Vista geral
Esta página fornece conceitos sobre planos de execução de consultas e como são usados pelo Spanner para executar consultas num ambiente distribuído. Para saber como obter um plano de execução para uma consulta específica através da Google Cloud consola, consulte o artigo Compreenda como o Spanner executa consultas. Também pode ver planos de consultas históricos com base em amostras e comparar o desempenho de uma consulta ao longo do tempo para determinadas consultas. Para saber mais, consulte o artigo Planos de consultas com amostras.
O Spanner usa declarações SQL declarativas para consultar as respetivas bases de dados. As declarações SQL definem o que o utilizador quer sem especificar como obter os resultados. Um plano de execução de consultas é o conjunto de passos que indicam como os resultados são obtidos. Para uma determinada declaração SQL, podem existir várias formas de obter os resultados. O otimizador de consultas do Spanner avalia diferentes planos de execução e escolhe o que considera mais eficiente. Em seguida, o Spanner usa o plano de execução para obter os resultados.
Em termos conceptuais, um plano de execução é uma árvore de operadores relacionais. Cada operador lê linhas das respetivas entradas e produz linhas de saída. O resultado do operador na raiz da execução é devolvido como o resultado da consulta SQL.
Por exemplo, esta consulta:
SELECT s.SongName FROM Songs AS s;
resulta num plano de execução de consultas que pode ser visualizado da seguinte forma:
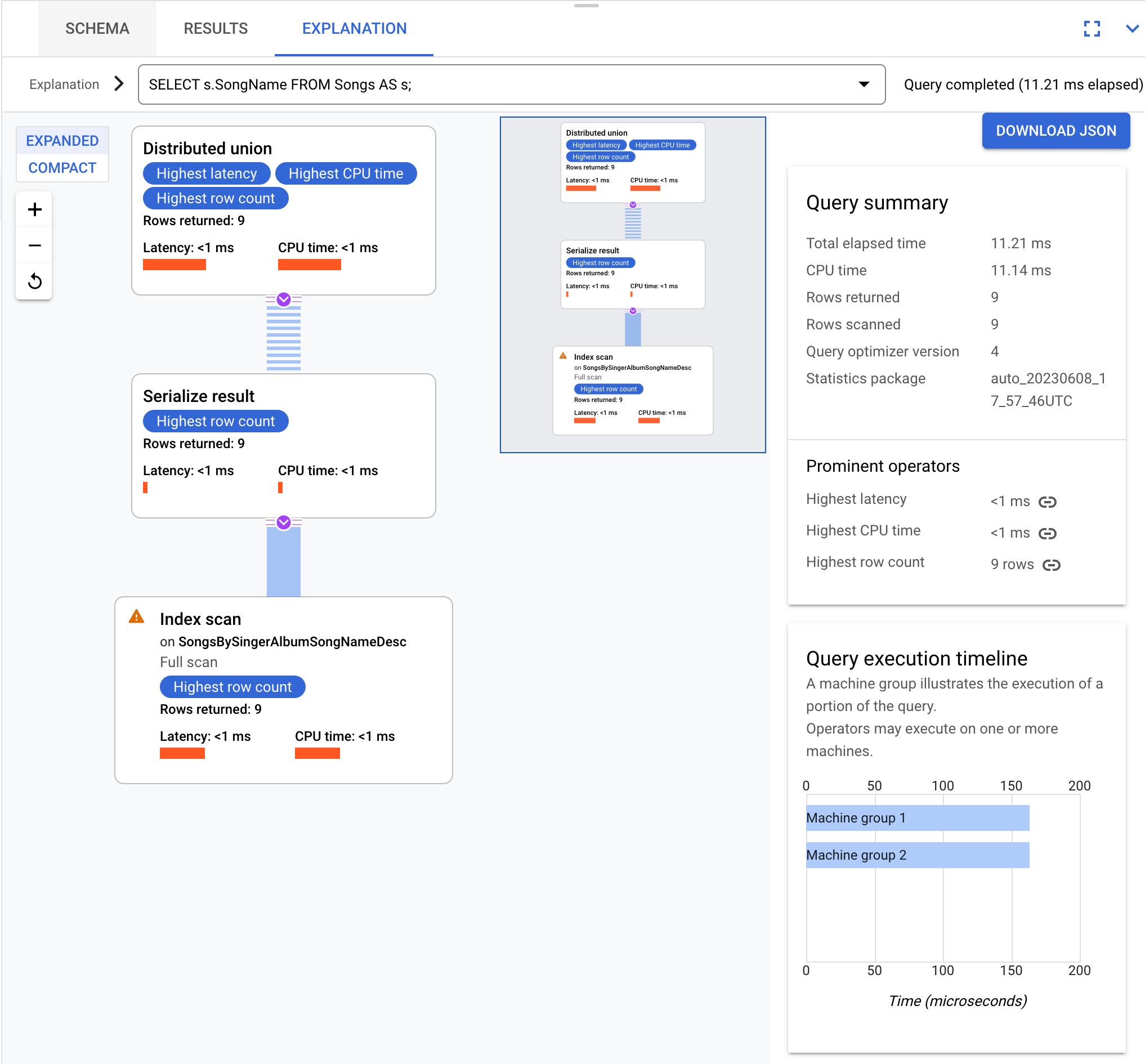
As consultas e os planos de execução nesta página baseiam-se no seguinte esquema da base de dados:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Pode usar as seguintes declarações da linguagem de manipulação de dados (DML) para adicionar dados a estas tabelas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
A obtenção de planos de execução eficientes é difícil porque o Spanner divide os dados em divisões. As divisões podem mover-se independentemente umas das outras e ser atribuídas a servidores diferentes, que podem estar em localizações físicas diferentes. Para avaliar planos de execução sobre os dados distribuídos, o Spanner usa a execução com base no seguinte:
