Vertex AI Vecter Search を使用すると、ベクトル エンベディングを使用して意味的に類似した項目を検索できます。Spanner To Vertex AI Vector Search Workflow を使用すると、Spanner データベースをベクトル検索と統合して、Spanner データのベクトル類似性検索を実行できます。
次の図は、ベクトル検索を有効にして Spanner データで使用する方法のエンドツーエンドのアプリケーション ワークフローを示しています。
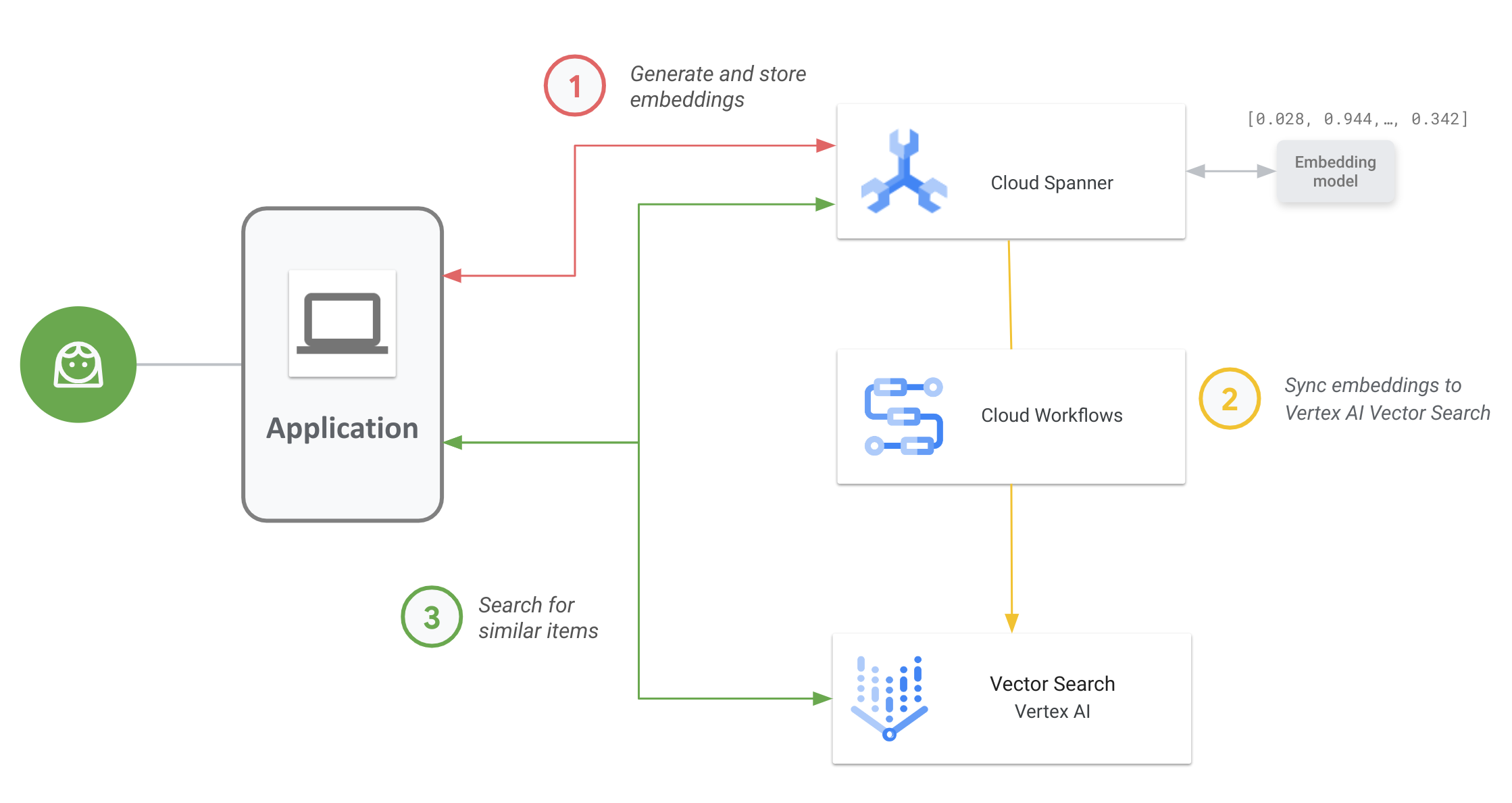
一般的なワークフローは次のとおりです。
ベクトル エンベディングを生成して保存する。
データのベクトル エンベディングを生成し、運用データとともに Spanner に保存して管理できます。Spanner の
ML.PREDICTSQL 関数を使用してエンベディングを生成し、Vertex AI テキスト エンベディング モデルにアクセスすることや、Vertex AI にデプロイされた他のエンベディング モデルを使用することが可能です。エンベディングをベクトル検索と同期する。
Spanner To Vertex AI ベクトル検索ワークフローを使用します。これは、ワークフローを使用してデプロイされ、エンベディングをエクスポートしてベクトル検索インデックスにアップロードします。Cloud Scheduler を使用してこのワークフローを定期的にスケジュールすると、Spanner のエンベディングに対する最新の変更を反映してベクトル検索インデックスを最新の状態に維持できます。
ベクトル検索インデックスを使用してベクトル類似度検索を実行する。
ベクトル検索インデックスをクエリして、意味的に類似している項目を検索し見つけます。パブリック エンドポイントを使用するか VPC ピアリングを介してクエリを実行できます。
ユースケースの例
ベクトル検索のユースケースの一例は、何十万もの在庫を持つオンライン小売店です。このシナリオでは、オンライン小売店のデベロッパーが、Spanner の商品カタログでベクトル類似度検索を使用して、お客様が検索クエリに基づいて関連商品を見つけることを支援します。
