários campos que determina o posicionamento e a ordenação dos dados. partition key: um valor de campo único ou múltiplo que determina o posicionamento dos dados por hash consistente. coluna de agrupamento: um valor de campo único ou múltiplo que determina a ordenação lexicográfica dos dados numa partição. |
Chave da linha: uma string de bytes única que determina o posicionamento dos dados por uma ordenação lexicográfica. As chaves compostas são imitadas juntando os dados de várias colunas através de um delimitador comum, por exemplo, os símbolos de cardinal (#) ou percentagem (%). |
| node: uma máquina responsável por ler e escrever dados associados a uma série de intervalos de hash de partições de chaves primárias. No Cassandra, os dados são armazenados no armazenamento ao nível do bloco anexado ao servidor de nós. | node: um recurso de computação virtual responsável por ler e escrever dados associados a uma série de intervalos de chaves de linhas. No Bigtable, os dados não estão localizados juntamente com os nós de computação. Em alternativa, é armazenado no Colossus, o sistema de ficheiros distribuído da Google. Os nós recebem responsabilidade temporária pela publicação de vários intervalos de dados com base na carga de operações e no estado de funcionamento de outros nós no cluster. |
|
Centro de dados: semelhante a um cluster do Bigtable, exceto que alguns aspetos da topologia e da estratégia de replicação são configuráveis no Cassandra. rack: um agrupamento de nós num centro de dados que influencia o posicionamento de réplicas. |
cluster: um grupo de nós na mesma zona geográfica, colocados para resolver problemas de latência e replicação.Google Cloud |
| cluster: uma implementação do Cassandra que consiste numa coleção de centros de dados. | instância: um grupo de clusters do Bigtable em diferentes Google Cloud zonas ou regiões entre os quais ocorre a replicação e o encaminhamento de ligações. |
| vnode: um intervalo fixo de valores de hash atribuídos a um nó físico específico. Os dados num vnode são armazenados fisicamente no nó do Cassandra numa série de SSTables. | tablet: uma SSTable que contém todos os dados para um intervalo contíguo de chaves de linhas ordenadas lexicograficamente. As tabelas não são armazenadas em nós no Bigtable, mas são armazenadas numa série de SSTables no Colossus. |
| Fator de replicação: o número de réplicas de um vnode que são mantidas em todos os nós no centro de dados. O fator de replicação é configurado de forma independente para cada centro de dados. | Replicação: o processo de replicação dos dados armazenados no Bigtable para todos os clusters na instância. A replicação num cluster zonal é processada pela camada de armazenamento do Colossus. |
| tabela (anteriormente família de colunas): uma organização lógica de valores indexada pela chave primária exclusiva. | tabela: uma organização lógica de valores indexados pela chave de linha exclusiva. |
| keyspace: um espaço de nomes de tabelas lógico que define o fator de replicação para as tabelas que contém. | Não aplicável. O Bigtable processa as preocupações com o espaço de chaves de forma transparente. |
| map: um tipo de coleção do Cassandra que contém pares de chave-valor. | Família de colunas: um espaço de nomes especificado pelo utilizador que agrupa qualificadores de colunas para leituras e escritas mais eficientes. Quando consulta o Bigtable através de SQL, as famílias de colunas são tratadas como mapas do Cassandra. |
| map key: chave que identifica de forma exclusiva uma entrada de chave-valor num mapa do Cassandra | qualificador de coluna: uma etiqueta para um valor armazenado numa tabela que é indexado pela chave de linha única. Quando consulta o Bigtable através de SQL, as colunas são tratadas como chaves de um mapa. |
| coluna: a etiqueta de um valor armazenado numa tabela que é indexada pela chave principal única. | coluna: a etiqueta de um valor armazenado numa tabela que é indexada pela chave de linha exclusiva. O nome da coluna é construído combinando a família de colunas com o qualificador de coluna. |
| célula: um valor de data/hora numa tabela associado à interseção de uma chave principal com a coluna. | célula: um valor de data/hora numa tabela associado à interseção de uma chave de linha com o nome da coluna. Podem ser armazenadas e obtidas várias versões com indicação de data/hora para cada célula. |
| counter: um tipo de campo incrementável otimizado para operações de soma de números inteiros. | contadores: células que usam tipos de dados especializados para operações de soma de números inteiros. Para mais informações, consulte o artigo Crie e atualize contadores. |
| Política de equilíbrio de carga: uma política que configura na lógica da aplicação para encaminhar operações para um nó adequado no cluster. A política tem em conta a topologia do centro de dados e os intervalos de tokens de nós virtuais. | perfil da aplicação: definições que indicam ao Bigtable como encaminhar uma chamada API de cliente para o cluster adequado na instância. Também pode usar o perfil da aplicação como uma etiqueta para segmentar métricas. Configura o perfil da aplicação no serviço. |
| CQL: a Cassandra Query Language, uma linguagem semelhante ao SQL que é usada para a criação de tabelas, alterações de esquemas, mutações de linhas e consultas. | O cliente Cassandra para Java é uma substituição perfeita para os seus controladores Cassandra. O cliente Java compreende as suas consultas CQL e permite-lhe usar o Bigtable de forma transparente com a sua aplicação baseada em Cassandra existente sem reescrever o código. O adaptador de proxy do Cassandra para o Bigtable é uma camada autónoma que pode executar em paralelo com a sua aplicação e estabelecer ligação ao Bigtable como outro nó do Cassandra. O adaptador de proxy oferece compatibilidade com CQL e suporta a gravação dupla e as migrações em massa. Esta funcionalidade é semelhante à que o cliente do Cassandra para o Bigtable para Java oferece. As APIs Bigtable são as bibliotecas de cliente e as APIs gRPC usadas para a criação de instâncias e clusters, a criação de tabelas e famílias de colunas, a mutação de linhas e a execução de consultas. A API SQL do Bigtable é familiar para os utilizadores do CQL. |
Vista materializada: uma declaração SELECT que define um conjunto de linhas que corresponde a linhas numa tabela de origem subjacente. Quando a tabela de origem muda, o Cassandra atualiza automaticamente a vista materializada.
