本页面介绍了如何使用 Query Insights 信息中心检测和分析 Spanner 性能问题。
Query Insights 概览
借助查询洞见,您可以检测和诊断 Spanner 数据库的查询和 DML(INSERT、UPDATE 和 DELETE)语句性能问题。它支持直观监控并提供诊断信息,帮助您在检测范围之外确定性能问题的根本原因。
Query Insights 可以指导您完成以下步骤,帮助您提高 Spanner 查询性能:
Query Insights 适用于单区域和多区域配置。
价格
Query Insights 不会产生额外费用。
数据保留
Query Insights 最多将数据保留 30 天。对于总 CPU 利用率(按每个查询或请求标记)图表,Spanner 会从 SPANNER_SYS.QUERY_STATS_TOP_* 表中检索数据。这些表最多保留 30 天。如需了解详情,请参阅数据保留。
所需的角色
您需要不同的 IAM 角色和权限,具体取决于您是 IAM 用户还是精细访问权限控制用户。
Identity and Access Management (IAM) 用户
如需获得查看 Query Insights 页面所需的权限,请让您的管理员为您授予实例的以下 IAM 角色:
-
Cloud Spanner Viewer (
roles/spanner.viewer) -
Cloud Spanner Database Reader (
roles/spanner.databaseReader)
查看 Query Insights 页面需要 Cloud Spanner Database Reader (
roles/spanner.databaseReader) 角色提供的以下权限:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
