Cette page explique comment utiliser le tableau de bord "Insights sur les requêtes" pour détecter et analyser les problèmes de performances de Spanner.
Présentation des insights sur les requêtes
L'outil Insights sur les requêtes vous aide à détecter et à diagnostiquer les problèmes de performances des requêtes et des instructions LMD (INSERT, UPDATE et DELETE) pour une base de données Spanner. Il offre un système de surveillance intuitif et fournit des informations de diagnostic qui vous aident à identifier la principale cause des problèmes de performances.
Insights sur les requêtes vous aide à améliorer les performances des requêtes Spanner en suivant les étapes ci-dessous :
- Déterminez si des requêtes inefficaces entraînent une utilisation élevée du processeur.
- Identifiez une requête ou un tag potentiellement problématique
- Analysez la requête ou le tag de demande pour identifier les problèmes.
Les insights sur les requêtes sont disponibles dans les configurations régionales et multirégionales.
Tarifs
L'utilisation de Insights sur les requêtes n'entraîne aucun coût supplémentaire.
Conservation des données
Les insights sur les requêtes conservent les données pendant 30 jours maximum.
Pour le graphique Utilisation totale du processeur (par requête ou tag de requête), Spanner récupère les données des tables SPANNER_SYS.QUERY_STATS_TOP_*. La durée de conservation maximale de ces tables est de 30 jours. Pour en savoir plus, consultez Conservation des données.
Rôles requis
Vous avez besoin de différents rôles et autorisations IAM selon que vous êtes un utilisateur IAM ou un utilisateur du contrôle des accès précis.
Utilisateur Identity and Access Management (IAM)
Pour obtenir les autorisations nécessaires pour afficher la page "Insights sur les requêtes", demandez à votre administrateur de vous accorder les rôles IAM suivants sur l'instance :
-
Lecteur Cloud Spanner (
roles/spanner.viewer) -
Lecteur de bases de données Cloud Spanner (
roles/spanner.databaseReader)
Les autorisations suivantes du rôle Lecteur de bases de données Cloud Spanner(
roles/spanner.databaseReader) sont requises pour afficher la page "Insights sur les requêtes" :
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Utilisateur du contrôle précis des accès
Si vous utilisez le contrôle précis des accès, vérifiez que :
- Disposer du rôle Lecteur Cloud Spanner(
roles/spanner.viewer) - disposent de droits de contrôle des accès ultraprécis et du rôle système
spanner_sys_readerou de l'un de ses rôles membres. - Sélectionnez
spanner_sys_readerou un rôle de membre comme rôle système actuel sur la page de présentation de la base de données.
Pour en savoir plus, consultez À propos du contrôle des accès ultraprécis et Rôles système pour le contrôle des accès ultraprécis.
Tableau de bord "Insights sur les requêtes"
Le tableau de bord "Insights sur les requêtes" affiche la charge de la requête en fonction de la base de données et de la période que vous sélectionnez. La charge de la requête correspond à la mesure de l'utilisation totale du processeur pour toutes les requêtes de l'instance au cours de la période sélectionnée. Le tableau de bord fournit une série de filtres qui vous aident à afficher la charge des requêtes.
Pour afficher le tableau de bord "Insights sur les requêtes" d'une base de données :
- Sélectionnez Insights sur les requêtes dans le panneau de navigation de gauche. Le tableau de bord "Insights sur les requêtes" s'ouvre.
- Sélectionnez une base de données dans la liste Bases de données. Le tableau de bord affiche les informations sur la charge de requête pour la base de données.
Le tableau de bord comprend les sections suivantes :
- Liste des bases de données : permet de filtrer la charge des requêtes sur une base de données spécifique ou sur toutes les bases de données.
- Filtre de période : filtre la charge des requêtes par période, par exemple par heure, par jour ou selon une plage personnalisée.
- Graphique "Utilisation totale du processeur (toutes les requêtes)" : affiche la charge agrégée de toutes les requêtes.
- Graphique "Utilisation totale du processeur (par requête ou tag de requête)" : affiche l'utilisation du processeur par tag de requête.
- Tableau des requêtes et tags TopN : affiche la liste des requêtes et des tags de requête les plus fréquents, triés par utilisation du processeur. Consultez Identifier une requête ou un tag potentiellement problématique.
