En esta página se describe cómo usar la recuperación a un momento dado (PITR) para conservar y recuperar datos en Spanner para bases de datos con dialecto GoogleSQL y con dialecto PostgreSQL.
Para obtener más información, consulta Recuperación a un momento dado.
Requisitos previos
En esta guía se usan la base de datos y el esquema definidos en la guía de inicio rápido de Spanner. Puedes seguir la guía de inicio rápido para crear la base de datos y el esquema, o modificar los comandos para usarlos con tu propia base de datos.
Configurar el periodo de conservación
Para definir el periodo de conservación de tu base de datos, sigue estos pasos:
Consola
Ve a la página Instancias de Spanner de la Google Cloud consola.
Haz clic en la instancia que contiene la base de datos para abrir su página Resumen.
Haz clic en la base de datos para abrir su página Vista general.
Selecciona la pestaña Copia de seguridad/Restaurar.
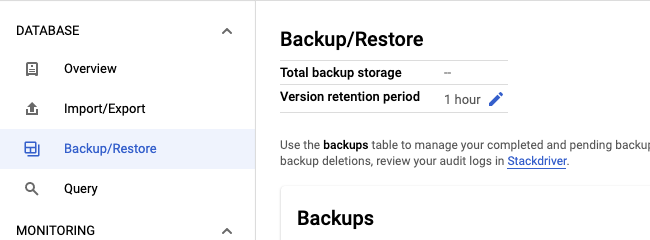
Haga clic en el icono del lápiz del campo Periodo de conservación de versiones.
Introduce una cantidad y una unidad de tiempo para el periodo de retención y, a continuación, haz clic en Actualizar.
gcloud
Actualiza el esquema de la base de datos con la instrucción ALTER DATABASE. Por ejemplo:
gcloud spanner databases ddl update example-db \
--instance=test-instance \
--ddl='ALTER DATABASE `example-db` \
SET OPTIONS (version_retention_period="7d");'Para ver el periodo de conservación, obtén el DDL de tu base de datos:
gcloud spanner databases ddl describe example-db \
--instance=test-instanceEste es el resultado:
ALTER DATABASE example-db SET OPTIONS (
version_retention_period = '7d'
);
...
Bibliotecas de cliente
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Notas sobre el uso:
- El periodo de conservación debe ser de entre 1 hora y 7 días, y se puede especificar en días, horas, minutos o segundos. Por ejemplo, los valores
1d,24h,1440my86400sson equivalentes. - Si ha habilitado el registro de la API de Spanner en su proyecto, el evento se registrará como UpdateDatabaseDdl y se mostrará en el Explorador de registros.
- Para volver al periodo de conservación predeterminado de 1 hora, puedes definir la opción de base de datos
version_retention_periodenNULLpara las bases de datos de GoogleSQL o enDEFAULTpara las bases de datos de PostgreSQL. - Si amplía el periodo de conservación, el sistema no rellenará las versiones anteriores de los datos. Por ejemplo, si amplías el periodo de conservación de una hora a 24 horas, debes esperar 23 horas para que el sistema acumule datos antiguos antes de poder recuperar datos de las últimas 24 horas.
Obtener el periodo de conservación y la hora de la versión más antigua
El recurso Database incluye dos campos:
version_retention_period: el periodo durante el cual Spanner conserva todas las versiones de los datos de la base de datos.earliest_version_time: la marca de tiempo más antigua en la que se pueden leer versiones anteriores de los datos de la base de datos. Spanner actualiza este valor continuamente y se queda obsoleto en el momento en que se consulta. Si utiliza este valor para recuperar datos, tenga en cuenta el tiempo transcurrido desde el momento en que se consulta el valor hasta el momento en que inicia la recuperación.
Consola
Ve a la página Instancias de Spanner en la Google Cloud consola.
Haz clic en la instancia que contiene la base de datos para abrir su página Resumen.
Haz clic en la base de datos para abrir su página Vista general.
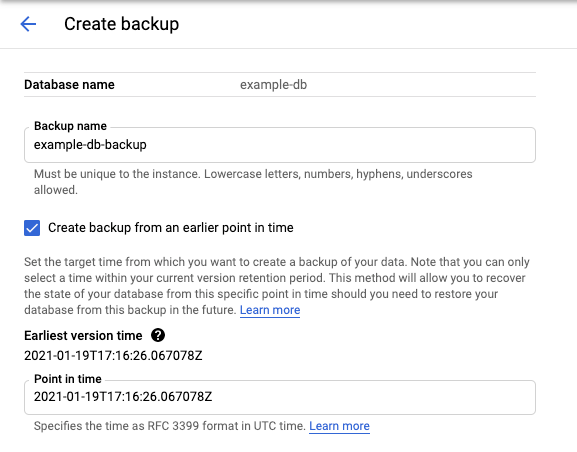
Selecciona la pestaña Copia de seguridad/Restaurar para abrir la página Copia de seguridad/Restaurar y mostrar el periodo de conservación.