- Execução local de subplanos em servidores que contêm os dados
- orquestração e agregação de várias execuções remotas com eliminação agressiva da distribuição
O Spanner usa o operador primitivo distributed union, juntamente com as respetivas variantes distributed cross apply e distributed outer apply, para ativar este modelo.
Planos de consulta com amostragem
Os planos de consulta com amostragem do Spanner permitem-lhe ver exemplos de planos de consulta históricos e comparar o desempenho de uma consulta ao longo do tempo. Nem todas as consultas têm planos de consulta com amostragem disponíveis. Apenas as consultas que consomem mais CPU podem ser amostradas. A retenção de dados para exemplos de planos de consultas do Spanner é de 30 dias. Pode encontrar exemplos de planos de consultas na página Estatísticas de consultas da Google Cloud consola. Para ver instruções, consulte o artigo Veja planos de consultas com amostragem.
A anatomia de um plano de consulta com amostragem é igual à de um plano de execução de consulta normal. Para mais informações sobre como compreender os planos visuais e usá-los para depurar as suas consultas, consulte Uma visita guiada ao visualizador do plano de consulta.
Exemplos de utilização comuns para planos de consulta com amostragem:
Seguem-se alguns exemplos de utilização comuns para planos de consultas com amostragem:
- Observe as alterações do plano de consulta devido a alterações do esquema (por exemplo, adicionar ou remover um índice).
- Observe as alterações do plano de consulta devido a uma atualização da versão do otimizador.
- Observe as alterações ao plano de consulta devido a novas estatísticas do otimizador, que são recolhidas automaticamente a cada três dias ou realizadas manualmente através do comando
ANALYZE.
Se o desempenho de uma consulta mostrar uma diferença significativa ao longo do tempo ou se quiser melhorar o desempenho de uma consulta, consulte as práticas recomendadas de SQL para criar instruções de consulta otimizadas que ajudem o Spanner a encontrar planos de execução eficientes.
