Cloud Tensor Processing Units (TPUs)
Accelerate AI development with Google Cloud TPUs
Cloud TPUs optimize performance and cost for all AI workloads, from training to inference. Using world-class data center infrastructure, TPUs offer high reliability, availability, and security.
Not sure if TPUs are the right fit? Learn about when to use GPUs or CPUs on Compute Engine instances to run your machine learning workloads.

Overview
What is a Tensor Processing Unit (TPU)?
Google Cloud TPUs are custom-designed AI accelerators, which are optimized for training and inference of AI models. They are ideal for a variety of use cases, such as agents, code generation, media content generation, synthetic speech, vision services, recommendation engines, and personalization models, among others. TPUs power Gemini, and all of Google’s AI powered applications like Search, Photos, and Maps, all serving over 1 Billion users.
What are the advantages of Cloud TPUs?
Cloud TPUs are designed to scale cost-efficiently for a wide range of AI workloads, spanning training, fine-tuning, and inference. Cloud TPUs provide the versatility to accelerate workloads on leading AI frameworks, including PyTorch, JAX, and TensorFlow. Seamlessly orchestrate large-scale AI workloads through Cloud TPU integration in Google Kubernetes Engine (GKE). Leverage Dynamic Workload Scheduler to improve the scalability of workloads by scheduling all accelerators needed simultaneously. Customers looking for the simplest way to develop AI models can also leverage Cloud TPUs in Vertex AI, a fully-managed AI platform.
When to use Cloud TPUs?
Cloud TPUs are optimized for training large and complex deep learning models that feature many matrix calculations, for instance building large language models (LLMs). Cloud TPUs also have SparseCores, which are dataflow processors that accelerate models relying on embeddings found in recommendation models. Other use cases include healthcare, like protein folding modeling and drug discovery.
How are Cloud TPUs different from GPUs?
A GPU is a specialized processor originally designed for manipulating computer graphics. Their parallel structure makes them ideal for algorithms that process large blocks of data commonly found in AI workloads. Learn more.
A TPU is an application-specific integrated circuit (ASIC) designed by Google for neural networks. TPUs possess specialized features, such as the matrix multiply unit (MXU) and proprietary interconnect topology that make them ideal for accelerating AI training and inference.
Cloud TPU versions
| Cloud TPU version | Description | Availability |
|---|---|---|
Ironwood | Our most powerful and efficient TPU yet, for the largest scale training and inference | Ironwood TPU will be general available in Q4, 2025 |
Trillium | Sixth-generation TPU. Improved energy efficiency and peak compute performance per chip for training and inference | Trillium is generally available in North America (US East region), Europe (West region), and Asia (Northeast region) |
Cloud TPU v5p | Powerful TPU for building large, complex foundational models | Cloud TPU v5p is generally available in North America (US East region) |
Cloud TPU v5e | Cost-effective and accessible TPU for medium-to-large-scale training and inference workloads | Cloud TPU v5e is generally available in North America (US Central/East/South/ West regions), Europe (West region), and Asia (Southeast region) |
Additional information on Cloud TPU versions
Ironwood
Our most powerful and efficient TPU yet, for the largest scale training and inference
Ironwood TPU will be general available in Q4, 2025
Trillium
Sixth-generation TPU. Improved energy efficiency and peak compute performance per chip for training and inference
Trillium is generally available in North America (US East region), Europe (West region), and Asia (Northeast region)
Cloud TPU v5p
Powerful TPU for building large, complex foundational models
Cloud TPU v5p is generally available in North America (US East region)
Cloud TPU v5e
Cost-effective and accessible TPU for medium-to-large-scale training and inference workloads
Cloud TPU v5e is generally available in North America (US Central/East/South/ West regions), Europe (West region), and Asia (Southeast region)
Additional information on Cloud TPU versions
How It Works
Get an inside look at the magic of Google Cloud TPUs, including a rare inside view of the data centers where it all happens. Customers use Cloud TPUs to run some of the world's largest AI workloads and that power comes from much more than just a chip. In this video, take a look at the components of the TPU system, including data center networking, optical circuit switches, water cooling systems, biometric security verification and more.