Haz clic en Crear para abrir la página Crear una copia de seguridad y mostrar la hora de la versión más antigua.
gcloud
Puedes obtener estos campos llamando a describe databases o list databases. Por ejemplo:
gcloud spanner databases describe example-db \
--instance=test-instanceEste es el resultado:
createTime: '2020-09-07T16:56:08.285140Z'
earliestVersionTime: '2020-10-07T16:56:08.285140Z'
name: projects/my-project/instances/test-instance/databases/example-db
state: READY
versionRetentionPeriod: 3d
Recuperar una parte de una base de datos
Realiza una lectura obsoleta y especifica la marca de tiempo de recuperación necesaria. Asegúrate de que la marca de tiempo que especifiques sea más reciente que la
earliest_version_time.de la base de datos.gcloud
Usa execute-sql Por ejemplo:
gcloud spanner databases execute-sql example-db \ --instance=test-instance --read-timestamp=2020-09-11T10:19:36.010459-07:00\ --sql='SELECT * FROM SINGERS'Bibliotecas de cliente
Consulta realizar una lectura obsoleta.
Almacena los resultados de la consulta. Esto es obligatorio porque no puedes escribir los resultados de la consulta en la base de datos en la misma transacción. Si tienes una cantidad pequeña de datos, puedes imprimirlos en la consola o almacenarlos en la memoria. Si tienes que gestionar una gran cantidad de datos, puede que tengas que escribir en un archivo local.
Vuelve a escribir los datos recuperados en la tabla que se debe recuperar. Por ejemplo:
gcloud
gcloud spanner rows update --instance=test-instance --database=example-db --table=Singers \ --data=SingerId=1,FirstName='Marc'Para obtener más información, consulta cómo actualizar datos con gcloud.
Bibliotecas de cliente
Para obtener más información, consulta Actualizar datos mediante DML o Actualizar datos mediante mutaciones.
Si quieres analizar los datos recuperados antes de volver a escribirlos, puedes crear manualmente una tabla temporal en la misma base de datos, escribir los datos recuperados en esta tabla temporal, hacer el análisis y, a continuación, leer los datos que quieras recuperar de esta tabla temporal y escribirlos en la tabla que necesites recuperar.
Recuperar una base de datos completa
Puedes recuperar toda la base de datos con Copia de seguridad y restauración o Importar y exportar, y especificando una marca de tiempo de recuperación.
Copia de seguridad y restauración
Crea una copia de seguridad y define
version_timeen la marca de tiempo de recuperación que necesites.Consola
Ve a la página Detalles de la base de datos de la consola de Cloud.
En la pestaña Copia de seguridad/Restaurar, haz clic en Crear.
Marca la casilla Crear copia de seguridad de un momento anterior.
gcloud
gcloud spanner backups create example-db-backup-1 \ --instance=test-instance \ --database=example-db \ --retention-period=1y \ --version-time=2021-01-22T01:10:35Z --asyncPara obtener más información, consulta Crear una copia de seguridad con gcloud.
Bibliotecas de cliente
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Restaura la copia de seguridad en una base de datos nueva. Ten en cuenta que Spanner conserva el periodo de conservación de la copia de seguridad en la base de datos restaurada.
Consola
Ve a la página Detalles de la instancia de la consola de Cloud.
En la pestaña Copia de seguridad/Restaurar, selecciona una copia de seguridad y haz clic en Restaurar.
gcloud
gcloud spanner databases restore --async \ --destination-instance=destination-instance --destination-database=example-db-restored \ --source-instance=test-instance --source-backup=example-db-backup-1Para obtener más información, consulta el artículo Restaurar una base de datos a partir de una copia de seguridad.
Bibliotecas de cliente
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Importar y exportar
- Exporta la base de datos y especifica el parámetro
snapshotTimecon la marca de tiempo de recuperación necesaria.Consola
Ve a la página Detalles de la instancia de la consola de Cloud.
En la pestaña Importar/Exportar, haga clic en Exportar.
Marca la casilla Exportar base de datos de un momento anterior.
