Conforme descrito em Planos de execução de consultas, o compilador SQL transforma uma declaração SQL num plano de execução de consultas, que é usado para obter os resultados da consulta. Esta página descreve as práticas recomendadas para criar declarações SQL de modo a ajudar o Spanner a encontrar planos de execução eficientes.
As declarações SQL de exemplo apresentadas nesta página usam o seguinte esquema de exemplo:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Para ver a referência SQL completa, consulte a sintaxe de declarações, funções e operadores e estrutura lexical e sintaxe.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Para mais informações, consulte o artigo A linguagem PostgreSQL no Spanner.
Use parâmetros de consulta
O Spanner suporta parâmetros de consulta para aumentar o desempenho e ajudar a evitar a injeção SQL quando as consultas são criadas com a entrada do utilizador. Pode usar parâmetros de consulta como substitutos de expressões arbitrárias, mas não como substitutos de identificadores, nomes de colunas, nomes de tabelas ou outras partes da consulta.
Os parâmetros podem aparecer em qualquer lugar onde seja esperado um valor literal. O mesmo nome do parâmetro pode ser usado mais do que uma vez numa única declaração SQL.
Em resumo, os parâmetros de consulta suportam a execução de consultas das seguintes formas:
- Planos pré-otimizados: as consultas que usam parâmetros podem ser executadas mais rapidamente em cada invocação porque a parametrização facilita o armazenamento em cache do plano de execução no Spanner.
- Composição de consultas simplificada: não tem de escapar a valores de strings quando os fornece em parâmetros de consulta. Os parâmetros de consulta também reduzem o risco de erros de sintaxe.
- Segurança: os parâmetros de consulta tornam as suas consultas mais seguras, protegendo-as de vários ataques de injeção de SQL. Esta proteção é especialmente importante para as consultas que cria a partir da introdução do utilizador.
Compreenda como o Spanner executa consultas
O Spanner permite-lhe consultar bases de dados através de declarações SQL declarativas que especificam os dados que quer obter. Se quiser saber como o Spanner obtém os resultados, examine o plano de execução da consulta. Um plano de execução de consultas apresenta o custo computacional associado a cada passo da consulta. Com esses custos, pode depurar problemas de desempenho de consultas e otimizar a sua consulta. Para saber mais, consulte o artigo Planos de execução de consultas.
Pode obter planos de execução de consultas através da Google Cloud consola ou das bibliotecas cliente.
Para obter um plano de execução de consultas para uma consulta específica através da Google Cloud consola, siga estes passos:
Abra a página de instâncias do Spanner.
Selecione os nomes da instância do Spanner e da base de dados que quer consultar.
Clique em Spanner Studio no painel de navegação do lado esquerdo.
Escreva a consulta no campo de texto e, de seguida, clique em Executar consulta.
Clique em Explicação
. A Google Cloud consola apresenta um plano de execução visual para a sua consulta.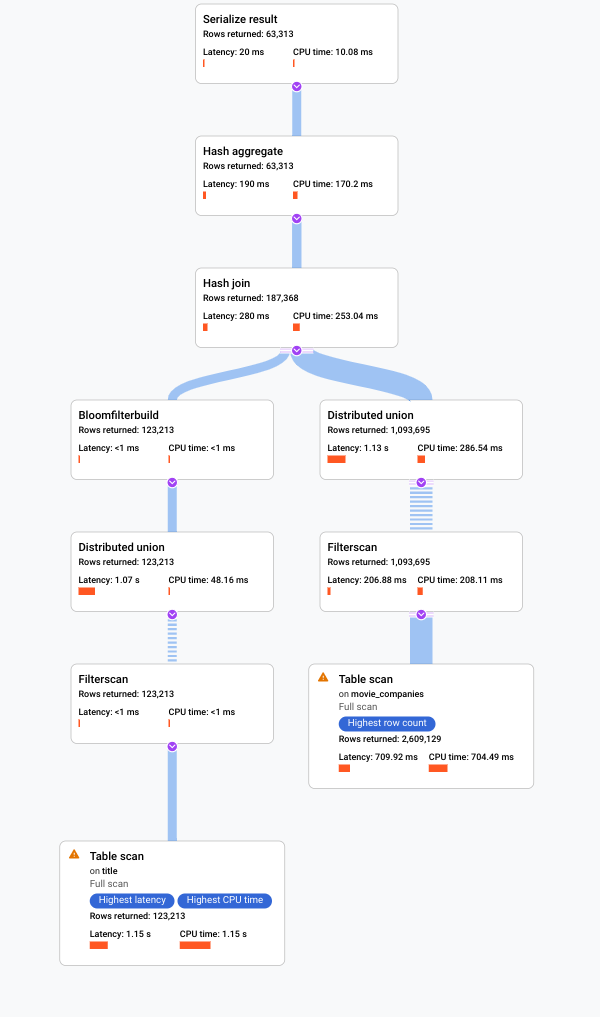
Para mais informações sobre como compreender os planos visuais e usá-los para depurar as suas consultas, consulte o artigo Otimize uma consulta com o visualizador de planos de consultas.
