Cloud Tensor Processing Units (TPUs)
AI-Entwicklung mit Google Cloud TPUs beschleunigen
Sie sind sich nicht sicher, ob TPUs die richtige Wahl sind? Hier erfahren Sie, wann Sie in Compute Engine-Instanzen GPUs oder CPUs zum Ausführen Ihrer ML-Arbeitslasten verwenden sollten.

Überblick
Was ist eine Tensor Processing Unit (TPU)?
Google Cloud TPUs sind speziell entwickelte KI-Beschleuniger, die für das Training und die Inferenz AI-Modelle optimiert sind. Sie eignen sich ideal für eine Vielzahl von Anwendungsfällen, z. B. Agents, Codegenerierung, Generierung von Medieninhalten, synthetische Sprache, Vision-Dienste, Empfehlungssysteme, Personalisierungsmodelle usw. TPUs werden für Gemini und alle KI-gestützten Anwendungen von Google wie die Google Suche, Google Fotos und Google Maps verwendet, die insgesamt über eine Milliarde Nutzer haben.
Welche Vorteile bieten Cloud TPUs?
Cloud TPUs sind darauf ausgelegt, eine kosteneffiziente Skalierung für eine Vielzahl von KI-Arbeitslasten zu ermöglichen – von Training über Feinabstimmung bis hin zu Inferenz. Cloud TPUs bieten die Vielseitigkeit, um Arbeitslasten in führenden KI-Frameworks wie PyTorch, JAX und TensorFlow zu erstellen. Große AI-Arbeitslasten lassen sich durch die Cloud TPU-Einbindung in Google Kubernetes Engine (GKE) nahtlos orchestrieren. Mit dem dynamischen Workload Scheduler können Sie alle benötigten Beschleuniger gleichzeitig planen und so die Skalierbarkeit von Arbeitslasten verbessern. Kunden, die AI-Modelle auf einfachste Art entwickeln möchten, können auch Cloud TPUs in Vertex AI, einer vollständig verwalteten AI-Plattform, nutzen.
Wann sollten Cloud TPUs verwendet werden?
Wie unterscheiden sich Cloud TPUs von GPUs?
Eine GPU ist ein spezieller Prozessor, der ursprünglich für die Manipulation von Computergrafiken entwickelt wurde. Ihre parallele Struktur macht sie ideal für Algorithmen, die große Datenblöcke verarbeiten, welche häufig in ML-Arbeitslasten enthalten sind. Weitere Informationen
Eine TPU ist ein anwendungsspezifischer integrierter Schaltkreis (Application-Specific Integrated Circuit, ASIC), der von Google für neuronale Netzwerke entwickelt wurde. TPUs haben spezielle Features wie die Matrixmultiplikationseinheit (MXU) und die proprietäre Interconnect-Topologie, die sich ideal für ein schnelleres KI-Training und für die Inferenz eignen.
Cloud TPU-Versionen
| Cloud TPU-Version | Beschreibung | Verfügbarkeit |
|---|---|---|
Trillium | Die bislang fortschrittlichste Cloud TPU | Trillium ist in Nordamerika (Region US East), Europa (Region West) und Asien (Region Northeast) allgemein verfügbar. |
Cloud TPU v5p | Die leistungsstärkste Cloud TPU zum Trainieren von KI-Modellen | Cloud TPU v5p ist allgemein in Nordamerika (Region „US-Ost“) verfügbar |
Cloud TPU v5e | Eine vielseitige Cloud TPU für Trainings- und Inferenzanforderungen | Cloud TPU v5e ist allgemein in Nordamerika (Regionen (Mittel-/Ost-/Süd-/West der USA), Europa (Westregion) und Asien (Südostregion) verfügbar |
Weitere Informationen zu Cloud TPU-Versionen
Trillium
Die bislang fortschrittlichste Cloud TPU
Trillium ist in Nordamerika (Region US East), Europa (Region West) und Asien (Region Northeast) allgemein verfügbar.
Cloud TPU v5p
Die leistungsstärkste Cloud TPU zum Trainieren von KI-Modellen
Cloud TPU v5p ist allgemein in Nordamerika (Region „US-Ost“) verfügbar
Cloud TPU v5e
Eine vielseitige Cloud TPU für Trainings- und Inferenzanforderungen
Cloud TPU v5e ist allgemein in Nordamerika (Regionen (Mittel-/Ost-/Süd-/West der USA), Europa (Westregion) und Asien (Südostregion) verfügbar
Weitere Informationen zu Cloud TPU-Versionen
Funktionsweise
Erhalten Sie einen Einblick in die Magie der Google Cloud TPUs und erhalten Sie einen seltenen Einblick in die Rechenzentren, in denen alles stattfindet. Kunden nutzen Cloud TPUs, um einige der weltweit größten KI-Arbeitslasten auszuführen, und die Leistung basiert nicht nur auf einem Chip. In diesem Video werfen wir einen Blick auf die Komponenten des TPU-Systems, darunter das Netzwerk von Rechenzentren, optische Schalter, Wasserkühlsysteme, biometrische Sicherheitsprüfung und mehr.
Erhalten Sie einen Einblick in die Magie der Google Cloud TPUs und erhalten Sie einen seltenen Einblick in die Rechenzentren, in denen alles stattfindet. Kunden nutzen Cloud TPUs, um einige der weltweit größten KI-Arbeitslasten auszuführen, und die Leistung basiert nicht nur auf einem Chip. In diesem Video werfen wir einen Blick auf die Komponenten des TPU-Systems, darunter das Netzwerk von Rechenzentren, optische Schalter, Wasserkühlsysteme, biometrische Sicherheitsprüfung und mehr.

