Cloud Tensor Processing Unit (TPU)
Mempercepat pengembangan AI dengan Google Cloud TPU
Tidak yakin apakah TPU sesuai dengan kebutuhan Anda? Pelajari kapan saatnya harus menggunakan GPU atau CPU di instance Compute Engine untuk menjalankan workload machine learning.

Ringkasan
Apa itu Tensor Processing Unit (TPU)?
Google Cloud TPU adalah akselerator AI yang dirancang khusus serta dioptimalkan untuk pelatihan dan inferensi model AI. Google Cloud TPU cocok untuk berbagai kasus penggunaan, seperti agen, pembuatan kode, pembuatan konten media, ucapan sintetis, layanan visi, mesin pemberi saran, model personalisasi, dan lainnya. TPU mendukung Gemini, dan semua aplikasi yang didukung AI Google seperti Penelusuran, Foto, dan Maps, semuanya melayani lebih dari 1 Miliar pengguna.
Apa saja keuntungan Cloud TPU?
Cloud TPU dirancang untuk menskalakan berbagai workload AI secara hemat biaya, termasuk pelatihan, fine-tuning, dan inferensi. Cloud TPU memberikan fleksibilitas untuk mempercepat workload pada framework AI terkemuka, termasuk PyTorch, JAX, dan TensorFlow. Orkestrasikan workload AI berskala besar dengan lancar melalui integrasi Cloud TPU di Google Kubernetes Engine (GKE). Manfaatkan Dynamic Workload Scheduler untuk meningkatkan skalabilitas workload dengan menjadwalkan semua akselerator yang diperlukan secara bersamaan. Pelanggan yang mencari cara paling sederhana untuk mengembangkan model AI juga dapat memanfaatkan Cloud TPU di Vertex AI, platform AI yang terkelola sepenuhnya.
Kapan harus menggunakan Cloud TPU?
Apa perbedaan Cloud TPU dengan GPU?
GPU adalah pemroses khusus yang awalnya dirancang untuk memanipulasi grafis komputer. Dengan struktur paralelnya, GPU cocok untuk algoritma yang memproses blok data besar yang biasanya ditemukan dalam workload AI. Pelajari lebih lanjut.
TPU adalah application-specific integrated circuit (ASIC) yang dirancang oleh Google untuk jaringan neural. TPU memiliki fitur khusus, seperti matrix multiply unit (MXU) dan topologi interkoneksi eksklusif, sehingga cocok untuk mempercepat pelatihan dan inferensi AI.
Versi Cloud TPU
| Versi Cloud TPU | Deskripsi | Ketersediaan |
|---|---|---|
Trillium | Cloud TPU paling canggih saat ini | Trillium tersedia secara umum di Amerika Utara (region US East), Eropa (region West), dan Asia (region Northeast) |
Cloud TPU v5p | Cloud TPU yang paling canggih untuk melatih model AI | Cloud TPU v5p secara umum tersedia di Amerika Utara (region Timur AS) |
Cloud TPU v5e | Cloud TPU serbaguna untuk kebutuhan pelatihan dan inferensi | Cloud TPU v5e umumnya tersedia di Amerika Utara (region AS Tengah/Timur/Selatan/Barat), Eropa (region Barat), dan Asia (region Tenggara) |
Informasi tambahan tentang versi Cloud TPU
Trillium
Cloud TPU paling canggih saat ini
Trillium tersedia secara umum di Amerika Utara (region US East), Eropa (region West), dan Asia (region Northeast)
Cloud TPU v5p
Cloud TPU yang paling canggih untuk melatih model AI
Cloud TPU v5p secara umum tersedia di Amerika Utara (region Timur AS)
Cloud TPU v5e
Cloud TPU serbaguna untuk kebutuhan pelatihan dan inferensi
Cloud TPU v5e umumnya tersedia di Amerika Utara (region AS Tengah/Timur/Selatan/Barat), Eropa (region Barat), dan Asia (region Tenggara)
Informasi tambahan tentang versi Cloud TPU
Cara Kerjanya
Lihatlah lebih dalam keajaiban Google Cloud TPU, termasuk tampilan dalam yang langka dari pusat data tempat semua hal terjadi. Pelanggan menggunakan Cloud TPU untuk menjalankan beberapa workload AI terbesar di dunia dan keunggulan tersebut berasal dari lebih dari sekedar chip. Dalam video ini, lihat komponen sistem TPU, termasuk jaringan pusat data, tombol sirkuit optik, sistem pendingin air, verifikasi keamanan biometrik, dan banyak lagi.
Lihatlah lebih dalam keajaiban Google Cloud TPU, termasuk tampilan dalam yang langka dari pusat data tempat semua hal terjadi. Pelanggan menggunakan Cloud TPU untuk menjalankan beberapa workload AI terbesar di dunia dan keunggulan tersebut berasal dari lebih dari sekedar chip. Dalam video ini, lihat komponen sistem TPU, termasuk jaringan pusat data, tombol sirkuit optik, sistem pendingin air, verifikasi keamanan biometrik, dan banyak lagi.