Também pode ver exemplos de planos de consultas históricos e comparar o desempenho de uma consulta ao longo do tempo para determinadas consultas. Para saber mais, consulte o artigo Planos de consultas com amostras.
Use índices secundários
Tal como outras bases de dados relacionais, o Spanner oferece índices secundários, que pode usar para obter dados através de uma declaração SQL ou da interface de leitura do Spanner. A forma mais comum de obter dados de um índice é usar o Spanner Studio. A utilização de um índice secundário numa consulta SQL permite especificar como quer que o Spanner obtenha os resultados. A especificação de um índice secundário pode acelerar a execução de consultas.
Por exemplo, suponhamos que quer obter os IDs de todos os cantores com um apelido específico. Uma forma de escrever uma consulta SQL deste tipo é:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
Esta consulta devolve os resultados que espera, mas pode demorar muito tempo a devolvê-los. O tempo depende do número de linhas na tabela Singers e de quantas satisfazem o predicado WHERE s.LastName = 'Smith'. Se não existir um índice secundário que contenha a coluna LastName a partir da qual ler, o plano de consulta lê a tabela Singers inteira para encontrar linhas que correspondam ao predicado. A leitura de toda a tabela chama-se análise completa da tabela. Uma análise completa da tabela é uma forma dispendiosa de obter os resultados quando a tabela contém apenas uma pequena percentagem de Singers com esse apelido.
Pode melhorar o desempenho desta consulta definindo um índice secundário na coluna do apelido:
CREATE INDEX SingersByLastName ON Singers (LastName);
Uma vez que o índice secundário SingersByLastName contém a coluna da tabela indexada LastName e a coluna da chave primária SingerId, o Spanner pode obter todos os dados da tabela de índice muito mais pequena em vez de analisar a tabela Singers completa.
Neste cenário, o Spanner usa automaticamente o índice secundário SingersByLastName quando executa a consulta (desde que tenham passado três dias desde a criação da base de dados; consulte uma nota sobre novas bases de dados). No entanto, é melhor indicar explicitamente ao Spanner que use esse índice especificando uma diretiva de índice na cláusula FROM:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Agora, suponhamos que também quer obter o nome próprio do cantor, além do ID. Embora a coluna FirstName não esteja contida no índice, deve
continuar a especificar a diretiva de índice como antes:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Continua a ter uma vantagem de desempenho ao usar o índice porque o Spanner não precisa de fazer uma análise completa da tabela quando executa o plano de consulta. Em vez disso, seleciona o subconjunto de linhas que satisfazem o predicado do índice SingersByLastName e, em seguida, faz uma pesquisa na tabela base Singers para obter o primeiro nome apenas para esse subconjunto de linhas.
Se quiser que o Spanner não tenha de obter nenhuma linha da tabela base, pode armazenar uma cópia da coluna FirstName no próprio índice:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
A utilização de uma cláusula STORING (para o dialeto GoogleSQL) ou uma cláusula INCLUDE (para o dialeto PostgreSQL) como esta implica um custo de armazenamento adicional, mas oferece as seguintes vantagens:
- As consultas SQL que usam o índice e selecionam colunas armazenadas na cláusula
STORINGouINCLUDEnão requerem uma junção adicional à tabela base. - As chamadas de leitura que usam o índice podem ler colunas armazenadas na cláusula
STORINGouINCLUDE.
