En esta página se describe cómo usar el panel de control Estadísticas de las consultas para detectar y analizar problemas de rendimiento de Spanner.
Información general sobre Query Insights
Información valiosa sobre las consultas te ayuda a detectar y diagnosticar problemas de rendimiento de las consultas y las declaraciones de DML (INSERT, UPDATE y DELETE) en una base de datos de Spanner. Cuenta con funciones de monitorización intuitivas y proporciona información de diagnóstico que puede ayudarte a identificar la causa principal del problema de rendimiento.
Estadísticas de consultas te ayuda a mejorar el rendimiento de las consultas de Spanner guiándote por los siguientes pasos:
- Determina si las consultas ineficientes están provocando un uso elevado de la CPU.
- Identifica una consulta o una etiqueta que pueda dar problemas.
- Analiza la etiqueta de consulta o solicitud para identificar problemas.
Estadísticas de las consultas está disponible en configuraciones de una o varias regiones.
Precios
Query Insights no tiene ningún coste adicional.
Conservación de datos
Estadísticas de las consultas conserva los datos durante un máximo de 30 días.
En el gráfico Uso total de la CPU (por consulta o etiqueta de solicitud), Spanner obtiene los datos de las tablas SPANNER_SYS.QUERY_STATS_TOP_*. Estas tablas tienen un periodo de conservación máximo de 30 días. Para obtener más información, consulta Conservación de datos.
Roles obligatorios
Necesitas diferentes roles y permisos de gestión de identidades y accesos en función de si eres un usuario de gestión de identidades y accesos o un usuario de control de acceso pormenorizado.
Usuario de Gestión de Identidades y Accesos (IAM)
Para obtener los permisos que necesitas para ver la página Estadísticas de consultas, pide a tu administrador que te conceda los siguientes roles de IAM en la instancia:
-
Lector de Cloud Spanner (
roles/spanner.viewer) -
Lector de las bases de datos de Cloud Spanner (
roles/spanner.databaseReader)
Para ver la página Estadísticas de consultas, se necesitan los siguientes permisos del rol Lector de bases de datos de Cloud Spanner(
roles/spanner.databaseReader):
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Usuario de control de acceso pormenorizado
Si usas el control de acceso pormenorizado, comprueba que:
- Tener el rol Lector de Cloud Spanner(
roles/spanner.viewer) - Tener privilegios de control de acceso pormenorizado y tener asignado el
spanner_sys_readerrol de sistema o uno de sus roles miembros. - Selecciona
spanner_sys_readero un rol de miembro como rol del sistema actual en la página de resumen de la base de datos.
Para obtener más información, consulta Acerca del control de acceso pormenorizado y Roles del sistema de control de acceso pormenorizado.
Panel de control Estadísticas de las consultas
El panel de control Estadísticas de las consultas muestra la carga de las consultas en función de la base de datos y el periodo que selecciones. La carga de consultas es una medida del uso total de CPU de todas las consultas de la instancia en el intervalo de tiempo seleccionado. El panel de control ofrece una serie de filtros que te ayudan a ver la carga de las consultas.
Para ver el panel de control Estadísticas de consultas de una base de datos, sigue estos pasos:
- En el panel de navegación de la izquierda, seleccione Estadísticas de consultas. Se abre el panel de control Estadísticas de las consultas.
- Seleccione una base de datos de la lista Bases de datos. El panel de control muestra la información de carga de consultas de la base de datos.
Las áreas del panel de control son las siguientes:
- Lista de bases de datos: filtra la carga de consultas en una base de datos específica o en todas las bases de datos.
- Filtro de periodo: filtra la carga de la consulta por periodos, como horas, días o un periodo personalizado.
- Gráfico Uso total de CPU (todas las consultas): muestra la carga agregada de todas las consultas.
- Gráfico "Uso total de la CPU (por etiqueta de consulta o solicitud)": muestra el uso de la CPU por cada etiqueta de consulta o solicitud.
- Tabla de consultas y etiquetas principales: muestra la lista de las consultas y etiquetas de solicitud principales ordenadas por uso de CPU. Consulta Identificar una consulta o una etiqueta que pueda dar problemas.
