このドキュメントでは、Compute Engine で Prometheus から指標を収集するために使用できる Ops エージェント指標レシーバーの構成と使用方法について説明します。このドキュメントでは、レシーバーの試行に使用できる例についても説明します。
Google Kubernetes Engine のユーザーは、Google Cloud Managed Service for Prometheus を使用して Prometheus 指標を収集できました。Ops エージェントの Prometheus レシーバーは、Compute Engine のユーザーに同じ機能を提供します。
PromQL を含め Cloud Monitoring のすべてのツールを使用して、Prometheus レシーバーによって収集されたデータを表示および分析できます。たとえば、Monitoring 用のGoogle Cloud コンソールで説明されているように、Metrics Explorer はデータのクエリに使用できます。また、Cloud Monitoring のダッシュボードとアラート ポリシーを作成して、Prometheus 指標をモニタリングできます。Prometheus 指標のクエリ言語には、PromQL を使用することをおすすめします。
Prometheus 指標は、Cloud Monitoring 以外のインターフェース(Prometheus UI や Grafana など)でも表示できます。
適切なレシーバーを選択する
Prometheus レシーバーの使用を決める前に、使用しているアプリケーションに Ops エージェントがすでに統合されているかどうかを確認してください。Ops エージェントとの既存の統合については、サードパーティ アプリケーションのモニタリングをご覧ください。既存の統合がある場合は、その使用をおすすめします。詳細については、既存の統合の選択をご覧ください。
次の条件に該当する場合は、Ops エージェントの Prometheus レシーバーの使用をおすすめします。
Prometheus の使用経験があり、Prometheus 標準を活用しており、間隔やカーディナリティのスクレイピングなどの要因が費用に与える影響を理解している。詳細については、Prometheus レシーバーの選択をご覧ください。
モニタリング中のソフトウェアは、まだ既存の Ops エージェントの統合の一部ではありません。
既存の統合
Ops エージェントには、多くのサードパーティ アプリケーションの統合が用意されています。これらの統合では、次のことが提供されます。
- アプリケーション用に選択された一連の
workload.googleapis.com指標 - 指標を可視化するためのダッシュボード
既存の統合を使用して取り込まれた指標には、エージェントによって収集された指標のバイトベースの料金が適用されます。この料金については、Google Cloud Observability の料金をご覧ください。指標の数と種類を事前に把握できるため、その情報を使用して費用を見積もることができます。
たとえば、Apache ウェブサーバー(httpd)の統合を使用している場合、Ops エージェントは 5 つのスカラー指標(各データポイントは 8 バイトとしてカウント)を収集します。Ops エージェントのデフォルトのサンプリング頻度を 60 秒のままにすると、1 日に取り込まれるバイト数は 57,600 × ホスト数です。
- 8(バイト)× 1,440(1 日を分で換算)× 5(指標)× n(ホスト数)、または
- 57,600 × n(ホスト数)
費用の見積もりの詳細については、取り込まれたバイト数に基づく料金の例をご覧ください。
Prometheus レシーバー
Ops エージェントを使用して Prometheus 指標を収集する場合、以下が適用されます。
アプリケーションから出力される指標の数とカーディナリティは、ご自身で管理できます。キュレートされる指標のセットはありません。取り込むデータは、Prometheus アプリケーションと Ops エージェント Prometheus レシーバーの構成によって決まります。
指標は、
prometheus.googleapis.com指標として Cloud Monitoring に取り込まれます。これらの指標は、Cloud Monitoring に取り込まれたときに「カスタム指標」の一種として分類され、カスタム指標の割り当てと上限が適用されます。取り込む一連の指標とビジネスニーズに基づいて、必要な Cloud Monitoring ダッシュボードを設計、作成する必要があります。ダッシュボードの作成については、ダッシュボードとグラフをご覧ください。
