Google Cloud Managed Service for Prometheus는 Cloud Monitoring에 수집된 샘플 수와 Monitoring API에 대한 읽기 요청에 대한 요금을 청구합니다. 비용의 주요 원인은 수집된 샘플 수입니다.
이 문서에서는 측정항목 수집과 관련된 비용을 관리하는 방법과 대량 수집의 소스를 식별하는 방법에 대해 설명합니다.
Managed Service for Prometheus 가격 책정에 대한 자세한 내용은 Google Cloud Observability 가격 책정 페이지의 Cloud Monitoring 섹션을 참고하세요.
청구서 보기
Google Cloud 청구서를 보려면 다음을 실행합니다.
Google Cloud 콘솔에서 결제 페이지로 이동합니다.
결제 계정이 둘 이상인 경우 연결된 결제 계정으로 이동을 선택하여 현재 프로젝트의 결제 계정을 확인합니다. 다른 결제 계정을 찾으려면 결제 계정 관리를 선택하고 사용량 보고서를 확인할 계정을 선택합니다.
결제 탐색 메뉴의 비용 관리 섹션에서 보고서를 선택합니다.
서비스 메뉴에서 Cloud Monitoring 옵션을 선택합니다.
SKU 메뉴에서 다음 옵션을 선택합니다.
- 수집된 Prometheus 샘플
- Monitoring API 요청
다음 스크린샷에서는 한 프로젝트에서 Managed Service for Prometheus의 결제 보고서를 보여줍니다.
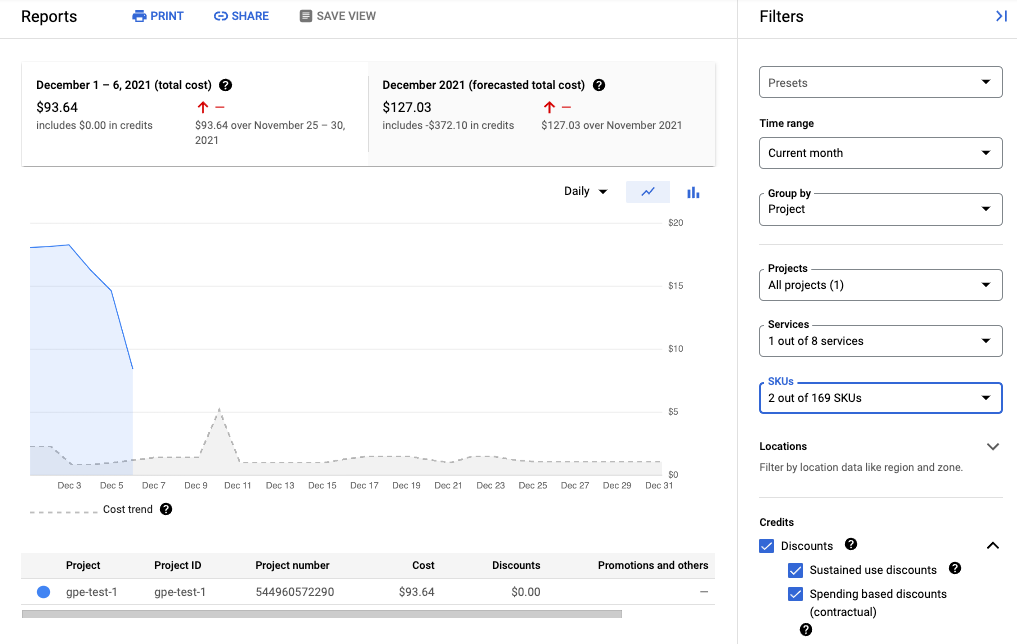
비용 절감
Managed Service for Prometheus 사용과 관련된 비용을 줄이기 위해 다음을 수행할 수 있습니다.
- 생성하는 측정항목 데이터를 필터링하여 관리형 서비스로 전송하는 시계열 수를 줄입니다.
- 스크레이핑 간격을 변경하여 수집하는 샘플 수를 줄입니다.
- 잠재적으로 잘못 구성된 카디널리티가 높은 측정항목의 샘플 수를 제한합니다.
