Cloud Tensor Processing Unit (TPU)
Acelera el desarrollo de IA con Google Cloud TPU
¿No sabes si las TPU son adecuadas? Aprende cuándo usar GPU o CPU en las instancias de Compute Engine para ejecutar tus cargas de trabajo de aprendizaje automático.

Descripción general
¿Qué es una unidad de procesamiento tensorial (TPU)?
Las Google Cloud TPU son aceleradores de IA con diseño personalizado que están optimizadas para el entrenamiento y la inferencia de grandes modelos de IA. Son ideales para una variedad de casos de uso, como agentes, generación de código, generación de contenido multimedia, voz sintética, servicios de visión, motores de recomendaciones y modelos de personalización, entre otros. Las TPU impulsan Gemini y todas las aplicaciones potenciadas por IA de Google, como la Búsqueda, Fotos y Maps, que sirven a más de 1,000 millones de usuarios.
¿Cuáles son las ventajas de las Cloud TPU?
Las Cloud TPU están diseñadas para escalar de manera rentable en una amplia variedad de cargas de trabajo de IA, que abarcan el entrenamiento, los ajustes y la inferencia. Las Cloud TPU proporcionan la versatilidad necesaria para acelerar las cargas de trabajo en frameworks de IA líderes, como PyTorch, JAX y TensorFlow. Organiza sin problemas cargas de trabajo de IA a gran escala a través de la integración de Cloud TPU en Google Kubernetes Engine (GKE). Aprovecha el programador dinámico de cargas de trabajo para mejorar la escalabilidad de las cargas de trabajo a través de la programación de todos los aceleradores necesarios de forma simultánea. Los clientes que buscan la forma más sencilla de desarrollar modelos de IA también pueden aprovechar las Cloud TPU en Vertex AI, una plataforma de IA completamente administrada.
¿Cuándo usar Cloud TPUs?
¿En qué se diferencian las Cloud TPU de las GPU?
Una GPU es un procesador especializado y diseñado originalmente para manipular gráficos por computadora. Su estructura paralela las hace ideales para los algoritmos que procesan grandes bloques de datos que suelen encontrarse en las cargas de trabajo de IA. Obtener más información.
Una TPU es un circuito integrado específico de la aplicación (ASIC) diseñado por Google para redes neuronales. Las TPU poseen funciones especializadas, como las unidades de multiplicación de matrices (MXU) y la topología de interconexión patentada, que las hacen ideales para acelerar el entrenamiento y la inferencia de la IA.
Versiones de Cloud TPU
| Versión de Cloud TPU | Descripción | Disponibilidad |
|---|---|---|
Trillium | El Cloud TPU más avanzado hasta la fecha | Trillium está disponible de forma general en Norteamérica (región oriental de EE.UU.), Europa (región occidental) y Asia (región nororiental) |
Cloud TPU v5p | La Cloud TPU más potente para entrenar modelos de IA | Cloud TPU v5p tiene disponibilidad general en Norteamérica (región del este de EE.UU.). |
Cloud TPU v5e | Un Cloud TPU versátil para las necesidades de entrenamiento y de inferencia | Cloud TPU v5e tiene disponibilidad general en Norteamérica (regiones Central/Este/Sur/Oeste de EE.UU.), Europa (región occidental) y Asia (región del Sudeste). |
Información adicional sobre las versiones de Cloud TPU
Trillium
El Cloud TPU más avanzado hasta la fecha
Trillium está disponible de forma general en Norteamérica (región oriental de EE.UU.), Europa (región occidental) y Asia (región nororiental)
Cloud TPU v5p
La Cloud TPU más potente para entrenar modelos de IA
Cloud TPU v5p tiene disponibilidad general en Norteamérica (región del este de EE.UU.).
Cloud TPU v5e
Un Cloud TPU versátil para las necesidades de entrenamiento y de inferencia
Cloud TPU v5e tiene disponibilidad general en Norteamérica (regiones Central/Este/Sur/Oeste de EE.UU.), Europa (región occidental) y Asia (región del Sudeste).
Información adicional sobre las versiones de Cloud TPU
Cómo funciona
Descubre la magia de las Google Cloud TPU, incluida una vista inusual de los centros de datos en los que todo ocurre. Los clientes usan las Cloud TPU para ejecutar algunas de las cargas de trabajo de IA más grandes del mundo, y esa potencia proviene de mucho más que un chip. En este video, observarás los componentes del sistema de TPU, incluidas las redes de los centros de datos, los interruptores de circuitos ópticos, los sistemas de enfriamiento de agua, la verificación de seguridad biométrica y mucho más.
Descubre la magia de las Google Cloud TPU, incluida una vista inusual de los centros de datos en los que todo ocurre. Los clientes usan las Cloud TPU para ejecutar algunas de las cargas de trabajo de IA más grandes del mundo, y esa potencia proviene de mucho más que un chip. En este video, observarás los componentes del sistema de TPU, incluidas las redes de los centros de datos, los interruptores de circuitos ópticos, los sistemas de enfriamiento de agua, la verificación de seguridad biométrica y mucho más.

