Cloud Tensor Processing Units (TPU)
Accelera lo sviluppo dell'IA con Google Cloud TPU
Non sai se le TPU sono adatte a te? Scopri quando utilizzare GPU o CPU su istanze Compute Engine per eseguire i carichi di lavoro di machine learning.

Panoramica
Che cos'è una Tensor Processing Unit (TPU)?
Le Google Cloud TPU sono acceleratori AI progettati su misura, ottimizzati per l'addestramento e l'inferenza di modelli AI. Sono ideali per una varietà di casi d'uso, tra cui agenti, generazione di codice, generazione di contenuti multimediali, sintesi vocale, servizi di visione artificiale, motori per suggerimenti e modelli di personalizzazione, tra gli altri. Le TPU sono alla base di Gemini e di tutte le applicazioni basate sull'AI di Google, come la Ricerca, Foto e Maps, che servono oltre 1 miliardo di utenti.
Quali sono i vantaggi delle Cloud TPU?
Le Cloud TPU sono progettate per scalare in modo economico per un'ampia gamma di carichi di lavoro IA, compresi addestramento, ottimizzazione e inferenza. Le Cloud TPU offrono la versatilità per accelerare i carichi di lavoro sui principali framework di IA, tra cui PyTorch, JAX e TensorFlow. Orchestra senza problemi carichi di lavoro di IA su larga scala tramite l'integrazione di Cloud TPU in Google Kubernetes Engine (GKE). Utilizza Dynamic Workload Scheduler per migliorare la scalabilità dei carichi di lavoro pianificando tutti gli acceleratori necessari contemporaneamente. I clienti che cercano il modo più semplice per sviluppare modelli di IA possono sfruttare le Cloud TPU anche in Vertex AI, una piattaforma di AI completamente gestita.
Quando utilizzare le Cloud TPU?
Quali sono le differenze tra le Cloud TPU e le GPU?
Una GPU è un processore specializzato progettato originariamente per la manipolazione della grafica computerizzata. La loro struttura parallela le rende ideali per algoritmi che elaborano grandi blocchi di dati presenti in genere nei carichi di lavoro di IA. Scopri di più.
Una TPU è un circuito integrato specifico per applicazioni (ASIC) progettato da Google per le reti neurali. Le TPU dispongono di funzionalità specializzate, come l'unità di moltiplicazione a matrice (MXU) e la topologia di interconnessione proprietaria, che le rendono ideali per accelerare l'addestramento e l'inferenza dell'IA.
Versioni di Cloud TPU
| Versione Cloud TPU | Descrizione | Disponibilità |
|---|---|---|
Ironwood | La nostra TPU più potente ed efficiente di sempre, per l'addestramento e l'inferenza su larga scala | La TPU Ironwood sarà disponibile a livello generale nel quarto trimestre del 2025 |
Trillium | TPU di sesta generazione. Migliore efficienza energetica e prestazioni di calcolo di picco per chip per l'addestramento e l'inferenza | Trillium è in disponibilità generale in Nord America (regione degli Stati Uniti orientali), Europa (regione occidentale) e Asia (regione nord-orientale) |
Cloud TPU v5p | TPU potente per la creazione di modelli di base di grandi dimensioni e complessi | Cloud TPU v5p è in disponibilità generale in Nord America (regione degli Stati Uniti orientali) |
Cloud TPU v5e | TPU conveniente e accessibile per carichi di lavoro di addestramento e inferenza su scala medio-grande | Cloud TPU v5e è in disponibilità generale in Nord America (regioni degli Stati Uniti centrali/orientali/meridionali/occidentali), Europa (regione occidentale) e Asia (regione del sud-orientale) |
Informazioni aggiuntive sulle versioni di Cloud TPU
Ironwood
La nostra TPU più potente ed efficiente di sempre, per l'addestramento e l'inferenza su larga scala
La TPU Ironwood sarà disponibile a livello generale nel quarto trimestre del 2025
Trillium
TPU di sesta generazione. Migliore efficienza energetica e prestazioni di calcolo di picco per chip per l'addestramento e l'inferenza
Trillium è in disponibilità generale in Nord America (regione degli Stati Uniti orientali), Europa (regione occidentale) e Asia (regione nord-orientale)
Cloud TPU v5p
TPU potente per la creazione di modelli di base di grandi dimensioni e complessi
Cloud TPU v5p è in disponibilità generale in Nord America (regione degli Stati Uniti orientali)
Cloud TPU v5e
TPU conveniente e accessibile per carichi di lavoro di addestramento e inferenza su scala medio-grande
Cloud TPU v5e è in disponibilità generale in Nord America (regioni degli Stati Uniti centrali/orientali/meridionali/occidentali), Europa (regione occidentale) e Asia (regione del sud-orientale)
Informazioni aggiuntive sulle versioni di Cloud TPU
Come funziona
Dai un'occhiata all'interno delle Google Cloud TPU, inclusa una rara vista dall'interno dei data center in cui avviene la magia. I clienti utilizzano le Cloud TPU per eseguire alcuni dei più grandi carichi di lavoro di IA al mondo e questa potenza proviene da molto più di un semplice chip. In questo video, dai un'occhiata ai componenti del sistema TPU, tra cui networking di data center, interruttori di circuiti ottici, sistemi di raffreddamento ad acqua, verifica della sicurezza biometrica e altro ancora.