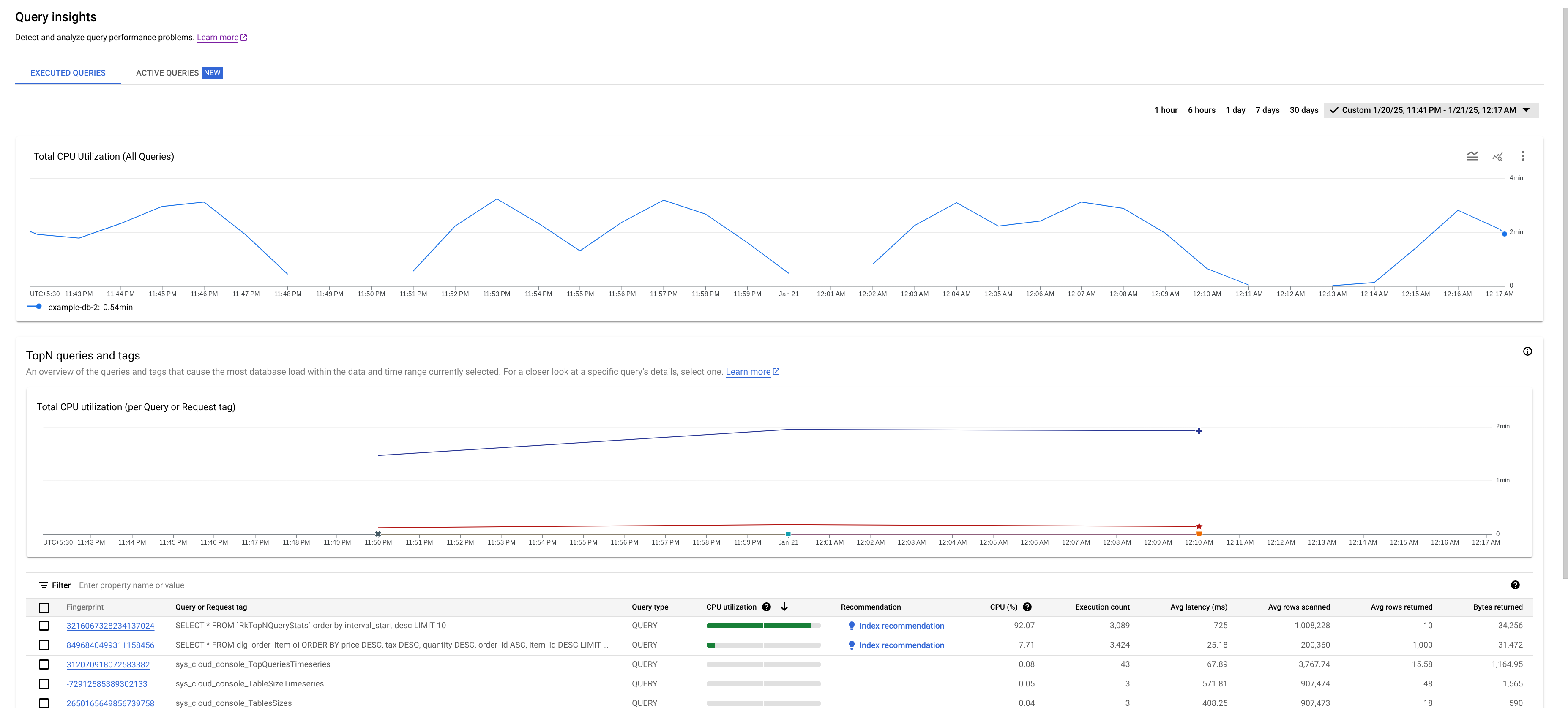
Performances du tableau de bord
Utilisez des paramètres de requête ou taggez vos requêtes pour optimiser les performances de Query Insights. Si vous ne paramétrez pas ou ne taguez pas vos requêtes, un trop grand nombre de résultats peut être renvoyé, ce qui peut empêcher le chargement correct du tableau "Requêtes et tags TopN".
Vérifier si des requêtes inefficaces sont responsables d'une utilisation élevée du processeur
L'utilisation totale du CPU est une mesure du travail (en secondes de temps de processeur) effectué au fil du temps par les requêtes exécutées dans la base de données sélectionnée.