Usos comunes
Ejecuta cargas de trabajo de entrenamiento de IA a gran escala
Cómo escalar tu modelo
Entrenar LLMs a menudo se siente como alquimia, pero entender y optimizar el rendimiento de tus modelos no tiene que ser así. Este libro tiene como objetivo desmitificar la ciencia de escalar modelos de lenguaje en TPU: cómo funcionan y cómo se comunican entre sí, cómo se ejecutan los LLM en hardware real y cómo paralelizar los modelos durante el entrenamiento y la inferencia para que se ejecuten de forma eficiente a gran escala.

Entrenamiento de IA potente, escalable y eficiente
Maximiza el rendimiento, la eficiencia y el tiempo de generación de valor con Cloud TPU.Escala a miles de chips con el entrenamiento de Cloud TPU Multislice.Mide y mejora la productividad del entrenamiento de AA a gran escala con ML Goodput Measurement.Comienza rápidamente con MaxText y MaxDiffusion, implementaciones de referencia de código abierto para el entrenamiento de modelos grandes.

Instructivos
Cómo escalar tu modelo
Entrenar LLMs a menudo se siente como alquimia, pero entender y optimizar el rendimiento de tus modelos no tiene que ser así. Este libro tiene como objetivo desmitificar la ciencia de escalar modelos de lenguaje en TPU: cómo funcionan y cómo se comunican entre sí, cómo se ejecutan los LLM en hardware real y cómo paralelizar los modelos durante el entrenamiento y la inferencia para que se ejecuten de forma eficiente a gran escala.
Recursos adicionales
Entrenamiento de IA potente, escalable y eficiente
Maximiza el rendimiento, la eficiencia y el tiempo de generación de valor con Cloud TPU.Escala a miles de chips con el entrenamiento de Cloud TPU Multislice.Mide y mejora la productividad del entrenamiento de AA a gran escala con ML Goodput Measurement.Comienza rápidamente con MaxText y MaxDiffusion, implementaciones de referencia de código abierto para el entrenamiento de modelos grandes.
Ajusta los modelos de base de IA
Adapta los LLM a tus aplicaciones con Pytorch/XLA
Ajusta de manera eficaz los modelos de base a través del aprovechamiento de tus propios datos de entrenamiento que representan tu caso de uso. Cloud TPU v5e ofrece un rendimiento de ajuste de los LLM hasta 1.9 veces superior por dólar en comparación con Cloud TPU v4.

Recursos adicionales
Adapta los LLM a tus aplicaciones con Pytorch/XLA
Ajusta de manera eficaz los modelos de base a través del aprovechamiento de tus propios datos de entrenamiento que representan tu caso de uso. Cloud TPU v5e ofrece un rendimiento de ajuste de los LLM hasta 1.9 veces superior por dólar en comparación con Cloud TPU v4.
Entrega cargas de trabajo de inferencia de IA a gran escala
Inferencia de alto rendimiento, escalable y rentable
Acelera la inferencia de IA con JetStream y MaxDiffusion. JetStream es un nuevo motor de inferencia diseñado específicamente para la inferencia de modelos de lenguaje grandes (LLM). JetStream representa un avance significativo en rendimiento y rentabilidad, ya que ofrece una capacidad de procesamiento y latencia inigualables para la inferencia de LLM en Cloud TPU. MaxDiffusion es un conjunto de implementaciones de modelos de difusión optimizadas para Cloud TPU, lo que facilita la ejecución de inferencias de modelos de difusión en Cloud TPU con alto rendimiento.
Maximiza el rendimiento/$ con infraestructura de IA que escala
Cloud TPU v5e permite una inferencia rentable y de alto rendimiento para una amplia variedad de cargas de trabajo de IA, incluidos los LLMs y los modelos de IA generativa más recientes. TPU v5e ofrece hasta 2.5 veces más rendimiento por dólar y 1.7 veces más velocidad en comparación con Cloud TPU v4. Cada chip TPU v5e proporciona hasta 393 billones de operaciones int8 por segundo, lo que permite que los modelos complejos hagan predicciones rápidas. Un pod de TPU v5e ofrece hasta 100,000 billones de operaciones int8 por segundo o 100 petaOps de potencia de procesamiento.