Get an inside look at the magic of Google Cloud TPUs, including a rare inside view of the data centers where it all happens. Customers use Cloud TPUs to run some of the world's largest AI workloads and that power comes from much more than just a chip. In this video, take a look at the components of the TPU system, including data center networking, optical circuit switches, water cooling systems, biometric security verification and more.

Common Uses
Run large-scale AI training workloads
How to Scale Your Model
Training LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models on TPUs: how TPUs work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and inference so they run efficiently at massive scale.

Powerful, scalable, and efficient AI training
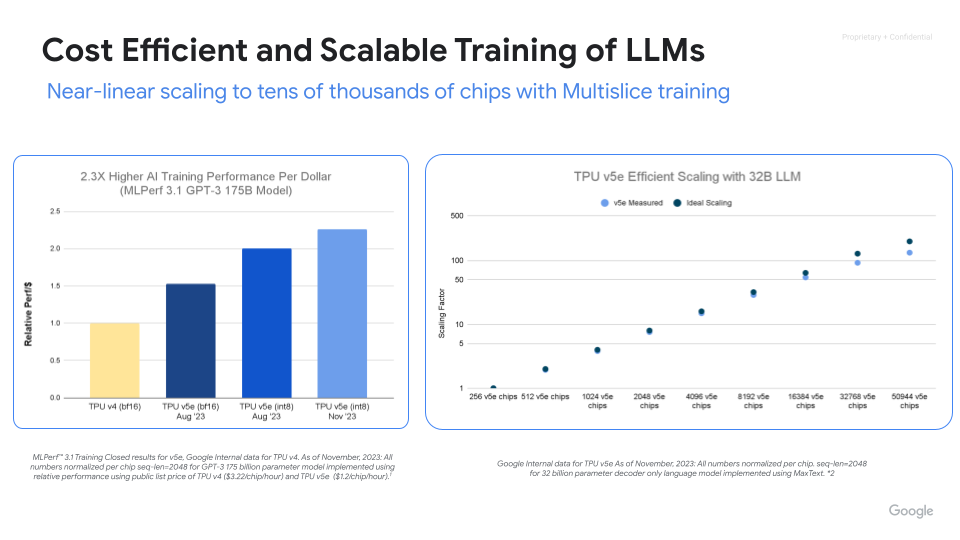
Maximize performance, efficiency, and time to value with Cloud TPUs. Scale to thousands of chips with Cloud TPU Multislice training. Measure and improve large scale ML training productivity with ML Goodput Measurement. Get started quickly with MaxText and MaxDiffusion, open source reference deployments for large model training.
How-tos
How to Scale Your Model
Training LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models on TPUs: how TPUs work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and inference so they run efficiently at massive scale.
Additional resources
Powerful, scalable, and efficient AI training
Maximize performance, efficiency, and time to value with Cloud TPUs. Scale to thousands of chips with Cloud TPU Multislice training. Measure and improve large scale ML training productivity with ML Goodput Measurement. Get started quickly with MaxText and MaxDiffusion, open source reference deployments for large model training.
