云张量处理单元 (TPU)
利用 Google Cloud TPU 加速 AI 开发
不确定 TPU 是否适合自己? 了解何时在 Compute Engine 实例上使用 GPU 或 CPU 来运行机器学习工作负载。

概览
什么是张量处理单元 (TPU)?
Google Cloud TPU 是定制设计的 AI 加速器,针对 AI 模型的训练和推理进行了优化。它们非常适合各种应用场景,例如智能体、代码生成、媒体内容生成、合成语音、视觉服务、商品推荐引擎和个性化模型等。TPU 为 Gemini 和 Google 的所有 AI 赋能的应用(如 Google 搜索、Google 相册和 Google 地图)提供支持,这些应用服务于超过 10 亿用户。
Cloud TPU 有哪些优势?
Cloud TPU 能够针对各种 AI 工作负载(涵盖训练、微调和推理)进行经济高效的扩缩。Cloud TPU 提供了多种功能,可加速领先 AI 框架(包括 PyTorch、JAX 和 TensorFlow)上的工作负载。通过 Google Kubernetes Engine (GKE) 中的 Cloud TPU 集成,无缝编排大规模 AI 工作负载。利用动态工作负载调度程序同时安排所有需要的加速器,从而提高工作负载的可伸缩性。寻求最简单的 AI 模型开发方法的客户还可以在全托管式 AI 平台 Vertex AI 中利用 Cloud TPU。
何时使用 Cloud TPU?
Cloud TPU 与 GPU 有何不同?
GPU 是专门为处理计算机图形而设计的处理器。并行结构使其非常适合处理 AI 工作负载中常见的大数据块的算法。了解详情。
TPU 是 Google 专为神经网络设计的应用专用集成电路 (ASIC)。TPU 具有专用功能,例如矩阵乘法单元 (MXU) 和专有的互连拓扑,因此非常适合用于加快 AI 训练和推理速度。
Cloud TPU 版本
| Cloud TPU 版本 | 说明 | 可用情况 |
|---|---|---|
Ironwood | 迄今为止我们提供的最强大、最高效的 TPU,适用于最大规模的训练和推理 | Ironwood TPU 将于 2025 年第 4 季度正式发布 |
Trillium | 第六代 TPU。提升了能效和单芯片峰值计算性能,可用于训练和推理 | Trillium 已在北美(美国东部区域)、欧洲(西欧区域)和亚洲(东北亚区域)全面上线 |
Cloud TPU v5p | 适用于构建大型、复杂的基础模型的强大 TPU | Cloud TPU v5p 现已在北美(美国东部区域)正式发布 |