Gängige Einsatzmöglichkeiten
Große KI-Trainingsarbeitslasten ausführen
Modell skalieren
Das Training von LLMs fühlt sich oft wie Alchemie an, aber die Leistung Ihrer Modelle zu verstehen und zu optimieren muss nicht so sein. Dieses Buch soll die Wissenschaft hinter der Skalierung von Language Models auf TPUs verständlich machen: Wie TPUs funktionieren und wie sie miteinander kommunizieren, wie LLMs auf echter Hardware ausgeführt werden und wie Sie Ihre Modelle während des Trainings und der Inferenz parallelisieren, damit sie in großem Maßstab effizient ausgeführt werden.

Leistungsstarkes, skalierbares und effizientes KI-Training
Maximieren Sie mit Cloud TPUs Leistung, Effizienz und Wertschöpfung.Skalieren Sie mit dem Cloud TPU-Multislice-Training auf Tausende von Chips.Messen und verbessern Sie mit ML Goodput Measurement die ML-Trainingsproduktivität in großem Maßstab.Mit MaxText und MaxDiffusion, den Open-Source-Referenzbereitstellungen für das Training großer Modelle, können Sie schnell loslegen.

Anleitungen
Modell skalieren
Das Training von LLMs fühlt sich oft wie Alchemie an, aber die Leistung Ihrer Modelle zu verstehen und zu optimieren muss nicht so sein. Dieses Buch soll die Wissenschaft hinter der Skalierung von Language Models auf TPUs verständlich machen: Wie TPUs funktionieren und wie sie miteinander kommunizieren, wie LLMs auf echter Hardware ausgeführt werden und wie Sie Ihre Modelle während des Trainings und der Inferenz parallelisieren, damit sie in großem Maßstab effizient ausgeführt werden.
Weitere Ressourcen
Leistungsstarkes, skalierbares und effizientes KI-Training
Maximieren Sie mit Cloud TPUs Leistung, Effizienz und Wertschöpfung.Skalieren Sie mit dem Cloud TPU-Multislice-Training auf Tausende von Chips.Messen und verbessern Sie mit ML Goodput Measurement die ML-Trainingsproduktivität in großem Maßstab.Mit MaxText und MaxDiffusion, den Open-Source-Referenzbereitstellungen für das Training großer Modelle, können Sie schnell loslegen.
Grundlegende KI-Modelle optimieren
LLMs mit Pytorch/XLA für Ihre Anwendungen anpassen
Sie können Basismodelle effizient optimieren, indem Sie Ihre eigenen Trainingsdaten für Ihren Anwendungsfall nutzen. Cloud TPU v5e bietet im Vergleich zu Cloud TPU v4 eine bis zu 1,9-mal höhere LLM-Feinabstimmungsleistung pro Dollar.