Os exemplos anteriores ilustram como os índices secundários podem acelerar as consultas quando as linhas escolhidas pela cláusula WHERE de uma consulta podem ser rapidamente identificadas através do índice secundário.
Outro cenário em que os índices secundários podem oferecer vantagens de desempenho é para determinadas consultas que devolvem resultados ordenados. Por exemplo, suponhamos que quer obter todos os títulos dos álbuns e as respetivas datas de lançamento por ordem ascendente da data de lançamento e ordem descendente do título do álbum. Pode escrever uma consulta SQL da seguinte forma:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Sem um índice secundário, esta consulta requer um passo de ordenação potencialmente dispendioso no plano de execução. Pode acelerar a execução de consultas definindo este índice secundário:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
Em seguida, reescreva a consulta para usar o índice secundário:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Esta consulta e definição de índice cumprem ambos os seguintes critérios:
- Para remover o passo de ordenação, certifique-se de que a lista de colunas na cláusula
ORDER BYé um prefixo da lista de chaves de índice. - Para evitar a junção novamente a partir da tabela base para obter colunas em falta, certifique-se de que o índice abrange todas as colunas na tabela que a consulta usa.
Embora os índices secundários possam acelerar as consultas comuns, a adição de índices secundários pode adicionar latência às suas operações de confirmação, porque cada índice secundário requer normalmente o envolvimento de um nó adicional em cada confirmação. Para a maioria das cargas de trabalho, ter alguns índices secundários não é um problema. No entanto, deve ponderar se se preocupa mais com a latência de leitura ou de escrita e considerar que operações são mais críticas para a sua carga de trabalho. Compare a sua carga de trabalho com os resultados de testes de referência para garantir que tem o desempenho esperado.
Para a referência completa sobre os índices secundários, consulte o artigo Índices secundários.
Otimize as análises
Determinadas consultas do Spanner podem beneficiar da utilização de um método de processamento orientado por lotes ao analisar dados, em vez do método de processamento orientado por linhas mais comum. O processamento de exames em lotes é uma forma mais eficiente de processar grandes volumes de dados de uma só vez e permite que as consultas alcancem uma utilização e uma latência da CPU mais baixas.
A operação de análise do Spanner inicia sempre a execução no método orientado por linhas. Durante este período, o Spanner recolhe várias métricas de tempo de execução. Em seguida, o Spanner aplica um conjunto de heurísticas com base no resultado destas métricas para determinar o método de análise ideal. Quando adequado, o Spanner muda para um método de processamento orientado por lotes para ajudar a melhorar o débito e o desempenho da análise.
Exemplos de utilização comuns
Geralmente, as consultas com as seguintes caraterísticas beneficiam da utilização do processamento orientado por lotes:
- Análises grandes em dados atualizados com pouca frequência.
- Análises com predicados em colunas de largura fixa.
- Análises com um grande número de pesquisas. (Uma procura usa um índice para obter registos.)
Exemplos de utilização sem ganhos de desempenho
Nem todas as consultas beneficiam do processamento orientado por lotes. Os seguintes tipos de consultas têm um melhor desempenho com o processamento de análise orientado por linhas:
- Consultas de pesquisa de pontos: consultas que apenas obtêm uma linha.
- Consultas de análise pequenas: análises de tabelas que analisam apenas algumas linhas, a menos que tenham um número elevado de procuras.
- Consultas que usam
LIMIT. - Consultas que leem dados de elevada rotatividade: consultas em que mais de ~10% dos dados lidos são atualizados com frequência.
- Consultas com linhas que contêm valores grandes: as linhas com valores grandes são as que contêm valores superiores a 32 000 bytes (antes da compressão) numa única coluna.
Verifique o método de análise usado por uma consulta
Para verificar se a sua consulta usa o processamento orientado por lotes, o processamento orientado por linhas ou se está a alternar automaticamente entre os dois métodos de análise:
Aceda à página Instances do Spanner na Google Cloud consola.
Clique no nome da instância com a consulta que quer investigar.