Examinez le graphique pour répondre aux questions suivantes :
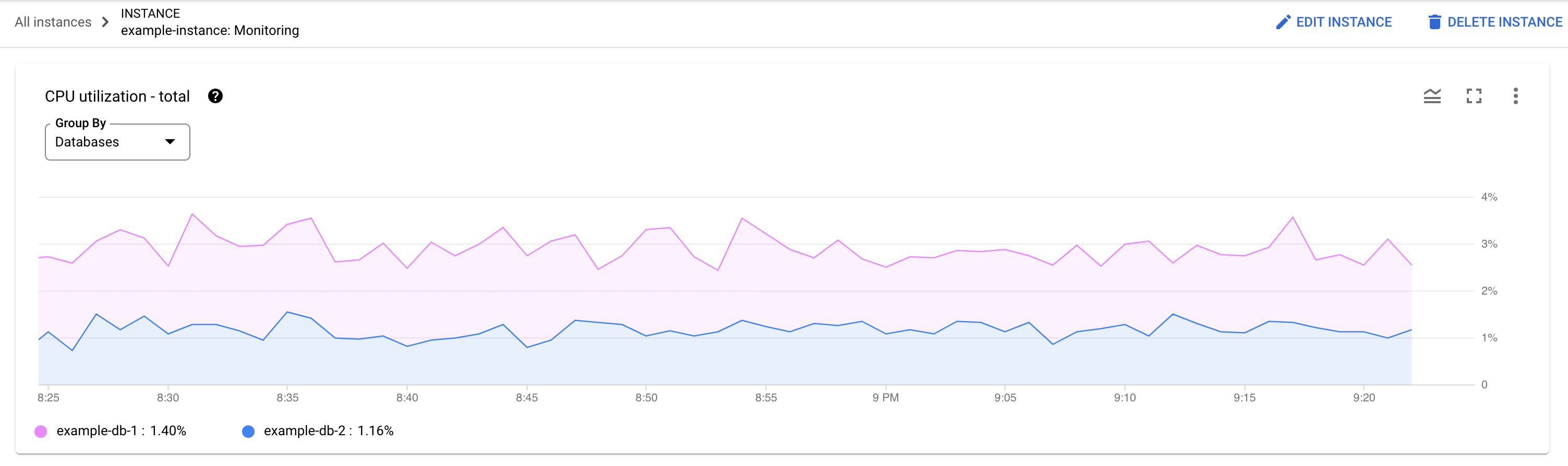
Quelle base de données subit la charge ? Sélectionnez différentes bases de données dans la liste "Bases de données" pour trouver celles avec les charges les plus élevées. Pour identifier la base de données ayant la charge la plus élevée, vous pouvez également consulter le graphique Utilisation du processeur – Total pour les bases de données dans la consoleGoogle Cloud .
L'utilisation du processeur est-elle élevée ? Le graphique a-t-il connu un pic ou augmenté au fil du temps ? Si vous ne constatez pas une utilisation élevée du processeur, le problème ne concerne pas vos requêtes.
Depuis combien de temps l'utilisation du processeur est-elle élevée ? A-t-il connu un pic récemment ou est-il resté élevé pendant un certain temps ? Utilisez le sélecteur de plage pour sélectionner différentes périodes afin de déterminer la durée du problème. Effectuez un zoom avant pour afficher une période pendant laquelle les pics de charge de requêtes sont observés. Effectuez un zoom arrière pour afficher jusqu'à une semaine de la chronologie.
Si vous constatez un pic ou une augmentation dans le graphique correspondant à l'utilisation globale du processeur de l'instance, cela est très probablement dû à une ou plusieurs requêtes coûteuses. Vous pouvez ensuite approfondir le débogage en identifiant une requête ou un tag de requête potentiellement problématiques.