Cloud TPU v5e | 经济实惠且易于获取的 TPU,适用于中到大规模的训练和推理工作负载 | Cloud TPU v5e 现已在北美(美国中部/东部/南部/西部区域)、欧洲(西欧区域)和亚洲(东南亚区域)正式发布 |
有关 Cloud TPU 版本的更多信息
Ironwood
迄今为止我们提供的最强大、最高效的 TPU,适用于最大规模的训练和推理
Ironwood TPU 将于 2025 年第 4 季度正式发布
Trillium
第六代 TPU。提升了能效和单芯片峰值计算性能,可用于训练和推理
Trillium 已在北美(美国东部区域)、欧洲(西欧区域)和亚洲(东北亚区域)全面上线
Cloud TPU v5p
适用于构建大型、复杂的基础模型的强大 TPU
Cloud TPU v5p 现已在北美(美国东部区域)正式发布
Cloud TPU v5e
经济实惠且易于获取的 TPU,适用于中到大规模的训练和推理工作负载
Cloud TPU v5e 现已在北美(美国中部/东部/南部/西部区域)、欧洲(西欧区域)和亚洲(东南亚区域)正式发布
有关 Cloud TPU 版本的更多信息
工作方式
深入了解 Google Cloud TPU 的神奇之处,包括执行各种操作的数据中心的罕见内部视图。客户使用 Cloud TPU 运行一些全球规模最大的 AI 工作负载,其强大能力远不止芯片。在本视频中,我们将介绍 TPU 系统的组件,包括数据中心网络、光学电路开关、水冷却系统、生物识别安全性验证等。
深入了解 Google Cloud TPU 的神奇之处,包括执行各种操作的数据中心的罕见内部视图。客户使用 Cloud TPU 运行一些全球规模最大的 AI 工作负载,其强大能力远不止芯片。在本视频中,我们将介绍 TPU 系统的组件,包括数据中心网络、光学电路开关、水冷却系统、生物识别安全性验证等。

常见用途
运行大规模 AI 训练工作负载
如何扩缩模型
训练 LLM 通常感觉像炼金术,但了解和优化模型的性能却并非如此。本书旨在揭开在 TPU 上扩缩语言模型的科学原理:TPU 的工作方式和彼此之间的通信方式、LLM 在真实硬件上的运行方式,以及如何在训练和推理期间并行运行模型,以便它们能够以大规模高效运行。

强大、可伸缩且高效的 AI 训练
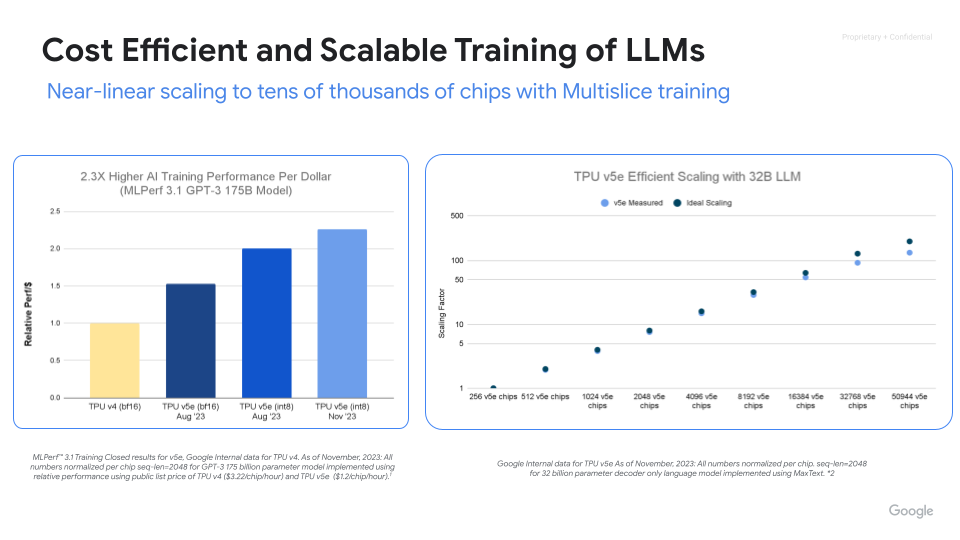
借助 Cloud TPU,最大限度地提高性能、效率并缩短价值实现时间。通过 Cloud TPU 多切片训练,扩展到数千个芯片。利用 ML Goodput Measurement 衡量和提高大规模机器学习训练的效率。通过 MaxText 和 MaxDiffusion(适用于大型模型训练的开源参考部署)快速上手。