Dai un'occhiata all'interno delle Google Cloud TPU, inclusa una rara vista dall'interno dei data center in cui avviene la magia. I clienti utilizzano le Cloud TPU per eseguire alcuni dei più grandi carichi di lavoro di IA al mondo e questa potenza proviene da molto più di un semplice chip. In questo video, dai un'occhiata ai componenti del sistema TPU, tra cui networking di data center, interruttori di circuiti ottici, sistemi di raffreddamento ad acqua, verifica della sicurezza biometrica e altro ancora.

Utilizzi comuni
Esegui carichi di lavoro per l'addestramento dell'IA su larga scala
Come scalare il modello
Addestrare gli LLM spesso sembra alchimia, ma comprendere e ottimizzare le prestazioni dei modelli non deve essere necessariamente così. Questo libro mira a sfatare il mito della scienza dello scaling dei modelli linguistici sulle TPU: come funzionano le TPU e come comunicano tra loro, come vengono eseguiti i modelli LLM su hardware reale e come effettuare il parallelismo tra i modelli durante l'addestramento e l'inferenza in modo che vengano eseguiti in modo efficiente su larga scala.

Addestramento su IA potente, scalabile ed efficiente
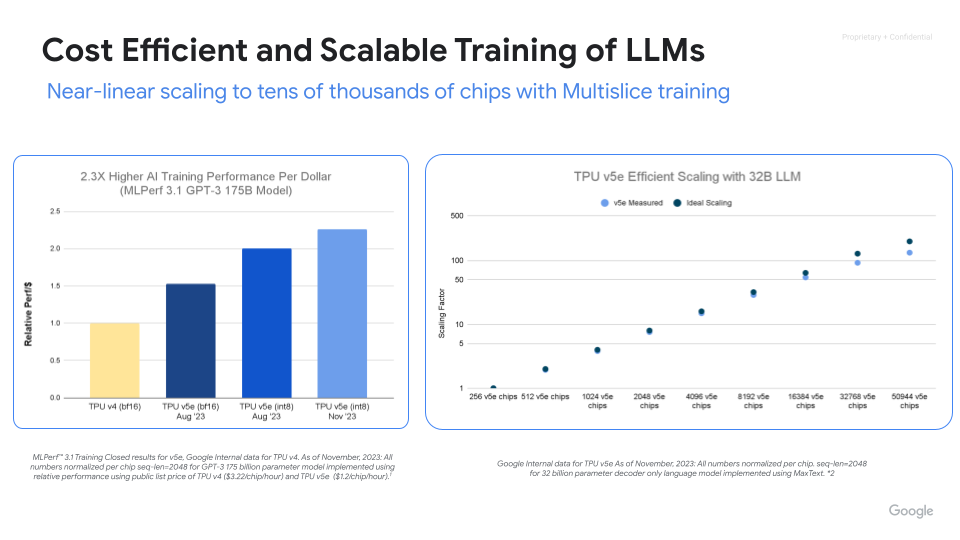
Massimizza le prestazioni, l'efficienza e il time to value con le Cloud TPU. Scala fino a migliaia di chip con l'addestramento multislice delle Cloud TPU. Misura e migliora la produttività dell'addestramento ML su larga scala con ML Goodput Measurement. Inizia rapidamente con MaxText e MaxDiffusion, deployment di riferimento open source per l'addestramento di modelli di grandi dimensioni.