Ciclo de vida de uma consulta
Uma consulta SQL no Spanner é primeiro compilada num plano de execução e, em seguida, enviada para um servidor raiz inicial para execução. O servidor raiz é escolhido de forma a minimizar o número de saltos para alcançar os dados que estão a ser consultados. O servidor raiz:
- inicia a execução remota de subplanos (se necessário)
- aguarda os resultados das execuções remotas
- processa todos os passos de execução local restantes, como a agregação de resultados
- devolve resultados para a consulta
Os servidores remotos que recebem um subplano atuam como um servidor "raiz" para o respetivo subplano, seguindo o mesmo modelo que o servidor raiz mais elevado. O resultado é uma árvore de execuções remotas. Conceitualmente, a execução da consulta flui de cima para baixo e os resultados da consulta são devolvidos de baixo para cima.O diagrama seguinte mostra este padrão:

Os exemplos seguintes ilustram este padrão mais detalhadamente.
Consultas agregadas
Uma consulta agregada implementa GROUP BY consultas.
Por exemplo, usando esta consulta:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
Estes são os resultados:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
Conceitualmente, este é o plano de execução:
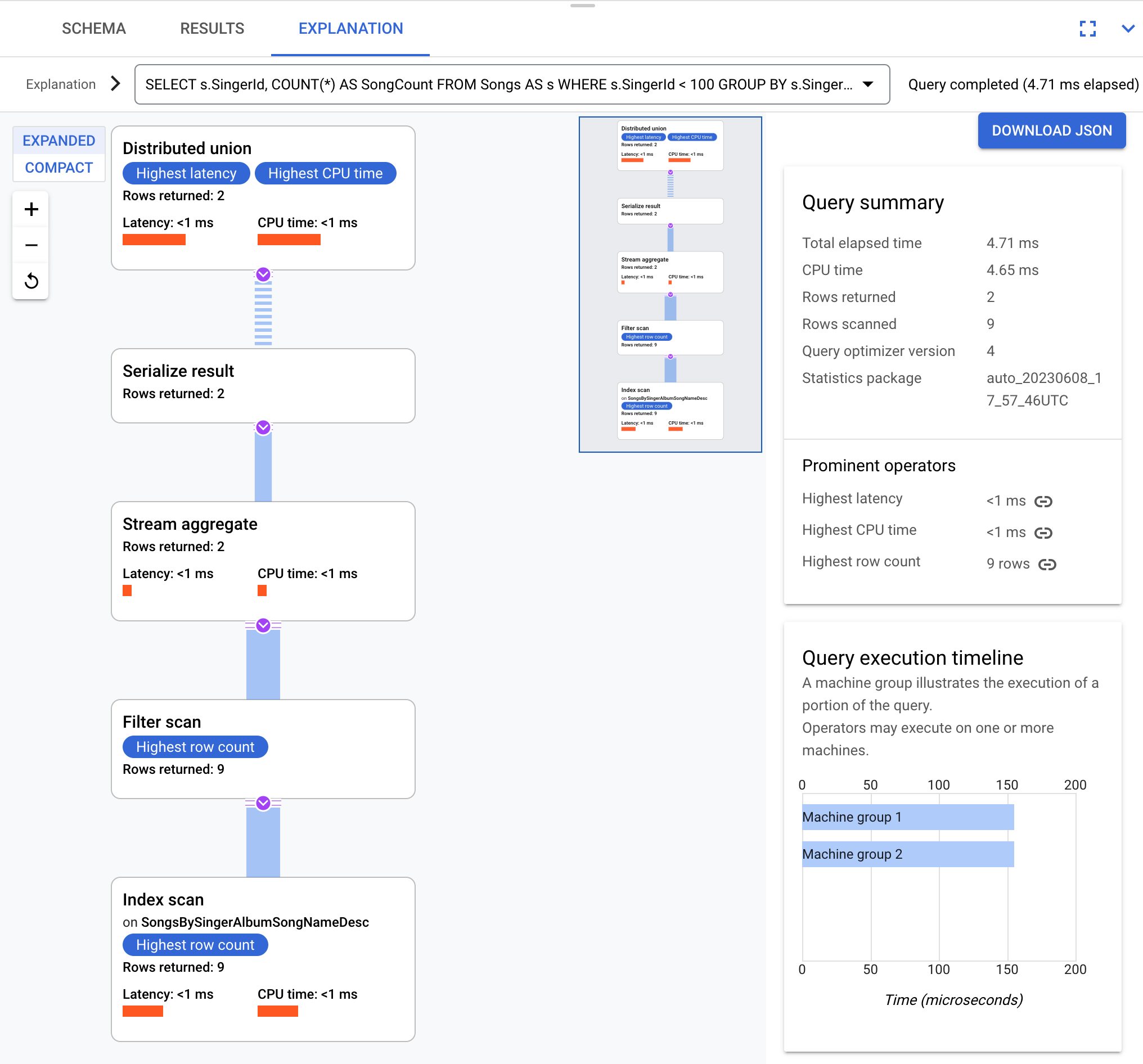
O Spanner envia o plano de execução para um servidor raiz que coordena a execução da consulta e realiza a distribuição remota de subplanos.