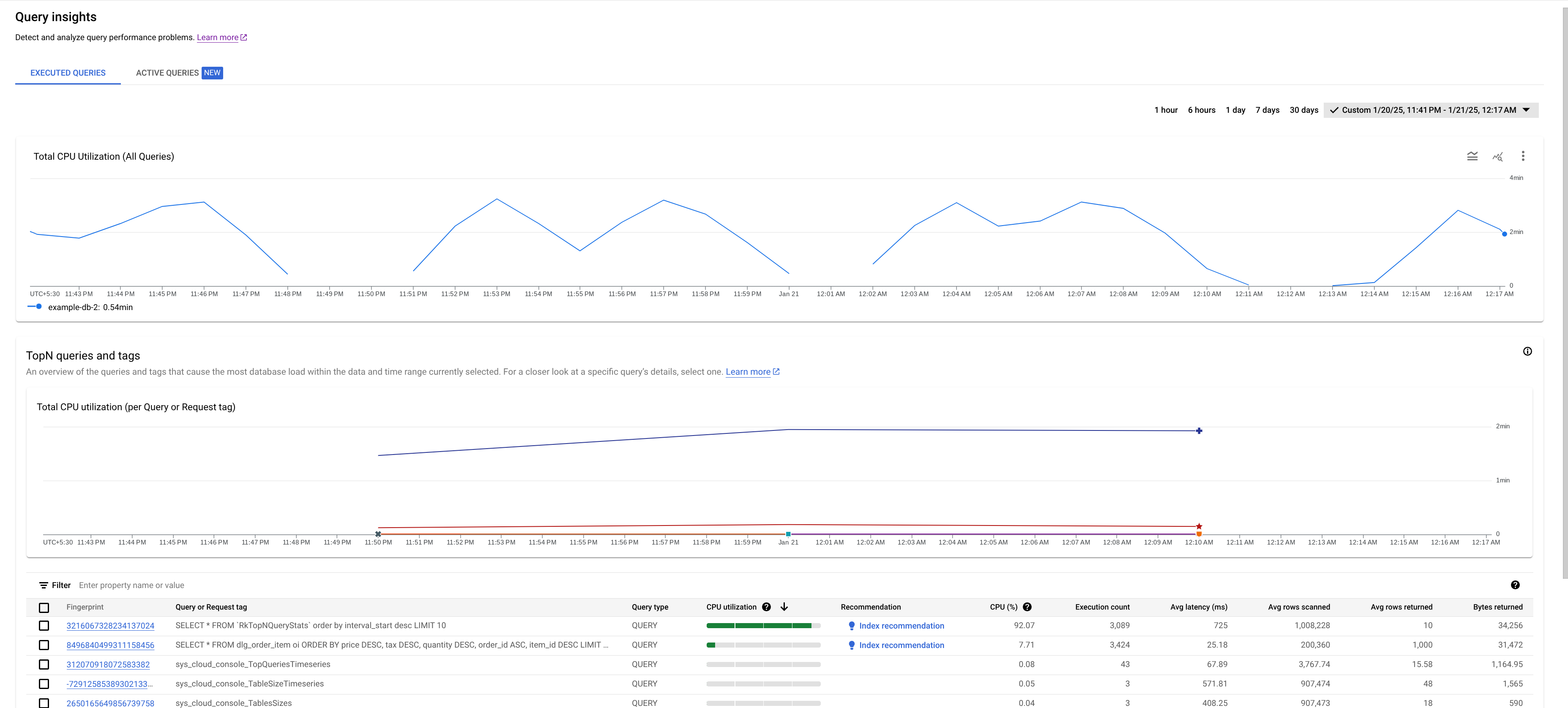
Rendimiento del panel de control
Usa parámetros de consulta o etiqueta tus consultas para optimizar el rendimiento de Query Insights. Si no parametrizas ni etiquetas tus consultas, es posible que se devuelvan demasiados resultados, lo que podría provocar que la tabla de consultas y etiquetas TopN no se cargue correctamente.
Confirmar si las consultas ineficientes son las responsables del uso elevado de la CPU
El uso total de CPU es una medida del trabajo (en segundos de CPU) que realizan las consultas ejecutadas en la base de datos seleccionada a lo largo del tiempo.