Procedure
Come scalare il modello
Addestrare gli LLM spesso sembra alchimia, ma comprendere e ottimizzare le prestazioni dei modelli non deve essere necessariamente così. Questo libro mira a sfatare il mito della scienza dello scaling dei modelli linguistici sulle TPU: come funzionano le TPU e come comunicano tra loro, come vengono eseguiti i modelli LLM su hardware reale e come effettuare il parallelismo tra i modelli durante l'addestramento e l'inferenza in modo che vengano eseguiti in modo efficiente su larga scala.
Risorse aggiuntive
Addestramento su IA potente, scalabile ed efficiente
Massimizza le prestazioni, l'efficienza e il time to value con le Cloud TPU. Scala fino a migliaia di chip con l'addestramento multislice delle Cloud TPU. Misura e migliora la produttività dell'addestramento ML su larga scala con ML Goodput Measurement. Inizia rapidamente con MaxText e MaxDiffusion, deployment di riferimento open source per l'addestramento di modelli di grandi dimensioni.
Ottimizza i modelli IA di base
Adatta gli LLM per le tue applicazioni con Pytorch/XLA
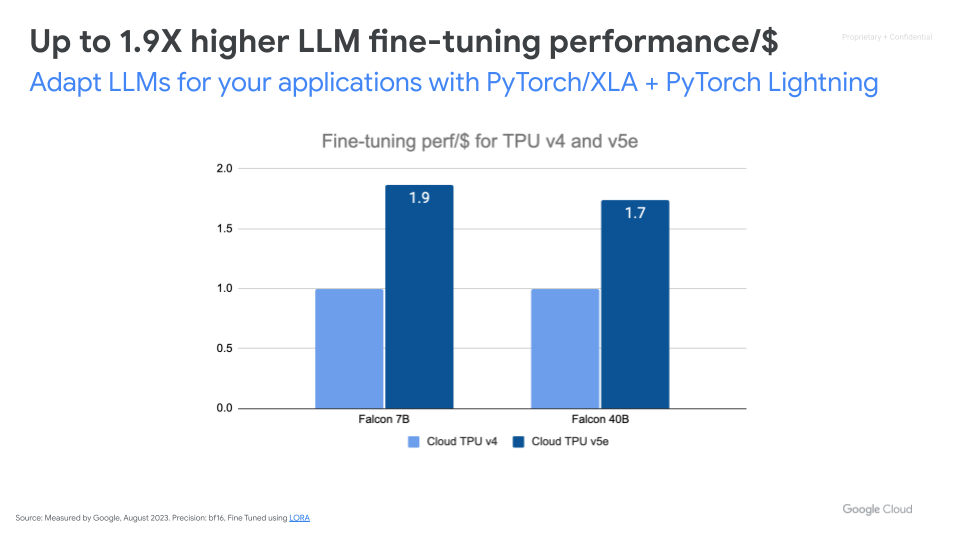
Ottimizza in modo efficiente i modelli di base sfruttando i tuoi dati di addestramento che rappresentano il tuo caso d'uso. Cloud TPU v5e offre prestazioni di ottimizzazione LLM fino a 1,9 volte superiori per dollaro rispetto a Cloud TPU v4.
Risorse aggiuntive
Adatta gli LLM per le tue applicazioni con Pytorch/XLA
Ottimizza in modo efficiente i modelli di base sfruttando i tuoi dati di addestramento che rappresentano il tuo caso d'uso. Cloud TPU v5e offre prestazioni di ottimizzazione LLM fino a 1,9 volte superiori per dollaro rispetto a Cloud TPU v4.