Weitere Ressourcen
LLMs mit Pytorch/XLA für Ihre Anwendungen anpassen
Sie können Basismodelle effizient optimieren, indem Sie Ihre eigenen Trainingsdaten für Ihren Anwendungsfall nutzen. Cloud TPU v5e bietet im Vergleich zu Cloud TPU v4 eine bis zu 1,9-mal höhere LLM-Feinabstimmungsleistung pro Dollar.
Große KI-Inferenzarbeitslasten bereitstellen
Skalierbare, kosteneffiziente Inferenz mit hoher Leistung
KI-Inferenzen mit JetStream und MaxDiffusion beschleunigen JetStream ist eine neue Inferenz-Engine, die speziell für LLM-Inferenzen (Large Language Model) entwickelt wurde. JetStream stellt einen erheblichen Fortschritt in puncto Leistung und Kosteneffizienz dar und bietet einen beispiellosen Durchsatz und eine beispiellose Latenz für LLM-Inferenzen auf Cloud TPUs. MaxDiffusion umfasst eine Reihe von Implementierungen von Diffusionsmodellen, die für Cloud TPUs optimiert sind. Dadurch wird die Ausführung von Inferenzen für Diffusionsmodelle auf Cloud TPUs mit hoher Leistung erleichtert.
Maximale Leistung/USD mit skalierbarer KI-Infrastruktur
Cloud TPU v5e ermöglicht leistungsstarke und kostengünstige Inferenz für eine Vielzahl von KI-Arbeitslasten, einschließlich der neuesten LLMs und Gen AI-Modelle. TPU v5e bietet eine bis zu 2,5-mal höhere Durchsatzleistung pro US-Dollar und eine bis zu 1,7-fache Beschleunigung gegenüber Cloud TPU v4. Jeder TPU v5e-Chip bietet bis zu 393 Billionen int8-Vorgänge pro Sekunde, sodass komplexe Modelle schnelle Vorhersagen treffen können. Ein TPU v5e-Pod bietet bis zu 100 Billiarden int8-Vorgänge pro Sekunde oder 100 PetaOps Rechenleistung.

Anleitungen
Skalierbare, kosteneffiziente Inferenz mit hoher Leistung
KI-Inferenzen mit JetStream und MaxDiffusion beschleunigen JetStream ist eine neue Inferenz-Engine, die speziell für LLM-Inferenzen (Large Language Model) entwickelt wurde. JetStream stellt einen erheblichen Fortschritt in puncto Leistung und Kosteneffizienz dar und bietet einen beispiellosen Durchsatz und eine beispiellose Latenz für LLM-Inferenzen auf Cloud TPUs. MaxDiffusion umfasst eine Reihe von Implementierungen von Diffusionsmodellen, die für Cloud TPUs optimiert sind. Dadurch wird die Ausführung von Inferenzen für Diffusionsmodelle auf Cloud TPUs mit hoher Leistung erleichtert.
Weitere Ressourcen
Maximale Leistung/USD mit skalierbarer KI-Infrastruktur
Cloud TPU v5e ermöglicht leistungsstarke und kostengünstige Inferenz für eine Vielzahl von KI-Arbeitslasten, einschließlich der neuesten LLMs und Gen AI-Modelle. TPU v5e bietet eine bis zu 2,5-mal höhere Durchsatzleistung pro US-Dollar und eine bis zu 1,7-fache Beschleunigung gegenüber Cloud TPU v4. Jeder TPU v5e-Chip bietet bis zu 393 Billionen int8-Vorgänge pro Sekunde, sodass komplexe Modelle schnelle Vorhersagen treffen können. Ein TPU v5e-Pod bietet bis zu 100 Billiarden int8-Vorgänge pro Sekunde oder 100 PetaOps Rechenleistung.
Cloud TPU in GKE
Optimierte KI-Arbeitslasten mit Plattformorchestrierung ausführen
Eine robuste KI-/ML-Plattform berücksichtigt die folgenden Ebenen: (i) Infrastrukturorchestrierung, die GPUs zum Trainieren und Bereitstellen von Arbeitslasten in großem Maßstab unterstützt, (ii) Flexible Einbindung in verteiltes Computing und Datenverarbeitungs-Frameworks und (iii) Unterstützung für mehrere Teams in derselben Infrastruktur, um die Ressourcennutzung zu maximieren.