精细访问权限控制用户
如果您是精细访问权限控制用户,请确认您:
- 具有 Cloud Spanner Viewer(
roles/spanner.viewer) - 拥有精细访问权限控制权限,并且已被授予
spanner_sys_reader系统角色或其成员角色之一。 - 在数据库概览页面上,选择
spanner_sys_reader或成员角色作为当前的系统角色。
如需了解详情,请参阅精细访问权限控制简介和精细访问权限控制系统角色。
Query Insights 信息中心
Query Insights 信息中心会基于您选择的数据库和时间范围显示查询负载。查询负载用于衡量选定时间范围内实例中所有查询的总 CPU 利用率。该信息中心提供了一系列过滤条件,可帮助您查看查询负载。
如需查看数据库的 Query Insights 信息中心,请执行以下操作:
- 在左侧导航面板中选择 Query Insights。Query Insights 信息中心会打开。
- 从数据库列表中选择一个数据库。信息中心会显示数据库的查询负载信息。
信息中心包含以下部分:
- 数据库列表:过滤特定数据库或所有数据库上的查询负载。
- 时间范围过滤条件:按时间范围(如小时、天或自定义范围)过滤查询负载。
- 总 CPU 利用率(所有查询)图表:显示所有查询的汇总负载。
- 总 CPU 利用率(按每个查询或请求标记)图表:按每个查询或请求标记显示 CPU 利用率。
- 排名前 N 的查询和标记表:显示按 CPU 利用率排序的热门查询和请求标记列表。请参阅确定可能存在问题的查询或标记。
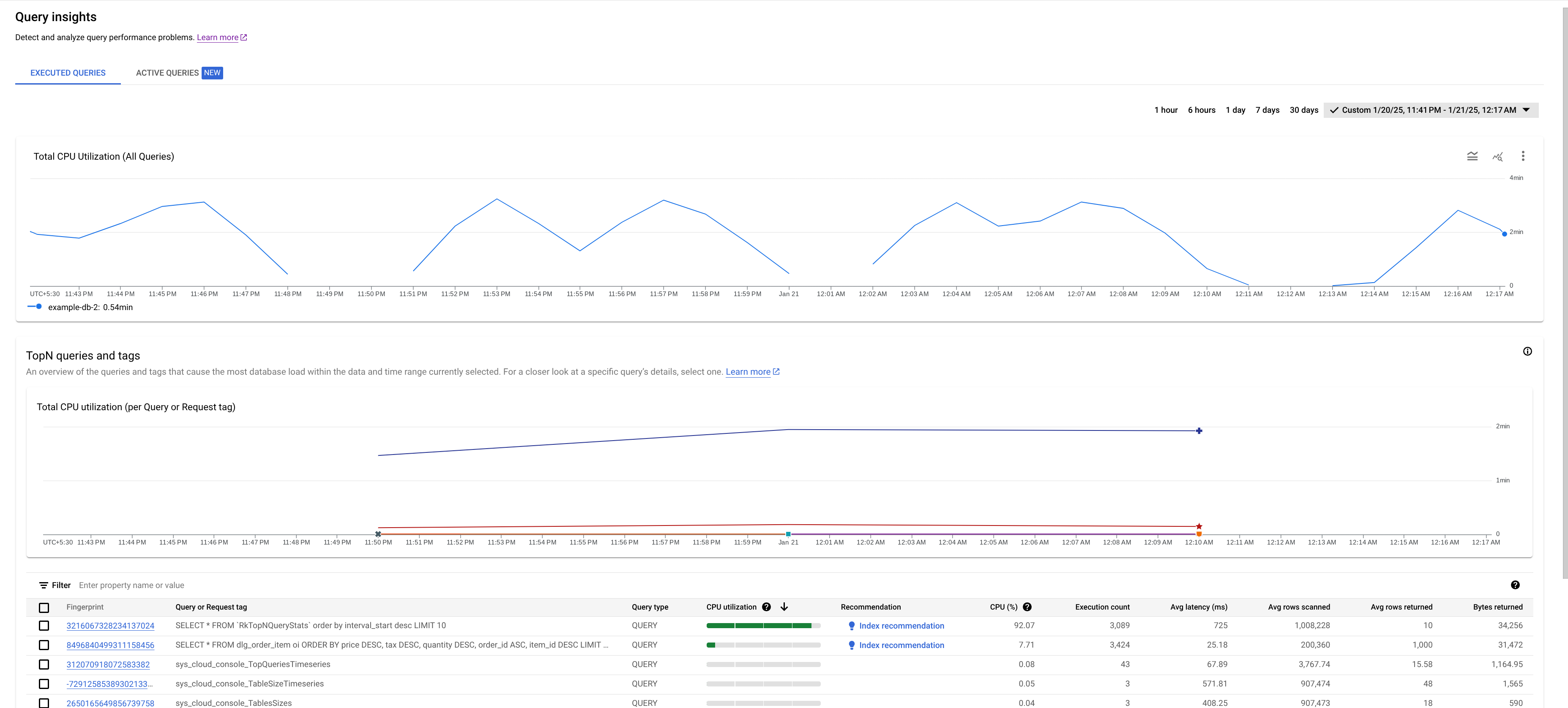
信息中心性能
使用查询参数或标记查询,以优化 Query Insights 的性能。如果您未对查询进行参数化或标记,则可能会返回过多的结果,从而可能导致 TopN 查询和标记表无法正确加载。