Consulta el gráfico para responder a estas preguntas:
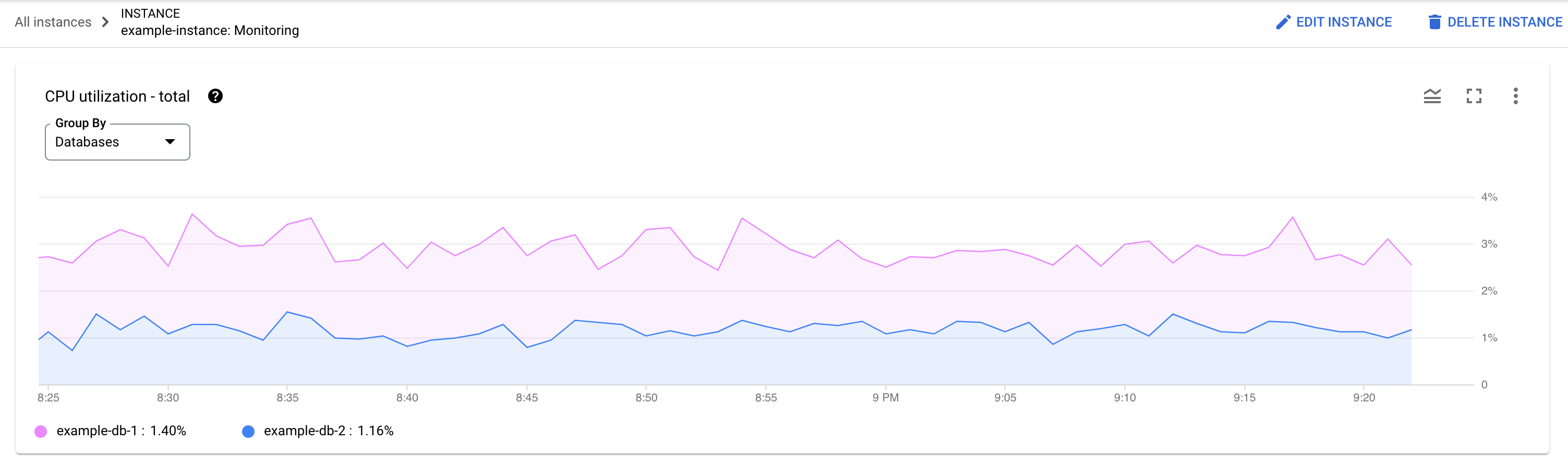
¿Qué base de datos está experimentando la carga? Seleccione diferentes bases de datos de la lista Bases de datos para encontrar las bases de datos con las cargas más altas. Para saber qué base de datos tiene la carga más alta, también puedes consultar el gráfico Uso de la CPU (total) de las bases de datos en la Google Cloud consola.
¿El uso de la CPU es elevado? ¿El gráfico muestra picos o valores elevados a lo largo del tiempo? Si no ves una utilización elevada de la CPU, el problema no está en tus consultas.
¿Cuánto tiempo lleva el uso de CPU elevado? ¿Ha aumentado recientemente o ha sido alto de forma constante durante un tiempo? Usa el selector de intervalo para seleccionar varios periodos y averiguar cuánto tiempo ha durado el problema. Amplía para ver el periodo en el que se observan los picos de carga de la consulta. Reduce la vista para ver hasta una semana de la cronología.
Si ve un pico o un aumento en el gráfico correspondiente al uso general de la CPU de la instancia, lo más probable es que se deba a una o varias consultas costosas. A continuación, puedes profundizar en el proceso de depuración identificando una consulta o una etiqueta de solicitud que pueda dar problemas.