Na tabela Bases de dados, clique na base de dados com a consulta que quer investigar.
No menu de navegação, clique em Spanner Studio.
Abra um novo separador clicando em Novo separador do editor de SQL ou Novo separador.
Quando o editor de consultas aparecer, escreva a sua consulta.
Clique em Executar.
O Spanner executa a consulta e mostra os resultados.
Clique no separador Explicação abaixo do editor de consultas.
O Spanner mostra um visualizador do plano de execução de consultas. Cada cartão no gráfico representa um iterador.
Clique no cartão do iterador Tabela de verificação para abrir um painel de informações.
O painel de informações mostra informações contextuais acerca da análise selecionada. O método de análise é apresentado neste cartão. Automático indica que o Spanner determina o método de análise. Outros valores possíveis incluem Batch para processamento orientado por lotes e Row para processamento orientado por linhas.
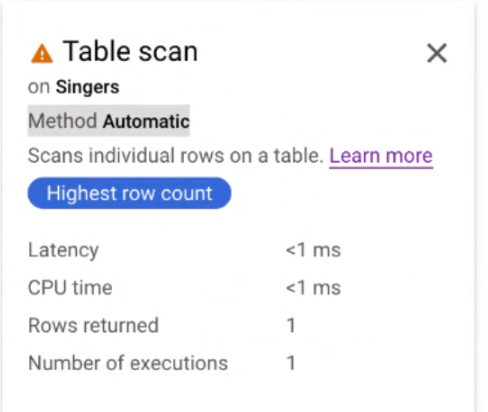
Aplique o método de análise usado por uma consulta
Para otimizar o desempenho das consultas, o Spanner escolhe o método de análise ideal para a sua consulta. Recomendamos que use este método de análise predefinido. No entanto, pode haver cenários em que queira aplicar um tipo específico de método de controlo.
Aplique a leitura orientada por lotes
Pode aplicar a análise orientada por lotes ao nível da tabela e da declaração.
Para aplicar o método de análise orientado por lotes ao nível da tabela, use uma sugestão de tabela na sua consulta:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
Para aplicar o método de análise orientado por lotes ao nível da declaração, use uma dica de declaração na sua consulta:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
Desative a análise automática e aplique a análise orientada por linhas
Embora não recomendemos a desativação do método de análise automática definido pelo Spanner, pode optar por desativá-lo e usar o método de análise orientado por linhas para fins de resolução de problemas, como o diagnóstico da latência.
Para desativar o método de análise automática e aplicar o processamento de linhas ao nível da tabela, use uma sugestão de tabela na sua consulta:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
Para desativar o método de análise automática e aplicar o processamento de linhas ao nível da declaração, use uma sugestão de declaração na sua consulta:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
Otimize a execução de consultas
Além de otimizar as análises, também pode otimizar a execução de consultas aplicando o método de execução ao nível da declaração. Esta opção só funciona para alguns operadores e é independente do método de análise, que só é usado pelo operador de análise.
Por predefinição, a maioria dos operadores é executada no método orientado por linhas, que processa os dados uma linha de cada vez. Os operadores vetorizados são executados no método orientado por lotes para ajudar a melhorar o débito de execução e o desempenho. Estes operadores processam os dados um bloco de cada vez. Quando um operador precisa de processar muitas linhas, o método de execução orientado por lotes é normalmente mais eficiente.
Método de execução versus método de análise
O método de execução da consulta é independente do método de análise da consulta. Pode definir um, ambos ou nenhum destes métodos na sugestão de consulta.
O método de execução de consultas refere-se à forma como os operadores de consultas processam os resultados intermédios e como os operadores interagem entre si, enquanto o método de análise refere-se à forma como o operador de análise interage com a camada de armazenamento do Spanner.
Aplique o método de execução usado pela consulta
Para otimizar o desempenho das consultas, o Spanner escolhe o método de execução ideal para a sua consulta com base em várias heurísticas. Recomendamos que use este método de execução predefinido. No entanto, pode haver cenários em que queira aplicar um tipo específico de método de execução.
Pode aplicar o método de execução ao nível da declaração. O elemento
EXECUTION_METHOD é uma sugestão de consulta e não uma diretiva. Em última análise, o otimizador de consultas decide que método usar para cada operador individual.