Identifier une requête ou un tag de requête potentiellement problématique
Pour identifier une requête ou un tag de requête potentiellement problématique, examinez la section "Requêtes TopN" :
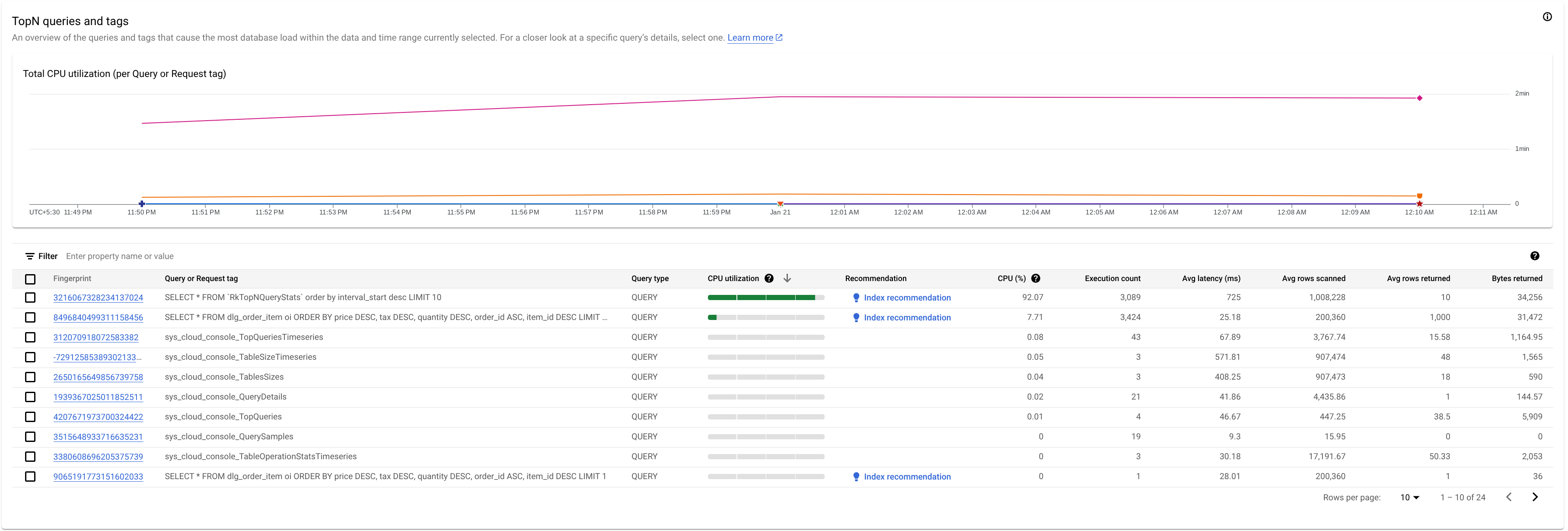
Ici, nous voyons que la requête avec l'empreinte 3216067328234137024 présente une utilisation élevée du processeur et peut être problématique.
Le tableau Requêtes TopN fournit un aperçu des requêtes qui utilisent le plus de processeur au cours de la période choisie, triées de la plus élevée à la plus faible. Le nombre de requêtes TopN est limité à 100.
Pour les graphiques, nous récupérons les données de la table des statistiques sur les requêtes TopN, qui présente trois niveaux de précision différents : 1 min, 10 min et 1 heure. La valeur de chaque point de données des graphiques représente la valeur moyenne sur un intervalle d'une minute.
Nous vous recommandons d'ajouter des tags à vos requêtes SQL. L'ajout de tags aux requêtes vous aide à détecter les problèmes liés à des constructions de niveau supérieur, tels que la logique métier ou un microservice.

Le tableau affiche les propriétés suivantes :
- Empreinte digitale : hachage du tag de la requête ou, si le tag n'est pas présent, hachage du texte de la requête.
Tag de requête : si la requête est associée à un tag, le tag de requête s'affiche. Les statistiques de plusieurs requêtes ayant la même chaîne de tag sont regroupées sur une seule ligne avec la valeur
REQUEST_TAGcorrespondant à la chaîne de tag. Pour en savoir plus sur l'utilisation des tags de requête, consultez Résoudre les problèmes liés aux tags de requête et aux tags de transaction.Si la requête n'est associée à aucun tag, la requête SQL, tronquée à environ 64 Ko, s'affiche. Pour le traitement LMD par lots, les instructions SQL sont aplaties en une seule ligne et concaténées à l'aide d'un point-virgule comme délimiteur. Les textes SQL identiques consécutifs sont dédupliqués avant d'être tronqués.