确认低效查询是否导致高 CPU 利用率
总 CPU 利用率用于衡量所选数据库中已执行的查询在一段时间内所执行的工作(以 CPU 秒为单位)。

查看图表来探索以下问题:
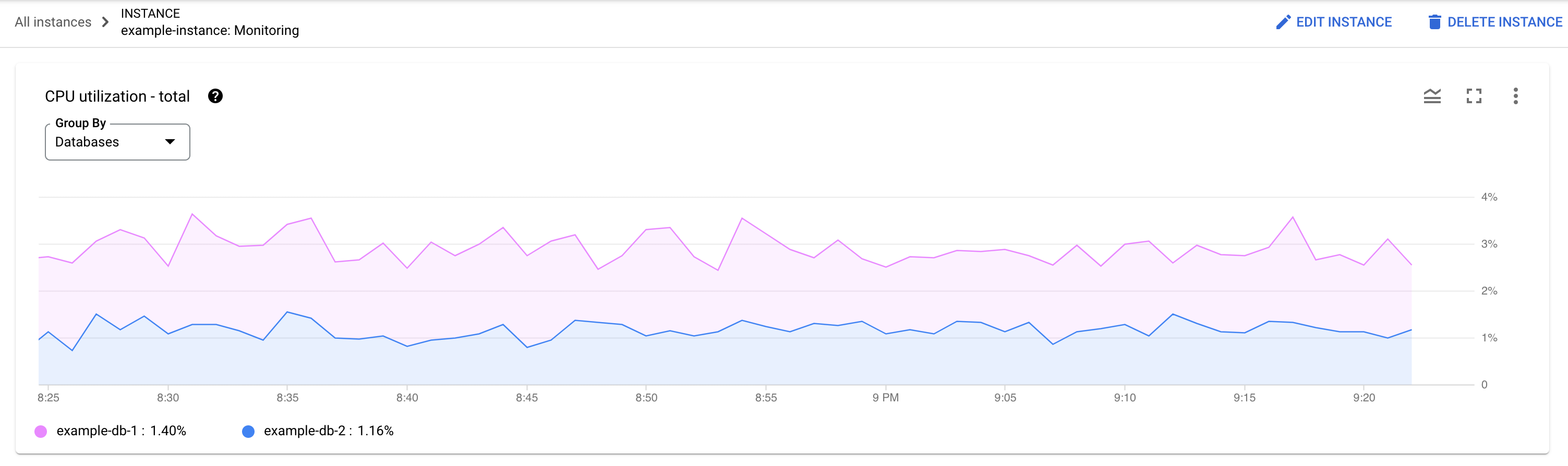
哪个数据库遇到了负载?从“数据库”列表中选择不同的数据库,找出负载最高的数据库。如需了解哪个数据库的负载最高,您还可以查看Google Cloud 控制台中数据库的 CPU 利用率 - 总计图表。
CPU 利用率是否较高?图表是否随着时间推移或上升?如果未看到 CPU 利用率较高,则问题与您的查询无关。
CPU 利用率较高的情况持续了多长时间?是最近出现峰值,还是在一段时间内一直很高?使用范围选择器选择不同的时间段,以了解问题持续了多长时间。放大可查看观察到查询负载高峰的时间范围。缩小可查看长达一周的时间轴。
如果您在与总体实例 CPU 使用率对应的图表中看到高峰或升高,则很可能是因为一个或多个费用高的查询。接下来,您可以确定可能存在问题的查询或请求标记,从而更深入了解调试过程。
确定可能存在问题的查询或请求标记
如需确定可能存在问题的查询或请求标记,请查看“排名前 N 的查询”部分:
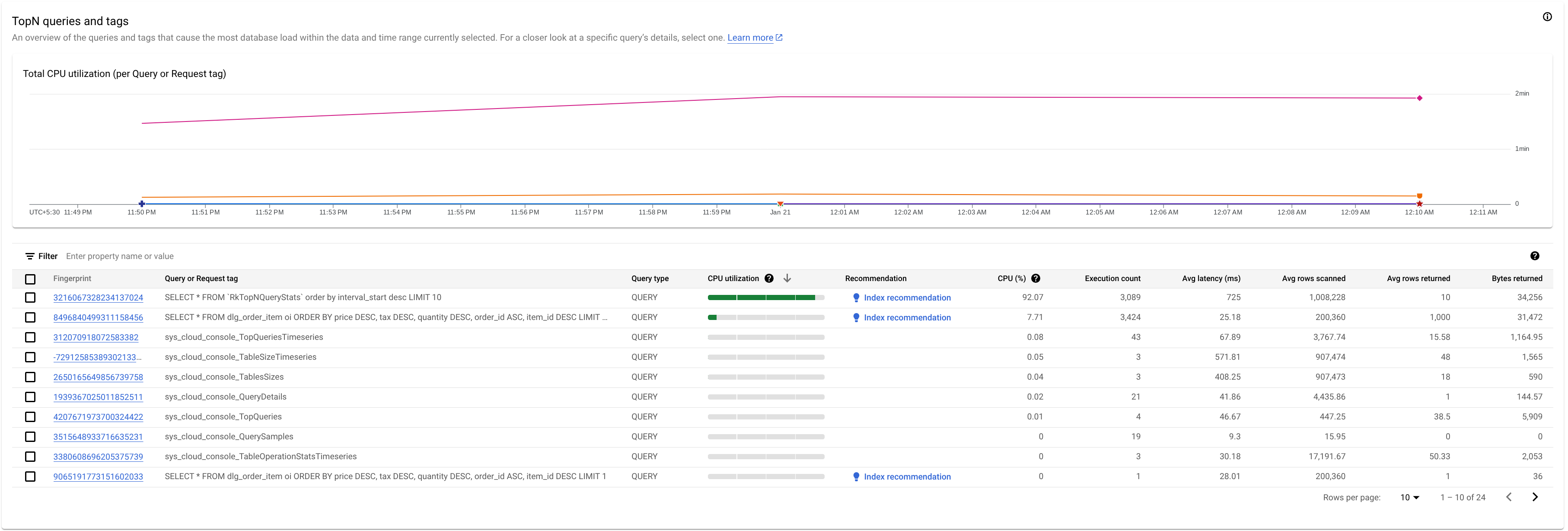
在此示例中,我们看到指纹为 3216067328234137024 的查询的 CPU 利用率很高,可能会有问题。
排名前 N 的查询表概述了所选时间范围内 CPU 使用率最高的查询,并按从高到低的顺序排序。排名前 N 的查询数量上限为 100。
对于图表,我们会从排名前 N 的查询统计信息表中提取数据,该表具有三种不同的粒度:1 分钟、10 分钟和 1 小时。图表中每个数据点的值表示一分钟时间间隔内的平均值。
我们建议您向 SQL 查询添加标记。查询标记可帮助您找到更高级别的结构(例如使用业务逻辑或微服务)中的问题。