Para aplicar o método de execução orientado por lotes ao nível da declaração, use uma dica de declaração na sua consulta:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
Embora não recomendemos a desativação do método de execução automático definido pelo Spanner, pode optar por desativá-lo e usar o método de execução orientado por linhas para fins de resolução de problemas, como o diagnóstico da latência.
Para desativar o método de execução automática e aplicar o método de execução orientado por linhas ao nível da declaração, use uma sugestão de declaração na sua consulta:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
Verifique que método de execução está ativado
Nem todos os operadores do Spanner suportam métodos de execução orientados por lotes e orientados por linhas. Para cada operador, o visualizador do plano de execução de consultas mostra o método de execução no cartão do iterador. Se o método de execução for orientado para lotes, é apresentado Lote. Se estiver orientado para as linhas, mostra Linha.
Se os operadores na sua consulta forem executados através de métodos de execução diferentes, os adaptadores do método de execução DataBlockToRowAdapter e RowToDataBlockAdapter aparecem entre os operadores para mostrar a alteração no método de execução.
Otimize as pesquisas de chaves de intervalo
Uma utilização comum de uma consulta SQL é ler várias linhas do Spanner com base numa lista de chaves conhecidas.
As práticas recomendadas seguintes ajudam a escrever consultas eficientes quando obtém dados por um intervalo de chaves:
Se a lista de chaves for esparsa e não adjacente, use parâmetros de consulta e
UNNESTpara criar a sua consulta.Por exemplo, se a sua lista de chaves for
{1, 5, 1000}, escreva a consulta da seguinte forma:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
Notas:
O operador de matriz UNNEST reduz uma matriz de entrada a linhas de elementos.
O parâmetro de consulta, que é
@KeyListpara o GoogleSQL e$1para o PostgreSQL, pode acelerar a sua consulta, conforme abordado na prática recomendada anterior.
Se a lista de chaves for adjacente e estiver dentro de um intervalo, especifique os limites inferior e superior do intervalo de chaves na cláusula
WHERE.Por exemplo, se a sua lista de chaves for
{1,2,3,4,5}, construa a consulta da seguinte forma:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
Esta consulta só é mais eficiente se as chaves no intervalo de chaves forem adjacentes. Por outras palavras, se a sua lista de chaves for
{1, 5, 1000}, não especifique os limites inferior e superior como na consulta anterior, porque a consulta resultante analisaria todos os valores entre 1 e 1000.
Otimize as junções
As operações de junção podem ser dispendiosas porque podem aumentar significativamente o número de linhas que a sua consulta tem de analisar, o que resulta em consultas mais lentas. Além das técnicas que está habituado a usar noutras bases de dados relacionais para otimizar as consultas de junção, seguem-se algumas práticas recomendadas para uma junção mais eficiente quando usa o Spanner SQL:
Se possível, junte dados em tabelas intercaladas pela chave primária. Por exemplo:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
Garante-se que as linhas na tabela intercalada
Albumssão armazenadas fisicamente nas mesmas divisões que a linha principal emSingers, conforme abordado em Esquema e modelo de dados. Por conseguinte, as junções podem ser concluídas localmente sem enviar muitos dados através da rede.Use a diretiva de junção se quiser forçar a ordem da junção. Por exemplo:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
A diretiva de junção
FORCE_JOIN_ORDERindica ao Spanner que deve usar a ordem de junção especificada na consulta (ou seja,Singers JOIN Albumse nãoAlbums JOIN Singers). Os resultados devolvidos são os mesmos, independentemente da ordem escolhida pelo Spanner. No entanto, pode querer usar esta diretiva de junção se notar no plano de consulta que o Spanner alterou a ordem de junção e causou consequências indesejáveis, como resultados intermédios maiores, ou perdeu oportunidades de procurar linhas.Use uma diretiva de junção para escolher uma implementação de junção. Quando usa SQL para consultar várias tabelas, o Spanner usa automaticamente um método de junção que provavelmente torna a consulta mais eficiente. No entanto, a Google recomenda que faça testes com diferentes algoritmos de junção. A escolha do algoritmo de junção adequado pode melhorar a latência, o consumo de memória ou ambos. Esta consulta demonstra a sintaxe para usar uma diretiva JOIN com a sugestão
JOIN_METHODpara escolher umHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
Se estiver a usar um
HASH JOINou umAPPLY JOINe tiver uma cláusulaWHEREaltamente seletiva num dos lados doJOIN, coloque a tabela que produz o menor número de linhas como a primeira tabela na cláusulaFROMda junção. Esta estrutura ajuda porque, emHASH JOIN, o Spanner escolhe sempre a tabela do lado esquerdo como tabela de criação e a tabela do lado direito como tabela de sondagem. Da mesma forma, paraAPPLY JOIN, o Spanner escolhe a tabela do lado esquerdo como externa e a tabela do lado direito como interna. Veja mais informações sobre estes tipos de junções: Junção hash e Junção de aplicação.Para consultas críticas para a sua carga de trabalho, especifique o método de junção e a ordem de junção com melhor desempenho nas suas declarações SQL para um desempenho mais consistente.