|
vista materializada contínua: um resultado pré-calculado totalmente gerido de uma consulta SQL que é atualizado de forma incremental e automática a partir de uma tabela de origem. Para mais informações, consulte o artigo Vistas materializadas contínuas. |
Vistas gerais de produtos
As secções seguintes oferecem uma vista geral da filosofia de design e dos principais atributos do Bigtable e do Cassandra.
Bigtable
O Bigtable oferece muitas das funcionalidades principais descritas no artigo Bigtable: A Distributed Storage System for Structured Data. O Bigtable separa os nós de computação, que atendem aos pedidos dos clientes, da gestão de armazenamento subjacente. Os dados são armazenados no Colossus. A camada de armazenamento replica automaticamente os dados para oferecer uma durabilidade que excede os níveis fornecidos pela replicação tripla do Hadoop Distributed File System (HDFS) padrão.
Esta arquitetura oferece leituras e escritas consistentes num cluster, é escalável para cima e para baixo sem custos de redistribuição de armazenamento e pode reequilibrar as cargas de trabalho sem modificar o cluster nem o esquema. Se algum nó de processamento de dados ficar danificado, o serviço Bigtable substitui-o de forma transparente. O Bigtable também suporta a replicação assíncrona.
Além do gRPC e das bibliotecas cliente para várias linguagens de programação, o Bigtable mantém a compatibilidade com a HBase de código aberto do Apache, uma implementação alternativa do motor de base de dados de código aberto do artigo do Bigtable.
O diagrama seguinte mostra como o Bigtable separa fisicamente os nós de processamento da camada de armazenamento:
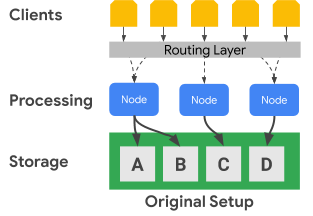
No diagrama anterior, o nó de processamento intermédio só é responsável por servir pedidos de dados para o conjunto de dados C na camada de armazenamento. Se o Bigtable identificar que é necessário reequilibrar a atribuição de intervalos para um conjunto de dados, os intervalos de dados de um nó de processamento são fáceis de alterar porque a camada de armazenamento está separada da camada de processamento.
O diagrama seguinte mostra, em termos simplificados, um reequilíbrio do intervalo de chaves e uma alteração do tamanho do cluster:
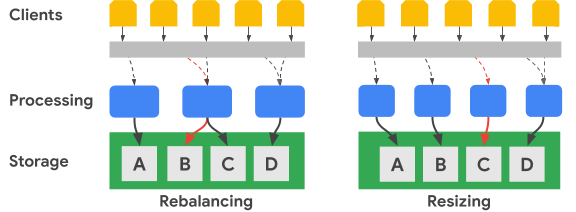
A imagem Reequilibrar ilustra o estado do cluster do Bigtable depois de o nó de processamento mais à esquerda receber um número aumentado de pedidos para o conjunto de dados A. Após o reequilíbrio, o nó do meio, em vez do nó mais à esquerda, é responsável por processar pedidos de dados para o conjunto de dados B. O nó mais à esquerda continua a processar pedidos para o conjunto de dados A.
O Bigtable pode reorganizar os intervalos de chaves de linhas para equilibrar os intervalos do conjunto de dados num número aumentado de nós de processamento disponíveis. A imagem de redimensionamento mostra o estado do cluster do Bigtable depois de adicionar um nó.
Cassandra
O Apache Cassandra é uma base de dados de código aberto parcialmente influenciada por conceitos do artigo do Bigtable. Usa uma arquitetura de nós distribuídos, onde o armazenamento está localizado juntamente com os servidores que respondem às operações de dados. Uma série de nós virtuais (vnodes) são atribuídos aleatoriamente a cada servidor para publicar uma parte do espaço de chaves do cluster.
Os dados são armazenados nos vnodes com base na chave de partição. Normalmente, é usada uma função hash consistente para gerar um token para determinar o posicionamento dos dados. Tal como no Bigtable, pode usar um particionador que preserve a ordem para a geração de tokens e, por conseguinte, também para o posicionamento de dados. No entanto, a documentação do Cassandra desaconselha esta abordagem porque o cluster vai provavelmente ficar desequilibrado, uma condição difícil de corrigir. Por este motivo, este documento pressupõe que usa uma estratégia de hash consistente para gerar tokens que resultam na distribuição de dados entre nós.
O Cassandra oferece tolerância a falhas através de níveis de disponibilidade que estão correlacionados com o nível de consistência ajustável, o que permite que um cluster sirva clientes enquanto um ou mais nós estão danificados. Define a replicação geográfica através de uma estratégia de topologia de replicação de dados configurável.
Especifica um nível de consistência para cada operação. A definição típica é QUORUM (ou LOCAL_QUORUM em determinadas topologias de vários centros de dados). Esta definição do nível de consistência requer que a maioria dos nós de réplica responda ao nó coordenador para que a operação seja considerada bem-sucedida. O fator de replicação, que configura para cada espaço de chaves, determina o número de réplicas de dados armazenadas em cada centro de dados no cluster. Por exemplo, é
habitual usar um valor de fator de replicação de 3 para oferecer um equilíbrio prático
entre a durabilidade e o volume de armazenamento.