指標の取り込みの料金は、取り込まれたサンプルの数に基づきます。Prometheus レシーバーを使用する場合の費用を見積もるには、請求期間中に収集する可能性があるサンプル数を決定する必要があります。この見積もりは、次の要素に基づきます。
- スカラー指標の数(各値が 1 つのサンプル)。
- 分布指標の数。各ヒストグラムは、(2 + ヒストグラムのバケット数)個のサンプルとしてカウントされます。
- 各指標のサンプリング頻度
- 指標がサンプリングされるホストの数
料金の詳細については、Google Cloud Observability の料金をご覧ください。例については、取り込まれたサンプル数に基づく料金の例をご覧ください。
前提条件
Prometheus レシーバーを使用して Prometheus 指標を収集するには、バージョン 2.25.0 以降の Ops エージェントをインストールする必要があります。
Ops エージェント レシーバーには、Prometheus 指標を送信するエンドポイントが必要です。アプリケーションでは、このようなエンドポイントを直接提供するか、Prometheus ライブラリまたはエクスポータを使用してエンドポイントを公開する必要があります。Prometheus 以外の指標を出力する多くのライブラリまたは言語フレームワーク(Spring や DropWizard など)やアプリケーション(StatsD、DogStatsD、Graphite など)では、Prometheus クライアント ライブラリやエクスポータを使用して、Prometheus スタイルの指標を出力できます。たとえば、Prometheus 指標を出力するには:
- Spring ユーザーは、Spring Metrics ライブラリを使用できます。
- StatsD ユーザーは、
statsd_exporterパッケージを使用できます。 - Graphite ユーザーは、
graphite_exporterパッケージを使用できます。
Prometheus 指標が、アプリケーションによって直接出力されるか、ライブラリまたはエクスポータによって出力される場合、その指標は、Prometheus レシーバーで構成された Ops エージェントによって収集できます。
Ops エージェントを構成する
通常、Ops エージェントの構成モデルには、次の項目を定義が含まれます。
- レシーバー。収集される指標を決定します。
- プロセッサ。Ops エージェントが指標を変更する方法を記述します。
- パイプライン。レシーバーとプロセッサをまとめて 1 つのサービスにリンクします。
Prometheus 指標の取り込みの構成は若干異なり、関係するプロセッサがありません。
Prometheus 指標の構成
Prometheus 指標を取り込むように Ops エージェントを構成することは、次の点で通常の構成と異なります。
Prometheus 指標用の Ops エージェント プロセッサは作成しません。Prometheus レシーバーは、再ラベル付けオプションを含め、Prometheus の
scrape_config仕様で指定されたほぼすべての構成オプションをサポートします。Prometheus レシーバーで指定されているように、指標の処理は、Ops エージェント プロセッサを使用するのではなく、スクレイピング構成ファイルの
relabel_configsセクションとmetric_relabel_configsセクションを使用して行われます。詳細については、再ラベル付け: スクレイピングされるデータを変更するをご覧ください。Prometheus パイプラインは、Prometheus レシーバーに関してのみ定義します。プロセッサは指定しません。また、Prometheus 指標のパイプラインで Prometheus 以外のレシーバーも使用できません。
レシーバー構成の大半は、スクレイピング構成オプションの仕様です。Prometheus レシーバーを使用する Ops エージェント構成の構造を次に示します。簡潔にするため、このようなオプションは省略しています。RECEIVER_ID と PIPELINE_ID の値を指定します。
metrics:
receivers:
RECEIVER_ID:
type: prometheus
config:
scrape_configs:
[... omitted for brevity ...]