Otimize as consultas com o pushdown do predicado de indicação de tempo
O pushdown de predicados de data/hora é uma técnica de otimização de consultas usada no Spanner para melhorar a eficiência das consultas que usam datas/horas e dados com uma política de armazenamento hierárquico baseada na antiguidade. Quando ativa esta otimização, as operações de filtragem nas colunas de data/hora são realizadas o mais cedo possível no plano de execução da consulta. Isto pode reduzir significativamente a quantidade de dados processados e melhorar o desempenho geral das consultas.
Com o pushdown do predicado de data/hora, o motor da base de dados analisa a consulta e identifica o filtro de data/hora. Em seguida, "envia" este filtro para a camada de armazenamento, para que apenas os dados relevantes com base nos critérios de data/hora sejam lidos a partir do SSD. Isto minimiza a quantidade de dados processados e transferidos, o que resulta numa execução de consultas mais rápida.
Para otimizar as consultas de modo a aceder apenas aos dados armazenados no SSD, têm de se aplicar as seguintes condições:
- A consulta tem de ter o pushdown do predicado de data/hora ativado. Para mais informações, consulte as sugestões de declarações do GoogleSQL e as sugestões de declarações do PostgreSQL
- A consulta tem de usar uma restrição baseada na idade igual ou inferior à idade especificada na política de transbordo de dados (definida com a opção
ssd_to_hdd_spill_timespanno comando DDLCREATE LOCALITY GROUPouALTER LOCALITY GROUP). Para mais informações, consulte as declarações GoogleSQLLOCALITY GROUPe as declarações PostgreSQLLOCALITY GROUP. A coluna que está a ser filtrada na consulta tem de ser uma coluna de data/hora que contenha a data/hora de confirmação. Para ver detalhes sobre como criar uma coluna de data/hora de confirmação, consulte os artigos Datas/horas de confirmação no GoogleSQL e Datas/horas de confirmação no PostgreSQL. Estas colunas têm de ser atualizadas juntamente com a coluna de data/hora e residir no mesmo grupo de localidades, que tem uma política de armazenamento hierarquizada baseada na idade.
Se, para uma determinada linha, algumas das colunas consultadas residirem no SSD e algumas das colunas residirem no HDD (devido à atualização das colunas em alturas diferentes e à migração para o HDD em alturas diferentes), o desempenho da consulta pode ser pior quando usa a sugestão. Isto deve-se ao facto de a consulta ter de preencher dados das diferentes camadas de armazenamento. Como resultado da utilização da sugestão, o Spanner envelhece os dados ao nível da célula individual (nível de granularidade de linha e coluna) com base na data/hora de confirmação de cada célula, o que torna a consulta mais lenta. Para evitar este problema, certifique-se de que atualiza rotineiramente todas as colunas consultadas através desta técnica de otimização na mesma transação, para que todas as colunas partilhem a mesma data/hora de confirmação e beneficiem da otimização.