Fine-tune foundational AI models
Adapt LLMs for your applications with Pytorch/XLA
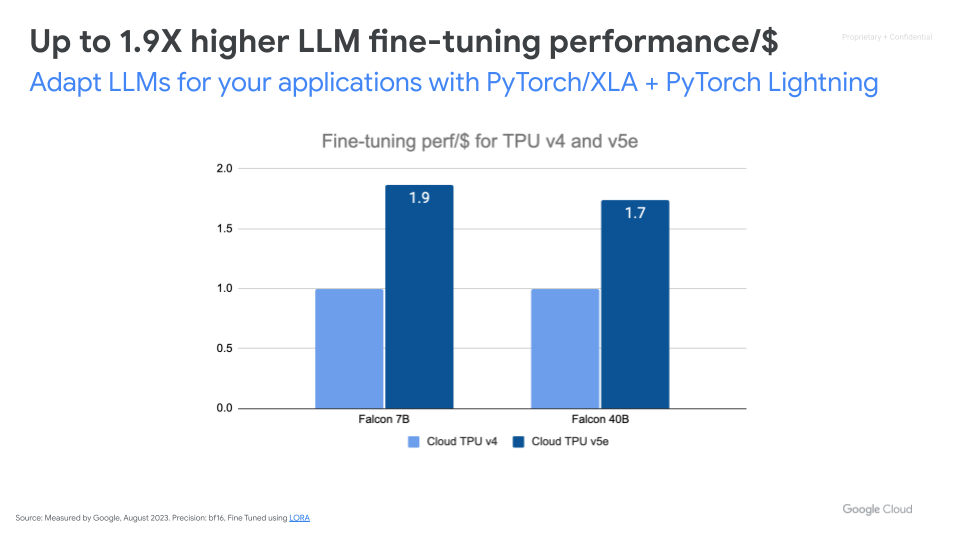
Efficiently fine-tune foundation models by leveraging your own training data that represents your use case. Cloud TPU v5e provides up to 1.9x higher LLM fine-tuning performance per dollar compared to Cloud TPU v4.
Additional resources
Adapt LLMs for your applications with Pytorch/XLA
Efficiently fine-tune foundation models by leveraging your own training data that represents your use case. Cloud TPU v5e provides up to 1.9x higher LLM fine-tuning performance per dollar compared to Cloud TPU v4.
Serve large-scale AI inference workloads
High-performance, scalable, cost-efficient inference
Accelerate AI Inference with vLLM and MaxDiffusion. vLLM is a popular open-source inference engine, designed to achieve high throughput and low latency for Large Language Model (LLM) inference. Powered by tpu-inference, vLLM now offers vLLM TPU for high-throughput, low-latency LLM inference. It unifies JAX and Pytorch, providing broader model coverage (Gemma, Llama, Qwen) and enhanced features. MaxDiffusion optimizes diffusion model inference on Cloud TPUs for high performance.
Maximize performance/$ with AI infrastructure that scales
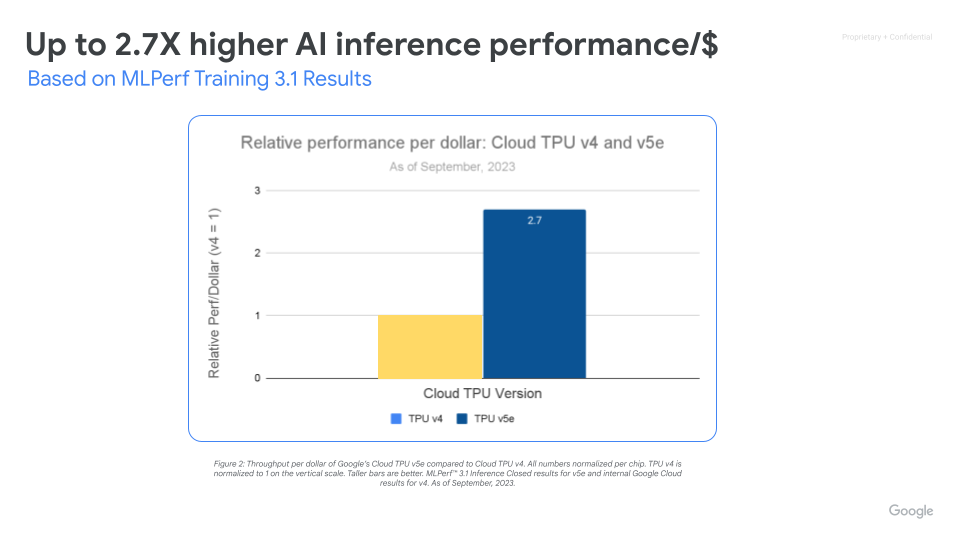
Cloud TPU v5e enables high-performance and cost-effective inference for a wide range of AI workloads, including the latest LLMs and Gen AI models. TPU v5e delivers up to 2.5x more throughput performance per dollar and up to 1.7x speedup over Cloud TPU v4. Each TPU v5e chip provides up to 393 trillion int8 operations per second, allowing complex models to make fast predictions. A TPU v5e pod delivers up to 100 quadrillion int8 operations per second, or 100 petaOps of compute power.
