クエリプラン ビジュアライザを使用すると、クエリを評価するために Spanner によって選択されたクエリプランの構造をすばやく把握できます。このガイドでは、クエリプランを使用してクエリの実行を把握する方法について説明します。
始める前に
このガイドで説明する Google Cloud コンソールのユーザー インターフェースの各要素について理解を深めるには、次の内容をご覧ください。
Google Cloud コンソールでクエリを実行する
- Google Cloud コンソールの [Spanner インスタンス] ページに移動します。
-
クエリを実行するデータベースを含むインスタンスの名前を選択します。
Google Cloud コンソールにインスタンスの [概要] ページが表示されます。
-
クエリを実行するデータベースの名前を選択します。
Google Cloud コンソールにデータベースの [概要] ページが表示されます。
- サイドメニューで、[Spanner Studio] をクリックします。
Google Cloud コンソールにデータベースの [Spanner Studio] ページが表示されます。
- エディタペインで SQL クエリを入力します。
- [実行] をクリックします。
Spanner がクエリを実行します。
- [説明] タブをクリックして、クエリプランの可視化を表示します。
クエリエディタのツアー
[Spanner Studio] ページには、SQL クエリと DML ステートメントを入力または貼り付け、データベースに対して実行し、それらの結果とクエリ実行プランを表示できるクエリタブがあります。次のスクリーンショットでは、[Spanner Studio] ページの主要なコンポーネントに番号が付けられています。
- タブバーには、開いているクエリタブが表示されます。新しいタブを作成するには、[新しいタブ] をクリックします。
タブバーにはクエリ テンプレートの一覧も表示され、データベース クエリ、トランザクション、読み取りなどに関する分析情報を提供するクエリを貼り付けるときに使用できます。詳しくは、イントロスペクション ツールの概要を参照ください。