Identificar una consulta o una etiqueta de solicitud que pueda dar problemas
Para identificar una consulta o una etiqueta de solicitud que pueda dar problemas, consulta la sección TopN queries:
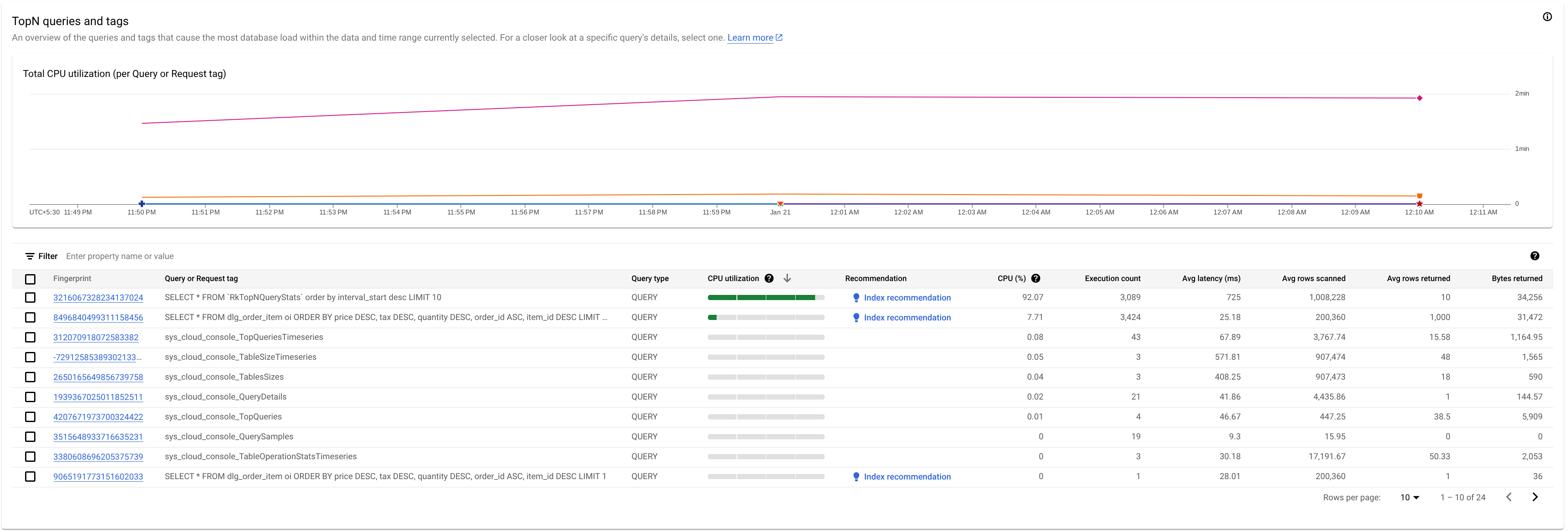
Aquí vemos que la consulta con la huella digital 3216067328234137024 tiene un uso elevado de la CPU y puede causar problemas.
La tabla Consultas principales ofrece un resumen de las consultas que usan más CPU durante el periodo elegido, ordenadas de mayor a menor. El número de consultas TopN está limitado a 100.
En el caso de los gráficos, obtenemos los datos de la tabla de estadísticas de consultas TopN, que tiene tres granularidades diferentes: 1 minuto, 10 minutos y 1 hora. El valor de cada punto de datos de los gráficos representa el valor medio durante un intervalo de un minuto.
Te recomendamos que añadas etiquetas a tus consultas SQL. El etiquetado de consultas te ayuda a encontrar problemas en estructuras de nivel superior, como la lógica empresarial o un microservicio.

En la tabla se muestran las siguientes propiedades:
- Huella digital: hash de la etiqueta de la solicitud o, si la etiqueta no está presente, hash del texto de la consulta.
Etiqueta de consulta o solicitud: si la consulta tiene una etiqueta asociada, se muestra la etiqueta de solicitud. Las estadísticas de varias consultas que tienen la misma cadena de etiquetas se agrupan en una sola fila con el valor
REQUEST_TAGque coincide con la cadena de etiquetas. Para obtener más información sobre cómo usar etiquetas de solicitud, consulta el artículo Solucionar problemas con etiquetas de solicitud y de transacción.Si la consulta no tiene ninguna etiqueta asociada, se muestra la consulta SQL, truncada a aproximadamente 64 KB. En el caso de las DML por lotes, las instrucciones SQL se acoplan en una sola fila y se concatenan mediante un delimitador de punto y coma. Los textos SQL idénticos consecutivos se desduplican antes de truncarse.