시계열 수 줄이기
오픈소스 Prometheus 문서에서는 비용이 머신 비용으로 제한되는 경우 합당한 측정항목 볼륨 필터링이 거의 권장되지 않습니다. 하지만 관리형 서비스 제공업체를 단위별로 지불하는 경우 무제한 데이터를 전송하면 불필요하게 많은 금액이 청구될 수 있습니다.
kube-prometheus 프로젝트, 특히 kube-state-metrics 서비스에 포함된 내보내기는 많은 측정항목 데이터를 내보낼 수 있습니다.
예를 들어 kube-state-metrics 서비스는 측정항목 수백 개를 내보내며 그 중 대부분은 소비자로서의 가치가 전혀 없을 수 있습니다. kube-prometheus 프로젝트를 사용하는 새로운 3노드 클러스터는 Managed Service for Prometheus에 샘플을 초당 900개 정도 보냅니다.
이러한 불필요한 측정항목을 필터링하면 청구서를 허용 가능한 수준으로 낮출 수 있습니다.
측정항목 수를 줄이려면 다음을 수행하면 됩니다.
- 스크래핑 구성을 수정하여 더 적은 대상을 스크래핑합니다.
- 다음 설명에 따라 수집된 측정항목을 필터링합니다.
- 관리형 컬렉션을 사용할 때 내보낸 측정항목을 필터링합니다.
- 자체 배포 컬렉션을 사용할 때 내보낸 측정항목 필터링합니다.
kube-state-metrics 서비스를 사용하는 경우 keep 작업으로 Prometheus 라벨 재지정 규칙을 추가할 수 있습니다. 관리형 컬렉션의 경우 이 규칙은 PodMonitoring 또는 ClusterPodMonitoring 정의에서 다룹니다. 자체 배포 컬렉션의 경우 이 규칙은 Prometheus 스크래핑 구성 또는 ServiceMonitor 정의(prometheus-operator용)에서 다룹니다.
예를 들어 새로운 3노드 클러스터에서 다음 필터를 사용하면 샘플 볼륨이 초당 약 125개 샘플로 줄어듭니다.
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
이전 필터는 정규 표현식을 사용하여 측정항목 이름을 기준으로 유지할 측정항목을 지정합니다. 예를 들어 이름이 kube_daemonset_으로 시작하는 측정항목은 유지됩니다.
또한 정규 표현식과 일치하는 측정항목을 필터링하는 drop 작업을 지정할 수도 있습니다.
전체 내보내기가 중요하지 않은 경우도 있습니다. 예를 들어 kube-prometheus 패키지는 기본적으로 다음 서비스 모니터를 설치하지만 그 중 상당수가 관리형 환경에서 필요하지 않습니다.
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
내보내는 측정항목 수를 줄이려면 필요하지 않은 서비스 모니터를 삭제, 지 또는 스크래핑하면 됩니다. 예를 들어 새로운 3노드 클러스터에서 kube-apiserver 서비스 모니터를 중지하면 샘플 볼륨이 초당 약 200개까지 줄어듭니다.
수집되는 샘플 수 줄이기
Managed Service for Prometheus는 샘플 단위로 요금을 청구합니다. 샘플링 기간을 늘리면 수집되는 샘플 수를 줄일 수 있습니다. 예를 들면 다음과 같습니다.
- 10초 샘플링 기간을 30초 샘플링 기간으로 변경하면 정보 손실 없이 샘플 볼륨을 66%까지 줄일 수 있습니다.
- 10초 샘플링 기간을 60초 샘플링 기간으로 변경하면 샘플 볼륨이 83%까지 줄어들 수 있습니다.
샘플 집계 방식과 샘플링 기간이 샘플 수에 미치는 영향에 대한 자세한 내용은 수집된 샘플별로 청구되는 측정항목 데이터를 참고하세요.
일반적으로 작업별 또는 대상별로 스크래핑 간격을 설정할 수 있습니다.
관리형 컬렉션의 경우 interval 필드를 사용하여 PodMonitoring 리소스에서 스크래핑 간격을 설정합니다.
자체 배포 컬렉션의 경우 일반적으로 interval 또는 scrape_interval 필드를 설정하여 스크래핑 구성에서 샘플링 간격을 설정합니다.