下表显示了以下属性:
- 指纹:请求标记的哈希值;如果不存在标记,则为查询文本的哈希值。
查询或请求标记:如果查询具有关联的标记,则会显示请求标记。具有相同标记字符串的多个查询的统计信息归为一行,其中
REQUEST_TAG值与该标记字符串匹配。如需详细了解如何使用请求标记,请参阅使用请求标记和事务标记进行问题排查。如果查询没有关联的标记,则会显示截断至大约 64KB 的 SQL 查询。对于批处理 DML,SQL 语句会展平为一行,并使用英文分号分隔符串联。连续相同的 SQL 文本会在截断之前删除重复。
查询类型:指明查询是
PARTITIONED_QUERY还是QUERY。PARTITIONED_QUERY是包含从 PartitionQuery API 获取的partitionToken的查询。所有其他查询和 DML 语句都由QUERY查询类型表示。CPU 利用率:查询消耗的 CPU 资源,以百分比表示,占相应时间间隔内数据库上运行的所有查询所使用的总 CPU 资源的百分比,显示在范围为 0 到 100 的水平条上。
建议:Spanner 会分析您的查询,以确定它们是否可以从改进的索引中受益。如果是这样,Spanner 会建议可提高查询性能的新索引或更改后的索引。如需了解详情,请参阅使用 Spanner 索引顾问。
CPU (%):查询消耗的 CPU 资源,以百分比表示,该百分比是指查询消耗的 CPU 资源占相应时间间隔内数据库中运行的所有查询所消耗的总 CPU 资源的百分比。
执行次数:Spanner 在时间间隔内看到查询的次数。
平均延迟时间(毫秒):数据库中每次查询执行的平均时间长度(以微秒为单位)。该平均值不包括结果集编码和传输时间以及开销。
平均扫描行数:查询扫描的平均行数,不包括已删除的值。
平均返回行数:查询返回的平均行数。