Tipo de consulta: indica si una consulta es
PARTITIONED_QUERYoQUERY. UnPARTITIONED_QUERYes una consulta con unpartitionTokenobtenido de la API PartitionQuery. El resto de las consultas y las instrucciones DML se denotan con elQUERYquery type.Uso de CPU: consumo de recursos de CPU por parte de una consulta, expresado como porcentaje del total de recursos de CPU utilizados por todas las consultas que se ejecutan en las bases de datos en ese intervalo de tiempo. Se muestra en una barra horizontal con un intervalo de 0 a 100.
Recomendación: Spanner analiza tus consultas para determinar si pueden beneficiarse de índices mejorados. Si es así, recomienda índices nuevos o modificados que pueden mejorar el rendimiento de la consulta. Para obtener más información, consulta Usar el asesor de índices de Spanner.
CPU (%): consumo de recursos de CPU de una consulta, expresado como porcentaje del total de recursos de CPU utilizados por todas las consultas que se ejecutan en las bases de datos durante ese intervalo de tiempo.
Recuento de ejecuciones: número de veces que Spanner ha visto la consulta durante el intervalo.
Latencia media (ms): tiempo medio, en microsegundos, que tarda en ejecutarse cada consulta en la base de datos. Este promedio no incluye el tiempo de codificación ni el de transmisión del conjunto de resultados, así como la sobrecarga.
Promedio de filas analizadas: número medio de filas que ha analizado la consulta, sin incluir los valores eliminados.
Promedio de filas devueltas: número medio de filas que ha devuelto la consulta.
Bytes devueltos: número de bytes de datos que ha devuelto la consulta, sin incluir la sobrecarga de codificación de transmisión.
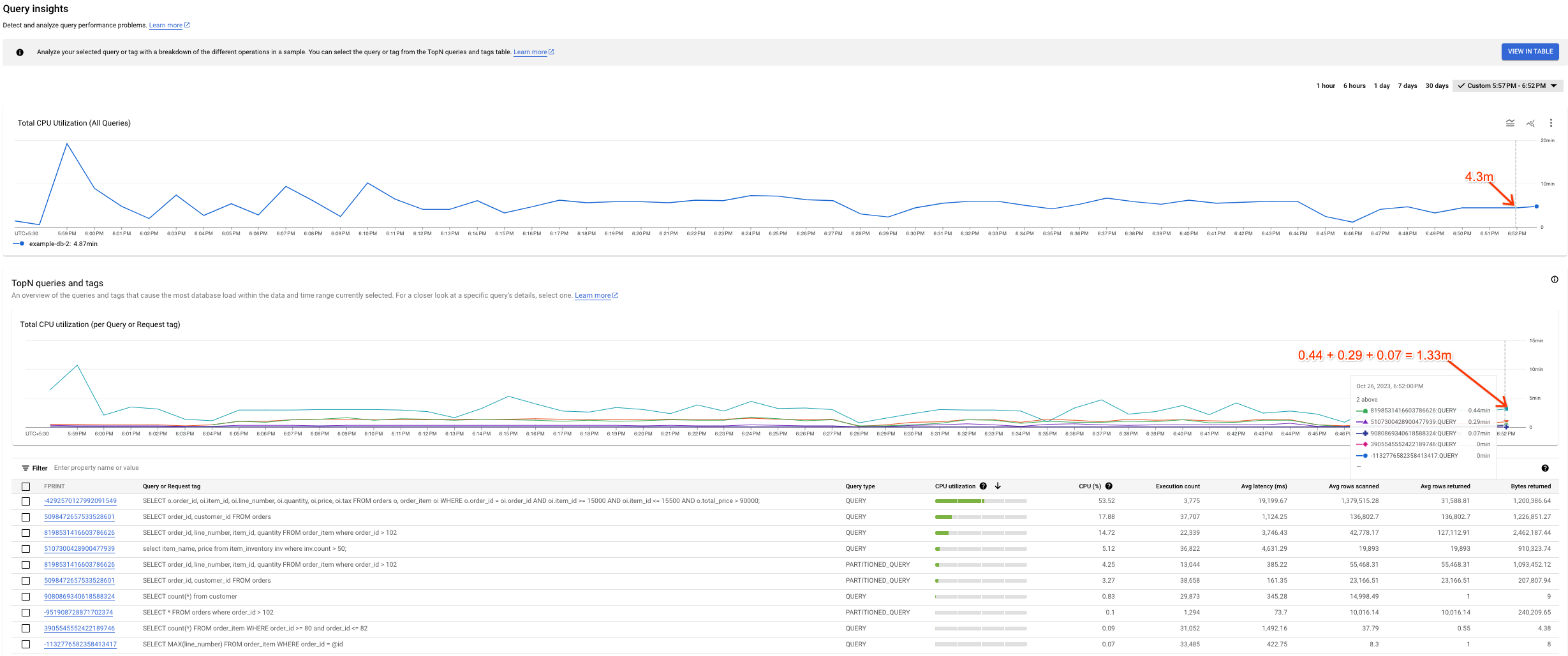
Posible varianza entre los gráficos
Puede que observes algunas variaciones entre el gráfico Uso total de la CPU (todas las consultas) y el gráfico Uso total de la CPU (por etiqueta de consulta o solicitud). Hay dos cosas que pueden provocar esta situación:
Diferentes fuentes de datos: los datos de Cloud Monitoring, que alimentan el gráfico de utilización total de la CPU (todas las consultas), suelen ser más precisos porque se envían cada minuto y tienen un periodo de conservación de 45 días. Por otro lado, los datos de la tabla del sistema, que alimentan el gráfico Uso total de la CPU (por consulta o etiqueta de solicitud), se pueden promediar en 10 minutos (o 1 hora), en cuyo caso podríamos perder datos de alta granularidad que vemos en el gráfico Uso total de la CPU (todas las consultas).