Instructivos
Inferencia de alto rendimiento, escalable y rentable
Acelera la inferencia de IA con JetStream y MaxDiffusion. JetStream es un nuevo motor de inferencia diseñado específicamente para la inferencia de modelos de lenguaje grandes (LLM). JetStream representa un avance significativo en rendimiento y rentabilidad, ya que ofrece una capacidad de procesamiento y latencia inigualables para la inferencia de LLM en Cloud TPU. MaxDiffusion es un conjunto de implementaciones de modelos de difusión optimizadas para Cloud TPU, lo que facilita la ejecución de inferencias de modelos de difusión en Cloud TPU con alto rendimiento.
Recursos adicionales
Maximiza el rendimiento/$ con infraestructura de IA que escala
Cloud TPU v5e permite una inferencia rentable y de alto rendimiento para una amplia variedad de cargas de trabajo de IA, incluidos los LLMs y los modelos de IA generativa más recientes. TPU v5e ofrece hasta 2.5 veces más rendimiento por dólar y 1.7 veces más velocidad en comparación con Cloud TPU v4. Cada chip TPU v5e proporciona hasta 393 billones de operaciones int8 por segundo, lo que permite que los modelos complejos hagan predicciones rápidas. Un pod de TPU v5e ofrece hasta 100,000 billones de operaciones int8 por segundo o 100 petaOps de potencia de procesamiento.
Cloud TPU en GKE
Ejecuta cargas de trabajo de IA optimizadas con organización de plataformas
Una plataforma sólida de IA y AA tiene en cuenta las siguientes capas: (i) organización de infraestructura que admite GPU para entrenar y entregar cargas de trabajo a gran escala, (ii) integración flexible con frameworks de computación distribuida y procesamiento de datos, y (iii) compatibilidad para que varios equipos trabajen en la misma infraestructura, de modo que se maximice el uso de los recursos.

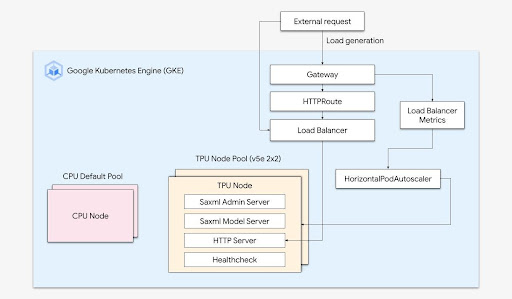
Escalamiento sin esfuerzo con GKE
Combina la potencia de las Cloud TPUs con la flexibilidad y escalabilidad de GKE para compilar y, luego, implementar modelos de aprendizaje automático más rápido y con más facilidad que nunca. Con las Cloud TPUs disponibles en GKE, ahora puedes tener un solo entorno de operaciones coherente para todas tus cargas de trabajo, lo que estandariza las canalizaciones automatizadas de MLOps.
Instructivos
Ejecuta cargas de trabajo de IA optimizadas con organización de plataformas
Una plataforma sólida de IA y AA tiene en cuenta las siguientes capas: (i) organización de infraestructura que admite GPU para entrenar y entregar cargas de trabajo a gran escala, (ii) integración flexible con frameworks de computación distribuida y procesamiento de datos, y (iii) compatibilidad para que varios equipos trabajen en la misma infraestructura, de modo que se maximice el uso de los recursos.
Recursos adicionales
Escalamiento sin esfuerzo con GKE
Combina la potencia de las Cloud TPUs con la flexibilidad y escalabilidad de GKE para compilar y, luego, implementar modelos de aprendizaje automático más rápido y con más facilidad que nunca. Con las Cloud TPUs disponibles en GKE, ahora puedes tener un solo entorno de operaciones coherente para todas tus cargas de trabajo, lo que estandariza las canalizaciones automatizadas de MLOps.
Cloud TPU en Vertex AI
Entrenamiento y predicciones de Vertex AI con Cloud TPU
Para los clientes que buscan una forma más sencilla de desarrollar modelos de IA, pueden implementar Cloud TPU v5e con Vertex AI, una plataforma de extremo a extremo para crear modelos de IA en una infraestructura completamente administrada creada para brindar entregas de latencia baja y un entrenamiento de alto rendimiento.
Recursos adicionales
Entrenamiento y predicciones de Vertex AI con Cloud TPU
Para los clientes que buscan una forma más sencilla de desarrollar modelos de IA, pueden implementar Cloud TPU v5e con Vertex AI, una plataforma de extremo a extremo para crear modelos de IA en una infraestructura completamente administrada creada para brindar entregas de latencia baja y un entrenamiento de alto rendimiento.
Precios
| Precios de Cloud TPU | Todos los precios de Cloud TPU se calculan por hora de chip. | ||
|---|---|---|---|
| Versión de Cloud TPU | Precio de evaluación (USD) | Compromiso por 1 año (USD) | Compromiso por 3 años (USD) |
Trillium | A partir de $2.7000 por hora chip | A partir de $1.8900 por hora chip | A partir de $1.2200 por hora chip |
Cloud TPU v5p | A partir de $4.2000 por hora chip | A partir de $2.9400 por hora chip | A partir de $1.8900 por hora chip |
Cloud TPU v5e | A partir de $1.2000 por hora chip | A partir de $0.8400 por hora chip | A partir de $0.5400 por hora chip |
Los precios de Cloud TPU varían según el producto y la región.
Precios de Cloud TPU
Todos los precios de Cloud TPU se calculan por hora de chip.
Trillium
Starting at
$2.7000
por hora chip
Starting at
$1.8900
por hora chip
Starting at
$1.2200
por hora chip
Cloud TPU v5p
Starting at
$4.2000
por hora chip
Starting at
$2.9400
por hora chip
Starting at
$1.8900
por hora chip
Cloud TPU v5e
Starting at
$1.2000
por hora chip
Starting at
$0.8400
por hora chip
Starting at
$0.5400
por hora chip
Los precios de Cloud TPU varían según el producto y la región.