service:
pipelines:
PIPELINE_ID:
receivers: [RECEIVER_ID]
Prometheus レシーバーについては、次のセクションで詳しく説明します。レシーバーとパイプラインの機能的な例については、Ops エージェント レシーバーとパイプラインを追加するをご覧ください。
Prometheus レシーバー
Prometheus 指標のレシーバーを指定するには、prometheus タイプの指標レシーバーを作成し、scrape_config オプションのセットを指定します。レシーバーは、次を除くすべての Prometheus scrape_config オプションをサポートしています。
- サービス ディスカバリ セクション(
*_sd_config)。 honor_labels設定。
したがって、既存のスクレイピング構成ファイルをコピーし、ほとんど変更しないか、まったく変更せずに Ops エージェントに使用できます。
Prometheus レシーバーの構造全体を次に示します。
metrics:
receivers:
prom_application:
type: prometheus
config:
scrape_configs:
- job_name: 'STRING' # must be unique across all Prometheus receivers
scrape_interval: # duration, like 10m or 15s
scrape_timeout: # duration, like 10m or 15s
metrics_path: # resource path for metrics, default = /metrics
honor_timestamps: # boolean, default = false
scheme: # http or https, default = http
params:
- STRING: STRING
basic_auth:
username: STRING
password: SECRET
password_file: STRING
authorization:
type: STRING # default = Bearer
credentials: SECRET
credentials_file: FILENAME
oauth2: OAUTH2 # See Prometheus oauth2
follow_redirects: # boolean, default = true
enable_http2: # boolean, default = true
tls_config: TLS_CONFIG # See Prometheus tls_config
proxy_url: STRING
static_configs:
STATIC_CONFIG # See Prometheus static_config
relabel_configs:
RELABEL_CONFIG # See Prometheus relabel_config
metric_relabel_configs:
METRIC_RELABEL_CONFIGS # See Prometheus metric_relabel_configs
構成ファイルを再ラベル付けする例については、追加のレシーバー構成をご覧ください。
例: Prometheus 用に Ops エージェントを構成する
このセクションでは、アプリケーションから Prometheus 指標を収集するように Ops エージェントを構成する方法について説明します。この例では、Prometheus コミュニティが提供する JSON エクスポータ(json_exporter)を使用します。これは、ポート 7979 で Prometheus 指標を公開します。
サンプルをセットアップするには次のリソースが必要です。これらのリソースのインストールが必要になることがあります。
gitcurlmakepython3- Go 言語(バージョン 1.19 以降)
アプリケーションを作成または構成する
JSON エクスポータを取得して実行するには、次の操作を行います。
json_exporterリポジトリのクローンを作成し、次のコマンドを実行してエクスポータをチェックアウトします。git clone https://github.com/prometheus-community/json_exporter.git cd json_exporter git checkout v0.5.0
次のコマンドを実行して、エクスポータをビルドします。
make build
次のコマンドを実行して、Python HTTP サーバーを起動します。
python3 -m http.server 8000 &
次のコマンドを実行して、JSON エクスポータを起動します。
./json_exporter --config.file examples/config.yml &
JSON エクスポータにクエリを実行して、エクスポータが動作し、ポート 7979 に指標を公開していることを確認します。
curl "http://localhost:7979/probe?module=default&target=http://localhost:8000/examples/data.json"
クエリが成功すると、次のような出力が表示されます。