- エディタ コマンドバーには、次のオプションがあります。
- [実行] コマンドは、編集ペインに入力されたステートメントを実行して、[結果] タブにクエリ結果を生成し、[説明] タブにクエリ実行プランを生成します。デフォルトの動作は、プルダウンを使用して [結果のみ] または [説明のみ] を生成するように変更します。
エディタでハイライト表示すると、[実行] コマンドが [選択項目を実行] に変更され、選択した内容だけを実行できるようになります。
- [Clear query] コマンドは、エディタ内のすべてのテキストを削除し、[結果] と [説明] サブタブをクリアします。
- [Format query] コマンドにより、読みやすくするために、Query Editor でステートメントがフォーマットされます。
- [Shortcuts] コマンドにより、エディタで使用できる一連のキーボード ショートカットが表示されます。
- [SQL クエリのヘルプ] リンクにより、ブラウザタブが開き、SQL クエリ構文に関するドキュメントが表示されます。
クエリは、エディタで更新されるたびに自動的に検証されます。ステートメントが有効な場合は、エディタ コマンドバーに確認のチェックマークと「有効」というメッセージが表示されます。問題がある場合は、詳細を示すエラー メッセージが表示されます。
- [実行] コマンドは、編集ペインに入力されたステートメントを実行して、[結果] タブにクエリ結果を生成し、[説明] タブにクエリ実行プランを生成します。デフォルトの動作は、プルダウンを使用して [結果のみ] または [説明のみ] を生成するように変更します。
- エディタに SQL クエリと DML ステートメントを入力します。複数行ステートメントの場合、これらは色分けされ、行番号が自動的に追加されます。
エディタに複数のステートメントを入力する場合は、最後のステートメントを除く各ステートメントの後に終了セミコロンを使用する必要があります。
- クエリタブの下部ペインには、3 つのサブタブがあります。