O diagrama seguinte mostra, em termos simplificados, um cluster de seis nós com o intervalo de chaves de cada nó dividido em cinco vnodes. Na prática, pode ter mais nós e, provavelmente, terá mais nós virtuais.

No diagrama anterior, pode ver o caminho de uma operação de escrita, com um nível de consistência de QUORUM, que tem origem numa aplicação cliente ou num serviço (Cliente). Para efeitos deste diagrama, os intervalos de chaves são apresentados como intervalos alfabéticos. Na realidade, os tokens produzidos por um hash da chave principal são números inteiros assinados muito grandes.
Neste exemplo, o hash da chave é M e os vnodes para M estão nos nós 2, 4 e 6. O coordenador tem de contactar cada nó onde os intervalos de hash das chaves estão armazenados localmente para que a gravação possa ser processada. Uma vez que o nível de consistência é QUORUM, duas réplicas (uma maioria) têm de responder ao nó coordenador antes de o cliente ser notificado de que a gravação está concluída.
Ao contrário do Bigtable, mover ou alterar intervalos de chaves no Cassandra requer que copie fisicamente os dados de um nó para outro. Se um nó estiver sobrecarregado com pedidos para um determinado intervalo de hash de tokens, adicionar o processamento para esse intervalo de tokens é mais complexo no Cassandra em comparação com o Bigtable.
Replicação geográfica e consistência
O Bigtable e o Cassandra processam a replicação e a consistência geográfica (também conhecida como multirregião) de forma diferente. Um cluster do Cassandra consiste em nós de processamento agrupados em racks, e os racks são agrupados em centros de dados. O Cassandra usa uma estratégia de topologia de rede que configura para determinar como as réplicas de vnode são distribuídas pelos anfitriões num centro de dados. Esta estratégia revela as origens do Cassandra como uma base de dados originalmente implementada em centros de dados físicos no local. Esta configuração também especifica o fator de replicação para cada centro de dados no cluster.
O Cassandra usa configurações de centro de dados e de racks para melhorar a tolerância a falhas das réplicas de dados. Durante as operações de leitura e escrita, a topologia determina os nós participantes necessários para fornecer garantias de consistência. Tem de configurar manualmente os nós, os racks e os centros de dados quando cria ou expande um cluster. Num ambiente de nuvem, uma implementação típica do Cassandra trata uma zona da nuvem como um rack e uma região da nuvem como um centro de dados.
Pode usar os controlos de quórum do Cassandra para ajustar as garantias de consistência para cada operação de leitura ou escrita. Os níveis de robustez da consistência eventual podem variar, incluindo opções que requerem um único nó de réplica (ONE), uma maioria de nós de réplica de um único centro de dados (LOCAL_QUORUM) ou uma maioria de todos os nós de réplica em todos os centros de dados (QUORUM).
No Bigtable, os clusters são recursos zonais. Uma instância do Bigtable pode conter um único cluster ou ser um grupo de clusters totalmente replicados. Pode colocar clusters de instâncias em qualquer combinação de zonas em todas as regiões que a Google Cloud oferece. Google Cloud Pode adicionar e remover clusters de uma instância com um impacto mínimo noutros clusters na instância.
No Bigtable, as escritas são realizadas (com consistência de leitura das suas escritas) num único cluster e são eventualmente consistentes nos outros clusters de instâncias. Uma vez que as células individuais têm versões com base na data/hora, não se perdem escritas, e cada cluster publica as células com as datas/horas mais atuais disponíveis.
O serviço expõe o estado de consistência do cluster. A Cloud Bigtable API oferece um mecanismo para obter um token de consistência ao nível da tabela. Pode usar este token para determinar se todas as alterações feitas a essa tabela antes da criação do token foram replicadas na totalidade.
Apoio técnico para transações
Embora nenhuma das bases de dados suporte transações complexas de várias linhas, cada uma tem algum suporte de transações.
O Cassandra tem um método de transação simples (LWT) que oferece atomicidade para atualizações de valores de colunas numa única partição. O Cassandra também tem semântica de comparação e definição que concluem a operação de leitura de linhas e a comparação de valores antes de iniciar uma escrita.
O Bigtable suporta escritas de linha única totalmente consistentes num cluster. As transações de linha única são ainda mais ativadas através das operações de leitura-modificação-escrita e verificação e mutação. Os perfis de aplicação de encaminhamento de vários clusters não suportam transações de linha única.
Modelo de dados
O Bigtable e o Cassandra organizam os dados em tabelas que suportam pesquisas e análises de intervalos através do identificador exclusivo da linha. Ambos os sistemas são classificados como armazenamentos de colunas largas NoSQL.
No Cassandra, tem de usar o CQL para criar o esquema completo da tabela antecipadamente, incluindo a definição da chave primária, juntamente com os nomes das colunas e os respetivos tipos. As chaves primárias no Cassandra são valores compostos únicos que consistem numa chave de partição obrigatória e numa chave de cluster opcional. A chave de partição determina o posicionamento do nó de uma linha e a chave de cluster determina a ordem de ordenação numa partição. Ao criar esquemas, tem de ter em atenção as potenciais compensações entre a execução de análises eficientes numa única partição e os custos do sistema associados à manutenção de partições grandes.
No Bigtable, só tem de criar a tabela e definir as respetivas famílias de colunas antecipadamente. As colunas não são declaradas quando as tabelas são criadas, mas são criadas quando as chamadas da API de aplicação adicionam células às linhas da tabela.