方法指南
如何扩缩模型
训练 LLM 通常感觉像炼金术,但了解和优化模型的性能却并非如此。本书旨在揭开在 TPU 上扩缩语言模型的科学原理:TPU 的工作方式和彼此之间的通信方式、LLM 在真实硬件上的运行方式,以及如何在训练和推理期间并行运行模型,以便它们能够以大规模高效运行。
其他资源
强大、可伸缩且高效的 AI 训练
借助 Cloud TPU,最大限度地提高性能、效率并缩短价值实现时间。通过 Cloud TPU 多切片训练,扩展到数千个芯片。利用 ML Goodput Measurement 衡量和提高大规模机器学习训练的效率。通过 MaxText 和 MaxDiffusion(适用于大型模型训练的开源参考部署)快速上手。
微调基础 AI 模型
使用 Pytorch/XLA 调整 LLM 以适应您的应用
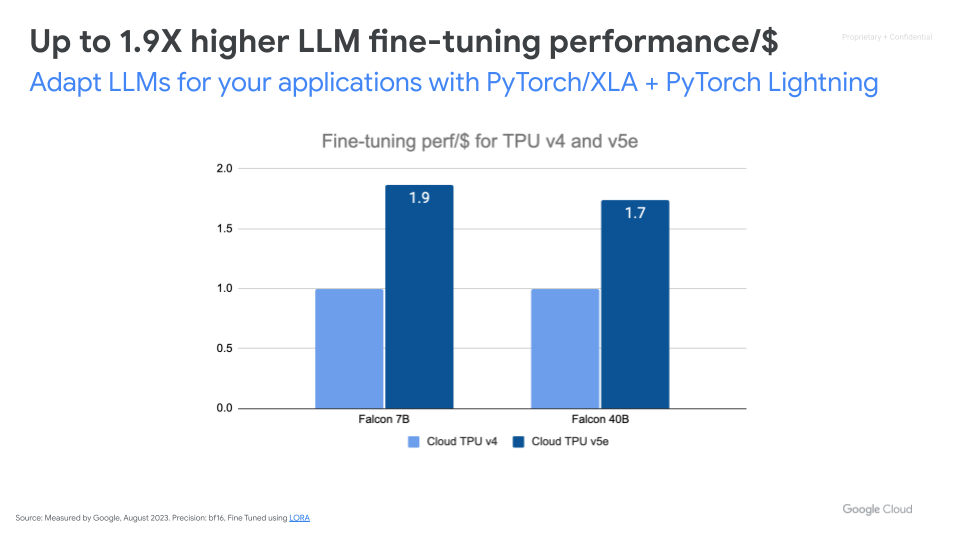
利用可代表您的使用场景的训练数据,高效微调基础模型。Cloud TPU v5e 的每美元 LLM 微调性能比 Cloud TPU v4 高至 1.9 倍。
其他资源
使用 Pytorch/XLA 调整 LLM 以适应您的应用
利用可代表您的使用场景的训练数据,高效微调基础模型。Cloud TPU v5e 的每美元 LLM 微调性能比 Cloud TPU v4 高至 1.9 倍。
处理大规模 AI 推理工作负载
高性能、可扩缩且经济高效的推理
使用 vLLM 和 MaxDiffusion 加速 AI 推理。vLLM 是一种热门的开源推理引擎,旨在实现用于大语言模型 (LLM) 推理的高吞吐量和低延迟。在 tpu-inference 的支持下,vLLM 现在提供 vLLM TPU,用于实现高吞吐量、低延迟的 LLM 推理。它统一了 JAX 和 PyTorch,可扩展模型覆盖范围(Gemma、Llama、Qwen)并增强功能。MaxDiffusion 可优化 Cloud TPU 上的 diffusion 模型推理,以实现高性能。
利用可扩缩的 AI 基础架构,实现最高的性价比
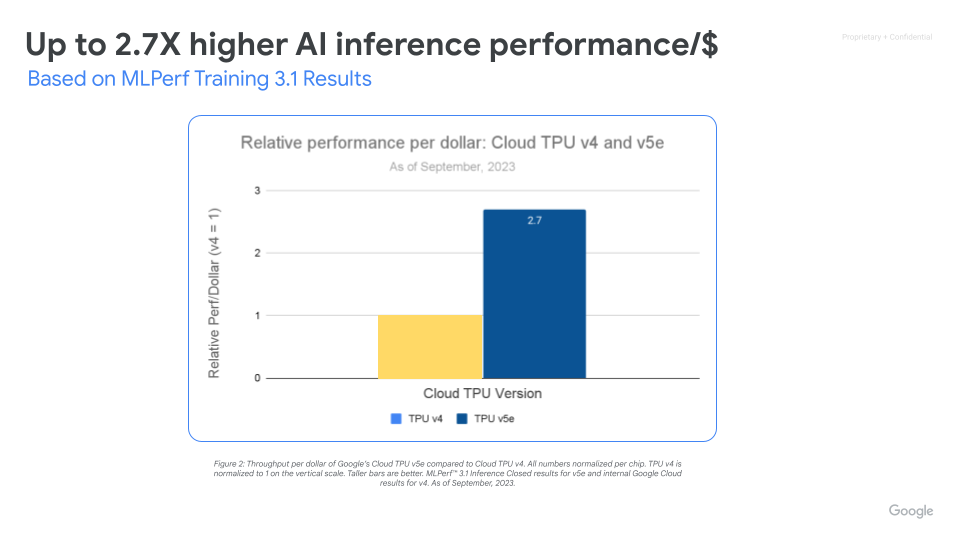
Cloud TPU v5e 可为各种 AI 工作负载(包括最新的 LLM 和生成式 AI 模型)实现高性能且经济高效的推理。与 Cloud TPU v4 相比,TPU v5e 可将性价比最多提高到 2.5 倍,并将速度最多提高到 1.7 倍。每个 TPU v5e 芯片每秒可提供高达 393 万亿次的 int8 运算,从而使复杂的模型进行快速预测。TPU v5e Pod 每秒可提供高达 10 亿亿次 int8 运算,即 100 petaOps 的计算能力。