# HELP example_global_value Example of a top-level global value scrape in the json # TYPE example_global_value untyped example_global_value{environment="beta",location="planet-mars"} 1234 # HELP example_value_active Example of sub-level value scrapes from a json # TYPE example_value_active untyped example_value_active{environment="beta",id="id-A"} 1 example_value_active{environment="beta",id="id-C"} 1 # HELP example_value_boolean Example of sub-level value scrapes from a json # TYPE example_value_boolean untyped example_value_boolean{environment="beta",id="id-A"} 1 example_value_boolean{environment="beta",id="id-C"} 0 # HELP example_value_count Example of sub-level value scrapes from a json # TYPE example_value_count untyped example_value_count{environment="beta",id="id-A"} 1 example_value_count{environment="beta",id="id-C"} 3この出力では、
example_value_activeのような文字列が指標名で、中かっこの内側にラベルと値が含まれています。ラベルセットの後にデータ値が続きます。
Ops エージェント レシーバーとパイプラインを追加する
JSON Exporter アプリケーションから指標を取り込むように Ops エージェントを構成するには、Prometheus レシーバーとパイプラインを追加するように、エージェントの構成を変更する必要があります。JSON エクスポータの例では、次の操作を行います。
Ops エージェント構成ファイル
/etc/google-cloud-ops-agent/config.yamlを編集して、次の Prometheus レシーバーとパイプライン エントリを追加します。metrics: receivers: prometheus: type: prometheus config: scrape_configs: - job_name: 'json_exporter' scrape_interval: 10s metrics_path: /probe params: module: [default] target: [http://localhost:8000/examples/data.json] static_configs: - targets: ['localhost:7979'] service: pipelines: prometheus_pipeline: receivers: - prometheusこのファイルに他の構成エントリがすでにある場合は、Prometheus レシーバーとパイプラインを既存の
metricsエントリとserviceエントリに追加します。詳細については、指標の構成をご覧ください。レシーバー内の構成ファイルを再ラベル付けする例については、追加のレシーバー構成をご覧ください。
Ops エージェントを再起動する
構成の変更を適用するには、Ops エージェントを再起動する必要があります。
Linux
エージェントを再起動するには、インスタンスで次のコマンドを実行します。
sudo service google-cloud-ops-agent restart
エージェントが再起動したことを確認するには、次のコマンドを実行して「Metrics Agent」と「Logging エージェント」のコンポーネントが起動したことを確認します。
sudo systemctl status google-cloud-ops-agent"*"
Windows
RDP または同様のツールを使用してインスタンスに接続し、Windows にログインします。
PowerShell アイコンを右クリックし、[管理者として実行] を選択して、管理者権限で PowerShell ターミナルを開きます。
エージェントを再起動するには、次の PowerShell コマンドを実行します。
Restart-Service google-cloud-ops-agent -Force
エージェントが再起動したことを確認するには、次のコマンドを実行して「Metrics Agent」と「Logging エージェント」のコンポーネントが起動したことを確認します。
Get-Service google-cloud-ops-agent*
Cloud Monitoring の Prometheus 指標
Cloud Monitoring のツールは、Prometheus レシーバーが収集したデータで使用できます。たとえば、Monitoring 用のGoogle Cloud コンソールで説明されているように、Metrics Explorer を使用してデータをグラフ化できます。以降のセクションでは、Cloud Monitoring と Metrics Explorer で使用可能なクエリツールについて説明します。
指標用の Cloud Monitoring ダッシュボードとアラート ポリシーを作成できます。ダッシュボードと使用できるグラフの種類については、ダッシュボードとグラフをご覧ください。アラート ポリシーの詳細については、アラート ポリシーの使用をご覧ください。
また、他のインターフェース(Prometheus UI や Grafana など)で指標を表示することもできます。これらのインターフェースの設定については、Google Cloud Managed Service for Prometheus ドキュメントの次のセクションをご覧ください。
PromQL を使用する
PromQL は、Prometheus レシーバーを使用して取り込まれる指標に対して推奨されるクエリ言語です。
Prometheus データが取り込まれていることを確認する最も簡単な方法は、 Google Cloud コンソールの Cloud Monitoring の [Metrics Explorer] ページを使用することです。