Penggunaan Umum
Menjalankan workload pelatihan AI berskala besar
Cara Menskalakan Model
Melatih LLM sering kali terasa seperti ilmu sihir, tetapi memahami dan mengoptimalkan performa model Anda tidak harus seperti itu. Buku ini bertujuan untuk menjelaskan ilmu di balik penskalaan model bahasa di TPU: cara kerja TPU dan cara TPU berkomunikasi satu sama lain, cara LLM berjalan di hardware sungguhan, serta cara melakukan paralelisasi model Anda selama pelatihan dan inferensi agar berjalan secara efisien dalam skala besar.

Pelatihan AI yang andal, skalabel, dan efisien
Maksimalkan performa, efisiensi, dan waktu pemerolehan manfaat dengan Cloud TPU. Skalakan ke ribuan chip dengan pelatihan Cloud TPU Multislice. Ukur dan tingkatkan produktivitas pelatihan ML skala besar dengan Pengukuran Goodput ML. Mulai dengan cepat menggunakan MaxText dan MaxDiffusion, deployment referensi open source untuk pelatihan model besar.

Petunjuk
Cara Menskalakan Model
Melatih LLM sering kali terasa seperti ilmu sihir, tetapi memahami dan mengoptimalkan performa model Anda tidak harus seperti itu. Buku ini bertujuan untuk menjelaskan ilmu di balik penskalaan model bahasa di TPU: cara kerja TPU dan cara TPU berkomunikasi satu sama lain, cara LLM berjalan di hardware sungguhan, serta cara melakukan paralelisasi model Anda selama pelatihan dan inferensi agar berjalan secara efisien dalam skala besar.
Referensi tambahan
Pelatihan AI yang andal, skalabel, dan efisien
Maksimalkan performa, efisiensi, dan waktu pemerolehan manfaat dengan Cloud TPU. Skalakan ke ribuan chip dengan pelatihan Cloud TPU Multislice. Ukur dan tingkatkan produktivitas pelatihan ML skala besar dengan Pengukuran Goodput ML. Mulai dengan cepat menggunakan MaxText dan MaxDiffusion, deployment referensi open source untuk pelatihan model besar.
Meningkatkan kualitas model AI dasar
Menyesuaikan LLM untuk aplikasi Anda dengan Pytorch/XLA
Tingkatkan kualitas model dasar secara efisien dengan memanfaatkan data pelatihan Anda sendiri yang mewakili kasus penggunaan Anda. Cloud TPU v5e memberikan performa fine-tuning LLM per dolar hingga 1,9x lebih tinggi dibandingkan Cloud TPU v4.