方法指南
高性能、可扩缩且经济高效的推理
使用 vLLM 和 MaxDiffusion 加速 AI 推理。vLLM 是一种热门的开源推理引擎,旨在实现用于大语言模型 (LLM) 推理的高吞吐量和低延迟。在 tpu-inference 的支持下,vLLM 现在提供 vLLM TPU,用于实现高吞吐量、低延迟的 LLM 推理。它统一了 JAX 和 PyTorch,可扩展模型覆盖范围(Gemma、Llama、Qwen)并增强功能。MaxDiffusion 可优化 Cloud TPU 上的 diffusion 模型推理,以实现高性能。
其他资源
利用可扩缩的 AI 基础架构,实现最高的性价比
Cloud TPU v5e 可为各种 AI 工作负载(包括最新的 LLM 和生成式 AI 模型)实现高性能且经济高效的推理。与 Cloud TPU v4 相比,TPU v5e 可将性价比最多提高到 2.5 倍,并将速度最多提高到 1.7 倍。每个 TPU v5e 芯片每秒可提供高达 393 万亿次的 int8 运算,从而使复杂的模型进行快速预测。TPU v5e Pod 每秒可提供高达 10 亿亿次 int8 运算,即 100 petaOps 的计算能力。
GKE 中的 Cloud TPU
借助平台编排运行经过优化的 AI 工作负载
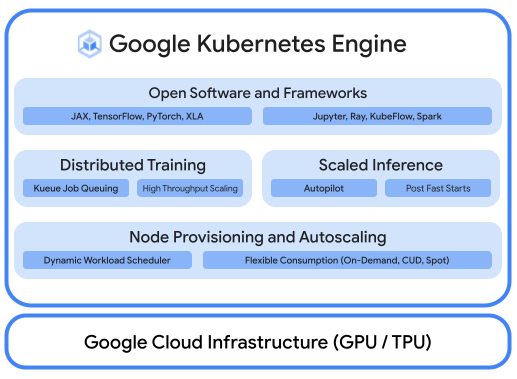
强大的 AI/机器学习平台通常包含以下层:(i) 支持使用 GPU 大规模训练和服务工作负载的基础设施编排;(ii) 与分布式计算和数据处理框架灵活集成;(iii) 支持多个团队使用同一基础设施,以最大限度地提高资源利用率。
使用 GKE 轻松扩缩
将 Cloud TPU 的强大功能与 GKE 的灵活性和可伸缩性相结合,比以往更快速、更轻松地构建和部署机器学习模型。利用 GKE 中提供的 Cloud TPU,您现在可以为所有工作负载提供一个一致的运营环境,从而实现自动 MLOps 流水线的标准化。
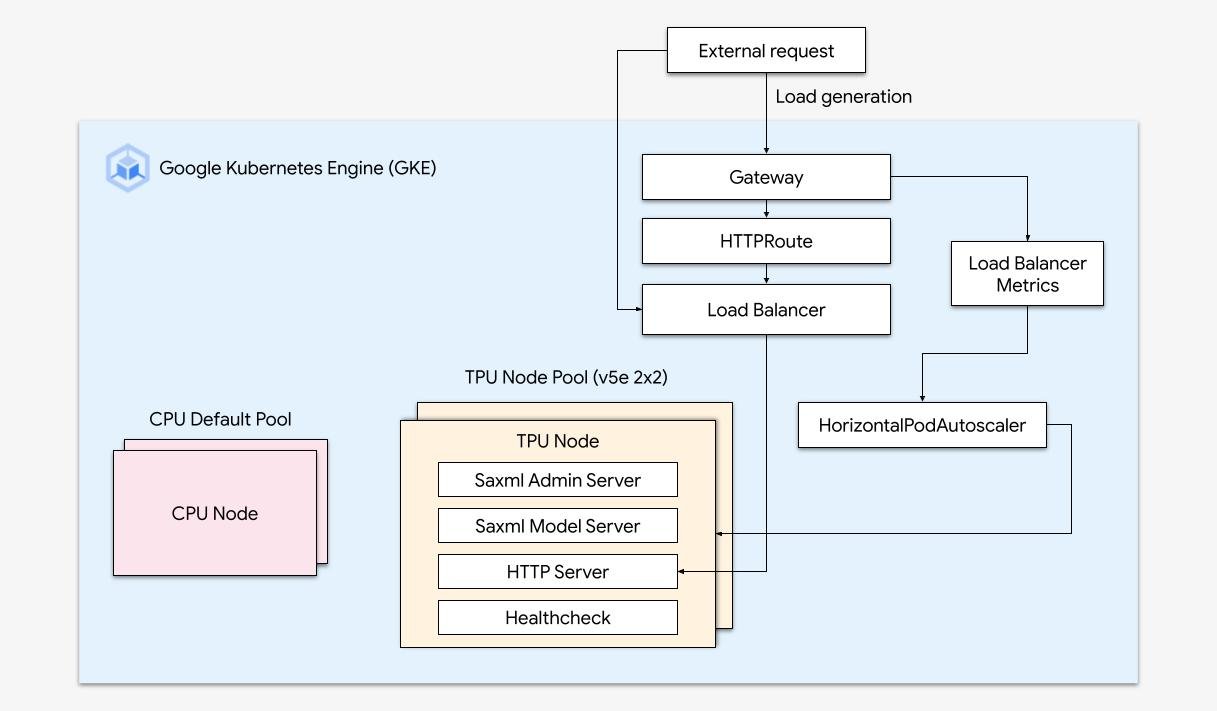
方法指南
借助平台编排运行经过优化的 AI 工作负载
强大的 AI/机器学习平台通常包含以下层:(i) 支持使用 GPU 大规模训练和服务工作负载的基础设施编排;(ii) 与分布式计算和数据处理框架灵活集成;(iii) 支持多个团队使用同一基础设施,以最大限度地提高资源利用率。
其他资源
使用 GKE 轻松扩缩