- [スキーマ] サブタブには、データベース内のテーブルとそのスキーマが表示されます。エディタでステートメントを作成する場合のクイック リファレンスとして使用してください。
- [結果] サブタブには、エディタでステートメントを実行した結果が表示されます。結果テーブルおよび
INSERTや >UPDATEなどの DML ステートメントを表示するクエリの場合、影響を受ける行の数を示すメッセージが表示されます。 - [説明] サブタブには、エディタでステートメントを実行するときに作成されるクエリプランの視覚的なグラフが表示されます。
- [結果] と [説明] のサブタブのどちらにも、表示するステートメントの結果やクエリプランを選択するために使用するステートメント セレクタが用意されています。
サンプリングされたクエリプランを表示する
- Google Cloud コンソールの [Spanner インスタンス] ページに移動します。
-
調査するクエリを含むインスタンスの名前をクリックします。
Google Cloud コンソールにインスタンスの [概要] ページが表示されます。
-
[ナビゲーション] メニューの [オブザーバビリティ] という見出しの下にある [Query Insights] をクリックします。
Google Cloud コンソールにインスタンスの [Query Insights] ページが表示されます。
-
[データベース] プルダウン メニューで、調査するクエリを含むデータベースを選択します。
Google Cloud コンソールに、データベースのクエリ読み込み情報が表示されます。TopN クエリとタグのテーブルには、CPU 使用率で並べ替えられた上位のクエリとリクエストタグのリストが表示されます。
-
サンプリングされたクエリプランを表示する CPU 使用率の高いクエリを探します。そのクエリの [FPRINT] 値をクリックします。
[クエリの詳細] ページには、時間の経過に伴うクエリのクエリプランのサンプルグラフが表示されます。現在の時刻の最大 7 日前までズームアウトできます。注: クエリプランは、PartitionQuery API およびパーティション化 DML クエリから取得したパーティション トークンを使用するクエリではサポートされません。