How-tos
High-performance, scalable, cost-efficient inference
Accelerate AI Inference with vLLM and MaxDiffusion. vLLM is a popular open-source inference engine, designed to achieve high throughput and low latency for Large Language Model (LLM) inference. Powered by tpu-inference, vLLM now offers vLLM TPU for high-throughput, low-latency LLM inference. It unifies JAX and Pytorch, providing broader model coverage (Gemma, Llama, Qwen) and enhanced features. MaxDiffusion optimizes diffusion model inference on Cloud TPUs for high performance.
Additional resources
Maximize performance/$ with AI infrastructure that scales
Cloud TPU v5e enables high-performance and cost-effective inference for a wide range of AI workloads, including the latest LLMs and Gen AI models. TPU v5e delivers up to 2.5x more throughput performance per dollar and up to 1.7x speedup over Cloud TPU v4. Each TPU v5e chip provides up to 393 trillion int8 operations per second, allowing complex models to make fast predictions. A TPU v5e pod delivers up to 100 quadrillion int8 operations per second, or 100 petaOps of compute power.
Cloud TPU in GKE
Run optimized AI workloads with platform orchestration
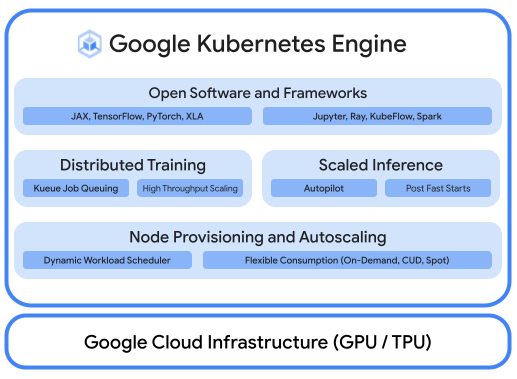
A robust AI/ML platform considers the following layers: (i) Infrastructure orchestration that support GPUs for training and serving workloads at scale, (ii) Flexible integration with distributed computing and data processing frameworks, and (iii) Support for multiple teams on the same infrastructure to maximize utilization of resources.
Effortless scaling with GKE
Combine the power of Cloud TPUs with the flexibility and scalability of GKE to build and deploy machine learning models faster and more easily than ever before. With Cloud TPUs available in GKE, you can now have a single consistent operations environment for all your workloads, standardizing automated MLOps pipelines.
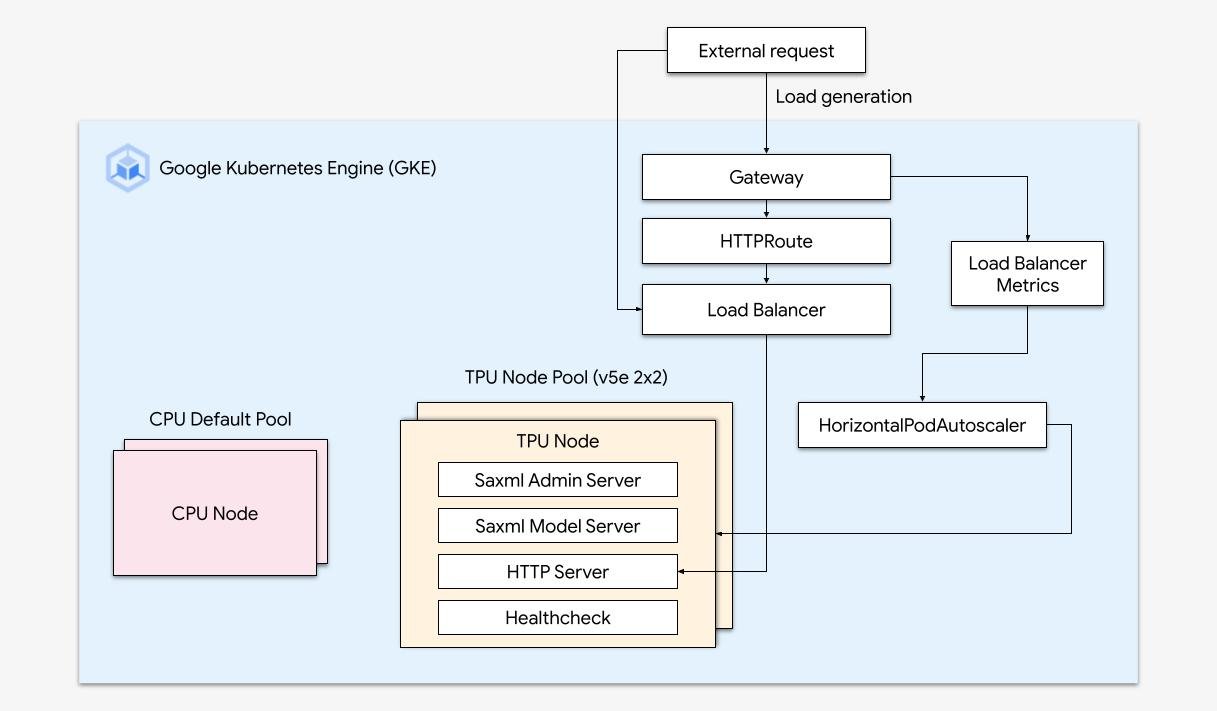
How-tos
Run optimized AI workloads with platform orchestration
A robust AI/ML platform considers the following layers: (i) Infrastructure orchestration that support GPUs for training and serving workloads at scale, (ii) Flexible integration with distributed computing and data processing frameworks, and (iii) Support for multiple teams on the same infrastructure to maximize utilization of resources.
