Cloud Tensor Processing Units (Cloud TPUs)
Acelere o desenvolvimento de IA com as Google Cloud TPUs
Não tem certeza se as TPUs são adequadas? Saiba quando usar GPUs ou CPUs em instâncias do Compute Engine para executar cargas de trabalho de machine learning.

Visão geral
O que é uma Unidade de Processamento de Tensor (TPU)?
As TPUs do Google Cloud são aceleradores de IA personalizados, otimizados para treinamento e inferência de modelos de IA. Eles são ideais para diversos casos de uso, como agentes, geração de código, geração de conteúdo de mídia, fala sintética, serviços de visão, mecanismos de recomendação, modelos de personalização, entre outros. As TPUs alimentam o Gemini e todos os aplicativos do Google com tecnologia de IA, como Pesquisa, Fotos e Maps, que atendem mais de 1 bilhão de usuários.
Quais são as vantagens das Cloud TPUs?
As Cloud TPUs foram projetadas para escalonar de maneira econômica para uma ampla variedade de cargas de trabalho de IA, abrangendo treinamento, ajuste e inferência. As Cloud TPUs oferecem a versatilidade de acelerar cargas de trabalho em frameworks de IA líderes, incluindo PyTorch, Jax eTensorFlow. Orquestre cargas de trabalho de IA em grande escala com perfeição com a integração da Cloud TPU no Google Kubernetes Engine (GKE). Aproveite o Dynamic Workload Scheduler para melhorar a escalonabilidade das cargas de trabalho programando todos os aceleradores necessários simultaneamente. Os clientes que procuram a maneira mais simples de desenvolver modelos de IA também podem aproveitar as Cloud TPUs na Vertex AI, uma plataforma de IA totalmente gerenciada.
Quando usar Cloud TPUs?
Qual é a diferença entre Cloud TPUs e GPUs?
GPU é um processador especializado originalmente projetado para manipular gráficos do computador. A estrutura paralela é ideal para algoritmos que processam grandes blocos de dados normalmente encontrados em cargas de trabalho de IA. Saiba mais.
A TPU é um circuito integrado específico de aplicativos (ASIC, na sigla em inglês) projetado pelo Google para redes neurais. As TPUs têm recursos especializados, como a unidade de multiplicação de matrizes (MXU) e a topologia de interconexão proprietária, que as tornam ideais para acelerar o treinamento e a inferência de IA.
Versões da Cloud TPU
| Versão da Cloud TPU | Descrição | Disponibilidade |
|---|---|---|
Trillium | O Cloud TPU mais avançado até hoje | O Trillium está disponível em geral na América do Norte (região leste dos EUA), na Europa (região oeste) e na Ásia (região nordeste). |
Cloud TPU v5p | O Cloud TPU mais potente para treinar modelos de IA | A Cloud TPU v5p está com disponibilidade geral na América do Norte (região leste dos EUA) |
Cloud TPU v5e | Um Cloud TPU versátil para treinamento e inferência | A Cloud TPU v5e está em disponibilidade geral na América do Norte (regiões central/leste/sul/oeste dos EUA), Europa (região oeste) e Ásia (região sudeste) |
Outras informações sobre as versões da Cloud TPU
Trillium
O Cloud TPU mais avançado até hoje
O Trillium está disponível em geral na América do Norte (região leste dos EUA), na Europa (região oeste) e na Ásia (região nordeste).
Cloud TPU v5p
O Cloud TPU mais potente para treinar modelos de IA
A Cloud TPU v5p está com disponibilidade geral na América do Norte (região leste dos EUA)
Cloud TPU v5e
Um Cloud TPU versátil para treinamento e inferência
A Cloud TPU v5e está em disponibilidade geral na América do Norte (regiões central/leste/sul/oeste dos EUA), Europa (região oeste) e Ásia (região sudeste)
Outras informações sobre as versões da Cloud TPU
Como funciona
Tenha uma visão detalhada da magia das TPUs do Google Cloud, incluindo uma visão rara dos data centers em que tudo isso acontece. Os clientes usam Cloud TPUs para executar algumas das maiores cargas de trabalho de IA do mundo, e essa potência vem de muito mais do que apenas um chip. Neste vídeo, confira os componentes do sistema de TPU, incluindo rede de data center, interruptores de circuito óptico, sistemas de resfriamento com água, verificação biométrica de segurança e muito mais.
Tenha uma visão detalhada da magia das TPUs do Google Cloud, incluindo uma visão rara dos data centers em que tudo isso acontece. Os clientes usam Cloud TPUs para executar algumas das maiores cargas de trabalho de IA do mundo, e essa potência vem de muito mais do que apenas um chip. Neste vídeo, confira os componentes do sistema de TPU, incluindo rede de data center, interruptores de circuito óptico, sistemas de resfriamento com água, verificação biométrica de segurança e muito mais.