로컬 집계 구성(자체 배포 컬렉션만 해당)
셀프 배포 컬렉션(예: kube-prometheus, prometheus-operator)을 사용하거나 이미지를 수동으로 배포하여 서비스를 구성하는 경우 카디널리티가 높은 측정항목을 로컬에서 집계하여 Prometheus용 관리형 서비스로 전송된 샘플을 줄일 수 있습니다. 기록 규칙을 사용하여 instance와 같은 라벨을 집계하고 --export.match 플래그 또는 EXTRA_ARGS 환경 변수를 집계된 데이터만 Monarch에 전송할 수 있습니다.
예를 들어 high_cardinality_metric_1, high_cardinality_metric_2, low_cardinality_metric의 3개 측정항목이 있다고 가정합니다. high_cardinality_metric_1에 전송되는 샘플을 줄이고 high_cardinality_metric_2에 전송되는 모든 샘플을 삭제하면서 모든 원시 데이터를 로컬로 저장하려고 합니다(예: 알림 목적). 설정은 다음과 같습니다.
- Prometheus용 관리형 서비스 이미지를 배포합니다.
- 스크레이핑 구성을 구성하여 모든 원시 데이터를 로컬 서버로 스크레이핑하도록 합니다(원하는 만큼의 적은 필터를 사용).
기록 규칙을 구성하여
high_cardinality_metric_1및high_cardinality_metric_2에 로컬 집계를 실행합니다. 불필요한 시계열 수를 줄이는 데 어떤 방식이 가장 효과적인지에 따라instance라벨 또는 임의 수의 측정항목 라벨을 집계하여 이를 수행합니다. 다음과 같은 규칙을 실행할 수 있습니다. 이 규칙은instance라벨을 삭제하고 결과 시계열을 나머지 라벨에 합산합니다.record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
더 많은 집계 옵션은 Prometheus 문서의 집계 연산자를 참조하세요.
다음 필터 플래그를 사용하여 Prometheus용 관리형 서비스를 배포하면 나열된 측정항목의 원시 데이터가 Monarch로 전송되지 않습니다.
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'이
export.match플래그 예시에서는!=연산자로 쉼표로 구분된 선택기를 사용하여 원치 않는 원시 데이터를 필터링합니다. 카디널리티가 높은 측정항목을 집계하기 위해 기록 규칙을 추가하는 경우 원시 데이터가 삭제되도록 필터에 새__name__선택기도 추가해야 합니다.!=연산자와 함께 여러 선택기가 포함된 단일 플래그를 사용하여 원치 않는 데이터를 필터링하면 스크랩 구성을 수정하거나 추가할 때마다 필터를 수정할 필요 없이 새 집계를 만들 때만 필터를 수정하면 됩니다.prometheus-operator와 같은 특정 배포 방법을 사용하려면 대괄호 주위의 작은 따옴표를 생략해야 할 수 있습니다.
이 워크플로는 기록 규칙 및 export.match 플래그를 만들고 관리하는 데 약간의 운영 오버헤드를 일으킬 수 있지만 카디널리티가 매우 높은 측정항목에만 집중하여 볼륨을 많이 줄일 수 있습니다. 로컬 사전 집계를 통해 가장 큰 이점을 얻을 수 있는 측정항목을 식별하는 방법은 대용량 측정항목 식별을 참조하세요.
Prometheus용 관리형 서비스를 사용할 때는 페더레이션을 구현하지 않습니다. 이 워크플로에서는 단일 배포 Prometheus 서버가 필요한 모든 클러스터 수준 집계를 수행할 수 있으므로 페더레이션 서버가 사용되지 않게 됩니다. 페데레이션으로 인해 '알 수 없는' 유형의 측정항목 및 두 배가 된 수집 볼륨과 같은 예상치 못한 결과가 발생할 수 있습니다.
카디널리티가 높은 측정항목의 샘플 제한(자체 배포 컬렉션만 해당)
사용자 ID 또는 IP 주소와 같이 잠재적인 값이 많은 라벨을 추가하여 카디널리티가 매우 높은 측정항목을 만들 수 있습니다. 이러한 측정항목은 매우 많은 샘플을 생성할 수 있습니다. 값이 많은 라벨 사용은 일반적으로 잘못된 구성입니다. 스크레이핑 구성에서 sample_limit 값을 설정하면 자체 배포된 수집기에서 카디널리티가 높은 측정항목으로부터 보호할 수 있습니다.