一般的なワークフローに示されているステップ 1 とステップ 2 に沿って、商品カタログのベクトル エンベディングを生成し、これらのエンベディングをベクトル検索と同期します。
お客様がアプリケーションを閲覧し、「水中で着用できる最も優れた速乾のスポーツパンツ」のような検索をしているとします。アプリケーションがこのクエリを受け取った際には、Spanner の ML.PREDICT SQL 関数を使用して、この検索リクエストのリクエスト エンベディングを生成する必要があります。エンベディング モデルは、商品カタログのエンベディングの生成に使用したものと同じものを使用してください。
次に、ベクトル検索インデックスをクエリし、対応するエンベディングがお客様の検索リクエストから生成されたリクエスト エンベディングと類似しているプロダクト ID を取得します。検索インデックスでは、ウェイクボード ショートパンツ、サーフィン用アパレル、スイミング パンツなど、意味が似ている項目に対して商品 ID が提案されることがあります。
ベクトル検索からこれらの類似した商品 ID が返されたら、Spanner に商品の説明、在庫数、価格、その他の関連するメタデータをクエリして、お客様に表示できます。
生成 AI を使用して、Spanner から返される結果を処理した後、お客様に表示することもできます。たとえば、Google の大規模生成 AI モデルを使用して、おすすめ商品の簡潔な要約を生成できます。詳細については、生成 AI を使用して e コマース アプリケーションでパーソナライズされたレコメンデーションを取得する方法に関するチュートリアルをご覧ください。
次のステップ
- Spanner を使用してエンベディングを生成する方法を確認する。
- AI のマルチツールのご紹介: ベクトル エンベディングについて詳細を確認する。
- エンベディングに関する集中講座で ML とエンベディングの詳細を確認する。
- Spanner To Vertex AI ベクトル検索ワークフローの詳細については、GitHub リポジトリをご覧ください。
- Python での一般的なデータ分析オペレーションを容易にし、Jupyter Notebooks との統合を含むオープンソースの spanner-analytics パッケージについて確認する。