Usos comuns
Execute cargas de trabalho de treinamento de IA em grande escala
Como escalonar seu modelo
Treinar LLMs parece uma alquimia, mas entender e otimizar o desempenho dos modelos não precisa ser assim. Este livro tem como objetivo desmistificar a ciência de escalonar modelos de linguagem em TPUs: como as TPUs funcionam e se comunicam entre si, como os LLMs são executados em hardware real e como paralelizar seus modelos durante o treinamento e a inferência para que eles sejam executados de maneira eficiente em grande escala.

Treinamento de IA avançado, escalonável e eficiente
Maximize o desempenho, a eficiência e o tempo de retorno do investimento com Cloud TPUs. Escalone para milhares de chips com o treinamento em Multislice da Cloud TPU. Meça e melhore a produtividade do treinamento de ML em grande escala com a medição de Goodput de ML. Comece rapidamente com as implantações de referência de código aberto MaxText e MaxDiffusion para treinamento de modelos grandes.

Tutoriais
Como escalonar seu modelo
Treinar LLMs parece uma alquimia, mas entender e otimizar o desempenho dos modelos não precisa ser assim. Este livro tem como objetivo desmistificar a ciência de escalonar modelos de linguagem em TPUs: como as TPUs funcionam e se comunicam entre si, como os LLMs são executados em hardware real e como paralelizar seus modelos durante o treinamento e a inferência para que eles sejam executados de maneira eficiente em grande escala.
Outros recursos
Treinamento de IA avançado, escalonável e eficiente
Maximize o desempenho, a eficiência e o tempo de retorno do investimento com Cloud TPUs. Escalone para milhares de chips com o treinamento em Multislice da Cloud TPU. Meça e melhore a produtividade do treinamento de ML em grande escala com a medição de Goodput de ML. Comece rapidamente com as implantações de referência de código aberto MaxText e MaxDiffusion para treinamento de modelos grandes.
Ajuste modelos básicos de IA
Adapte LLMs para seus aplicativos com Pytorch/XLA
Ajuste os modelos de base com eficiência aproveitando seus próprios dados de treinamento que representam seu caso de uso. O Cloud TPU v5e oferece um desempenho de ajuste de LLM até 1,9 vezes mais alto por dólar em comparação com o Cloud TPU v4.

Outros recursos
Adapte LLMs para seus aplicativos com Pytorch/XLA
Ajuste os modelos de base com eficiência aproveitando seus próprios dados de treinamento que representam seu caso de uso. O Cloud TPU v5e oferece um desempenho de ajuste de LLM até 1,9 vezes mais alto por dólar em comparação com o Cloud TPU v4.
Disponibilize cargas de trabalho de inferência de IA em grande escala
Inferência de alto desempenho, escalonável e econômica
Acelere a inferência de IA com o JetStream e o MaxDiffusion. O JetStream é um novo mecanismo de inferência desenvolvido especificamente para inferência de modelos de linguagem grandes (LLM). O JetStream representa um salto significativo em desempenho e economia, oferecendo capacidade de processamento e latência incomparáveis para inferência de LLM nas Cloud TPUs. O MaxDiffusion é um conjunto de implementações de modelo de difusão otimizadas para Cloud TPUs que facilita a execução de inferências em modelos de difusão em Cloud TPUs com alto desempenho.
Maximize o desempenho/$ com uma infraestrutura de IA que escalona
O Cloud TPU v5e permite a inferência de alto desempenho e economia para uma ampla variedade de cargas de trabalho de IA, incluindo os modelos de IA generativa e LLMs mais recentes. A TPU v5e oferece um desempenho de capacidade até 2,5 vezes maior por dólar e velocidade até 1,7 vezes maior em relação ao Cloud TPU v4. Cada chip TPU v5e fornece até 393 trilhões de operações int8 por segundo, permitindo que modelos complexos façam previsões rápidas. Um pod de TPU v5e oferece até 100 quatrilhões de operações int8 por segundo ou 100 petaOps de capacidade de computação.

Tutoriais
Inferência de alto desempenho, escalonável e econômica
Acelere a inferência de IA com o JetStream e o MaxDiffusion. O JetStream é um novo mecanismo de inferência desenvolvido especificamente para inferência de modelos de linguagem grandes (LLM). O JetStream representa um salto significativo em desempenho e economia, oferecendo capacidade de processamento e latência incomparáveis para inferência de LLM nas Cloud TPUs. O MaxDiffusion é um conjunto de implementações de modelo de difusão otimizadas para Cloud TPUs que facilita a execução de inferências em modelos de difusão em Cloud TPUs com alto desempenho.
Outros recursos
Maximize o desempenho/$ com uma infraestrutura de IA que escalona
O Cloud TPU v5e permite a inferência de alto desempenho e economia para uma ampla variedade de cargas de trabalho de IA, incluindo os modelos de IA generativa e LLMs mais recentes. A TPU v5e oferece um desempenho de capacidade até 2,5 vezes maior por dólar e velocidade até 1,7 vezes maior em relação ao Cloud TPU v4. Cada chip TPU v5e fornece até 393 trilhões de operações int8 por segundo, permitindo que modelos complexos façam previsões rápidas. Um pod de TPU v5e oferece até 100 quatrilhões de operações int8 por segundo ou 100 petaOps de capacidade de computação.
Cloud TPU no GKE
Execute cargas de trabalho de IA otimizadas com orquestração da plataforma
Uma plataforma de IA/ML robusta considera as seguintes camadas: (i) orquestração da infraestrutura que oferece suporte a GPUs para treinar e veicular cargas de trabalho em escala; (ii) integração flexível com computação distribuída e frameworks de processamento de dados; e (iii) suporte a várias equipes na mesma infraestrutura para maximizar a utilização de recursos.