Referensi tambahan
Menyesuaikan LLM untuk aplikasi Anda dengan Pytorch/XLA
Tingkatkan kualitas model dasar secara efisien dengan memanfaatkan data pelatihan Anda sendiri yang mewakili kasus penggunaan Anda. Cloud TPU v5e memberikan performa fine-tuning LLM per dolar hingga 1,9x lebih tinggi dibandingkan Cloud TPU v4.
Melayani workload inferensi AI berskala besar
Inferensi yang berperforma tinggi, skalabel, dan hemat biaya
Mempercepat Inferensi AI dengan JetStream dan MaxDiffusion. JetStream adalah mesin inferensi baru yang dirancang khusus untuk inferensi Model Bahasa Besar (LLM). JetStream menghadirkan kemajuan yang signifikan dalam hal performa dan efisiensi biaya, yang menawarkan throughput dan latensi yang tak tertandingi untuk inferensi LLM di Cloud TPU. MaxDiffusion adalah serangkaian implementasi model difusi yang dioptimalkan untuk Cloud TPU, sehingga memudahkan untuk menjalankan inferensi model difusi pada Cloud TPU dengan performa tinggi.
Memaksimalkan performa/$ dengan infrastruktur AI yang dapat diskalakan
Cloud TPU v5e memungkinkan inferensi berperforma tinggi dan hemat biaya untuk berbagai workload AI, termasuk model LLM dan AI Generatif terbaru. TPU v5e menghadirkan performa throughput hingga 2,5x per dolar lebih banyak dan kecepatan hingga 1,7x dibandingkan Cloud TPU v4. Setiap chip TPU v5e menyediakan hingga 393 triliun operasi int8 per detik, sehingga memungkinkan model kompleks membuat prediksi dengan cepat. Pod TPU v5e menghasilkan hingga 100 kuadriliun operasi int8 per detik, atau 100 petaOps daya komputasi.

Petunjuk
Inferensi yang berperforma tinggi, skalabel, dan hemat biaya
Mempercepat Inferensi AI dengan JetStream dan MaxDiffusion. JetStream adalah mesin inferensi baru yang dirancang khusus untuk inferensi Model Bahasa Besar (LLM). JetStream menghadirkan kemajuan yang signifikan dalam hal performa dan efisiensi biaya, yang menawarkan throughput dan latensi yang tak tertandingi untuk inferensi LLM di Cloud TPU. MaxDiffusion adalah serangkaian implementasi model difusi yang dioptimalkan untuk Cloud TPU, sehingga memudahkan untuk menjalankan inferensi model difusi pada Cloud TPU dengan performa tinggi.
Referensi tambahan
Memaksimalkan performa/$ dengan infrastruktur AI yang dapat diskalakan
Cloud TPU v5e memungkinkan inferensi berperforma tinggi dan hemat biaya untuk berbagai workload AI, termasuk model LLM dan AI Generatif terbaru. TPU v5e menghadirkan performa throughput hingga 2,5x per dolar lebih banyak dan kecepatan hingga 1,7x dibandingkan Cloud TPU v4. Setiap chip TPU v5e menyediakan hingga 393 triliun operasi int8 per detik, sehingga memungkinkan model kompleks membuat prediksi dengan cepat. Pod TPU v5e menghasilkan hingga 100 kuadriliun operasi int8 per detik, atau 100 petaOps daya komputasi.
Cloud TPU di GKE
Jalankan workload AI yang dioptimalkan dengan orkestrasi platform
Platform AI/ML yang tangguh mempertimbangkan lapisan berikut: (i) Orkestrasi infrastruktur yang mendukung GPU untuk pelatihan dan penyajian workload dalam skala besar, (ii) Integrasi fleksibel dengan komputasi terdistribusi dan framework pemrosesan data, dan (iii) Dukungan untuk beberapa tim di infrastruktur yang sama untuk memaksimalkan penggunaan resource.