-
グラフ内のドットのいずれかをクリックすると、古いクエリプランが表示され、クエリの実行中に実行されたステップが可視化されます。演算子をクリックすると、演算子の詳細情報が表示されます。
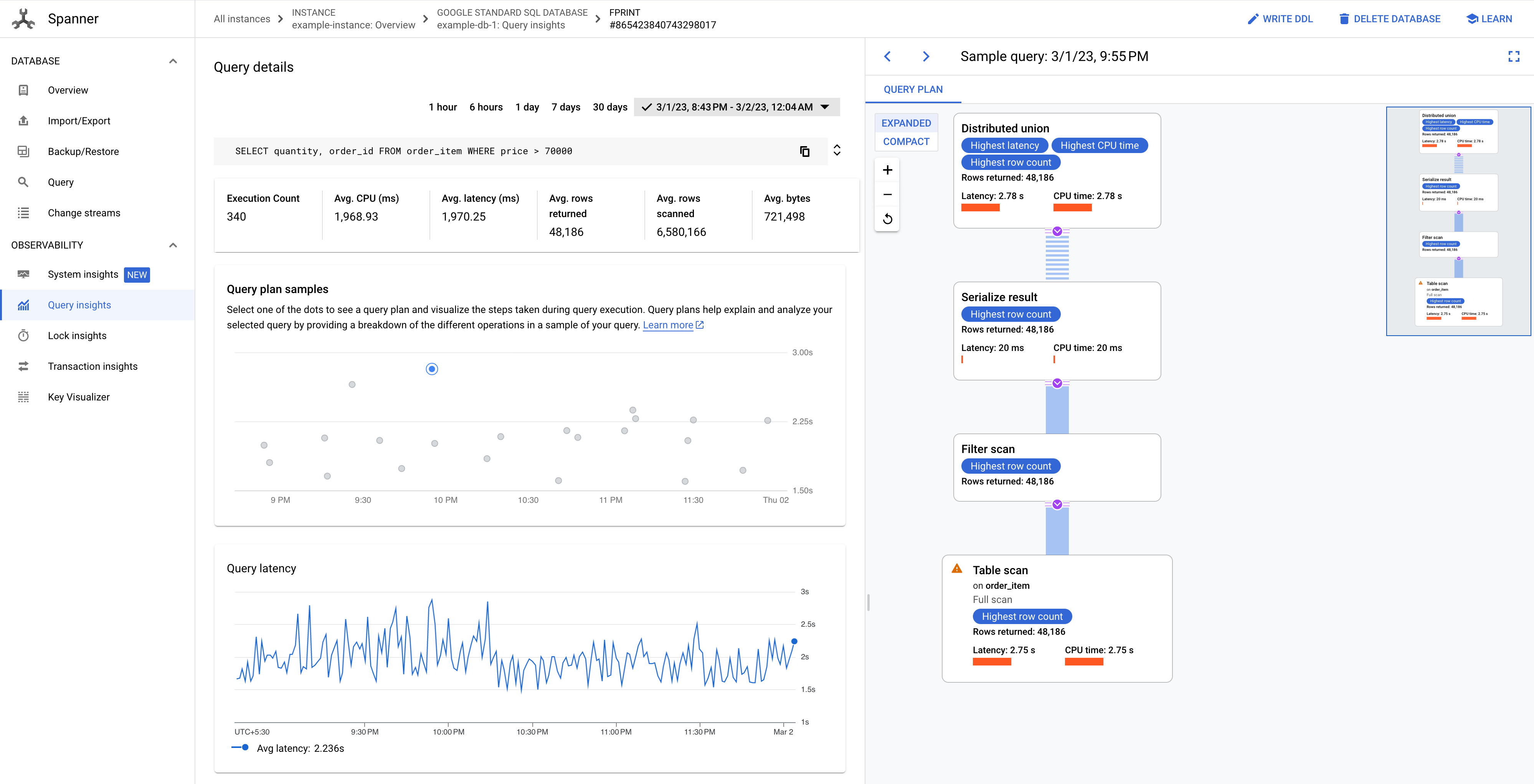
図 8. クエリプランのグラフの例。
場合によっては、サンプリングされたクエリプランを表示して、クエリのパフォーマンスの推移を時間推移とともに比較することもできます。CPU の消費量が多いクエリの場合、Spanner ではサンプリングされたクエリプランは Google Cloud コンソールの [Query insights] ページに 30 日間保持されます。サンプリングされたクエリプランを表示するには:
クエリプラン ビジュアライザのツアーを見る
次のスクリーンショットでは、ビジュアライザの主要なコンポーネントにアノテーションが付けられ、さらに説明されています。クエリタブでクエリを実行した後、クエリエディタの下にある [説明] タブを選択してクエリ実行プラン ビジュアライザを開きます。
次の図のデータフローはボトムアップです。つまり、すべてのテーブルとインデックスが図の一番下に表示され、最終出力が一番上になります。
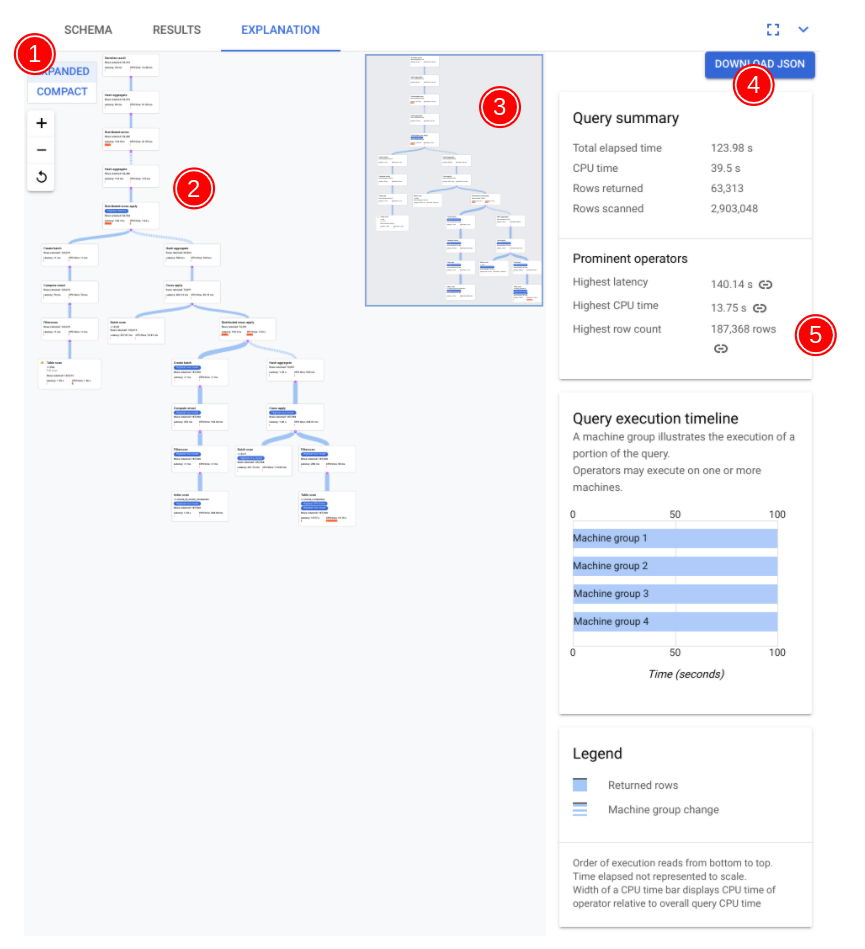
- 実行したクエリによっては、プランの可視化のサイズが大きくなる場合があります。詳細の表示と非表示を切り替えるには、[展開] / [最小] 表示セレクタを切り替えます。ズーム コントロールを使用すると、表示するプランのサイズをいつでもカスタマイズできます。
- Spanner によるクエリの実行方法を表す代数的論理が、非巡回グラフとして描画されます。このグラフの各ノードは、入力から行を取り込み、親に行を生成するイテレータに対応します。プランの例を図 9 に示します。図をクリックすると、プランの詳細の一部が拡大表示されます。