Gestisci carichi di lavoro di inferenza IA su larga scala
Inferenza ad alte prestazioni, scalabile ed economica
Accelera l'inferenza dell'AI con vLLM e MaxDiffusion. vLLM è un motore di inferenza open source molto diffuso, progettato per ottenere throughput elevato e bassa latenza per l'inferenza dei modelli linguistici di grandi dimensioni (LLM). Basato su tpu-inference, vLLM ora offre vLLM TPU per l'inferenza LLM a bassa latenza e con throughput elevato. Unifica JAX e Pytorch, fornendo una copertura più ampia dei modelli (Gemma, Llama, Qwen) e funzionalità avanzate. MaxDiffusion ottimizza l'inferenza del modello di diffusione su Cloud TPU per ottenere prestazioni elevate.
Massimizza le prestazioni/$ con un'infrastruttura IA scalabile
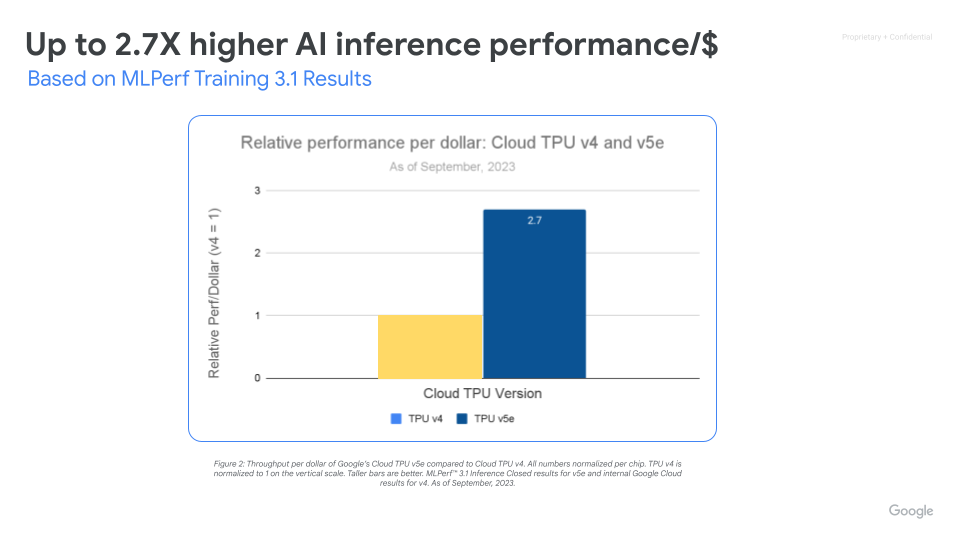
Cloud TPU v5e consente un'inferenza ad alte prestazioni ed economica per un'ampia gamma di carichi di lavoro IA, inclusi i più recenti LLM e modelli di IA generativa. TPU v5e offre prestazioni in termini di velocità effettiva fino a 2,5 volte superiore per dollaro e una velocità fino a 1,7 volte superiore rispetto a Cloud TPU v4. Ogni chip TPU v5e fornisce fino a 393 trilioni di operazioni int8 al secondo, consentendo a modelli complessi di fare previsioni rapidamente. Un pod TPU v5e offre fino a 100 quadrilioni di operazioni int8 al secondo o 100 petaOps di potenza di calcolo.
Procedure
Inferenza ad alte prestazioni, scalabile ed economica
Accelera l'inferenza dell'AI con vLLM e MaxDiffusion. vLLM è un motore di inferenza open source molto diffuso, progettato per ottenere throughput elevato e bassa latenza per l'inferenza dei modelli linguistici di grandi dimensioni (LLM). Basato su tpu-inference, vLLM ora offre vLLM TPU per l'inferenza LLM a bassa latenza e con throughput elevato. Unifica JAX e Pytorch, fornendo una copertura più ampia dei modelli (Gemma, Llama, Qwen) e funzionalità avanzate. MaxDiffusion ottimizza l'inferenza del modello di diffusione su Cloud TPU per ottenere prestazioni elevate.