-
Google Cloud コンソールで [leaderboard Metrics Explorer] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] の結果を選択します。
クエリビルダー ペインのツールバーで、[codeMQL] または [codePROMQL] という名前のボタンを選択します。
[言語] で [PromQL] が選択されていることを確認します。言語切り替えボタンは、クエリの書式設定と同じツールバーにあります。
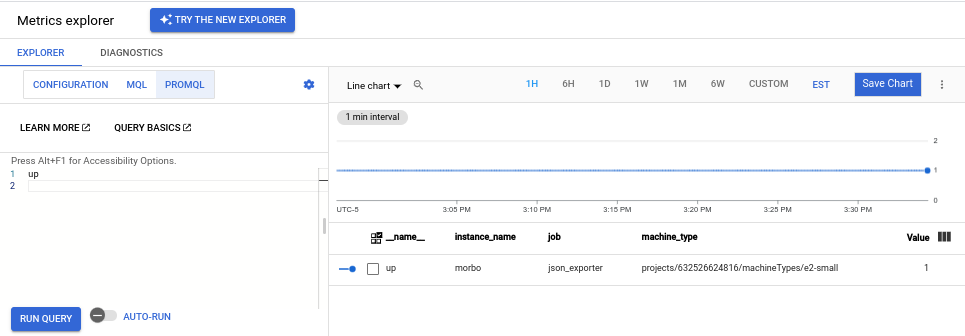
エディタに次のクエリを入力し、[クエリを実行] をクリックします。
up
データが取り込まれている場合、次のようなグラフが表示されます。
JSON Exporter の例を実行している場合は、次のようなクエリを発行することもできます。
エクスポートされた特定の指標のすべてのデータを名前でクエリします。次に例を示します。
example_value_count
JSON エクスポータ アプリケーションによって定義されたラベルと Ops エージェントによって追加されたラベルを含む
example_value_countのグラフを以下に示します。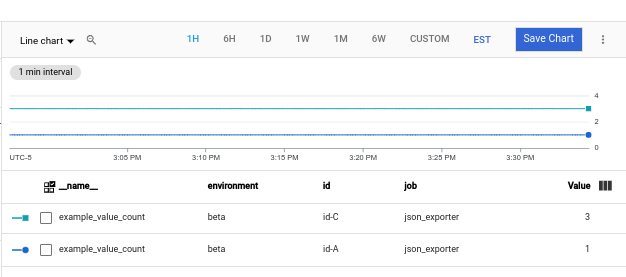
特定の名前空間から生成され、エクスポートされた指標のデータをクエリします。
namespaceラベルの値は、VM に割り当てられた Compute Engine インスタンス ID(5671897148133813325など)です。クエリは次のようになります。example_value_count{namespace="INSTANCE_ID"}特定の正規表現に一致するデータをクエリします。JSON エクスポータは、
id-A、id-B、id-Cなどの値を持つidラベル付きの指標を出力します。このパターンに一致するidラベルを持つ指標をフィルタするには、次のクエリを使用します。example_value_count{id=~"id.*"}
Metrics Explorer グラフと Cloud Monitoring グラフでの PromQL の使用方法については、Cloud Monitoring の PromQL をご覧ください。
Cloud Monitoring で指標の使用状況と診断情報を表示する
Cloud Monitoring の [指標の管理] ページでは、オブザーバビリティに影響を与えることなく、課金対象の指標に費やす金額を制御するために役立つ情報が提供されます。[指標の管理] ページには、次の情報が表示されます。
- 指標ドメイン全体と個々の指標での、バイトベースとサンプルベースの両方の課金に対する取り込み量。
- 指標のラベルとカーディナリティに関するデータ。
- 各指標の読み取り回数。
- アラート ポリシーとカスタム ダッシュボードでの指標の使用。
- 指標書き込みエラーの割合。
[指標の管理] ページで不要な指標を除外し、取り込みの費用を削減することもできます。
[指標の管理] ページを表示するには、次の操作を行います。
-
Google Cloud コンソールで、[ 指標の管理] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが「Monitoring」の結果を選択します。
- ツールバーで時間枠を選択します。デフォルトでは、[指標の管理] ページには、過去 1 日間に収集された指標に関する情報が表示されます。
[指標の管理] ページの詳細については、指標の使用状況の表示と管理をご覧ください。
再ラベル付け: スクレイピングされるデータの変更
再ラベル付けを使用して、ターゲットがスクレイピングされる前に、スクレイピング ターゲットのラベルセットや指標を変更できます。再ラベル付け構成に複数のステップがある場合、それらは構成ファイルに出現する順序で適用されます。
Ops エージェントは、一連のメタラベル(__meta_ で始まるラベル)を作成します。これらのメタラベルは、Ops エージェントが実行されている Compute Engine インスタンスに関する情報を記録します。メタラベルを含め __ 文字列で始まるラベルは、再ラベル付けの間にのみ使用できます。再ラベル付けを使用すると、スクレイピングされたラベルでこれらのラベルの値をキャプチャできます。
指標の再ラベル付けがサンプルに適用されます(取り込み前の最後のステップ)。指標の再ラベル付けは、取り込む必要のない時系列を削除するために使用できます。これらの時系列を削除すると、取り込まれるサンプルの数が減り、コストが削減されます。
再ラベル付けの詳細については、Prometheus ドキュメントで relabel_config と metric_relabel_configs をご覧ください。
再ラベル付けで利用可能な Compute Engine メタラベル
Ops エージェントが指標をスクレイピングする場合は、エージェントが動作している Compute Engine VM の構成に基づく値を持つ一連のメタラベルが含まれます。これらのラベルと Prometheus レシーバーの relabel_configs セクションを使用して、取り込まれた VM に関する指標に別のメタデータを追加できます。例については、追加のレシーバー構成をご覧ください。
ターゲットでは、relabel_configs セクションで使用する次のメタラベルを利用できます。