Penskalaan yang mudah dengan GKE
Kombinasikan kecanggihan Cloud TPU dengan fleksibilitas dan skalabilitas GKE untuk membangun dan men-deploy model machine learning dengan lebih cepat dan mudah dibandingkan sebelumnya. Dengan Cloud TPU yang tersedia di GKE, Anda kini dapat memiliki satu lingkungan operasi yang konsisten untuk semua workload Anda, yang menstandarkan pipeline MLOps otomatis.
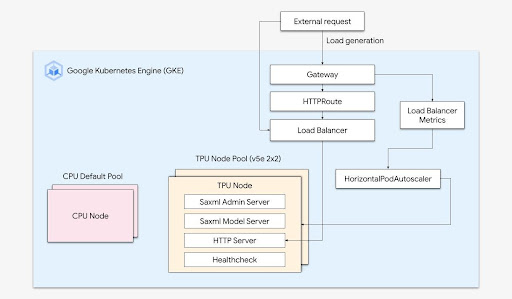
Petunjuk
Jalankan workload AI yang dioptimalkan dengan orkestrasi platform
Platform AI/ML yang tangguh mempertimbangkan lapisan berikut: (i) Orkestrasi infrastruktur yang mendukung GPU untuk pelatihan dan penyajian workload dalam skala besar, (ii) Integrasi fleksibel dengan komputasi terdistribusi dan framework pemrosesan data, dan (iii) Dukungan untuk beberapa tim di infrastruktur yang sama untuk memaksimalkan penggunaan resource.
Referensi tambahan
Penskalaan yang mudah dengan GKE
Kombinasikan kecanggihan Cloud TPU dengan fleksibilitas dan skalabilitas GKE untuk membangun dan men-deploy model machine learning dengan lebih cepat dan mudah dibandingkan sebelumnya. Dengan Cloud TPU yang tersedia di GKE, Anda kini dapat memiliki satu lingkungan operasi yang konsisten untuk semua workload Anda, yang menstandarkan pipeline MLOps otomatis.
Cloud TPU di Vertex AI
Vertex AI Training & Prediction dengan Cloud TPU
Bagi pelanggan yang mencari cara paling sederhana untuk mengembangkan model AI, Anda dapat men-deploy Cloud TPU v5e dengan Vertex AI, sebuah platform menyeluruh untuk membangun model AI pada infrastruktur yang terkelola sepenuhnya dan dibuat khusus untuk layanan berlatensi rendah dan pelatihan berperforma tinggi.
Referensi tambahan
Vertex AI Training & Prediction dengan Cloud TPU
Bagi pelanggan yang mencari cara paling sederhana untuk mengembangkan model AI, Anda dapat men-deploy Cloud TPU v5e dengan Vertex AI, sebuah platform menyeluruh untuk membangun model AI pada infrastruktur yang terkelola sepenuhnya dan dibuat khusus untuk layanan berlatensi rendah dan pelatihan berperforma tinggi.
Harga
| Harga Cloud TPU | Semua harga Cloud TPU adalah per chip-jam | ||
|---|---|---|---|
| Versi Cloud TPU | Harga Evaluasi (USD) | Komitmen 1 tahun (USD) | Komitmen 3 tahun (USD) |
Trillium | Mulai dari $2,7000 per chip-jam | Mulai dari $1,8900 per chip-jam | Mulai dari $1,2200 per chip-jam |
Cloud TPU v5p | Mulai dari $4,2000 per chip-jam | Mulai dari $2,9400 per chip-jam | Mulai dari $1,8900 per chip-jam |
Cloud TPU v5e | Mulai dari $1,2000 per chip-jam | Mulai dari $0,8400 per chip-jam | Mulai dari $0,5400 per chip-jam |
Harga Cloud TPU bervariasi menurut produk dan region.
Harga Cloud TPU
Semua harga Cloud TPU adalah per chip-jam
Trillium
Starting at
$2,7000
per chip-jam
Starting at
$1,8900
per chip-jam
Starting at
$1,2200
per chip-jam
Cloud TPU v5p
Starting at
$4,2000
per chip-jam
Starting at
$2,9400
per chip-jam
Starting at
$1,8900
per chip-jam
Cloud TPU v5e
Starting at
$1,2000
per chip-jam
Starting at
$0,8400
per chip-jam
Starting at
$0,5400
per chip-jam
Harga Cloud TPU bervariasi menurut produk dan region.