Risorse aggiuntive
Massimizza le prestazioni/$ con un'infrastruttura IA scalabile
Cloud TPU v5e consente un'inferenza ad alte prestazioni ed economica per un'ampia gamma di carichi di lavoro IA, inclusi i più recenti LLM e modelli di IA generativa. TPU v5e offre prestazioni in termini di velocità effettiva fino a 2,5 volte superiore per dollaro e una velocità fino a 1,7 volte superiore rispetto a Cloud TPU v4. Ogni chip TPU v5e fornisce fino a 393 trilioni di operazioni int8 al secondo, consentendo a modelli complessi di fare previsioni rapidamente. Un pod TPU v5e offre fino a 100 quadrilioni di operazioni int8 al secondo o 100 petaOps di potenza di calcolo.
Cloud TPU in GKE
Esegui carichi di lavoro IA ottimizzati con l'orchestrazione della piattaforma
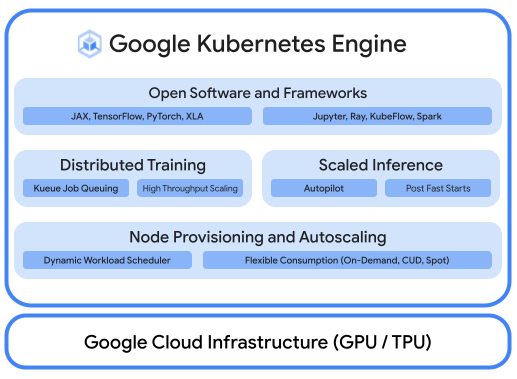
Una solida piattaforma AI/ML prende in considerazione i seguenti livelli: (i) Orchestrazione dell'infrastruttura che supporta le GPU per l'addestramento e la gestione dei carichi di lavoro su larga scala, (ii) Integrazione flessibile con i framework di trattamento dati e computing distribuito (iii) Supporto a più team sulla stessa infrastruttura per massimizzare l'utilizzo delle risorse.
Scalabilità semplice con GKE
Combina la potenza delle Cloud TPU con la flessibilità e la scalabilità di GKE per creare ed eseguire il deployment di modelli di machine learning in modo più rapido e semplice che mai. Con le Cloud TPU disponibili in GKE, ora puoi avere un singolo ambiente operativo coerente per tutti i tuoi carichi di lavoro, standardizzando le pipeline MLOps automatizzate.
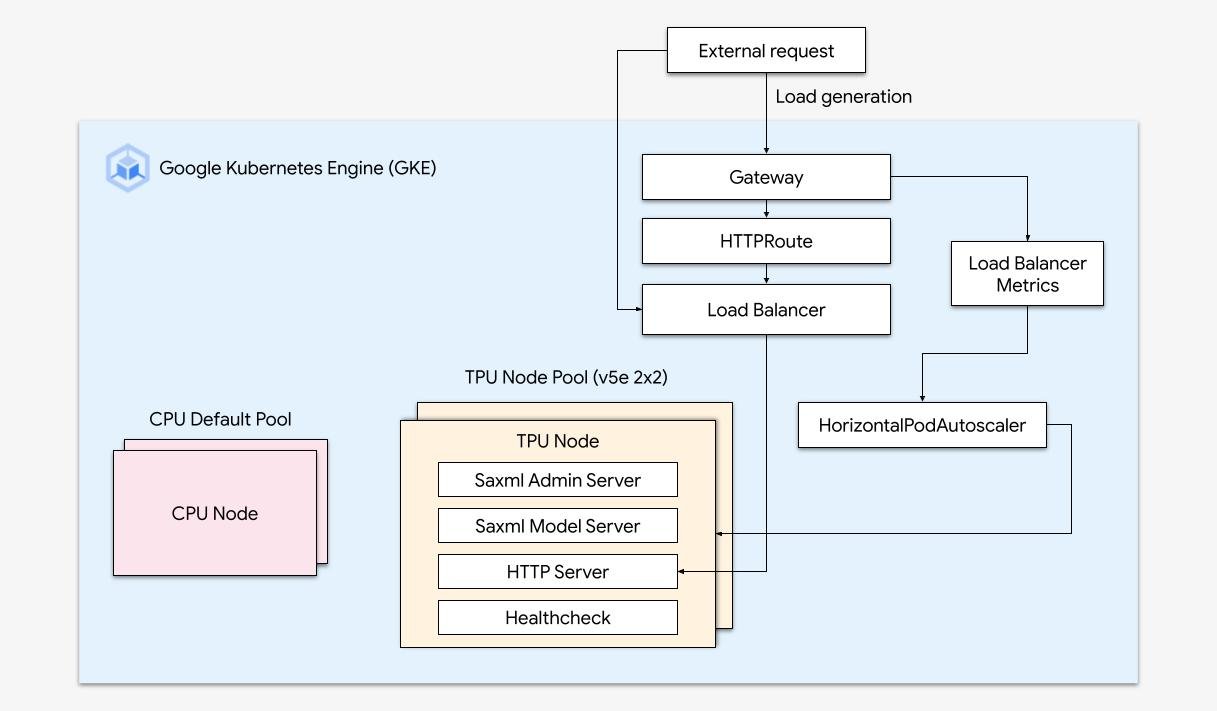
Procedure
Esegui carichi di lavoro IA ottimizzati con l'orchestrazione della piattaforma
Una solida piattaforma AI/ML prende in considerazione i seguenti livelli: (i) Orchestrazione dell'infrastruttura che supporta le GPU per l'addestramento e la gestione dei carichi di lavoro su larga scala, (ii) Integrazione flessibile con i framework di trattamento dati e computing distribuito (iii) Supporto a più team sulla stessa infrastruttura per massimizzare l'utilizzo delle risorse.
Risorse aggiuntive
Scalabilità semplice con GKE