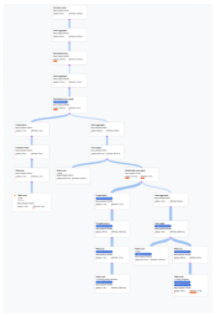
図 9. ビジュアル プランのサンプル(クリックして拡大)。 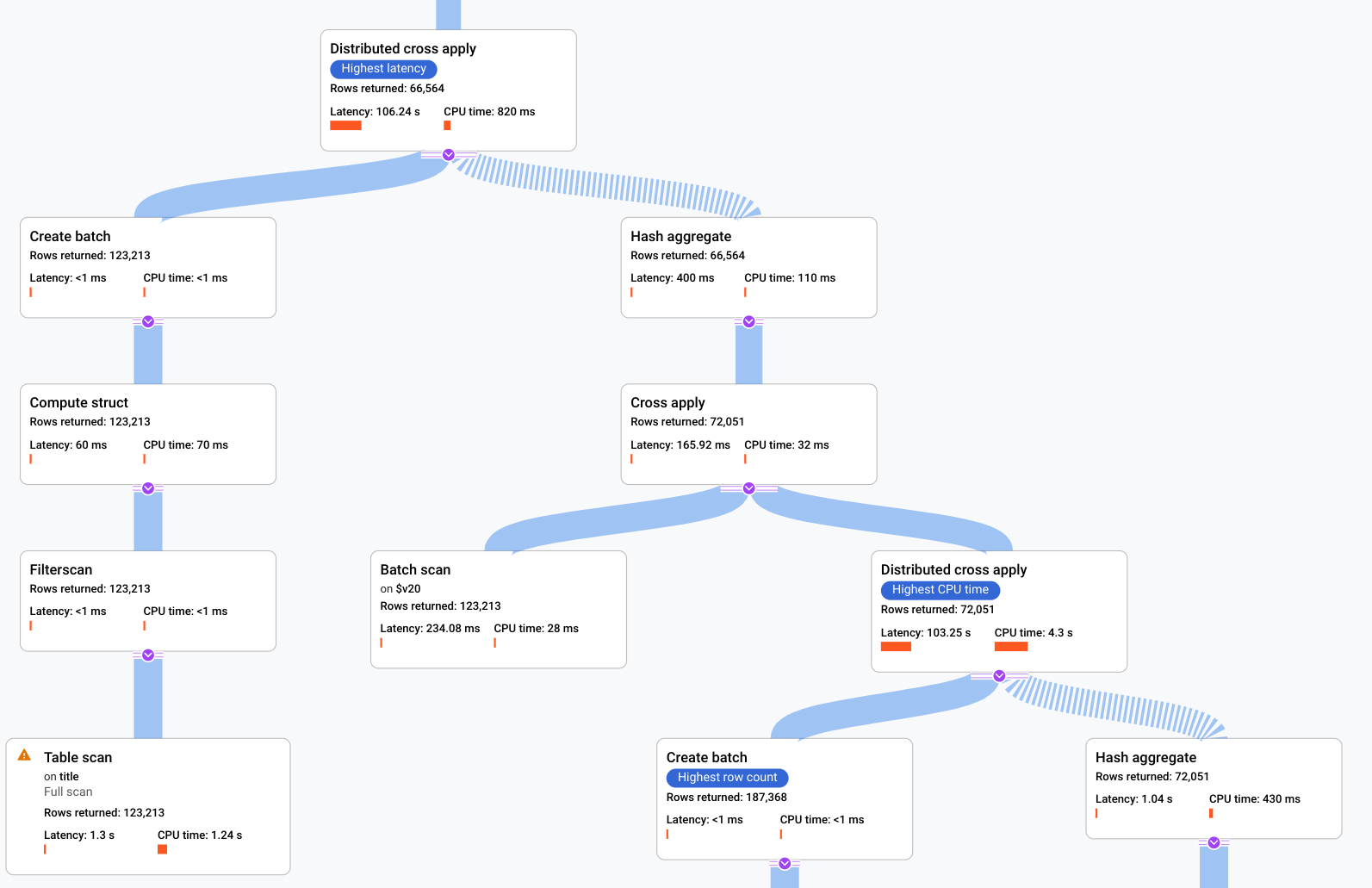
グラフの各ノード(カード)はイテレータを表し、次の情報が含まれます。
- イテレータ名。イテレータは、入力から行を取り込み、行を生成します。
- ランタイム統計情報には、返された行数、レイテンシ、CPU 使用量が表示されます。
- クエリ実行プランの潜在的な問題を特定できるように、次の視覚的な手がかりが用意されています。
- ノード内の赤いバーは、クエリ全体の合計値と比較した、このイテレータのレイテンシまたは CPU 時間の割合を示す視覚的なインジケーターです。
- 各ノードを接続する線の太さは、行数を表します。線が太いほど、次のノードに渡される行数が多くなります。コネクタの上にポインタを置くと、実際の行数が各カードに表示されます。
- テーブル全体のスキャンが実行されたノードに警告を示す三角形が表示されます。情報パネルの詳細には、インデックスを追加する、フルスキャンを避けるために可能であれば他の方法でクエリやスキーマを修正するなどの推奨事項が含まれます。
- プラン内のカードを選択すると、右側の情報パネル(5)に詳細が表示されます。
- 実行プランのミニマップには、プラン全体の縮小ビューが表示されます。これは、実行プラン全体の形状を判断したり、プラン内の他の箇所にすばやく移動したりする場合に便利です。ビジュアル プランの他の箇所に移動するには、ミニマップ上で直接ドラッグするか、フォーカスしたい場所をクリックします。
[JSON をダウンロード] を選択すると、トラブルシューティングに役立つ JSON 形式の実行プランをダウンロードできます。 Spanner チームに連絡してサポートを受ける場合に、このファイルを共有することもできます。 JSON を保存しても、クエリの結果は保存されません。
JSON 形式の実行プランをダウンロードして保存し、後で可視化するには:
- Spanner Studio でクエリを実行します。
- [説明] タブを選択します。