Type de requête : indique si une requête est
PARTITIONED_QUERYouQUERY. UnPARTITIONED_QUERYest une requête avec unpartitionTokenobtenu à partir de l'API PartitionQuery. Toutes les autres requêtes et instructions LMD sont indiquées par le type de requêteQUERY.Utilisation du processeur : consommation de ressources processeur par une requête, exprimée en pourcentage des ressources processeur totales utilisées par toutes les requêtes exécutées sur les bases de données au cours de cet intervalle de temps. Cette valeur est affichée sur une barre horizontale dont la plage va de 0 à 100.
Recommandation : Spanner analyse vos requêtes pour déterminer si elles peuvent bénéficier d'index améliorés. Si c'est le cas, il recommande de nouveaux index ou des index modifiés qui peuvent améliorer les performances des requêtes. Pour en savoir plus, consultez Utiliser le conseiller d'index Spanner.
CPU (%) : consommation de ressources de processeur par une requête, exprimée en pourcentage des ressources de processeur totales utilisées par toutes les requêtes exécutées sur les bases de données au cours de cette période.
Nombre d'exécutions : nombre de fois que Spanner a vu la requête au cours de l'intervalle.
Latence moyenne (ms) : durée moyenne, en microsecondes, de chaque exécution de la requête dans la base de données. à l'exclusion du temps d'encodage et de transmission de l'ensemble de résultats ainsi que de la surcharge
Lignes analysées en moyenne : nombre moyen de lignes analysées par la requête, à l'exclusion des valeurs supprimées.
Lignes renvoyées en moyenne : nombre moyen de lignes renvoyées par la requête.
Octets renvoyés : nombre d'octets de données renvoyés par la requête, à l'exclusion de la surcharge liée à l'encodage de la transmission.
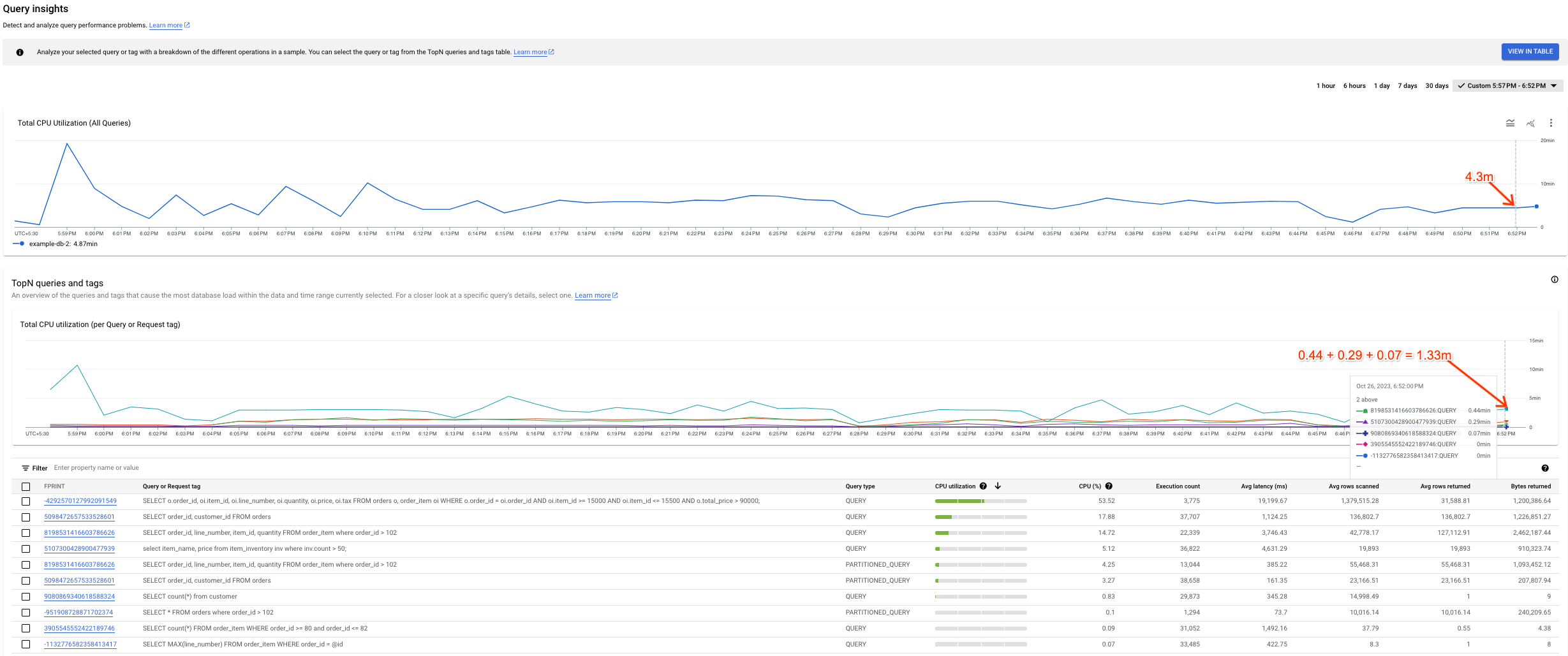
Variance possible entre les graphiques
Vous remarquerez peut-être une certaine variance entre le graphique Utilisation totale du processeur (toutes les requêtes) et le graphique Utilisation totale du processeur (par requête ou tag de requête). Deux raisons peuvent expliquer ce scénario :
Différentes sources de données : les données Cloud Monitoring, qui alimentent le graphique "Utilisation totale du processeur (toutes les requêtes)", sont généralement plus précises, car elles sont envoyées toutes les minutes et ont une période de conservation de 45 jours. En revanche, les données du tableau système, qui alimentent le graphique "Utilisation totale du processeur (par requête ou tag de requête)", peuvent être moyennées sur 10 minutes (ou 1 heure). Dans ce cas, nous risquons de perdre les données de haute précision que nous voyons dans le graphique "Utilisation totale du processeur (toutes les requêtes)".