Para ativar o pushdown do predicado de data/hora ao nível da declaração, use uma dica de declaração na sua consulta. Por exemplo:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
Evite leituras grandes em transações de leitura/escrita
As transações de leitura/escrita permitem uma sequência de zero ou mais leituras ou consultas SQL e podem incluir um conjunto de mutações antes de uma chamada para confirmação. Para manter a consistência dos seus dados, o Spanner adquire bloqueios ao ler e escrever linhas nas suas tabelas e índices. Para mais informações sobre o bloqueio, consulte o artigo Ciclo de vida das leituras e escritas.
Devido à forma como o bloqueio funciona no Spanner, a execução de uma leitura ou de uma consulta SQL que lê um grande número de linhas (por exemplo, SELECT * FROM Singers) significa que nenhuma outra transação pode escrever nas linhas que leu até que a sua transação seja confirmada ou anulada.
Além disso, uma vez que a sua transação está a processar um grande número de linhas, é
provável que demore mais tempo do que uma transação que lê um intervalo de linhas muito menor
(por exemplo, SELECT LastName FROM Singers WHERE SingerId = 7), o que agrava ainda mais o problema e reduz o débito do sistema.
Por isso, tente evitar leituras grandes (por exemplo, verificações completas de tabelas ou operações de junção massivas) nas suas transações, a menos que queira aceitar um débito de gravação inferior.
Em alguns casos, o seguinte padrão pode gerar melhores resultados:
- Faça as suas leituras grandes numa transação só de leitura. As transações só de leitura permitem um débito agregado mais elevado porque não usam bloqueios.
- Opcional: faça qualquer processamento necessário nos dados que acabou de ler.
- Inicie uma transação de leitura/escrita.
- Verifique se as linhas críticas não alteraram os valores desde que realizou a transação só de leitura no passo 1.
- Se as linhas tiverem sido alteradas, reverta a transação e comece novamente no passo 1.
- Se tudo parecer correto, confirme as suas mutações.
Uma forma de garantir que evita leituras grandes em transações de leitura/escrita é analisar os planos de execução gerados pelas suas consultas.
Use ORDER BY para garantir a ordenação dos resultados SQL
Se espera uma determinada ordenação para os resultados de uma consulta SELECT, inclua explicitamente a cláusula ORDER BY. Por exemplo, se quiser
apresentar todos os cantores por ordem da chave principal, use esta consulta:
SELECT * FROM Singers
ORDER BY SingerId;
O Spanner garante a ordenação dos resultados apenas se a cláusula ORDER BY estiver presente na consulta. Por outras palavras, considere esta consulta sem o ORDER
BY:
SELECT * FROM Singers;
O Spanner não garante que os resultados desta consulta estejam
por ordem da chave primária. Além disso, a ordem dos resultados pode mudar em qualquer altura e não é garantido que seja consistente de invocação para invocação. Se uma consulta tiver uma cláusula ORDER BY e o Spanner usar um índice que forneça a ordem necessária, o Spanner não ordena explicitamente os dados. Por conseguinte, não se preocupe com o impacto no desempenho da inclusão desta cláusula. Pode verificar se uma operação de ordenação explícita está incluída na execução consultando o plano de consulta.
Use STARTS_WITH em vez de LIKE
Uma vez que o Spanner não avalia padrões LIKEparametrizados
até ao momento da execução, o Spanner tem de ler todas as linhas e avaliá-las
em função da expressão LIKEpara filtrar as linhas que não correspondem.
Quando um padrão LIKE tem o formato foo% (por exemplo, começa com uma string fixa e termina com uma percentagem de carateres universais única) e a coluna está indexada, use STARTS_WITH em vez de LIKE. Esta opção permite que o Spanner otimize o plano de execução da consulta de forma mais eficaz.
Não recomendado:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
Recomendado:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
Use indicações de tempo de confirmação
Se a sua aplicação precisar de consultar dados escritos após uma hora específica,
adicione colunas de data/hora de confirmação às tabelas relevantes. As datas/horas de confirmação permitem uma otimização do Spanner que pode reduzir a E/S de consultas cujas cláusulas WHERE restringem os resultados a linhas escritas mais recentemente do que uma hora específica.
Saiba mais sobre esta otimização com bases de dados de dialeto GoogleSQL ou com bases de dados de dialeto PostgreSQL.