As chaves de linhas estão ordenadas lexicograficamente no cluster do Bigtable. Os nós no Bigtable equilibram automaticamente a responsabilidade nodal pelos intervalos de chaves, frequentemente denominados tablets e, por vezes, divisões. As chaves de linhas do Bigtable consistem frequentemente em vários valores de campos que são unidos através de um caráter separador usado frequentemente que escolhe (como um sinal de percentagem). Quando separados, os componentes individuais da string são análogos aos campos de uma chave primária do Cassandra.
Design da chave da linha
No Bigtable, o identificador exclusivo de uma linha de tabela é a chave da linha. A chave de linha tem de ser um valor único numa tabela inteira. Pode criar chaves compostas concatenando elementos distintos separados por um delimitador comum. A chave de linha determina a ordem de ordenação dos dados globais numa tabela. O serviço Bigtable determina dinamicamente os intervalos de chaves que são atribuídos a cada nó.
Ao contrário do Cassandra, em que o hash da chave de partição determina o posicionamento das linhas e as colunas de agrupamento determinam a ordenação, a chave de linha do Bigtable fornece a atribuição nodal e a ordenação. Tal como com o Cassandra, deve criar uma chave de linha no Bigtable para que as linhas que quer obter em conjunto sejam armazenadas em conjunto. No entanto, no Bigtable, não tem de criar a chave da linha para posicionamento e ordenação antes de usar uma tabela.
Tipos de dados
O serviço Bigtable não aplica os tipos de dados das colunas que o cliente envia. As bibliotecas de cliente fornecem métodos auxiliares para escrever valores de células como bytes, strings codificadas em UTF-8 e inteiros de 64 bits codificados em big-endian (são necessários inteiros codificados em big-endian para operações de incremento atómico).
Família de colunas
No Bigtable, uma família de colunas determina que colunas numa tabela são armazenadas e obtidas em conjunto. Cada tabela precisa de, pelo menos, uma família de colunas, embora as tabelas tenham frequentemente mais (o limite é de 100 famílias de colunas por tabela). Tem de criar explicitamente famílias de colunas antes de uma aplicação as poder usar numa operação.
Qualificadores de colunas
Cada valor armazenado numa tabela numa chave de linha está associado a uma etiqueta denominada qualificador de coluna. Uma vez que os qualificadores de colunas são apenas etiquetas, não existe um limite prático para o número de colunas que pode ter numa família de colunas. Os qualificadores de colunas são frequentemente usados no Bigtable para representar dados de aplicações.
Células
No Bigtable, uma célula é a interseção da chave da linha e do nome da coluna (uma família de colunas combinada com um qualificador de coluna). Cada célula contém um ou mais valores com indicação de data/hora que podem ser fornecidos pelo cliente ou aplicados automaticamente pelo serviço. Os valores das células antigas são recuperados com base numa política de recolha de lixo configurada ao nível da família de colunas.
Índices secundários
Pode usar vistas materializadas contínuas como índices secundários assíncronos para tabelas para consultar os mesmos dados usando diferentes padrões de pesquisa ou atributos. Para mais informações, consulte o artigo Crie um índice secundário assíncrono.
Balanceamento de carga e comutação por falha do cliente
No Cassandra, o cliente controla o equilíbrio de carga dos pedidos. O controlador do cliente define uma política especificada como parte da configuração ou programaticamente durante a criação da sessão. O cluster informa a política sobre os centros de dados mais próximos da aplicação, e o cliente identifica os nós desses centros de dados para prestar serviço a uma operação.
O serviço Bigtable encaminha as chamadas API para um cluster de destino com base num parâmetro (um identificador do perfil da aplicação) fornecido com cada operação. Os perfis de aplicação são mantidos no serviço Bigtable. As operações do cliente que não selecionam um perfil usam um perfil predefinido.
O Bigtable tem dois tipos de políticas de encaminhamento de perfis de aplicações: de cluster único e de vários clusters. Um perfil de vários clusters encaminha as operações para o cluster disponível mais próximo. Os clusters na mesma região são considerados equidistantes do ponto de vista do router de operações. Se o nó responsável pelo intervalo de chaves pedido estiver sobrecarregado ou temporariamente indisponível num cluster, este tipo de perfil oferece uma comutação por falha automática.
Em termos do Cassandra, uma política de vários clusters oferece as vantagens de comutação por falha de uma política de equilíbrio de carga que tem conhecimento dos centros de dados.
Um perfil de aplicação com encaminhamento de cluster único direciona todo o tráfego para um único cluster. A consistência forte das linhas e as transações de linha única só estão disponíveis em perfis com encaminhamento de cluster único.
A desvantagem de uma abordagem de cluster único é que, numa comutação por falha, a aplicação tem de conseguir repetir a operação através de um identificador de perfil da aplicação alternativo ou tem de executar manualmente a comutação por falha dos perfis de encaminhamento de cluster único afetados.
Encaminhamento de operações
O Cassandra e o Bigtable usam métodos diferentes para selecionar o nó de processamento para operações de leitura e escrita. No Cassandra, a chave de partição é identificada, enquanto no Bigtable é usada a chave de linha.
No Cassandra, o cliente inspeciona primeiro a política de equilíbrio de carga. Este objeto do lado do cliente determina o centro de dados para o qual a operação é encaminhada.
Depois de o centro de dados ser identificado, o Cassandra contacta um nó coordenador para gerir a operação. Se a política reconhecer tokens, o coordenador é um nó que publica dados da partição do nó virtual de destino; caso contrário, o coordenador é um nó aleatório. O nó coordenador identifica os nós onde se encontram as réplicas de dados da chave de partição da operação e, em seguida, indica a esses nós que realizem a operação.