- [JSON をダウンロード] をクリックして、JSON 形式の実行プランをダウンロードします。
- JSON ファイルの内容を保存してコピーします。
- 新しいクエリエディタのタブを開きます。
- エディタタブに次のように入力します。
PROTO: CONTENT_OF_JSON
- [実行] をクリックします。
- クエリエディタの下にある [説明] タブを選択すると、ダウンロードした実行プランが視覚的に表示されます。
- 情報パネルには、クエリプランの図で選択したノードに関する詳細なコンテキスト情報が表示されます。情報は次のカテゴリに分類されます。
- [イテレータ情報] には、グラフで選択したイテレータ カードに関する詳細とランタイム統計情報が表示されます。
- [クエリサマリー] には、返された行数とクエリの実行に要した時間に関する詳細情報が表示されます。[主な演算子] は、レイテンシ、他の演算子に比べた CPU 消費量、返されたデータ行数が非常に大きい演算子を表します。
- [クエリ実行タイムライン] は、クエリにおける各マシングループの実行時間の割合を示す時間ベースのグラフです。マシングループは、クエリの実行時間全体を通して実行中であるとは限りません。また、クエリの実行中にマシングループが複数回実行される可能性もありますが、このタイムラインには、最初の実行の開始時刻と最後の実行の終了時刻のみが表示されます。
パフォーマンスが低いクエリのチューニング
あなたの会社で、オンライン映画データベースを運営しているとします。そのデータベースには、キャスト、制作会社、映画の詳細などの映画に関する情報が含まれます。サービスは Spanner で実行されますが、最近いくつかのパフォーマンスの問題が生じています。
あなたはサービスのリード デベロッパーとして、これらのパフォーマンスの問題を調査するよう求められています。これらの問題がサービスの評価を低下させているためです。 Google Cloud コンソールを開き、データベース インスタンスに移動して、クエリエディタを開きます。次のクエリをエディタに入力して実行します。