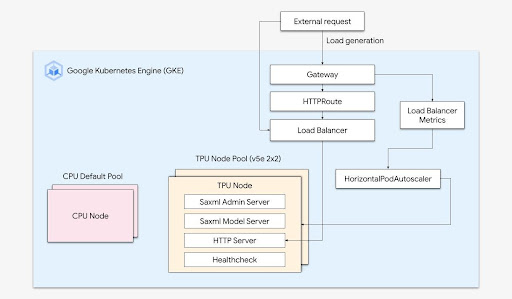
Escalonamento simplificado com o GKE
Combine a eficiência das Cloud TPUs com a flexibilidade e a escalonabilidade do GKE para criar e implantar modelos de machine learning com mais rapidez e facilidade do que nunca. Com as Cloud TPUs disponíveis no GKE, é possível ter um único ambiente de operações consistente para todas as cargas de trabalho, padronizando pipelines de MLOps automatizados.
Tutoriais
Execute cargas de trabalho de IA otimizadas com orquestração da plataforma
Uma plataforma de IA/ML robusta considera as seguintes camadas: (i) orquestração da infraestrutura que oferece suporte a GPUs para treinar e veicular cargas de trabalho em escala; (ii) integração flexível com computação distribuída e frameworks de processamento de dados; e (iii) suporte a várias equipes na mesma infraestrutura para maximizar a utilização de recursos.
Outros recursos
Escalonamento simplificado com o GKE
Combine a eficiência das Cloud TPUs com a flexibilidade e a escalonabilidade do GKE para criar e implantar modelos de machine learning com mais rapidez e facilidade do que nunca. Com as Cloud TPUs disponíveis no GKE, é possível ter um único ambiente de operações consistente para todas as cargas de trabalho, padronizando pipelines de MLOps automatizados.
Cloud TPU na Vertex AI
Treinamento e previsões da Vertex AI com Cloud TPUs
Para clientes que procuram uma maneira mais simples de desenvolver modelos de IA, implante a Cloud TPU v5e com a Vertex AI, uma plataforma completa para criar Modelos de IA em infraestrutura totalmente gerenciada, criados especificamente para veiculação de baixa latência e treinamento de alto desempenho.
Outros recursos
Treinamento e previsões da Vertex AI com Cloud TPUs
Para clientes que procuram uma maneira mais simples de desenvolver modelos de IA, implante a Cloud TPU v5e com a Vertex AI, uma plataforma completa para criar Modelos de IA em infraestrutura totalmente gerenciada, criados especificamente para veiculação de baixa latência e treinamento de alto desempenho.
Preços
| Preços da Cloud TPU | Todos os preços da Cloud TPU são calculados por hora de chip | ||
|---|---|---|---|
| Versão da Cloud TPU | Preço de avaliação (USD) | Compromisso de um ano (USD) | Compromisso de três anos (USD) |
Trillium | A partir de US$ 2,70 por chip/hora | A partir de US$ 1,8900 por chip/hora | A partir de US$ 1,22 por chip/hora |
Cloud TPU v5p | A partir de US$ 4,2000 por chip/hora | A partir de US$ 2,9400 por chip/hora | A partir de US$ 1,8900 por chip/hora |
Cloud TPU v5e | A partir de US$ 1,2000 por chip/hora | A partir de US$ 0,8400 por chip/hora | A partir de US$ 0,5400 por chip/hora |
Os preços da Cloud TPU variam de acordo com o produto e a região.
Preços da Cloud TPU
Todos os preços da Cloud TPU são calculados por hora de chip
Trillium
Starting at
US$ 2,70
por chip/hora
Starting at
US$ 1,8900
por chip/hora
Starting at
US$ 1,22
por chip/hora
Cloud TPU v5p
Starting at
US$ 4,2000
por chip/hora
Starting at
US$ 2,9400
por chip/hora
Starting at
US$ 1,8900
por chip/hora
Cloud TPU v5e
Starting at
US$ 1,2000
por chip/hora
Starting at
US$ 0,8400
por chip/hora
Starting at
US$ 0,5400
por chip/hora
Os preços da Cloud TPU variam de acordo com o produto e a região.