이 한도를 사용하는 경우 잘못 구성된 측정항목만 포착하도록 매우 높은 값으로 설정하는 것이 좋습니다. 한도를 초과하는 샘플은 모두 삭제되며 한도를 초과하여 발생하는 문제를 진단하기가 매우 어려울 수 있습니다.
샘플 한도 사용은 샘플 수집을 관리하는 좋은 방법이 아니지만 한도를 통해 실수로 인한 잘못된 구성을 방지할 수 있습니다. 자세한 내용은 sample_limit를 사용하여 과부하 방지를 참조하세요.
비용 식별 및 기여 분석
Cloud Monitoring을 사용하여 샘플을 가장 많이 작성하는 Prometheus 측정항목을 식별할 수 있습니다. 이러한 측정항목은 비용에 가장 큰 영향을 미칩니다. 가장 비용이 많이 드는 측정항목을 식별한 후에는 스크레이핑 구성을 수정하여 이러한 측정항목을 적절하게 필터링할 수 있습니다.
Cloud Monitoring 측정항목 관리 페이지에서는 모니터링 가능성에 영향을 주지 않고 청구 가능 측정항목에 지출하는 금액을 제어할 수 있는 정보를 제공합니다. 측정항목 관리 페이지에서는 다음 정보를 보고합니다.
- 측정항목 도메인 및 개별 측정항목의 바이트 기반 및 샘플 기반 청구에 대한 수집량
- 측정항목의 라벨 및 카디널리티에 대한 데이터
- 각 측정항목의 읽기 수
- 알림 정책 및 커스텀 대시보드의 측정항목 사용
- 측정항목 쓰기 오류의 비율
또한 측정항목 관리 페이지를 사용하면 불필요한 측정항목을 제외하여 수집 비용을 절감할 수 있습니다.
측정항목 관리 페이지를 보려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 측정항목 관리 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- 툴바에서 기간을 선택합니다. 기본적으로 측정항목 관리 페이지에는 이전 1일 동안 수집된 측정항목에 대한 정보가 표시됩니다.
측정항목 관리 페이지에 대한 자세한 내용은 측정항목 사용량 보기 및 관리를 참조하세요.
다음 섹션에서는 Managed Service for Prometheus에 전송하는 샘플 수를 분석하고 특정 측정항목, Kubernetes 네임스페이스, Google Cloud 리전에 대용량을 부여하는 방법을 설명합니다.
대용량 측정항목 식별
수집량이 가장 큰 Prometheus 측정항목을 식별하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 측정항목 관리 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- 수집된 청구 가능한 샘플 스코어카드에서 차트 보기를 클릭합니다.
- 네임스페이스 볼륨 수집 차트를 찾은 후 more_vert 차트 옵션 더보기를 클릭합니다.
- 측정항목 탐색기에서 보기 차트 옵션을 선택합니다.
- 측정항목 탐색기의 빌더 창에서 다음과 같이 필드를 수정합니다.
- 측정항목 필드에서 다음 리소스와 측정항목이 선택되어 있는지 확인합니다.
Metric Ingestion Attribution및Samples written by attribution id. - 집계 필드에서
sum을 선택합니다. - 기준 필드에서 다음 라벨을 선택합니다.
attribution_dimensionmetric_type
- 필터 필드에서
attribution_dimension = namespace를 사용합니다. 이 작업은attribution_dimension라벨별로 집계한 후에 수행해야 합니다.
결과 차트에는 각 측정항목 유형의 수집량이 표시됩니다.
- 측정항목 필드에서 다음 리소스와 측정항목이 선택되어 있는지 확인합니다.
- 각 측정항목의 수집량을 확인하려면 차트 테이블 모두 라벨이 지정된 전환 버튼에서 모두를 선택합니다. 테이블에는 값 열의 측정항목마다 수집된 볼륨이 표시됩니다.
- 값 열 헤더를 두 번 클릭하여 수집 볼륨 내림차순으로 측정항목을 정렬합니다.
볼륨별 상위 측정항목을 표시하는 결과 차트는 다음 스크린샷과 같습니다.