Este plano de execução começa com uma união distribuída, que distribui subplanos para servidores remotos cujas divisões satisfazem SingerId < 100. Após a análise
das divisões individuais, o operador stream aggregate agrega linhas
para obter as contagens de cada SingerId. O operador serialize result (serializar resultado) serializa o resultado. Por fim, a união distribuída combina todos os resultados e devolve os resultados da consulta.
Pode saber mais acerca das agregações em operador de agregação.
Consultas de junção localizadas
As tabelas intercaladas são armazenadas fisicamente com as respetivas linhas de tabelas relacionadas localizadas em conjunto. Uma junção de colocação conjunta é uma junção entre tabelas intercaladas. As junções colocadas no mesmo local podem oferecer vantagens de desempenho em relação às junções que requerem índices ou junções inversas.
Por exemplo, usando esta consulta:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(Esta consulta pressupõe que Songs está intercalado em Albums.)
Estes são os resultados:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
Este é o plano de execução:
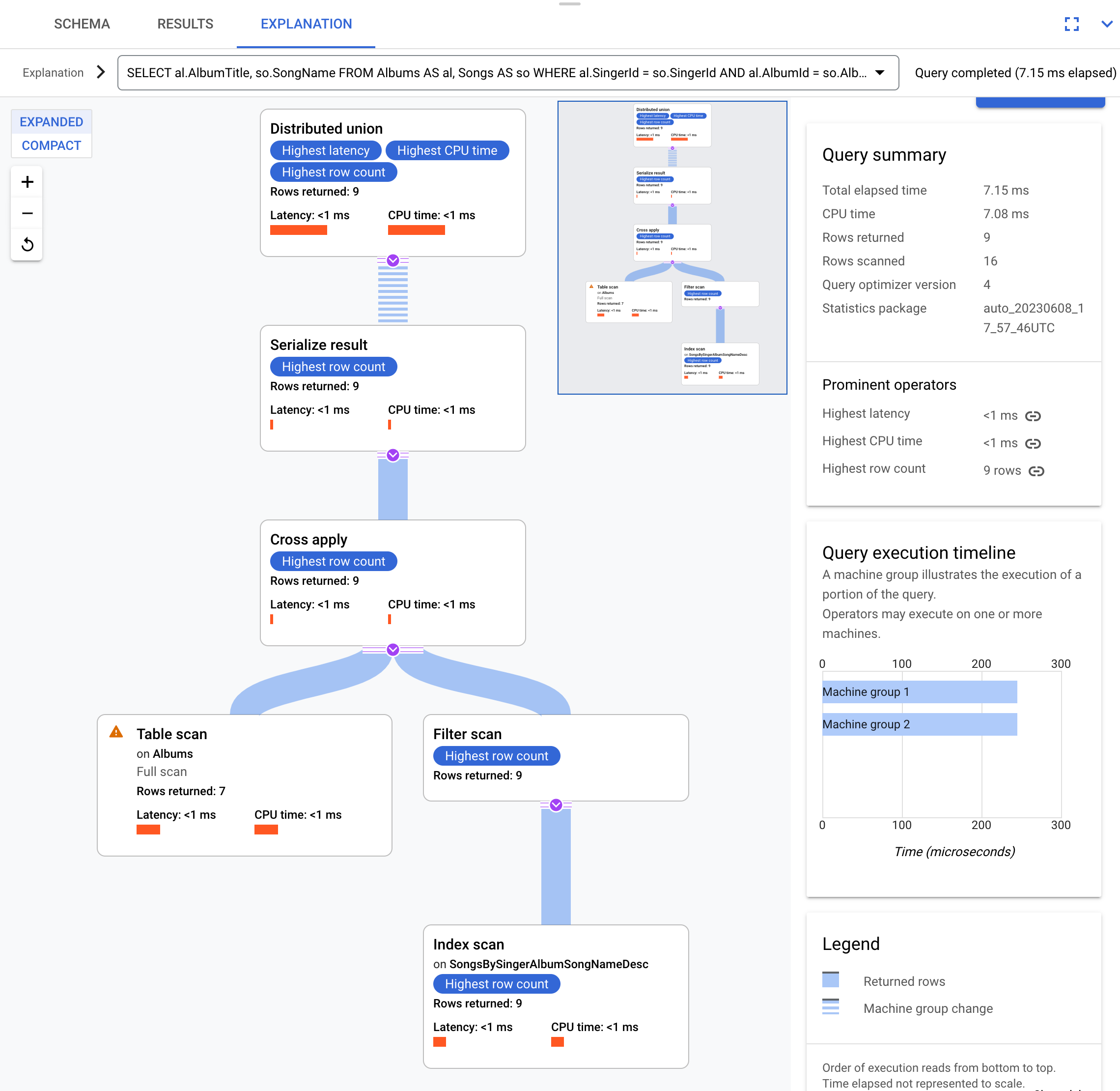
Este plano de execução começa com uma união distribuída, que distribui subplanos para servidores remotos que têm divisões da tabela Albums.