No Bigtable, conforme abordado anteriormente, cada operação inclui um identificador do perfil da aplicação. O perfil da aplicação é definido ao nível do serviço. A camada de encaminhamento do Bigtable inspeciona o perfil para escolher o cluster de destino adequado para a operação. A camada de encaminhamento fornece, em seguida, um caminho para que a operação alcance os nós de processamento corretos através da chave de linha da operação.
Processo de escrita de dados
Ambas as bases de dados estão otimizadas para escritas rápidas e usam um processo semelhante para concluir uma escrita. No entanto, os passos que as bases de dados dão variam ligeiramente, especialmente para o Cassandra, onde, consoante o nível de consistência da operação, pode ser necessária a comunicação com nós participantes adicionais.
Depois de o pedido de gravação ser encaminhado para os nós adequados (Cassandra) ou o nó (Bigtable), as gravações são primeiro persistidas no disco sequencialmente num registo de confirmação (Cassandra) ou num registo partilhado (Bigtable). Em seguida, as escritas são inseridas numa tabela na memória (também conhecida como memtable) que está ordenada como as SSTables.
Após estes dois passos, o nó responde para indicar que a escrita está concluída. No Cassandra, várias réplicas (consoante o nível de consistência especificado para cada operação) têm de responder antes de o coordenador informar o cliente de que a gravação está concluída. No Bigtable, uma vez que cada chave de linha só é atribuída a um único nó em qualquer momento, uma resposta do nó é tudo o que é necessário para confirmar que uma gravação é bem-sucedida.
Posteriormente, se necessário, pode limpar a memtable para o disco sob a forma de uma nova SSTable. No Cassandra, o flush ocorre quando o registo de confirmação atinge um tamanho máximo ou quando a tabela de memória excede um limite que configura. No Bigtable, é iniciado um flush para criar novas SSTables imutáveis quando a memtable atinge um tamanho máximo especificado pelo serviço. Periodicamente, um processo de compactação une as SSTables para um determinado intervalo de chaves numa única SSTable.
Atualizações de dados
Ambas as bases de dados processam as atualizações de dados de forma semelhante. No entanto, o Cassandra permite apenas um valor para cada célula, enquanto o Bigtable pode manter um grande número de valores com versões para cada célula.
Quando o valor na interseção de um identificador de linha exclusivo e uma coluna é modificado, a atualização é mantida conforme descrito anteriormente na secção processo de gravação de dados. A data/hora de gravação é armazenada juntamente com o valor na estrutura SSTable.
Se não tiver esvaziado uma célula atualizada para uma SSTable, pode armazenar apenas o valor da célula na memtable, mas as bases de dados diferem no que é armazenado. O Cassandra guarda apenas o valor mais recente na memtable, enquanto o Bigtable guarda todas as versões na memtable.
Em alternativa, se tiver esvaziado, pelo menos, uma versão de um valor de célula para o disco em SSTables separadas, as bases de dados processam os pedidos desses dados de forma diferente. Quando a célula é pedida ao Cassandra, apenas é devolvido o valor mais recente de acordo com a data/hora. Por outras palavras, a última gravação ganha. No Bigtable, usa filtros para controlar que versões de células uma solicitação de leitura devolve.
Eliminações de linhas
Uma vez que ambas as bases de dados usam ficheiros SSTable imutáveis para persistir os dados no disco, não é possível eliminar uma linha imediatamente. Para garantir que as consultas devolvem os resultados corretos após a eliminação de uma linha, ambas as bases de dados processam as eliminações através do mesmo mecanismo. Primeiro, é adicionado um marcador (denominado tombstone no Cassandra) à tabela de memória. Eventualmente, uma SSTable recém-escrita contém um marcador com data/hora que indica que o identificador exclusivo da linha foi eliminado e não deve ser devolvido nos resultados da consulta.
Tempo de vida
As capacidades de tempo de vida (TTL) nas duas bases de dados são semelhantes, exceto por uma disparidade. No Cassandra, pode definir o TTL para uma coluna ou uma tabela, enquanto no Bigtable só pode definir TTLs para a família de colunas. Existe um método para o Bigtable que pode simular o TTL ao nível da célula.
Recolha de lixo
Uma vez que as atualizações ou as eliminações de dados imediatas não são possíveis com SSTables imutáveis, como abordado anteriormente, a recolha de lixo ocorre durante um processo denominado compactação. O processo remove células ou linhas que não devem ser apresentadas nos resultados da consulta.
O processo de recolha de lixo exclui uma linha ou uma célula quando ocorre uma união de SSTable. Se existir um marcador ou uma lápide para uma linha, essa linha não é incluída na SSTable resultante. Ambas as bases de dados podem excluir uma célula da SSTable unida. Se a data/hora da célula exceder uma qualificação de TTL, as bases de dados excluem a célula. Se existirem duas versões com data/hora para uma determinada célula, o Cassandra inclui apenas o valor mais recente na SSTable unida.
Caminho de leitura de dados
Quando uma operação de leitura atinge o nó de processamento adequado, o processo de leitura para obter dados para satisfazer um resultado de consulta é o mesmo para ambas as bases de dados.
Para cada SSTable no disco que possa conter resultados da consulta, é verificado um filtro de Bloom para determinar se cada ficheiro contém linhas a serem devolvidas. Uma vez que os filtros de Bloom nunca fornecem um falso negativo, todas as SSTables elegíveis são adicionadas a uma lista de candidatos para inclusão no processamento de resultados de leitura adicional.