返回的字节数:查询返回的数据字节数,不包括传输编码开销。
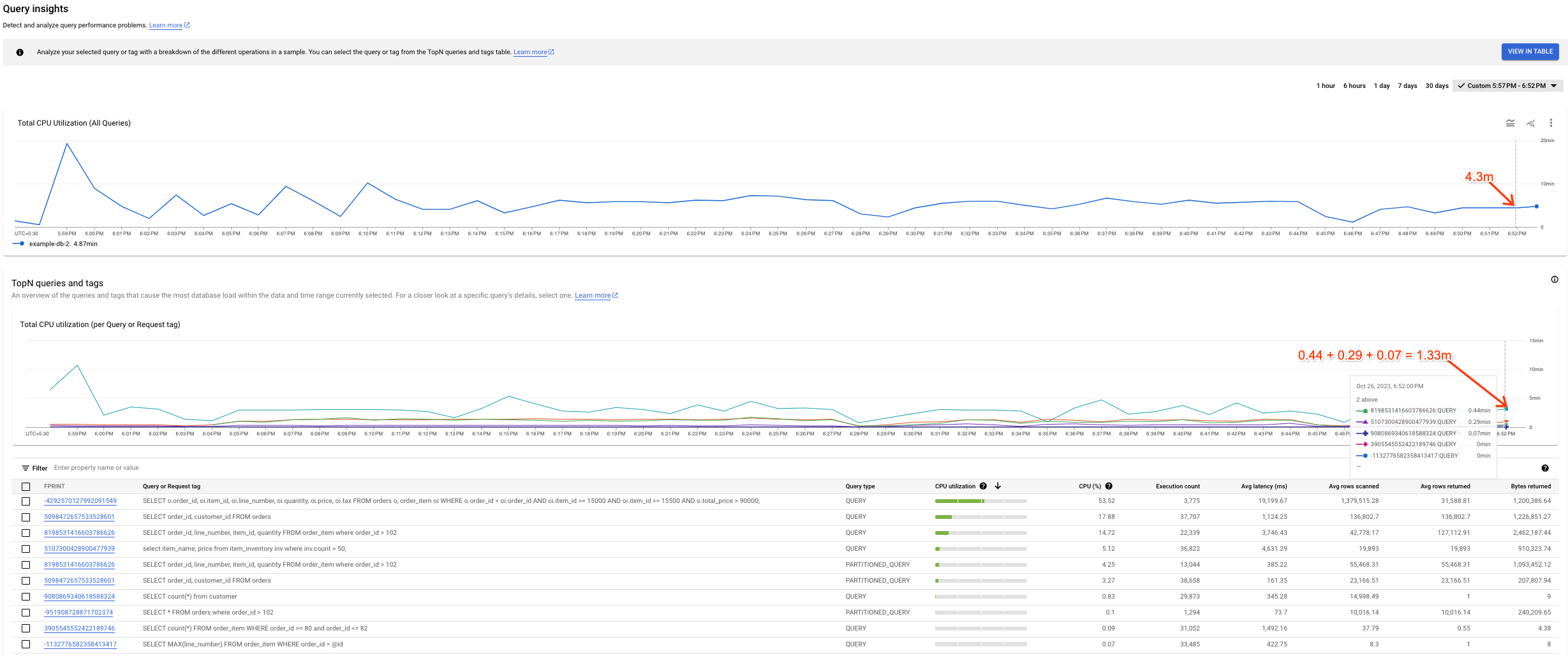
图表之间可能存在的差异
您可能会注意到,总 CPU 利用率(所有查询)图表与总 CPU 利用率(按每个查询或请求标记)图表之间存在一些差异。以下两种情况可能会导致此情形:
不同的数据来源:为总 CPU 利用率(所有查询)图表提供数据的 Cloud Monitoring 数据通常更准确,因为这些数据每分钟推送一次,保留期限为 45 天。另一方面,为总 CPU 利用率(按每个查询或请求标记)图表提供数据的系统表数据可能会在 10 分钟(或 1 小时)内进行平均处理,在这种情况下,我们可能会丢失总 CPU 利用率(所有查询)图表中显示的高粒度数据。
不同的汇总窗口:两个图表的汇总窗口不同。例如,在检查 6 小时前的事件时,我们会查询
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE表。在这种情况下,10:01 发生的事件将在 10 分钟内汇总,并显示在与 10:10 时间戳对应的系统表中。
以下屏幕截图显示了此类差异的一个示例。
分析特定查询或请求标记
如需确定查询或请求标记是否为问题的根本原因,请点击看似负载最高或比其他查询或请求标记用时更长的查询或请求标记。您可以一次选择多个查询和请求标记。
您可以将鼠标指针悬停在时间轴中查询的图表上,以了解其 CPU 利用率(以秒为单位)。
通过查看以下内容来缩小问题范围:
- 负载高的时间有多长?只是现在高吗?还是长时间位于高负载?更改时间范围以查找查询开始效果不佳的日期和时间。
- CPU 利用率是否出现过高峰?您可以更改时间范围来研究查询的历史 CPU 利用率。
- 什么是资源消耗量?它与其他查询有何关系?查看表,将其他查询的数据与所选查询的数据进行比较。两者之间有很大区别吗?