将 Cloud TPU 的强大功能与 GKE 的灵活性和可伸缩性相结合,比以往更快速、更轻松地构建和部署机器学习模型。利用 GKE 中提供的 Cloud TPU,您现在可以为所有工作负载提供一个一致的运营环境,从而实现自动 MLOps 流水线的标准化。
Vertex AI 中的 Cloud TPU
带有 Cloud TPU 的 Vertex AI 训练和预测
对于希望以最简单的方式开发 AI 模型的客户,您可以使用 Vertex AI 部署 Cloud TPU v5e。Vertex AI 是一个端到端平台,用于在全代管式基础架构上构建 AI 模型,该基础架构专为低延迟服务和高性能训练而打造。
其他资源
带有 Cloud TPU 的 Vertex AI 训练和预测
对于希望以最简单的方式开发 AI 模型的客户,您可以使用 Vertex AI 部署 Cloud TPU v5e。Vertex AI 是一个端到端平台,用于在全代管式基础架构上构建 AI 模型,该基础架构专为低延迟服务和高性能训练而打造。
价格
| Cloud TPU 价格 | 所有 Cloud TPU 价格均按芯片小时数计算 | ||
|---|---|---|---|
| Cloud TPU 版本 | 评估价格(美元) | 1 年承诺(美元) | 3 年承诺(美元) |
Trillium | 起价 $2.7000 每芯片小时 | 起价 $1.8900 每芯片小时 | 起价 $1.2200 每芯片小时 |
Cloud TPU v5p | 起价 $4.2000 每芯片小时 | 起价 $2.9400 每芯片小时 | 起价 $1.8900 每芯片小时 |
Cloud TPU v5e | 起价 $1.2000 每芯片小时 | 起价 $0.8400 每芯片小时 | 起价 $0.5400 每芯片小时 |
Cloud TPU 价格因产品和区域而异。
Cloud TPU 价格
所有 Cloud TPU 价格均按芯片小时数计算
Trillium
Starting at
$2.7000
每芯片小时
Starting at
$1.8900
每芯片小时
Starting at
$1.2200
每芯片小时
Cloud TPU v5p
Starting at
$4.2000
每芯片小时
Starting at
$2.9400
每芯片小时
Starting at
$1.8900
每芯片小时
Cloud TPU v5e
Starting at
$1.2000
每芯片小时
Starting at
$0.8400
每芯片小时
Starting at
$0.5400
每芯片小时
Cloud TPU 价格因产品和区域而异。