Ventanas de agregación diferentes: ambos gráficos tienen ventanas de agregación diferentes. Por ejemplo, si queremos inspeccionar un evento que tiene más de 6 horas, consultaríamos la tabla
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE. En este caso, un evento que se produzca a las 10:01 se agregaría durante 10 minutos y estaría presente en la tabla del sistema correspondiente a la marca de tiempo de las 10:10.
En la siguiente captura de pantalla se muestra un ejemplo de esta variación.
Analizar una consulta o una etiqueta de solicitud concretas
Para determinar si una consulta o una etiqueta de solicitud es la causa principal del problema, haga clic en la consulta o en la etiqueta de solicitud que parezca tener la carga más alta o que tarde más que las demás. Puedes seleccionar varias consultas y etiquetas de solicitud a la vez.
Puede mantener el puntero del ratón sobre el gráfico para ver las consultas de la cronología y saber el uso de CPU (en segundos).
Intenta acotar el problema analizando lo siguiente:
- ¿Cuánto tiempo lleva la carga alta? ¿Solo es alto ahora? ¿O ha estado alta durante mucho tiempo? Cambia los intervalos de tiempo para encontrar la fecha y la hora en las que la consulta empezó a dar un rendimiento bajo.
- ¿Ha habido picos en el uso de la CPU? Puedes cambiar el periodo para estudiar el uso histórico de la CPU de la consulta.
- ¿Cuál es el consumo de recursos? ¿Qué relación tiene con otras consultas? Consulta la tabla y compara los datos de otras consultas con la seleccionada. ¿Hay alguna diferencia importante?
Para confirmar que la consulta seleccionada contribuye al alto uso de la CPU, puede desglosar los detalles de la forma de la consulta específica (o etiqueta de solicitud) y analizarla más a fondo en la página Detalles de la consulta.
Ver la página Detalles de la consulta
Para ver los detalles de una forma de consulta o una etiqueta de solicitud específicas en formato gráfico, haz clic en la huella digital asociada a la consulta o a la etiqueta de solicitud. Se abrirá la página Detalles de la consulta.