如需确认所选查询是否导致 CPU 利用率较高,您可以深入了解特定查询形状(或请求标记)的详细信息,并在查询详情页面上进一步分析。
查看“查询详情”页面
如需以图形形式查看特定查询形状或请求标记的详细信息,请点击与该查询或请求标记关联的指纹。系统会打开“查询详情”页面。
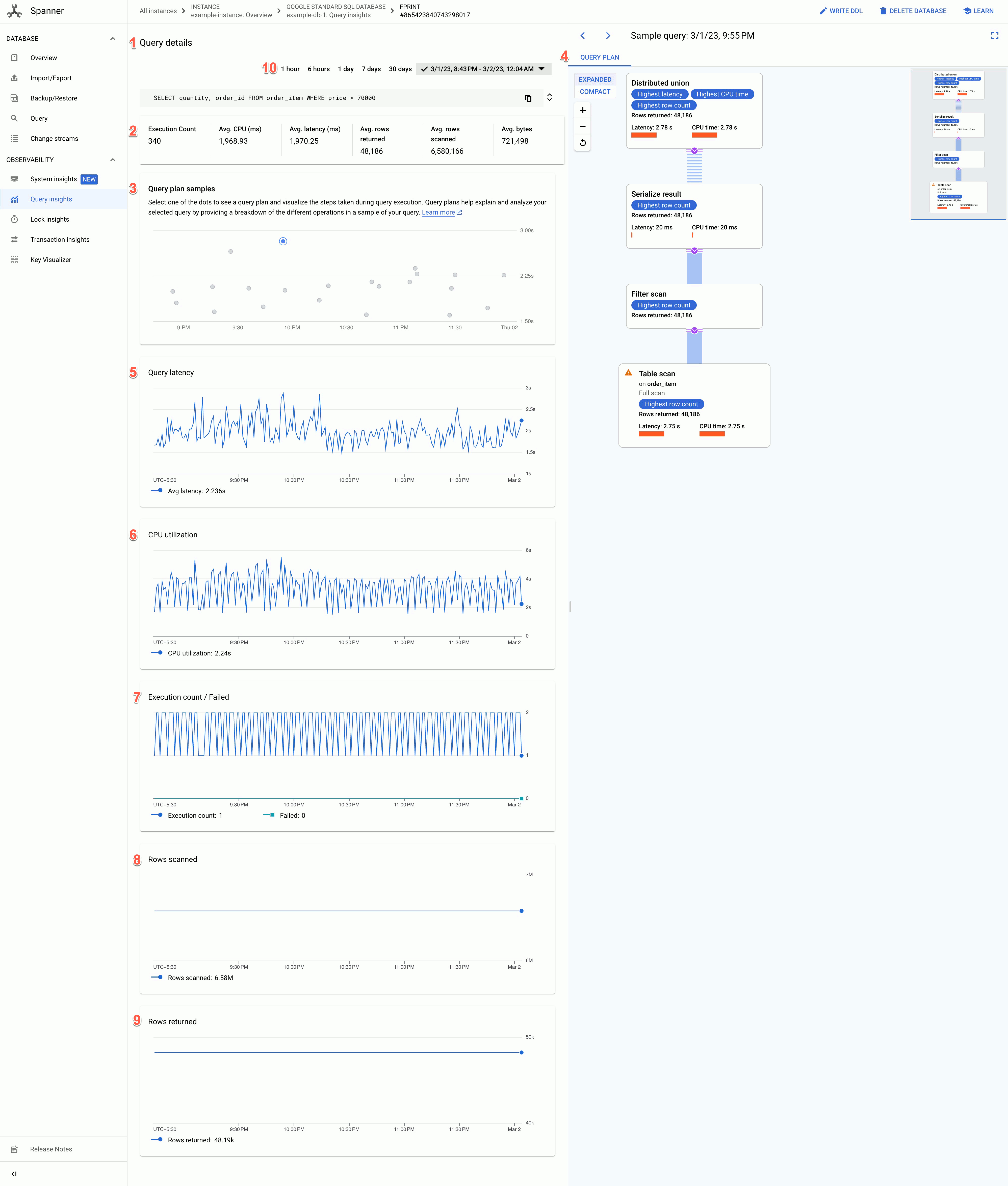
“查询详情”页面会显示以下信息:
- 查询详情文本:SQL 查询文本,被截断至大约 64KB。具有相同标记字符串的多个查询的统计信息归为一行,其中 REQUEST_TAG 与该标记字符串匹配。此字段中仅显示这些查询之一的文本。对于批处理 DML,这组 SQL 语句会展平为一行,并使用英文分号分隔符串联。连续相同的 SQL 文本会在截断之前删除重复。
- 以下字段的值:
- 执行次数:Spanner 在时间间隔内看到查询的次数。
- 平均 CPU 使用时长(毫秒):在某个时间间隔内,实例的 CPU 资源被查询所消耗的平均 CPU 资源量(以毫秒为单位)。
- 平均延迟时间(毫秒):数据库中每次查询执行的平均时间长度(以毫秒为单位)。该平均值不包括结果集编码和传输时间以及开销。
- 返回的平均行数:查询返回的平均行数。
- 扫描的平均行数:查询扫描的平均行数,不包括已删除的值。
- 平均字节数:查询返回的数据字节数,不包括传输编码开销。
- 查询计划样本图表:图表上的每个点都代表特定时间的抽样查询计划及其特定查询延迟时间。点击图表中的一个点,即可查看查询计划并直观呈现查询执行期间执行的步骤。注意:对于具有从 PartitionQuery API 获取的 partitionToken 的查询和分区 DML 查询,不支持查询计划。
查询计划可视化工具:显示所选的采样查询计划。 Spanner 提供以下布局选项:
- 树状视图:树状视图以图表的形式直观呈现查询计划,其中每个节点或卡片都表示一个迭代器,该迭代器会使用其输入中的行,并将行生成到其父级。您可以点击每个迭代器,查看展开的信息。