A operação de leitura é realizada através de uma vista unida criada a partir da tabela de memória e das tabelas SSTable candidatas no disco. Uma vez que todas as chaves são ordenadas lexicograficamente, é eficiente obter uma vista unida que é analisada para obter resultados da consulta.
No Cassandra, um conjunto de nós de processamento determinados pelo nível de consistência da operação tem de participar na operação. No Bigtable, só é necessário consultar o nó responsável pelo intervalo de chaves. Para o Cassandra, tem de considerar as implicações para o dimensionamento de computação, uma vez que é provável que vários nós processem cada leitura.
Os resultados de leitura podem ser limitados no nó de processamento de formas ligeiramente diferentes.
No Cassandra, a cláusula WHERE numa consulta CQL restringe as linhas devolvidas. A restrição é que as colunas na chave principal ou as colunas incluídas num índice secundário podem ser usadas para limitar os resultados.
O Bigtable oferece uma grande variedade de filtros que afetam as linhas ou as células que uma consulta de leitura obtém.
Existem três categorias de filtros:
- Filtros de limitação, que controlam as linhas ou as células que a resposta inclui.
- Modificar filtros, que afetam os dados ou os metadados de células individuais.
- Criar filtros, que lhe permitem combinar vários filtros num só.
Os filtros de limitação são os mais usados, por exemplo, a expressão regular da família de colunas e a expressão regular do qualificador de colunas.
Armazenamento físico de dados
O Bigtable e o Cassandra armazenam dados em SSTables, que são regularmente unidos durante uma fase de compactação. A compressão de dados SSTable oferece vantagens semelhantes para reduzir o tamanho do armazenamento. No entanto, a compressão é aplicada automaticamente no Bigtable e é uma opção de configuração no Cassandra.
Quando comparar as duas bases de dados, deve compreender como cada base de dados armazena fisicamente os dados de forma diferente nos seguintes aspetos:
- A estratégia de distribuição de dados
- O número de versões de células disponíveis
- O tipo de disco de armazenamento
- O mecanismo de replicação e durabilidade dos dados
Distribuição de dados
No Cassandra, uma hash consistente das colunas de partição da chave primária é o método recomendado para determinar a distribuição de dados nas várias SSTables servidas pelos nós do cluster.
O Bigtable usa um prefixo variável para a chave de linha completa de modo a colocar os dados lexicograficamente nas SSTables.
Versões de células
O Cassandra mantém apenas uma versão do valor da célula ativa. Se forem feitas duas escritas numa célula, uma política de última escrita ganha garante que apenas é devolvido um valor.
O Bigtable não limita o número de versões com data/hora para cada célula. Podem aplicar-se outros limites de tamanho das linhas. Se não for definido pelo pedido do cliente, a data/hora é determinada pelo serviço Bigtable no momento em que o nó de processamento recebe a mutação. As versões das células podem ser removidas através de uma política de recolha de lixo que pode ser diferente para cada família de colunas da tabela ou podem ser filtradas de um conjunto de resultados de consulta através da API.
Armazenamento em disco
O Cassandra armazena SSTables em discos anexados a cada nó do cluster. Para reequilibrar os dados no Cassandra, os ficheiros têm de ser copiados fisicamente entre os servidores.
O Bigtable usa o Colossus para armazenar SSTables. Uma vez que o Bigtable usa este sistema de ficheiros distribuído, o serviço Bigtable pode reatribuir quase instantaneamente SSTables a diferentes nós.
Durabilidade e replicação de dados
O Cassandra oferece durabilidade dos dados através da definição do fator de replicação. O fator de replicação determina o número de cópias de SSTable que são armazenadas em diferentes nós no cluster. Uma definição típica para o fator de replicação é 3, que ainda permite garantias de consistência mais fortes com QUORUM ou LOCAL_QUORUM, mesmo que ocorra uma falha de nó.
Com o Bigtable, são fornecidas garantias de elevada durabilidade dos dados através da replicação fornecida pelo Colossus.
O diagrama seguinte ilustra a disposição física dos dados, os nós de processamento de computação e a camada de encaminhamento do Bigtable:

Na camada de armazenamento do Colossus, cada nó é atribuído para publicar os dados que estão armazenados numa série de SSTables. Essas SSTables contêm os dados dos intervalos de chaves de linhas que são atribuídos dinamicamente a cada nó. Embora o diagrama mostre três SSTables para cada nó, é provável que existam mais, porque as SSTables são criadas continuamente à medida que os nós recebem novas alterações aos dados.
Cada nó tem um registo partilhado. As escritas processadas por cada nó são mantidas imediatamente no registo partilhado antes de o cliente receber uma confirmação de escrita. Uma vez que uma gravação no Colossus é replicada várias vezes, a durabilidade é garantida mesmo que ocorra uma falha de hardware nodal antes de os dados serem persistidos numa SSTable para o intervalo de linhas.
Interfaces de aplicações
Originalmente, o acesso à base de dados Cassandra era exposto através de uma API Thrift, mas este método de acesso está descontinuado. A interação com o cliente recomendada é através da CQL.
Semelhante à API Thrift original do Cassandra, o acesso à base de dados do Bigtable é fornecido através de uma API que lê e escreve dados com base nas chaves das linhas fornecidas.
Tal como o Cassandra, o Bigtable tem uma interface de linha de comandos, denominada cbtCLI, e bibliotecas cliente que suportam muitas linguagens de programação comuns. Estas bibliotecas são criadas com base nas APIs gRPC e REST. As aplicações escritas para o Hadoop e que dependem da biblioteca Apache HBase de código aberto para Java podem estabelecer ligação sem alterações significativas ao Bigtable. Para aplicações que não requerem compatibilidade com o HBase, recomendamos que use o cliente Java do Bigtable incorporado.