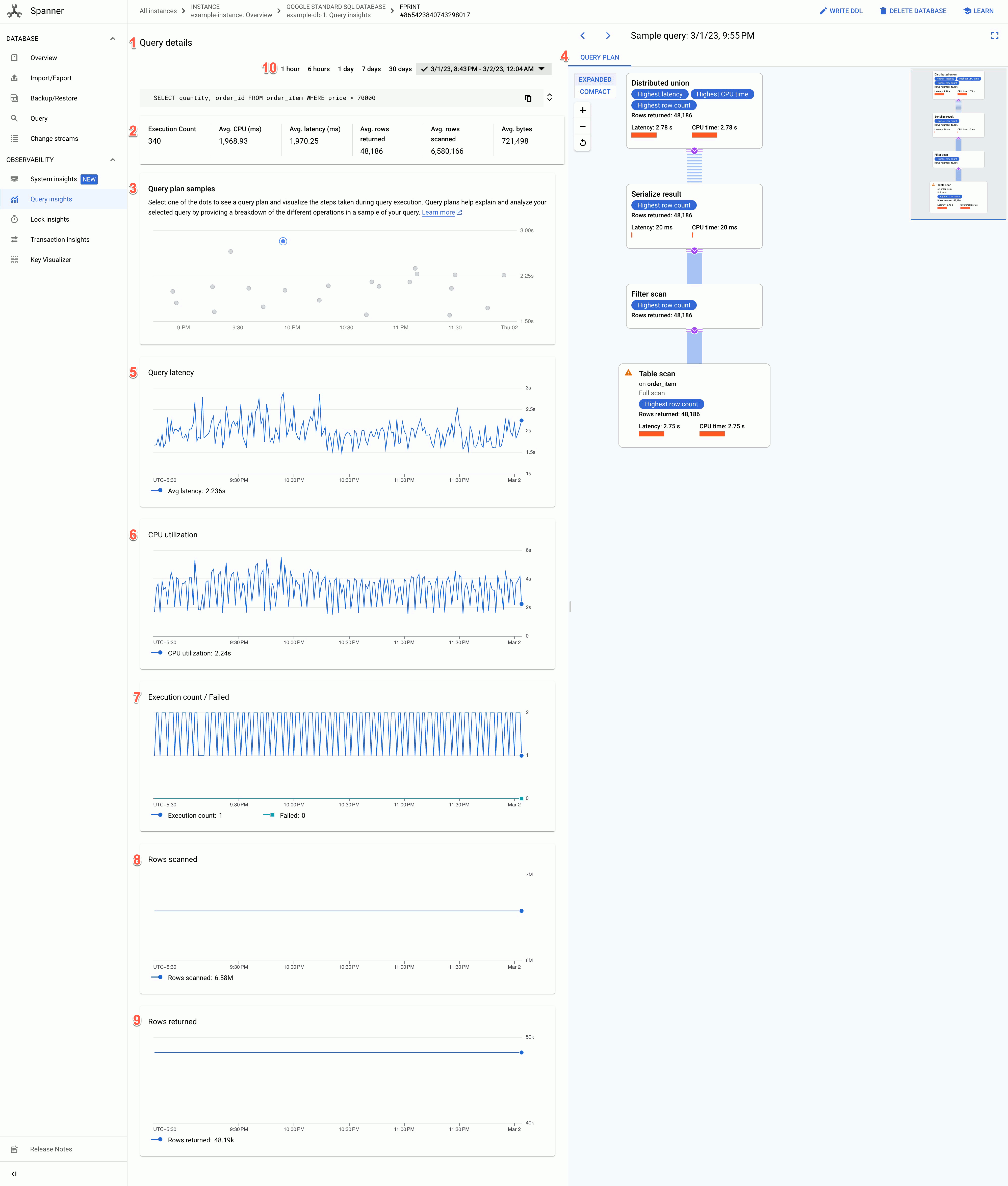
En la página Detalles de la consulta se muestra la siguiente información:
- Texto de los detalles de la consulta: texto de la consulta SQL, truncado a aproximadamente 64 KB. Las estadísticas de varias consultas que tienen la misma cadena de etiqueta se agrupan en una sola fila con el valor REQUEST_TAG que coincide con esa cadena de etiqueta. En este campo solo se muestra el texto de una de esas consultas. En el caso de las DML por lotes, el conjunto de instrucciones SQL se acopla en una sola fila y se concatena mediante un delimitador de punto y coma. Los textos SQL idénticos consecutivos se desduplican antes de truncarse.
- Los valores de los siguientes campos:
- Recuento de ejecuciones: número de veces que Spanner ha visto la consulta durante el intervalo.
- Uso medio de CPU (ms): consumo medio de recursos de CPU, en milisegundos, por una consulta de los recursos de CPU de la instancia en un intervalo de tiempo.