Différentes périodes d'agrégation : les deux graphiques ont des périodes d'agrégation différentes. Par exemple, lorsque nous inspectons un événement datant de plus de six heures, nous interrogeons la table
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE. Dans ce cas, un événement qui se produit à 10h01 est agrégé sur 10 minutes et figure dans le tableau système correspondant à l'horodatage de 10h10.
La capture d'écran suivante montre un exemple de cette variance.
Analyser une requête ou un tag de requête spécifique
Pour déterminer si une requête ou une balise de requête est la cause principale du problème, cliquez sur la requête ou la balise de requête qui semble avoir la charge la plus élevée ou qui dure plus longtemps que les autres. Vous pouvez sélectionner plusieurs requêtes et tags de requête à la fois.
Vous pouvez pointer sur le graphique des requêtes tout au long de la chronologie pour connaître leur utilisation du processeur (en secondes).
Essayez de préciser le problème en examinant les éléments suivants :
- Depuis combien de temps la charge est-elle élevée ? Est-elle élevée uniquement maintenant ? Ou est-elle élevée depuis longtemps ? Modifiez les périodes pour trouver la date et l'heure auxquelles la requête a commencé à mal fonctionner.
- Y a-t-il eu des pics d'utilisation du processeur ? Vous pouvez modifier la période pour étudier l'historique de l'utilisation du processeur pour la requête.
- Quelle est la consommation des ressources ? Quel est le rapport avec les autres requêtes ? Examinez le tableau et comparez les données des autres requêtes avec celles de la requête sélectionnée. Existe-t-il une différence majeure ?
Pour confirmer que la requête sélectionnée contribue à l'utilisation élevée du processeur, vous pouvez examiner en détail la forme de requête (ou le tag de requête) spécifique et l'analyser plus en détail sur la page "Détails de la requête".
Afficher la page "Détails de la requête"
Pour afficher les détails d'une forme de requête ou d'un tag de requête spécifique sous forme graphique, cliquez sur l'empreinte digitale associée à la requête ou au tag de requête. La page "Détails de la requête" s'ouvre.