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
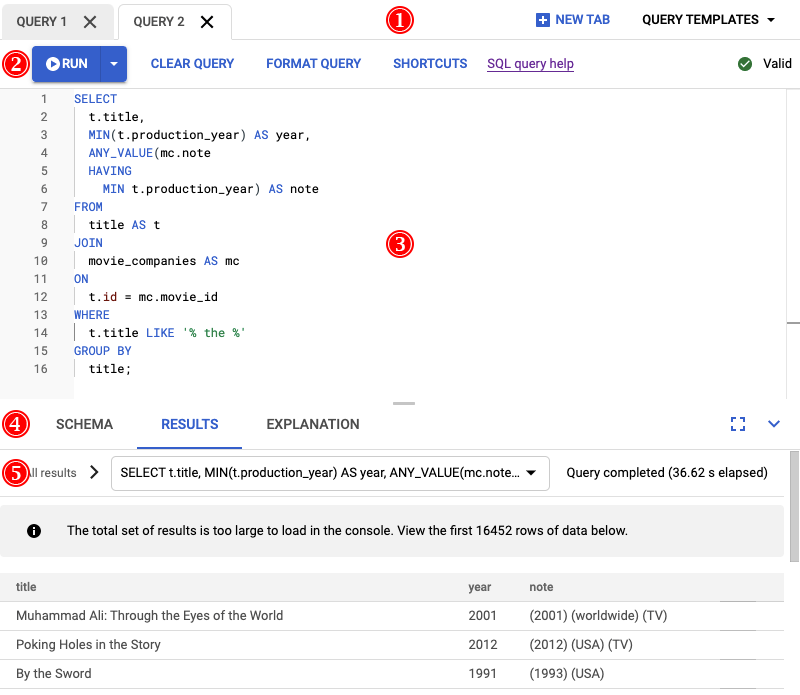
このクエリの実行結果は、次のスクリーンショットに表示されます。クエリエディタで [FORMAT QUERY] を選択してクエリの形式を整えました。画面の右上にも、クエリが有効であることの通知が表示されます。
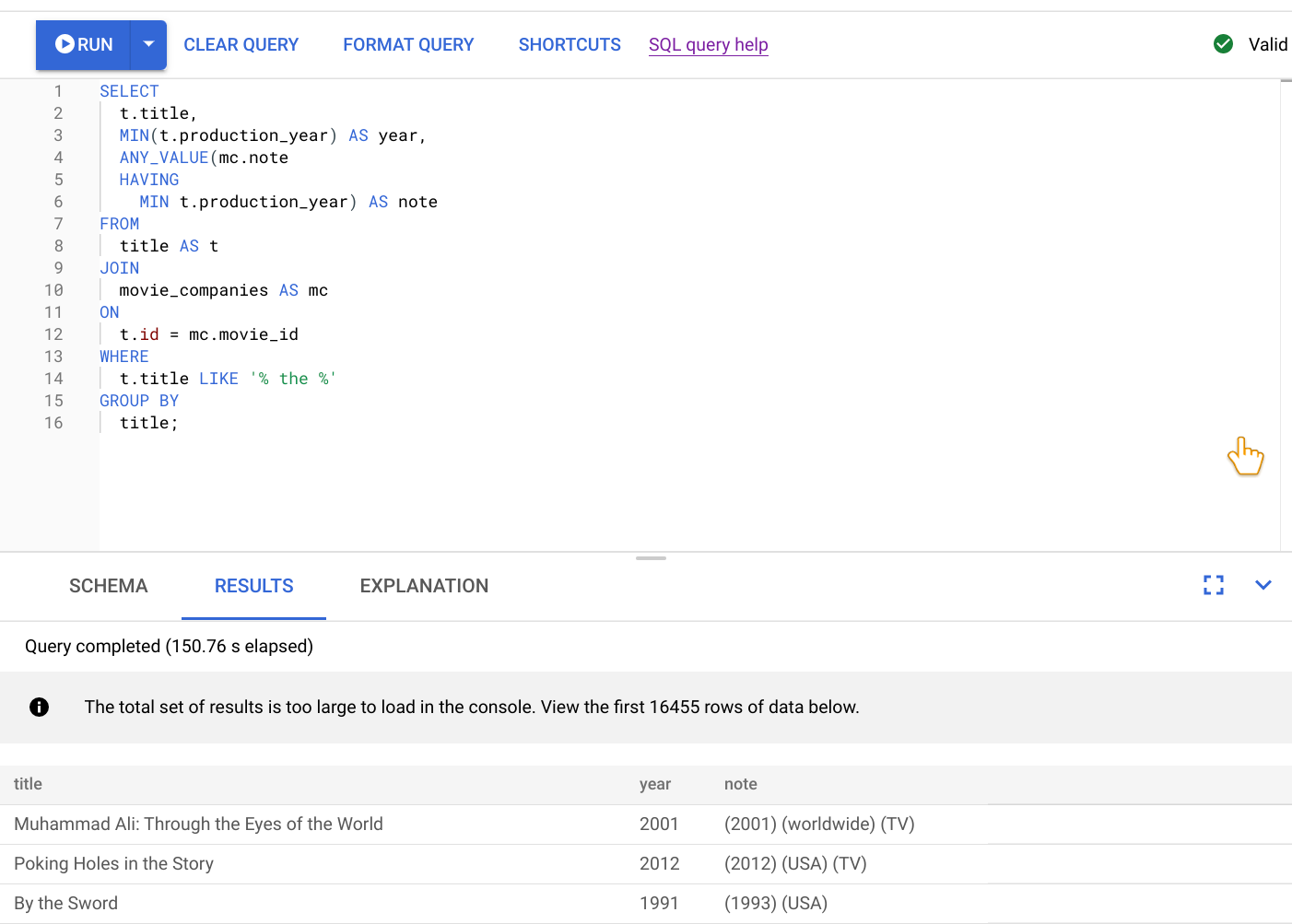
クエリエディタの下にある [結果] タブに、クエリが 2 分で完了したことが示されています。クエリを詳しく調べることで、クエリが効率的かどうかを確認します。
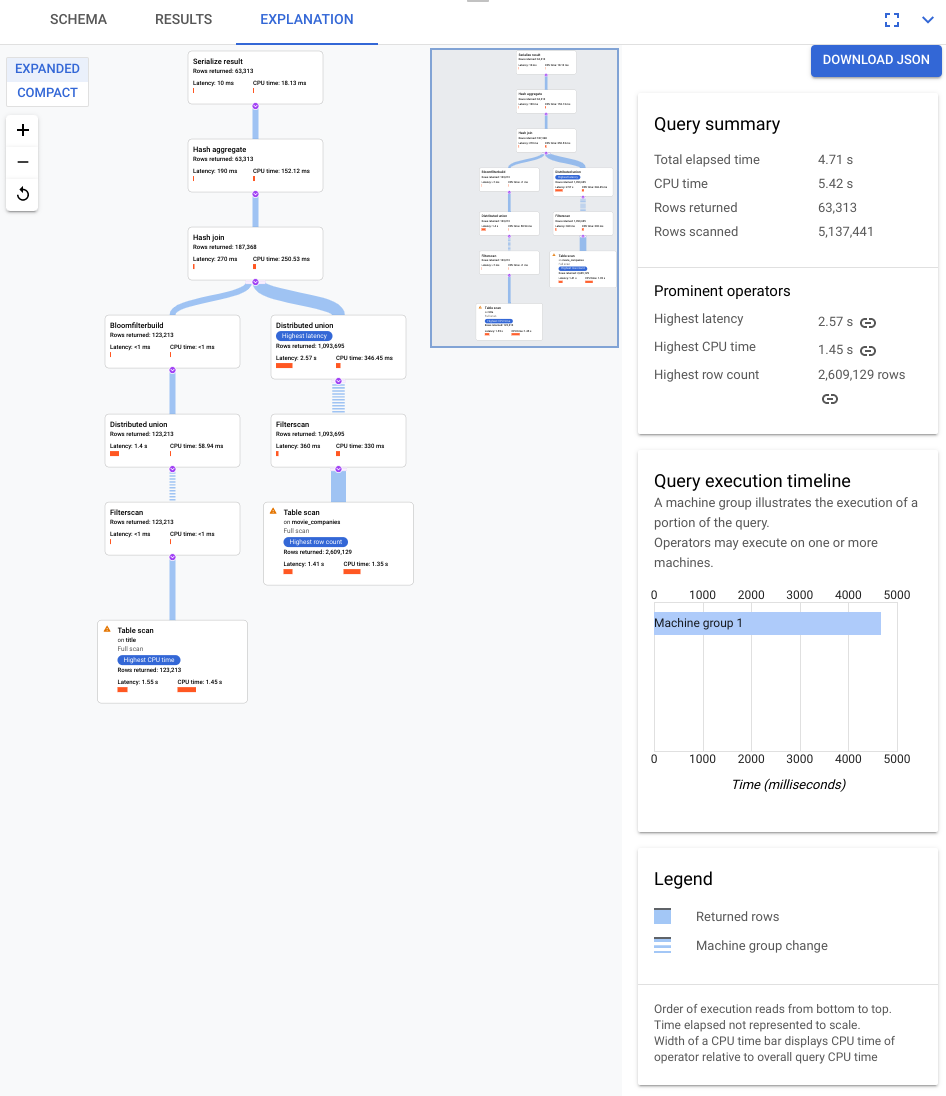
クエリプラン ビジュアライザで速度の遅いクエリを分析する
この時点では、前のステップのクエリが 2 分以上かかることは確認できたものの、クエリが十分に効率的かどうか、つまりこの時間が想定どおりであるかどうかは不明です。
クエリエディタのすぐ下にある [説明] タブを選択すると、クエリを実行して結果を返すために Spanner によって作成された実行プランが視覚的に表示されます。
次のスクリーンショットに示すプランは比較的大きなものですが、このズームレベルでも、次のようなことがわかります。
右側の情報パネルの [クエリの概要] に基づいて、約 300 万行がスキャンされ、最終的に 64K 未満の結果が返されたことがわかりました。
[クエリ実行タイムライン] パネルからも、4 つのマシングループがクエリに関与していることがわかります。マシングループは、クエリの一部の実行を担当します。演算子は 1 台以上のマシンで実行される場合があります。タイムラインでマシングループを選択すると、そのグループでクエリが実行されたビジュアル プランの部分が視覚的に示されます。
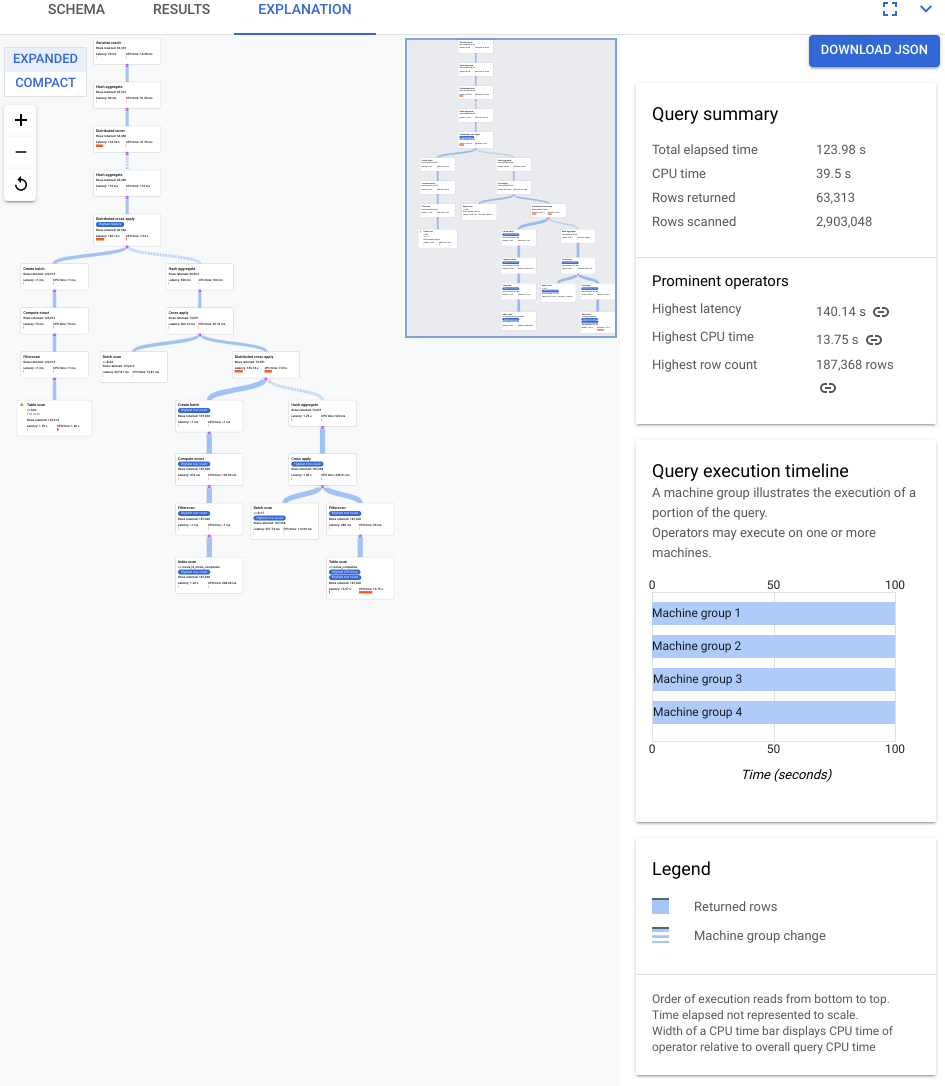
これらの要因により、Spanner がデフォルトで選択している適合結合からハッシュ結合に結合を変更することで、パフォーマンスが向上する可能性があると判断できます。