Uma vez que Songs é uma tabela intercalada de Albums, cada servidor remoto pode executar todo o subplano em cada servidor remoto sem precisar de uma junção a um servidor diferente.
Os subplanos contêm uma aplicação cruzada. Cada aplicação cruzada executa uma análise
da tabela na tabela Albums para obter SingerId, AlbumId e
AlbumTitle. A aplicação cruzada mapeia então a saída da leitura da tabela para a saída de uma leitura do índice no índice SongsBySingerAlbumSongNameDesc, sujeita a um filtro do SingerId no índice que corresponde ao SingerId da saída da leitura da tabela. Cada aplicação cruzada envia os respetivos resultados para um operador serialize result que serializa os dados AlbumTitle e SongName e devolve os resultados às uniões distribuídas locais. A união distribuída agrega os resultados das uniões distribuídas locais e devolve-os como resultado da consulta.
Consultas de junção de índice e de retorno
O exemplo acima usou uma junção em duas tabelas, uma intercalada na outra. Os planos de execução são mais complexos e menos eficientes quando duas tabelas ou uma tabela e um índice não estão intercalados.
Considere um índice criado com o seguinte comando:
CREATE INDEX SongsBySongName ON Songs(SongName)
Use este índice nesta consulta:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Estes são os resultados:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
Este é o plano de execução:
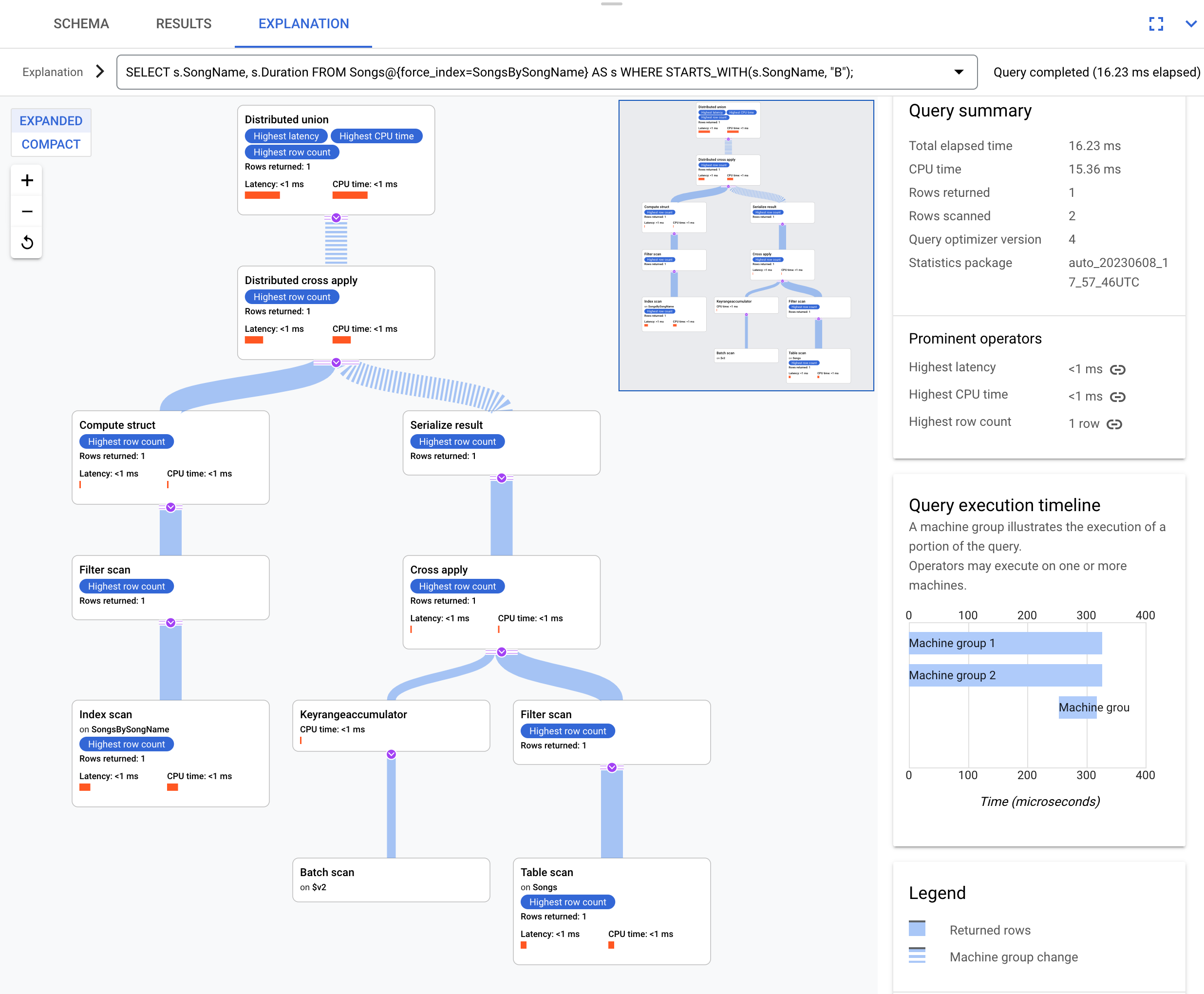