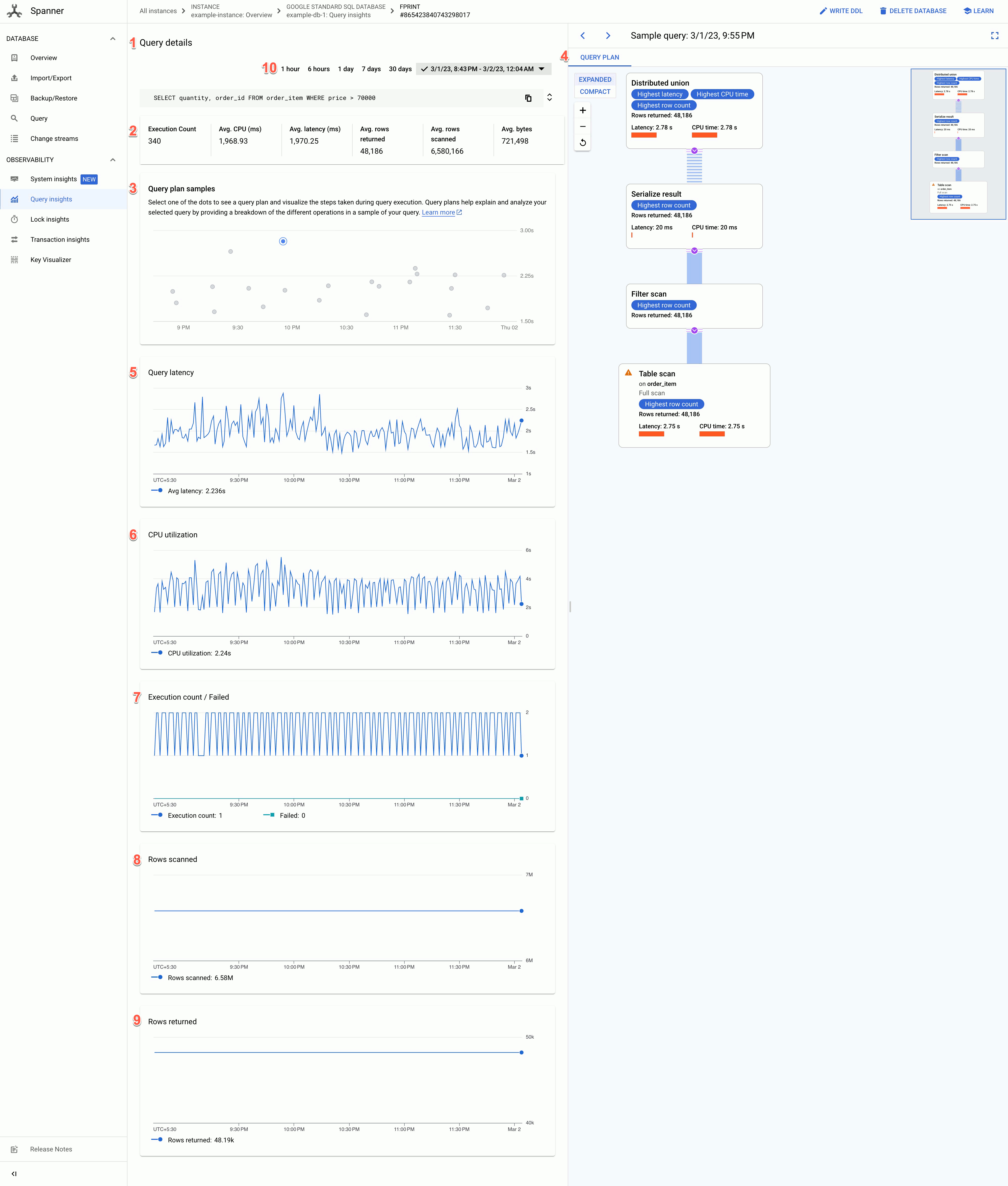
La page "Détails de la requête" affiche les informations suivantes :
- Texte des détails de la requête : texte de la requête SQL, tronqué à environ 64 Ko. Les statistiques de plusieurs requêtes ayant la même chaîne de tag sont regroupées sur une seule ligne avec le REQUEST_TAG correspondant à cette chaîne de tag. Seul le texte de l'une de ces requêtes est affiché dans ce champ. Pour le traitement LMD par lots, l'ensemble des instructions SQL est aplati en une seule ligne, concaténé à l'aide d'un point-virgule comme délimiteur. Les textes SQL identiques consécutifs sont dédupliqués avant d'être tronqués.
- Les valeurs des champs suivants :
- Nombre d'exécutions : nombre de fois que Spanner a vu la requête au cours de l'intervalle.
- Temps CPU moyen (ms) : consommation moyenne des ressources de processeur, en millisecondes, par une requête des ressources de processeur de l'instance dans un intervalle de temps.
- Latence moyenne (ms) : durée moyenne, en millisecondes, de chaque exécution de la requête dans la base de données. à l'exclusion du temps d'encodage et de transmission de l'ensemble de résultats ainsi que de la surcharge
- Lignes renvoyées en moyenne : nombre moyen de lignes renvoyées par la requête.