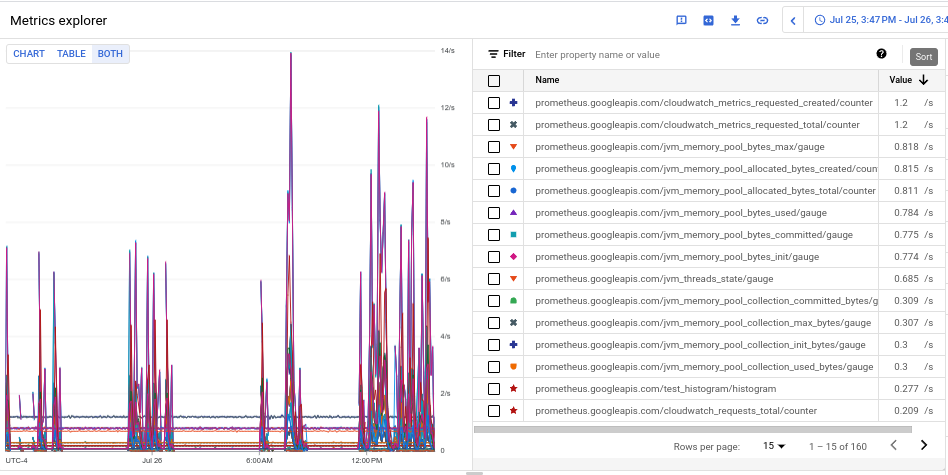
대용량 네임스페이스 식별
특정 Kubernetes 네임스페이스에 수집 볼륨 기여도를 부여하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 측정항목 관리 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- 수집된 청구 가능한 샘플 스코어카드에서 차트 보기를 클릭합니다.
- 네임스페이스 볼륨 수집 차트를 찾은 후 more_vert 차트 옵션 더보기를 클릭합니다.
- 측정항목 탐색기에서 보기 차트 옵션을 선택합니다.
- 측정항목 탐색기의 빌더 창에서 다음과 같이 필드를 수정합니다.
- 측정항목 필드에서 다음 리소스와 측정항목이 선택되어 있는지 확인합니다.
Metric Ingestion Attribution및Samples written by attribution id. - 나머지 쿼리 매개변수를 적절하게 구성합니다.
- 전체 수집량과 네임스페이스의 상관관계를 지정하려면 다음 안내를 따르세요.
- 집계 필드에서
sum을 선택합니다. - 기준 필드에서 다음 라벨을 선택합니다.
attribution_dimensionattribution_id
- 필터 필드에서
attribution_dimension = namespace를 사용합니다.
- 집계 필드에서
- 개별 측정항목의 수집량과 네임스페이스의 상관관계를 지정하려면 다음 안내를 따르세요.
- 집계 필드에서
sum을 선택합니다. - 기준 필드에서 다음 라벨을 선택합니다.
attribution_dimensionattribution_idmetric_type
- 필터 필드에서
attribution_dimension = namespace를 사용합니다.
- 집계 필드에서
- 특정 대용량 측정항목을 담당하는 네임스페이스를 식별하려면 다음 안내를 따르세요.
- 대용량 측정항목 유형을 식별하려면 다른 예시 중 하나를 사용하여 대용량 측정항목의 측정항목 유형을 식별합니다. 측정항목 유형은 테이블 뷰에서
prometheus.googleapis.com/으로 시작하는 문자열입니다. 자세한 내용은 대용량 측정항목 식별을 참조하세요. - 필터 필드에서 측정항목 유형에 대한 필터를 추가하여 차트 데이터를 식별된 측정항목 유형으로 제한합니다. 예를 들면 다음과 같습니다.
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - 집계 필드에서
sum을 선택합니다. - 기준 필드에서 다음 라벨을 선택합니다.
attribution_dimensionattribution_id
- 필터 필드에서
attribution_dimension = namespace를 사용합니다.
- 대용량 측정항목 유형을 식별하려면 다른 예시 중 하나를 사용하여 대용량 측정항목의 측정항목 유형을 식별합니다. 측정항목 유형은 테이블 뷰에서
- Google Cloud 리전별 수집을 보려면 기준 필드에
location라벨을 추가합니다. - Google Cloud 프로젝트별 수집을 보려면 기준 필드에
resource_container라벨을 추가합니다.
- 전체 수집량과 네임스페이스의 상관관계를 지정하려면 다음 안내를 따르세요.
- 측정항목 필드에서 다음 리소스와 측정항목이 선택되어 있는지 확인합니다.