Combina la potenza delle Cloud TPU con la flessibilità e la scalabilità di GKE per creare ed eseguire il deployment di modelli di machine learning in modo più rapido e semplice che mai. Con le Cloud TPU disponibili in GKE, ora puoi avere un singolo ambiente operativo coerente per tutti i tuoi carichi di lavoro, standardizzando le pipeline MLOps automatizzate.
Cloud TPU in Vertex AI
Addestramento e previsioni di Vertex AI con Cloud TPU
Per i clienti che cercano un modo più semplice per sviluppare modelli IA, puoi eseguire il deployment di Cloud TPU v5e con Vertex AI, una piattaforma end-to-end per la creazione modelli di IA su un'infrastruttura completamente gestita, creata appositamente per la gestione a bassa latenza e l'addestramento ad alte prestazioni.
Risorse aggiuntive
Addestramento e previsioni di Vertex AI con Cloud TPU
Per i clienti che cercano un modo più semplice per sviluppare modelli IA, puoi eseguire il deployment di Cloud TPU v5e con Vertex AI, una piattaforma end-to-end per la creazione modelli di IA su un'infrastruttura completamente gestita, creata appositamente per la gestione a bassa latenza e l'addestramento ad alte prestazioni.
Prezzi
| Prezzi per Cloud TPU | Tutti i prezzi di Cloud TPU si intendono per chip/ora | ||
|---|---|---|---|
| Versione Cloud TPU | Prezzo di valutazione (USD) | Impegno di 1 anno (USD) | Impegno di 3 anni (USD) |
Trillium | A partire da 2,7000 $ per chip/ora | A partire da 1,8900 $ per chip/ora | A partire da 1,2200 $ per chip/ora |
Cloud TPU v5p | A partire da 4,2000 $ per chip/ora | A partire da 2,9400 $ per chip/ora | A partire da 1,8900 $ per chip/ora |
Cloud TPU v5e | A partire da 1,2000 $ per chip/ora | A partire da 0,8400 $ per chip/ora | A partire da 0,5400 $ per chip/ora |
I prezzi di Cloud TPU variano in base al prodotto e alla regione.
Prezzi per Cloud TPU
Tutti i prezzi di Cloud TPU si intendono per chip/ora
Trillium
Starting at
2,7000 $
per chip/ora
Starting at
1,8900 $
per chip/ora
Starting at
1,2200 $
per chip/ora
Cloud TPU v5p
Starting at
4,2000 $
per chip/ora
Starting at
2,9400 $
per chip/ora
Starting at
1,8900 $
per chip/ora
Cloud TPU v5e
Starting at
1,2000 $
per chip/ora
Starting at
0,8400 $
per chip/ora
Starting at
0,5400 $
per chip/ora
I prezzi di Cloud TPU variano in base al prodotto e alla regione.