- Lignes analysées en moyenne : nombre moyen de lignes analysées par la requête, à l'exclusion des valeurs supprimées.
- Octets moyens : nombre d'octets de données renvoyés par la requête, à l'exclusion de la surcharge liée à l'encodage de la transmission.
- Graphique des exemples de plans de requête : chaque point du graphique représente un exemple de plan de requête à un moment précis et sa latence de requête spécifique. Cliquez sur l'un des points du graphique pour afficher le plan de requête et visualiser les étapes effectuées lors de l'exécution de la requête. Remarque : Les plans de requête ne sont pas compatibles avec les requêtes comportant des partitionTokens obtenus à partir de l'API PartitionQuery ni avec les requêtes LMD partitionné.
Outil de visualisation de plans de requête : affiche le plan de requête échantillonné sélectionné. Spanner propose les options de mise en page suivantes :
- Vue arborescente : la vue arborescente visualise le plan de requête sous la forme d'un graphique où chaque nœud ou fiche représente un itérateur qui consomme les lignes de ses entrées et produit des lignes vers son parent. Vous pouvez cliquer sur chaque itérateur pour obtenir plus d'informations.
Vue séquentielle : la vue séquentielle visualise le plan de requête dans un tableau hiérarchique où chaque ligne représente un opérateur. Vous pouvez cliquer sur chaque ligne pour afficher plus d'informations.

Le tableau comporte les colonnes suivantes :
- Nom : nom de l'opérateur.
- Groupe de machines : groupe de machines sur lequel cet opérateur s'est exécuté.
- Latence : temps écoulé lors de l'exécution de l'opération en cours. Ce total peut être supérieur au temps CPU (par exemple, si l'opérateur a attendu des appels à distance ou un retard du système de fichiers).
- Latence cumulée : temps écoulé pendant l'exécution de l'ensemble de la sous-arborescence dont cet opérateur est la racine. Cela n'inclut pas le temps de création du plan ni les autres frais généraux. La latence cumulée peut donc être inférieure à la durée totale de la requête.
- Temps CPU : temps CPU total utilisé pour l'exécution de la requête. N'inclut pas la latence du réseau. Certaines parties de l'exécution d'une requête peuvent avoir lieu en parallèle. Il est donc possible que le temps CPU soit supérieur à la durée totale écoulée. Par exemple, si une requête exécute dix opérations en parallèle en 1 milliseconde (ms), le temps écoulé est de 1 ms, mais le temps CPU est de 10 ms.
- Lignes renvoyées : nombre de lignes renvoyées par l'opérateur.
Graphique de latence des requêtes : indique la valeur de la latence des requêtes pour une requête sélectionnée sur une période donnée. Elle indique également la latence moyenne.
Graphique "Utilisation du processeur" : indique l'utilisation du processeur par une requête, en pourcentage, sur une période donnée. Il indique également l'utilisation moyenne du processeur.
Graphique "Nombre d'exécutions/Échecs" : indique le nombre d'exécutions d'une requête sur une période donnée et le nombre de fois où l'exécution de la requête a échoué.
Graphique "Lignes analysées" : indique le nombre de lignes analysées par la requête sur une période donnée.
Graphique "Lignes renvoyées" : indique le nombre de lignes renvoyées par la requête sur une période donnée.
Filtre de période : permet de filtrer les détails des requêtes par période, par exemple par heure, par jour ou selon une plage personnalisée.
Pour les graphiques, nous récupérons les données de la table des statistiques sur les requêtes TopN, qui présente trois niveaux de précision différents : 1 min, 10 min et 1 heure. La valeur de chaque point de données des graphiques représente la valeur moyenne sur un intervalle d'une minute.
Rechercher toutes les exécutions d'une requête dans le journal d'audit
Pour rechercher toutes les exécutions d'une empreinte de requête spécifique dans les journaux d'audit Cloud, interrogez le journal d'audit et recherchez tout query_fingerprint correspondant au champ Fingerprint dans le tableau des statistiques TopN sur les requêtes. Pour en savoir plus, consultez la présentation de l'interrogation et de l'affichage des journaux. Utilisez cette méthode pour identifier l'utilisateur qui a lancé la requête.