O plano de execução resultante é complicado porque o índice SongsBySongName
não contém a coluna Duration. Para obter o valor Duration, o Spanner tem de juntar novamente os resultados indexados à tabela Songs. Esta é uma junção, mas não está localizada conjuntamente porque a tabela Songs e o índice global SongsBySongName não estão intercalados. O plano de execução resultante é mais complexo do que o exemplo de junção colocada no mesmo local porque o Spanner faz otimizações para acelerar a execução se os dados não estiverem colocados no mesmo local.
O operador superior é uma aplicação cruzada distribuída. Este lado de entrada deste operador são lotes de linhas do índice SongsBySongName que satisfazem o predicado STARTS_WITH(s.SongName, "B"). A aplicação cruzada distribuída mapeia estes lotes para servidores remotos cujas divisões contêm os dados Duration. Os servidores remotos usam uma análise da tabela para obter a coluna Duration.
A análise da tabela usa o filtro Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), que junta TrackId da tabela Songs a TrackId das linhas que foram processadas em lote a partir do índice SongsBySongName.
Os resultados são agregados na resposta final da consulta. Por sua vez, o lado de entrada da aplicação cruzada distribuída contém um par de união distribuída/união distribuída local para avaliar as linhas do índice que satisfazem o predicado STARTS_WITH.