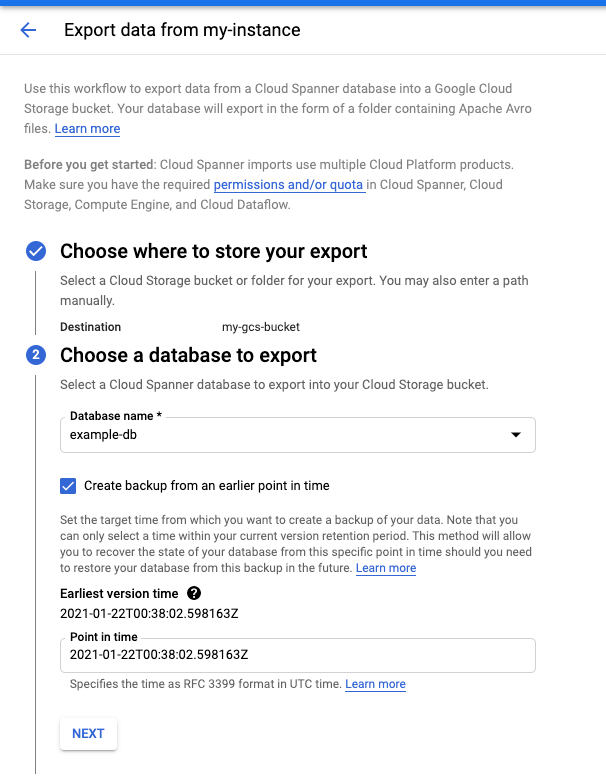
Para obtener instrucciones detalladas, consulta el artículo sobre cómo exportar una base de datos.
gcloud
Usa la plantilla de Dataflow Spanner a Avro para exportar la base de datos.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/export/templates/Cloud_Spanner_to_GCS_Avro' --region=DATAFLOW_REGION \ --parameters='instanceId=test-instance,databaseId=example-db,outputDir=YOUR_GCS_DIRECTORY,snapshotTime=2020-09-01T23:59:40.125245Z'Notas sobre el uso:
- Puedes monitorizar el progreso de tus tareas de importación y exportación en la consola de Dataflow.
- Spanner garantiza que los datos exportados sean coherentes desde el punto de vista externo y transaccional en la marca de tiempo especificada.
- Especifica la marca de tiempo en formato RFC 3339. Por ejemplo, 2020-09-01T23:59:30.234233Z.
- Asegúrate de que la marca de tiempo que especifiques sea más reciente que la
earliest_version_timede la base de datos. Si los datos ya no existen en la marca de tiempo especificada, se producirá un error.
Importar a una base de datos nueva.
Consola
Ve a la página Detalles de la instancia de la consola de Cloud.
En la pestaña Importar/Exportar, haz clic en Importar.
Para obtener instrucciones detalladas, consulta el artículo Importar archivos Avro de Spanner.
gcloud
Usa la plantilla de Dataflow Cloud Storage Avro to Spanner para importar los archivos Avro.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/import/templates/GCS_Avro_to_Cloud_Spanner' \ --region=DATAFLOW_REGION \ --staging-location=YOUR_GCS_STAGING_LOCATION \ --parameters='instanceId=test-instance,databaseId=example-db,inputDir=YOUR_GCS_DIRECTORY'
Estimar el aumento del almacenamiento
Antes de aumentar el periodo de conservación de versiones de una base de datos, puedes estimar el aumento previsto del uso del almacenamiento de la base de datos sumando los bytes de las transacciones del periodo necesario. Por ejemplo, la siguiente consulta calcula el número de GiB escritos en los últimos 7 días (168 horas) leyendo de las tablas de estadísticas de transacciones.
GoogleSQL
SELECT
SUM(bytes_per_hour) / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168);
PostgreSQL
SELECT
bph / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
SUM(bytes_per_hour) as bph
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168)
sub1) sub2;
Ten en cuenta que la consulta proporciona una estimación aproximada y puede ser imprecisa por varios motivos:
- La consulta no tiene en cuenta la marca de tiempo que debe almacenarse para cada versión de los datos antiguos. Si tu base de datos consta de muchos tipos de datos pequeños, es posible que la consulta subestime el aumento del almacenamiento.
- La consulta incluye todas las operaciones de escritura, pero solo las operaciones de actualización crean versiones anteriores de los datos. Si tu carga de trabajo incluye muchas operaciones de inserción, es posible que la consulta sobreestime el aumento del almacenamiento.