Mühelose Skalierung mit GKE
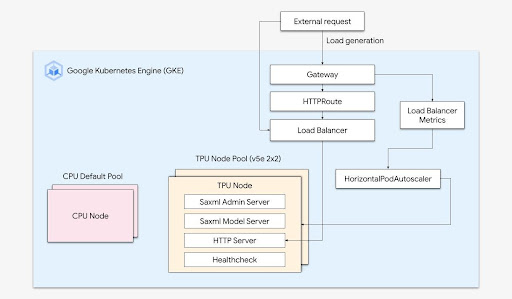
Kombinieren Sie die Leistungsfähigkeit von Cloud TPUs mit der Flexibilität und Skalierbarkeit von GKE, um Modelle für maschinelles Lernen schneller und einfacher als je zuvor zu erstellen und bereitzustellen. Dank der in GKE verfügbaren Cloud TPUs haben Sie jetzt eine einzige konsistente Betriebsumgebung für alle Arbeitslasten und können damit automatisierte MLOps-Pipelines standardisieren.
Anleitungen
Optimierte KI-Arbeitslasten mit Plattformorchestrierung ausführen
Eine robuste KI-/ML-Plattform berücksichtigt die folgenden Ebenen: (i) Infrastrukturorchestrierung, die GPUs zum Trainieren und Bereitstellen von Arbeitslasten in großem Maßstab unterstützt, (ii) Flexible Einbindung in verteiltes Computing und Datenverarbeitungs-Frameworks und (iii) Unterstützung für mehrere Teams in derselben Infrastruktur, um die Ressourcennutzung zu maximieren.
Weitere Ressourcen
Mühelose Skalierung mit GKE
Kombinieren Sie die Leistungsfähigkeit von Cloud TPUs mit der Flexibilität und Skalierbarkeit von GKE, um Modelle für maschinelles Lernen schneller und einfacher als je zuvor zu erstellen und bereitzustellen. Dank der in GKE verfügbaren Cloud TPUs haben Sie jetzt eine einzige konsistente Betriebsumgebung für alle Arbeitslasten und können damit automatisierte MLOps-Pipelines standardisieren.
Cloud TPU in Vertex AI
Vertex AI – Training und Vorhersagen mit Cloud TPUs
Kunden, die nach der einfachsten Möglichkeit zur Entwicklung von KI-Modellen suchen, können Cloud TPU v5e mit Vertex AI bereitstellen, einer End-to-End-Plattform zum Erstellen von KI-Modellen auf einer vollständig verwalteten Infrastruktur, die auf Bereitstellung mit niedriger Latenz und Hochleistungstraining ausgelegt ist.
Weitere Ressourcen
Vertex AI – Training und Vorhersagen mit Cloud TPUs
Kunden, die nach der einfachsten Möglichkeit zur Entwicklung von KI-Modellen suchen, können Cloud TPU v5e mit Vertex AI bereitstellen, einer End-to-End-Plattform zum Erstellen von KI-Modellen auf einer vollständig verwalteten Infrastruktur, die auf Bereitstellung mit niedriger Latenz und Hochleistungstraining ausgelegt ist.
Preise
| Cloud TPU-Preise | Alle Cloud TPU-Preise werden pro Chipstunde berechnet | ||
|---|---|---|---|
| Cloud TPU-Version | Kennenlernpreis (in $) | Zusicherung für 1 Jahr (USD) | Zusicherung für 3 Jahre (USD) |
Trillium | Ab 2,7000 $ pro Chipstunde | Ab 1,8900 $ pro Chipstunde | Ab 1,2200 $ pro Chipstunde |
Cloud TPU v5p | Ab 4,2000 $ pro Chipstunde | Ab 2,9400 $ pro Chipstunde | Ab 1,8900 $ pro Chipstunde |
Cloud TPU v5e | Ab 1,2000 $ pro Chipstunde | Ab 0,8400 $ pro Chipstunde | Ab 0,5400 $ pro Chipstunde |
Cloud TPU-Preise variieren je nach Produkt und Region.
Cloud TPU-Preise
Alle Cloud TPU-Preise werden pro Chipstunde berechnet
Trillium
Starting at
2,7000 $
pro Chipstunde
Starting at
1,8900 $
pro Chipstunde
Starting at
1,2200 $
pro Chipstunde
Cloud TPU v5p
Starting at
4,2000 $
pro Chipstunde
Starting at
2,9400 $
pro Chipstunde
Starting at
1,8900 $
pro Chipstunde
Cloud TPU v5e
Starting at
1,2000 $
pro Chipstunde
Starting at
0,8400 $
pro Chipstunde
Starting at
0,5400 $
pro Chipstunde
Cloud TPU-Preise variieren je nach Produkt und Region.