Additional resources
Effortless scaling with GKE
Combine the power of Cloud TPUs with the flexibility and scalability of GKE to build and deploy machine learning models faster and more easily than ever before. With Cloud TPUs available in GKE, you can now have a single consistent operations environment for all your workloads, standardizing automated MLOps pipelines.
Cloud TPU in Vertex AI
Vertex AI training and predictions with Cloud TPUs
For customers looking for a simplest way to develop AI models, you can deploy Cloud TPU v5e with Vertex AI, an end-to-end platform for building AI models on fully-managed infrastructure that’s purpose-built for low-latency serving and high-performance training.
Additional resources
Vertex AI training and predictions with Cloud TPUs
For customers looking for a simplest way to develop AI models, you can deploy Cloud TPU v5e with Vertex AI, an end-to-end platform for building AI models on fully-managed infrastructure that’s purpose-built for low-latency serving and high-performance training.
Pricing
| Cloud TPU pricing | All Cloud TPU pricing is per chip-hour | ||
|---|---|---|---|
| Cloud TPU Version | Evaluation Price (USD) | 1-year commitment (USD) | 3-year commitment (USD) |
Trillium | Starting at $2.7000 per chip-hour | Starting at $1.8900 per chip-hour | Starting at $1.2200 per chip-hour |
Cloud TPU v5p | Starting at $4.2000 per chip-hour | Starting at $2.9400 per chip-hour | Starting at $1.8900 per chip-hour |
Cloud TPU v5e | Starting at $1.2000 per chip-hour | Starting at $0.8400 per chip-hour | Starting at $0.5400 per chip-hour |
Cloud TPU pricing varies by product and region.
Cloud TPU pricing
All Cloud TPU pricing is per chip-hour
Trillium
Starting at
$2.7000
per chip-hour
Starting at
$1.8900
per chip-hour
Starting at
$1.2200
per chip-hour
Cloud TPU v5p
Starting at
$4.2000
per chip-hour
Starting at
$2.9400
per chip-hour
Starting at
$1.8900
per chip-hour
Cloud TPU v5e
Starting at
$1.2000
per chip-hour
Starting at
$0.8400
per chip-hour
Starting at
$0.5400
per chip-hour
Cloud TPU pricing varies by product and region.