Considere uma consulta ligeiramente diferente que não selecione a coluna s.Duration:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Esta consulta pode tirar total partido do índice, conforme mostrado neste plano de execução:
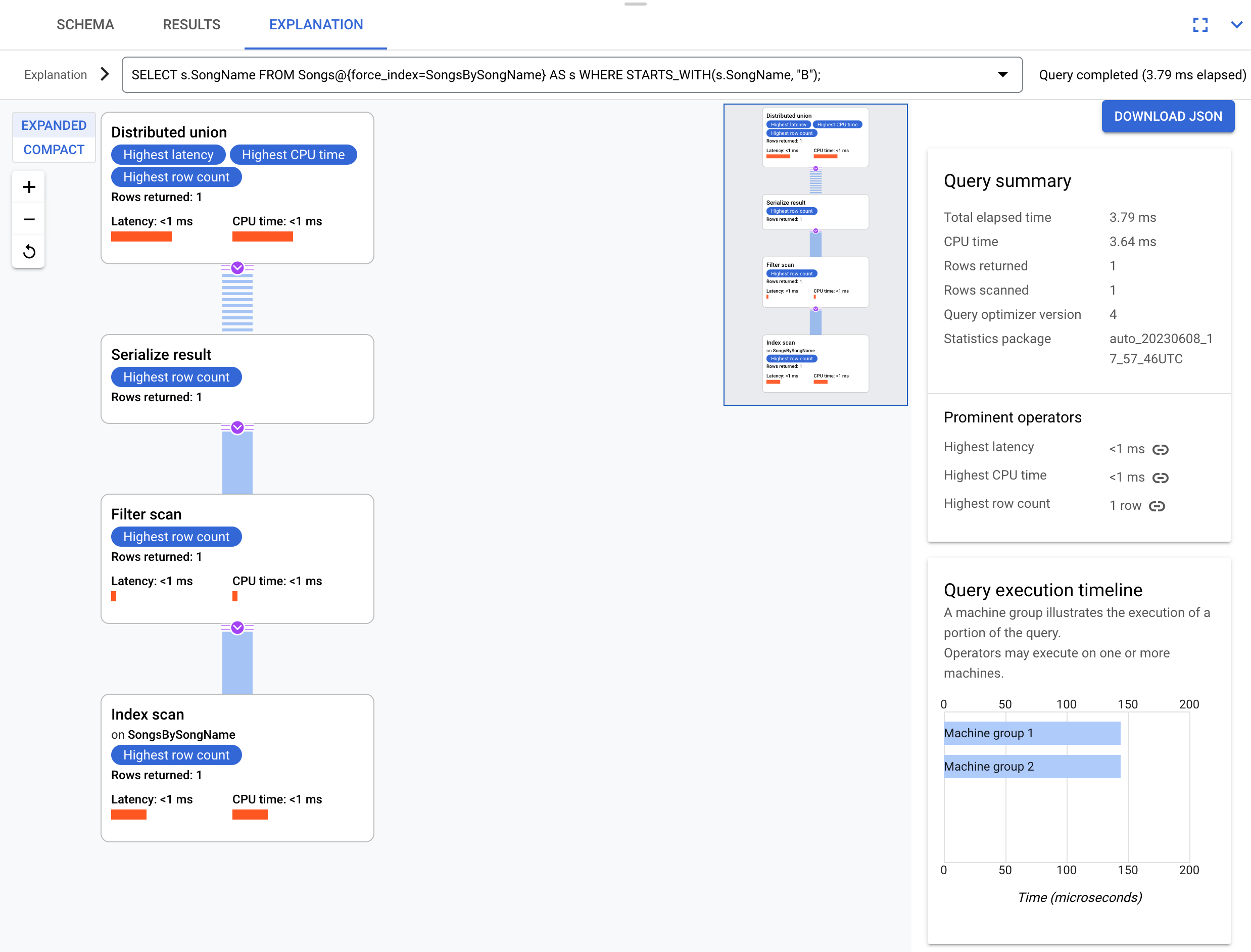
O plano de execução não requer uma junção posterior porque todas as colunas pedidas pela consulta estão presentes no índice.
O que se segue?
Saiba mais sobre os operadores de execução de consultas
Saiba mais sobre o otimizador de consultas do Spanner
Saiba como gerir o otimizador de consultas