__meta_gce_instance_id: Compute Engine インスタンス(ローカル)の数値 ID__meta_gce_instance_name: Compute Engine インスタンス(ローカル)の名前。Ops エージェントは、この値を指標の可変instance_nameラベルに自動的に配置します。__meta_gce_machine_type: インスタンスのマシンタイプの完全な URL または部分的な URL。Ops エージェントは、この値を指標の可変machine_typeラベルに自動的に配置します。__meta_gce_metadata_NAME: インスタンスの各メタデータ項目__meta_gce_network: インスタンスのネットワーク URL__meta_gce_private_ip: インスタンスのプライベート IP アドレス__meta_gce_interface_ipv4_NAME: 各名前付きインターフェースの IPv4 アドレス__meta_gce_project: インスタンスが実行されている Google Cloud プロジェクト(ローカル)__meta_gce_public_ip: インスタンスのパブリック IP アドレス(存在する場合)__meta_gce_tags: インスタンス タグのカンマ区切りリスト__meta_gce_zone: インスタンスが動作している Compute Engine のゾーン URL
これらのラベルの値は、Ops エージェントの開始時に設定されます。値を変更した場合は、Ops エージェントを再起動して値を更新する必要があります。
追加のレシーバー構成
このセクションでは、Prometheus レシーバーの relabel_configs セクションと metric_relabel_configs セクションを使用して、取り込まれた指標の数と構造を変更する例を示します。このセクションには、再ラベル付けオプションを使用する JSON エクスポータ例のレシーバーの修正版も含まれています。
VM メタデータを追加する
relabel_configs セクションを使用して、指標にラベルを追加できます。たとえば、次の例では、Ops エージェントが提供するメタラベル __meta_gce_zone を使用して、指標ラベル zone が作成されます。これは、zone に __ の接頭辞が付いていないため、再ラベル付け後も保持されます。
使用可能なメタラベルのリストについては、再ラベル付けの間に使用可能な Compute Engine メタラベルをご覧ください。一部のメタラベルは、デフォルトの Ops エージェント構成によって再ラベル付けされます。
relabel_configs:
- source_labels: [__meta_gce_zone]
regex: '(.+)'
replacement: '${1}'
target_label: zone
例: Prometheus 用の Ops エージェントを構成するに示されている Prometheus レシーバーには、このラベルの追加が含まれています。
指標をドロップする
metrics_relabel_configs セクションを使用して、取り込まない指標をドロップできます。このパターンは、コストを抑えるために使用できます。たとえば、次のパターンは、METRIC_NAME_REGEX_1 または METRIC_NAME_REGEX_2 に一致する名前の指標をドロップするために使用できます。
metric_relabel_configs:
- source_labels: [ __name__ ]
regex: 'METRIC_NAME_REGEX_1'
action: drop
- source_labels: [ __name__ ]
regex: 'METRIC_NAME_REGEX_2'
action: drop
静的ラベルを追加する
metrics_relabel_configs セクションは、Prometheus レシーバーによって取り込まれたすべての指標に静的ラベルを追加するために使用できます。次のパターンを使用して、取り込まれたすべての指標にラベル staticLabel1 と staticLabel2 を追加できます。
metric_relabel_configs:
- source_labels: [ __address__ ]
action: replace
replacement: 'STATIC_VALUE_1'
target_label: staticLabel1
- source_labels: [ __address__ ]
action: replace
replacement: 'STATIC_VALUE_2'
target_label: staticLabel2
以下に示す JSON エクスポータ例の Prometheus レシーバーのバージョンでは、これらの構成パターンを使用して、次のことを行います。
zoneラベルを、Ops エージェントが提供する__meta_gce_zoneメタラベルの値に基づいて設定します。- エクスポータの
example_global_value指標をドロップします。 - 取り込まれたすべての指標に、値が「A static value」の
staticLabelラベルを追加します。
metrics:
receivers:
prometheus:
type: prometheus
config:
scrape_configs:
- job_name: 'json_exporter'
scrape_interval: 10s
metrics_path: /probe
params:
module: [default]
target: [http://localhost:8000/examples/data.json]
static_configs:
- targets: ['localhost:7979']
relabel_configs:
- source_labels: [__meta_gce_zone]
regex: '(.+)'
replacement: '${1}'
target_label: zone
metric_relabel_configs:
- source_labels: [ __name__ ]
regex: 'example_global_value'
action: drop
- source_labels: [ __address__ ]
action: replace
replacement: 'A static value'
target_label: staticLabel