クエリを改善する
クエリのパフォーマンスを向上させるために、JOIN のヒントを使用して結合メソッドをハッシュ結合に変更します。この結合の実装では、セット単位で処理が実行されます。
更新後のクエリは次のとおりです。
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
次のスクリーンショットは、更新されたクエリを示しています。スクリーンショットに示されているように、クエリは 5 秒未満で完了し、この変更の前よりランタイムが 120 秒以上も改善されました。
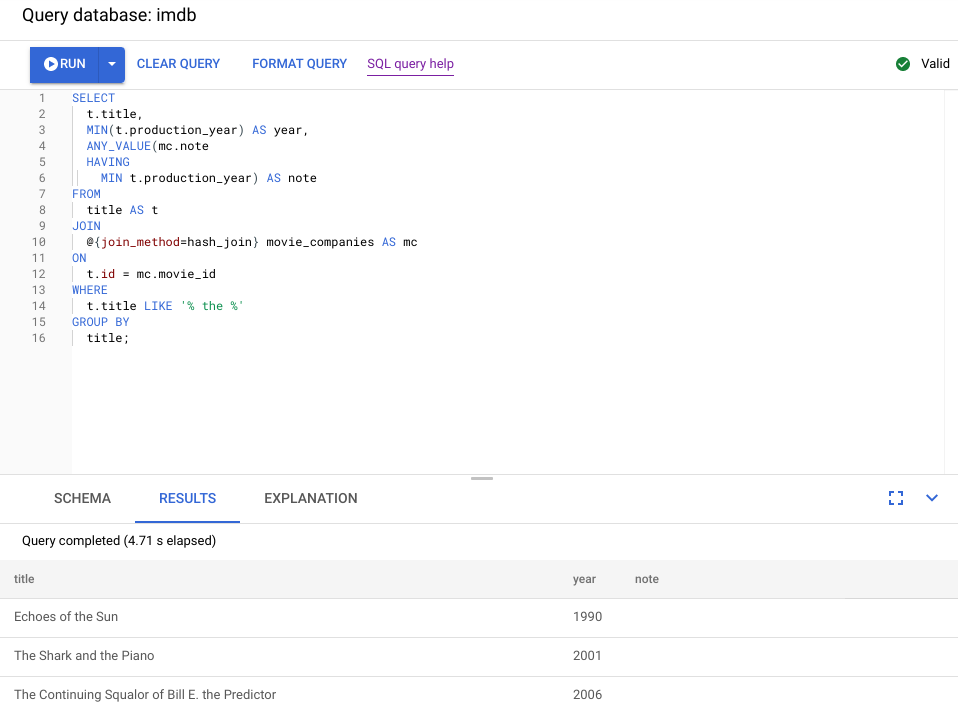
次の図に示される新しいビジュアル プランをチェックして、この改善の内容を確認します。
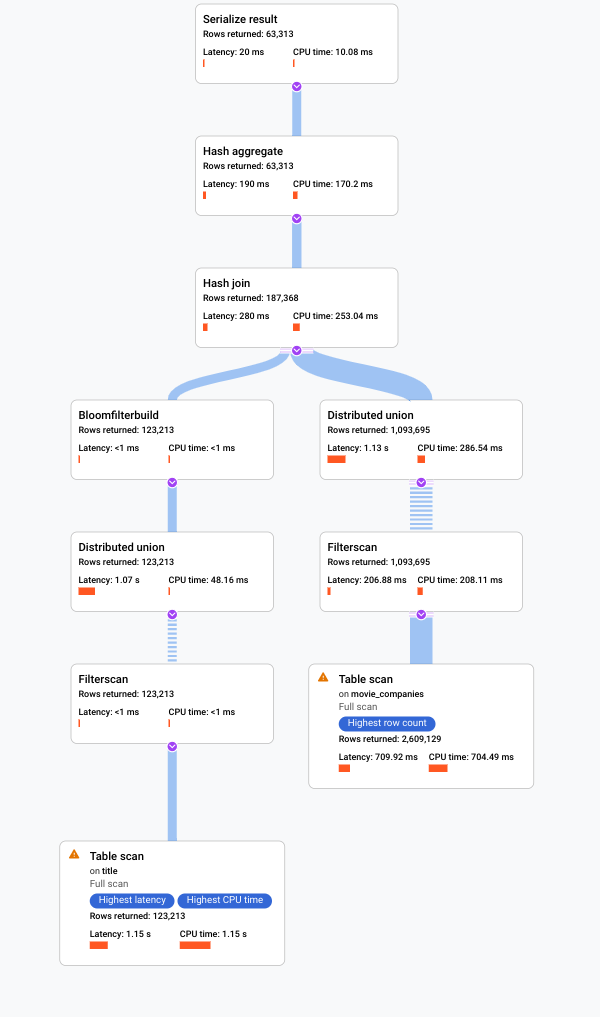
すぐに次のような違いに気がつきます。
このクエリの実行には 1 つのマシングループのみが含まれていた。
集約の数が大幅に減少した。
まとめ
このシナリオでは、実行に時間がかかるクエリを実行し、ビジュアル プランを見て、効率が悪い箇所を探しました。クエリとプランの変更前と変更後の概要を次に示します。各タブでは、実行したクエリと、クエリ実行プランの完全な可視化表現を簡潔に示します。
前
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
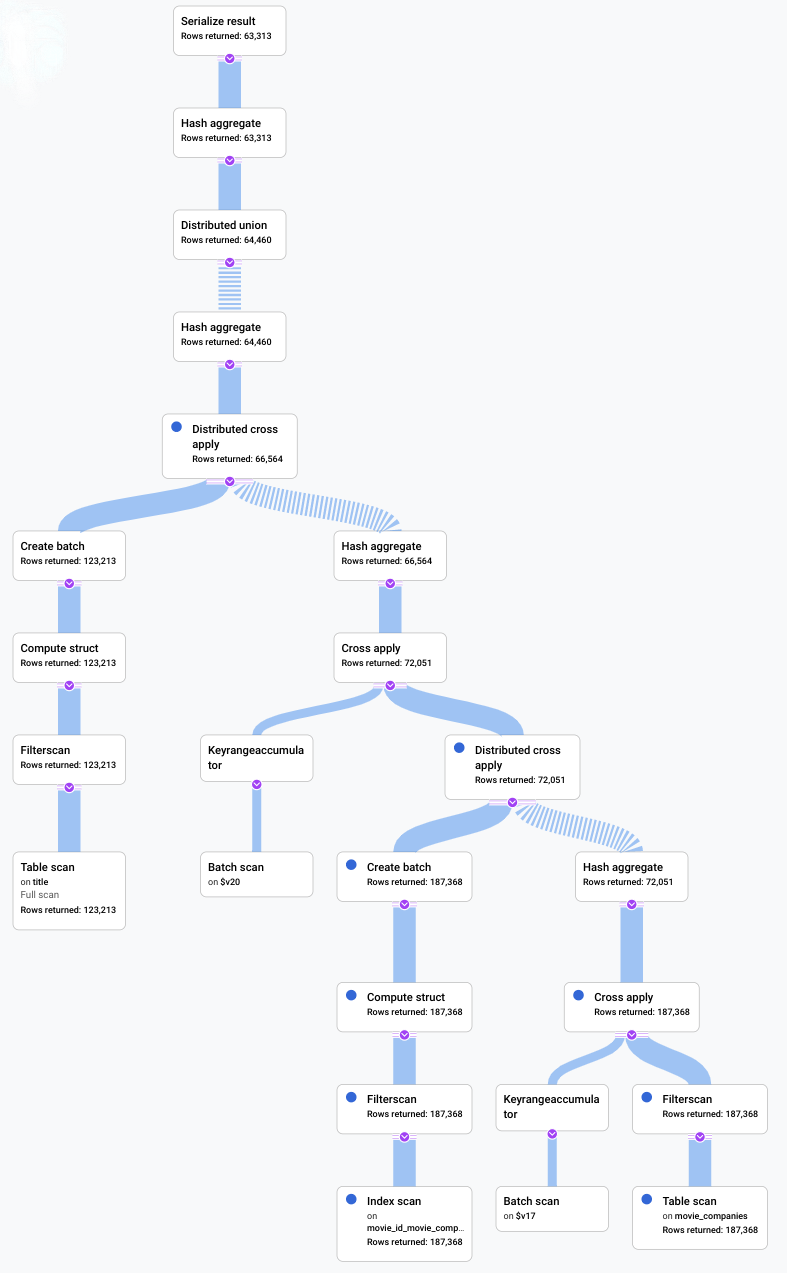
新
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
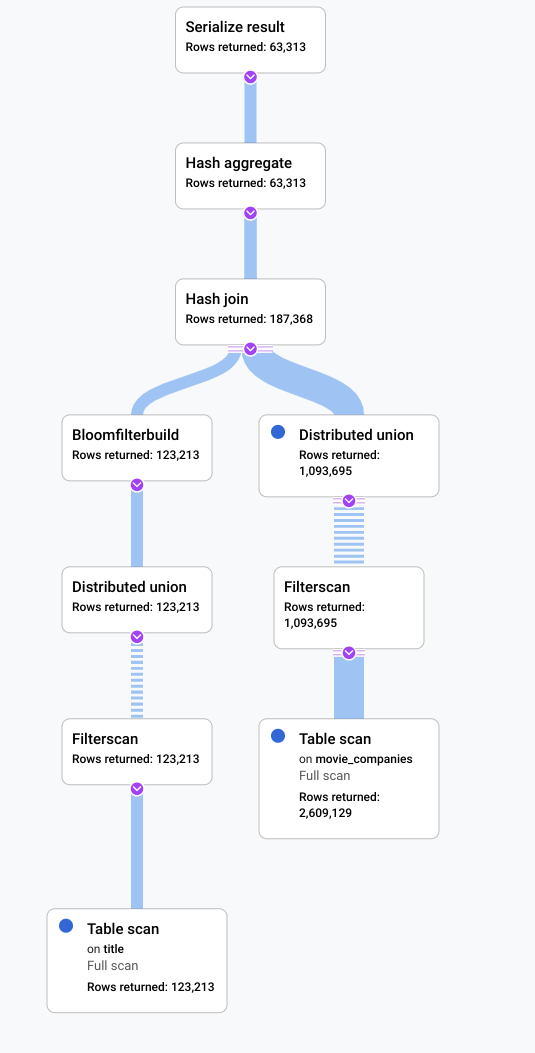
このシナリオで、改善できる箇所を示したものは、テーブル title の行の大部分がフィルタ LIKE
'% the %' に適合したことでした。行数が非常に多い別テーブルでのシークは、高コストになる可能性があります。結合の実装をハッシュ結合に変更したことで、パフォーマンスが大幅に向上しました。