顺序视图:顺序视图以分层表格的形式直观呈现查询计划,其中每行都表示一个运算符。您可以点击每一行来展开信息。

该表格显示以下列:
- 名称:运算符的名称。
- 机器组:相应运算符执行所在的机器组。
- 延迟时间:执行当前操作所经过的时间。此时间总和可能会超过 CPU 时间(例如,在该运算符等待远程调用或文件系统延迟的情况下)。
- 累计延迟时间:执行以该运算符为根的整个子树所用的时间。这不包括计划创建时间和开销,因此累积延迟时间可能比查询的总时长短。
- CPU 时间:执行查询所花费的总 CPU 时间。 不包括网络延迟时间。查询执行作业的某些部分可以并行进行,因此 CPU 时间可能大于总耗时。例如,如果查询在 1 毫秒 (ms) 内执行 10 个并行操作,则耗时为 1 毫秒,但 CPU 时间为 10 毫秒。
- 返回的行数:运算符返回的行数。
查询延迟时间图表:显示所选查询在一段时间内的查询延迟时间值。它还会显示平均延迟时间。
CPU 利用率图表:显示查询在一段时间内的 CPU 利用率(以百分比表示)。它还会显示平均 CPU 利用率。
执行次数/失败次数图表:显示查询在一段时间内的执行次数以及查询执行失败的次数。
扫描的行数图表:显示查询在一段时间内扫描的行数。
“返回的行数”图表:显示查询在一段时间内返回的行数。
时间范围过滤条件:按时间范围(如小时、天或自定义范围)过滤查询详情。
对于图表,我们会从排名前 N 的查询统计信息表中提取数据,该表具有三种不同的粒度:1 分钟、10 分钟和 1 小时。图表中每个数据点的值表示一分钟时间间隔内的平均值。
在审核日志中搜索查询的所有执行
如需在 Cloud Audit Logs 中搜索特定查询指纹的所有执行,请查询审核日志,并搜索与排名前 N 的查询统计信息表中的 Fingerprint 字段匹配的任何 query_fingerprint。如需了解详情,请参阅查询和查看日志概览。使用此方法可识别发起查询的用户。