- Latencia media (ms): tiempo medio, en milisegundos, de cada ejecución de consulta en la base de datos. Este promedio excluye el tiempo de codificación y transmisión del conjunto de resultados y la sobrecarga.
- Promedio de filas devueltas: número medio de filas que ha devuelto la consulta.
- Media de filas analizadas: número medio de filas que ha analizado la consulta, sin incluir los valores eliminados.
- Bytes medios: número de bytes de datos que ha devuelto la consulta, sin incluir la sobrecarga de codificación de la transmisión.
- Gráfico de ejemplos de planes de consultas: cada punto del gráfico representa un plan de consultas muestreado en un momento concreto y su latencia de consulta específica. Haz clic en uno de los puntos del gráfico para ver el plan de consultas y los pasos que se han seguido durante la ejecución de la consulta. Nota: Los planes de consulta no se admiten en las consultas con partitionTokens obtenidos de la API PartitionQuery ni en las consultas de DML particionado.
Visualizador de planes de consultas: muestra el plan de consultas seleccionado. Spanner ofrece las siguientes opciones de diseño:
- Vista de árbol: esta vista representa el plan de consulta como un gráfico en el que cada nodo o tarjeta representa un iterador que consume filas de sus entradas y genera filas para su elemento superior. Puedes hacer clic en cada iterador para ver más información.
Vista secuencial: esta vista muestra el plan de consulta en una tabla jerárquica en la que cada fila representa un operador. Puedes hacer clic en cada fila para ver más información.

La tabla muestra las siguientes columnas:
- Nombre: el nombre del operador.
- Grupo de máquinas: el grupo de máquinas en el que se ha ejecutado este operador.
- Latencia: tiempo transcurrido durante la ejecución de la operación actual. Puede que sea más que el tiempo de CPU (por ejemplo, si el operador ha esperado llamadas remotas o un retraso del sistema de archivos).
- Latencia acumulada: cantidad de tiempo transcurrido durante la ejecución de todo el subárbol cuya raíz es este operador. Esto no incluye el tiempo de creación del plan ni otros gastos generales, por lo que la latencia acumulada puede ser inferior a la duración total de la consulta.
- Tiempo de CPU: tiempo total de CPU que se ha empleado para ejecutar la consulta. No incluye la latencia de la red. Algunas partes de la ejecución de la consulta se pueden realizar en paralelo, por lo que es posible que el tiempo de CPU sea mayor que el tiempo total transcurrido. Por ejemplo, si una consulta ejecuta diez operaciones paralelas en 1 milisegundo (ms), el tiempo transcurrido es 1 ms, pero el tiempo de CPU es 10 ms.
- Filas devueltas: número de filas devueltas por el operador.
Gráfico de latencia de las consultas: muestra el valor de la latencia de una consulta seleccionada durante un periodo. También se muestra la latencia media.
Gráfico de uso de CPU: muestra el uso de CPU de una consulta, en porcentaje, durante un periodo. También muestra la utilización media de la CPU.
Gráfico de recuento de ejecuciones/fallos: muestra el recuento de ejecuciones de una consulta durante un periodo y el número de veces que ha fallado la ejecución de la consulta.
Gráfico de filas analizadas: muestra el número de filas que ha analizado la consulta durante un periodo.
Gráfico de filas devueltas: muestra el número de filas que ha devuelto la consulta durante un periodo.
Filtro de periodo: filtra los detalles de las consultas por periodos, como horas, días o un periodo personalizado.
En el caso de los gráficos, obtenemos los datos de la tabla de estadísticas de consultas TopN, que tiene tres granularidades diferentes: 1 minuto, 10 minutos y 1 hora. El valor de cada punto de datos de los gráficos representa el valor medio durante un intervalo de un minuto.
Buscar todas las ejecuciones de una consulta en el registro de auditoría
Para buscar todas las ejecuciones de una huella digital de consulta concreta en Registros de auditoría de Cloud, consulta el registro de auditoría y busca cualquier query_fingerprint que coincida con el campo Fingerprint de la tabla Estadísticas de las consultas principales. Para obtener más información, consulta el artículo Consultar y ver registros. Usa este método para identificar al usuario que ha iniciado la consulta.