Os controlos de gestão de identidade e acesso (IAM) do Bigtable estão totalmente integrados com o Google Cloud, e as tabelas também podem ser usadas como uma origem de dados externa do BigQuery.
Configuração da base de dados
Quando configura um cluster do Cassandra, tem de tomar várias decisões de configuração e concluir vários passos. Primeiro, tem de configurar os nós do servidor para fornecer capacidade de computação e aprovisionar armazenamento local. Quando usa um fator de replicação de três, a definição recomendada e mais comum, tem de aprovisionar armazenamento para armazenar três vezes a quantidade de dados que espera ter no cluster. Também tem de determinar e definir configurações para vnodes, racks e replicação.
A separação da computação do armazenamento no Bigtable simplifica a expansão e a redução dos clusters em comparação com o Cassandra. Num cluster em execução normal, normalmente, só se preocupa com o armazenamento total usado pelas tabelas geridas, que determina o número mínimo de nós, e com ter nós suficientes para manter o QPS atual.
Pode ajustar rapidamente o tamanho do cluster do Bigtable se o cluster tiver capacidade excessiva ou insuficiente com base na carga de produção.
Armazenamento do Bigtable
Além da localização geográfica do cluster inicial, a única escolha que tem de fazer quando cria a instância do Bigtable é o tipo de armazenamento. O Bigtable oferece duas opções de armazenamento: unidades de estado sólido (SSD) ou unidades de disco rígido (HDD). Todos os clusters numa instância têm de partilhar o mesmo tipo de armazenamento.
Quando tem em conta as necessidades de armazenamento com o Bigtable, não tem de ter em conta as réplicas de armazenamento, como faria ao dimensionar um cluster do Cassandra. Não há perda de densidade de armazenamento para alcançar a tolerância a falhas, como se vê no Cassandra. Além disso, uma vez que o armazenamento não tem de ser expressamente aprovisionado, só lhe é cobrado o armazenamento em utilização.
SSD
A capacidade do nó SSD de 5 TB, que é preferível para a maioria das cargas de trabalho, oferece uma densidade de armazenamento mais elevada em comparação com a configuração recomendada para máquinas Cassandra, que têm uma densidade de armazenamento máxima prática inferior a 2 TB para cada nó. Quando avaliar as necessidades de capacidade de armazenamento, lembre-se de que o Bigtable só conta com uma cópia dos dados. Em comparação, o Cassandra tem de ter em conta três cópias dos dados na maioria das configurações.
Embora o QPS de escrita para SSD seja aproximadamente o mesmo que para HDD, o SSD oferece um QPS de leitura significativamente superior ao do HDD. O armazenamento SSD tem um preço igual ou próximo dos custos dos discos persistentes SSD aprovisionados e varia consoante a região.
HDD
O tipo de armazenamento HDD permite uma densidade de armazenamento considerável: 16 TB para cada nó. A desvantagem é que as leituras aleatórias são significativamente mais lentas, suportando apenas 500 linhas lidas por segundo para cada nó. O HDD é preferível para cargas de trabalho com escrita intensiva em que se espera que as leituras sejam análises de intervalos associadas ao processamento em lote. O armazenamento em HDD tem um preço igual ou próximo do custo associado ao Cloud Storage e varia consoante a região.
Considerações sobre o tamanho do cluster
Quando dimensiona uma instância do Bigtable para se preparar para migrar uma carga de trabalho do Cassandra, existem considerações quando compara clusters do Cassandra de centro de dados único com instâncias do Bigtable de cluster único e clusters do Cassandra de vários centros de dados com instâncias do Bigtable de vários clusters. As diretrizes nas secções seguintes pressupõem que não são necessárias alterações significativas ao modelo de dados para fazer a migração e que existe uma compressão de armazenamento equivalente entre o Cassandra e o Bigtable.
Um cluster de centro de dados único
Quando compara um cluster de centro de dados único com uma instância do Bigtable de cluster único, deve considerar primeiro os requisitos de armazenamento. Pode estimar o tamanho não replicado de cada espaço de chaves através do comando
nodetool tablestats
e dividindo o tamanho total de armazenamento descarregado pelo fator de replicação do espaço de chaves. Em seguida, divide a quantidade de armazenamento não replicado de todos os espaços de chaves por
3,5 TB
(5 TB * 0,70)
para determinar o número sugerido de nós SSD para processar apenas o armazenamento. Conforme
mencionado, o Bigtable processa a replicação e a durabilidade do armazenamento
num nível separado que é transparente para o utilizador.
Em seguida, deve considerar os requisitos de computação para o número de nós. Pode consultar as métricas do servidor e da aplicação cliente do Cassandra para obter um número aproximado de leituras e escritas sustentadas que foram executadas. Para estimar o número mínimo de nós de SSD para executar a sua carga de trabalho, divida essa métrica por 10 000. Provavelmente, precisa de mais nós para aplicações que requerem resultados de consultas de baixa latência. A Google recomenda que teste o desempenho do Bigtable com dados e consultas representativos para estabelecer uma métrica para as QPS por nó que sejam alcançáveis para a sua carga de trabalho.
O número de nós necessários para o cluster deve ser igual ao maior dos requisitos de armazenamento e computação. Se tiver dúvidas acerca das suas necessidades de armazenamento ou débito, pode fazer corresponder o número de nós do Bigtable ao número de máquinas típicas do Cassandra. Pode aumentar ou diminuir a escala de um cluster do Bigtable para corresponder às necessidades da carga de trabalho com um esforço mínimo e sem tempo de inatividade.
Um cluster de vários centros de dados
Com clusters de vários centros de dados, é mais difícil determinar a configuração de uma instância do Bigtable. Idealmente, deve ter um cluster na instância para cada centro de dados na topologia do Cassandra. Cada cluster do Bigtable na instância tem de armazenar todos os dados na instância e tem de conseguir processar a taxa de inserção total em todo o cluster. Os clusters numa instância podem ser criados em qualquer região da nuvem suportada em todo o mundo.
A técnica para estimar as necessidades de armazenamento é semelhante à abordagem para clusters de centro de dados único. Use nodetool para capturar o tamanho do armazenamento de cada espaço de chaves no cluster do Cassandra e, em seguida, divida esse tamanho pelo número de réplicas. Tem de ter em atenção que o espaço de chaves de uma tabela pode ter fatores de replicação diferentes para cada centro de dados.
O número de nós em cada cluster numa instância deve ser capaz de processar todas as gravações no cluster e todas as leituras para, pelo menos, dois centros de dados para manter os objetivos de nível de serviço (SLOs) durante uma indisponibilidade do cluster. Uma abordagem comum é começar com todos os clusters a terem a capacidade de nós equivalente ao centro de dados mais ocupado no cluster do Cassandra. Os clusters do Bigtable numa instância podem ser individualmente dimensionados para cima ou para baixo de modo a corresponderem às necessidades da carga de trabalho sem tempo de inatividade.
Administração
O Bigtable oferece componentes totalmente geridos para funções de administração comuns realizadas no Cassandra.
Cópia de segurança e restauro
O Bigtable oferece dois métodos para abranger as necessidades comuns de cópias de segurança: cópias de segurança do Bigtable e exportações de dados geridas.
Pode considerar as cópias de segurança do Bigtable como análogas a uma versão gerida da funcionalidade de instantâneo do Cassandra.nodetool
As cópias de segurança do Bigtable criam cópias restauráveis de uma tabela, que são armazenadas como objetos membros de um cluster. Pode restaurar cópias de segurança como uma nova tabela no cluster que iniciou a cópia de segurança. As cópias de segurança foram concebidas para criar pontos de restauro se ocorrer corrupção ao nível da aplicação. As cópias de segurança que criar
através desta utilidade não consomem recursos de nós e têm preços iguais ou próximos
aos preços do Cloud Storage. Pode invocar cópias de segurança do Bigtable
por programação ou através da Google Cloud consola do Bigtable.
Outra forma de fazer uma cópia de segurança do Bigtable é usar uma exportação de dados gerida para o Cloud Storage. Pode exportar para os formatos de ficheiros Avro, Parquet ou Hadoop Sequence. Em comparação com as cópias de segurança do Bigtable, as exportações demoram mais tempo a ser executadas e incorrem em custos de computação adicionais porque usam o Dataflow. No entanto, estas exportações criam ficheiros de dados portáteis que pode consultar offline ou importar para outro sistema.
A redimensionar
Uma vez que o Bigtable separa o armazenamento e a computação, pode adicionar ou remover nós do Bigtable em resposta à procura de consultas de forma mais integrada do que no Cassandra. A arquitetura homogénea do Cassandra requer que reequilibre os nós (ou os vnodes) nas máquinas no cluster.
Pode alterar o tamanho do cluster manualmente na Google Cloud consola ou programaticamente através da API Cloud Bigtable. A adição de nós a um cluster pode gerar melhorias de desempenho notáveis em minutos. Alguns clientes usaram com êxito um ajuste de escala automático de código aberto desenvolvido pelo Spotify.
Manutenção interna
O serviço Bigtable processa perfeitamente as tarefas de manutenção internas comuns do Cassandra, como a aplicação de patches do SO, a recuperação de nós, a reparação de nós, a monitorização da compactação de armazenamento e a rotação de certificados SSL.
Monitorização
A associação do Bigtable à visualização de métricas ou aos alertas não requer esforços de administração ou desenvolvimento. A página da consola do Bigtable inclui painéis de controlo pré-criados para monitorizar as métricas de débito e utilização ao nível da instância, do cluster e da tabela.Google Cloud Pode criar vistas e alertas personalizados nos painéis de controlo do Cloud Monitoring, onde as métricas estão automaticamente disponíveis.
O Key Visualizer do Bigtable, uma funcionalidade de monitorização na consola do Google Cloud, permite-lhe fazer um ajuste de desempenho avançado. Google Cloud
IAM e segurança
No Bigtable, a autorização está totalmente integrada na estrutura doGoogle CloudIAMe requer uma configuração e manutenção mínimas. As contas e as palavras-passe de utilizadores locais não são partilhadas com as aplicações cliente. Em alternativa, são concedidas autorizações e funções detalhadas aos utilizadores ao nível da organização e às contas de serviço.
O Bigtable encripta automaticamente todos os dados em repouso e em trânsito. Não existem opções para desativar estas funcionalidades. Todo o acesso administrativo é totalmente registado. Pode usar os VPC Service Controls para controlar o acesso a instâncias do Bigtable a partir de redes externas aprovadas.
O que se segue?
- Leia acerca do design do esquema do Bigtable.
- Experimente o codelab do Bigtable para utilizadores do Cassandra.
- Saiba mais sobre o emulador do Bigtable.
- Explore arquiteturas de referência, diagramas e práticas recomendadas sobre o Google Cloud. Consulte o nosso Centro de arquitetura na nuvem.