L'outil de visualisation de plans de requête vous permet de comprendre rapidement la structure du plan de requête choisi par Spanner pour évaluer une requête. Ce guide explique comment utiliser un plan de requête pour comprendre l'exécution de vos requêtes.
Avant de commencer
Pour vous familiariser avec les parties de l'interface utilisateur de la console Google Cloud mentionnées dans ce guide, lisez les articles suivants :
Exécuter une requête dans la console Google Cloud
- Accédez à la page Instances de Spanner dans la console Google Cloud .
-
Sélectionnez le nom de l'instance contenant la base de données que vous souhaitez interroger.
Google Cloud Console affiche la page Présentation de l'instance.
-
Sélectionnez le nom de la base de données que vous souhaitez interroger.
La consoleGoogle Cloud affiche la page Présentation de la base de données.
-
Dans le menu latéral, cliquez sur Spanner Studio.
La consoleGoogle Cloud affiche la page Spanner Studio de la base de données.
- Saisissez la requête SQL dans le volet de l'éditeur.
-
Cliquez sur Exécuter.
Spanner exécute la requête.
- Cliquez sur l'onglet Explication pour afficher la visualisation du plan de requête.
Visite guidée de l'éditeur de requête
La page Spanner Studio fournit des onglets de requête qui vous permettent de saisir ou de coller des instructions SQL et des instructions LMD, de les exécuter sur votre base de données, et d'afficher leurs résultats ainsi que leurs plans d'exécution. Les principaux composants de la page Spanner Studio sont numérotés dans la capture d'écran suivante.
- La barre d'onglets affiche les onglets de requête que vous avez ouverts. Pour créer un onglet, cliquez sur Nouvel onglet.
La barre d'onglets fournit également une liste de modèles de requêtes que vous pouvez utiliser pour coller des requêtes fournissant des insights sur les requêtes, transactions, lectures, etc. de base de données, comme décrit dans Présentation des outils d'introspection.
- La barre de commandes de l'éditeur propose les options suivantes :
- La commande Exécuter exécute les instructions saisies dans le volet d'édition, produisant ainsi des résultats de requête dans l'onglet Résultats et des plans d'exécution de requêtes dans l'ongletExplication. Modifiez le comportement par défaut à l'aide de la liste déroulante pour produire des résultats uniquement ou des explications uniquement.
La mise en surbrillance d'un élément dans l'éditeur change la commande Exécuter en Exécuter la sélection, ce qui vous permet d'exécuter uniquement ce que vous avez sélectionné.
- La commande Effacer la requête supprime tout le texte de l'éditeur et efface les sous-onglets Résultats et Explication.
- La commande Mettre en forme la requête met en forme les instructions dans l'éditeur pour faciliter leur lecture.
- La commande Raccourcis affiche l'ensemble des raccourcis clavier que vous pouvez utiliser dans l'éditeur.
- Le lien Aide sur les requêtes SQL ouvre un onglet de navigateur vers la documentation consacrée à la syntaxe des requêtes SQL.
Les requêtes sont validées automatiquement chaque fois qu'elles sont mises à jour dans l'éditeur. Si les instructions sont valides, la barre de commandes de l'éditeur affiche une coche de confirmation et le message Valide. En cas de problème, elle affiche un message d'erreur avec des détails.
- La commande Exécuter exécute les instructions saisies dans le volet d'édition, produisant ainsi des résultats de requête dans l'onglet Résultats et des plans d'exécution de requêtes dans l'ongletExplication. Modifiez le comportement par défaut à l'aide de la liste déroulante pour produire des résultats uniquement ou des explications uniquement.
- L'éditeur vous permet de saisir une requête SQL et des instructions LMD.
Elles sont codées par couleur et des numéros de ligne sont automatiquement ajoutés pour les instructions multilignes.
Si vous saisissez plusieurs instructions dans l'éditeur, vous devez utiliser un point-virgule final après chaque instruction, à l'exception de la dernière.
- Le volet inférieur d'un onglet de requête fournit trois sous-onglets :
- Le sous-onglet Schéma affiche les tables de la base de données et leurs schémas. Utilisez-la comme référence rapide pour rédiger des instructions dans l'éditeur.
- Le sous-onglet Résultats affiche les résultats lorsque vous exécutez les instructions saisies dans l'éditeur. Pour les requêtes, il affiche une table de résultats, et pour les instructions LMD telles que
INSERTet >UPDATE, il affiche un message indiquant le nombre de lignes concernées. - Le sous-onglet Explication affiche des représentations graphiques des plans de requête créés lorsque vous exécutez les instructions dans l'éditeur.
- Les sous-onglets Résultats et Explication fournissent tous deux un sélecteur d'instructions qui vous permet de choisir pour quelle instruction afficher les résultats ou le plan de requête de l'instruction.
Afficher les plans de requêtes échantillonnés
- Accédez à la page Instances de Spanner dans la console Google Cloud .
-
Cliquez sur le nom de l'instance contenant les requêtes que vous souhaitez examiner.
Google Cloud Console affiche la page Présentation de l'instance.
-
Dans le menu Navigation, sous l'en-tête "Observabilité", cliquez sur Insights sur les requêtes.
La consoleGoogle Cloud affiche la page Insights sur les requêtes de l'instance.
-
Dans le menu déroulant Base de données, sélectionnez la base de données contenant les requêtes que vous souhaitez examiner.
La consoleGoogle Cloud affiche les informations sur la charge des requêtes pour la base de données. Le tableau "Requêtes et tags TopN" affiche la liste des requêtes et des tags de requête les plus fréquents, triés par utilisation du processeur.
-
Recherchez la requête à forte utilisation du processeur pour laquelle vous souhaitez afficher des plans de requête échantillonnés. Cliquez sur la valeur FPRINT de cette requête.
La page Détails de la requête affiche un graphique Exemples de plans de requête pour votre requête au fil du temps. Vous pouvez faire un zoom arrière jusqu'à sept jours avant l'heure actuelle. Remarque : Les plans de requête ne sont pas compatibles avec les requêtes comportant des partitionTokens obtenus à partir de l'API PartitionQuery ni avec les requêtes LMD partitionné.
-
Cliquez sur l'un des points du graphique pour afficher un ancien plan de requête et visualiser les étapes effectuées lors de l'exécution de la requête. Vous pouvez également cliquer sur un opérateur pour afficher des informations détaillées à son sujet.
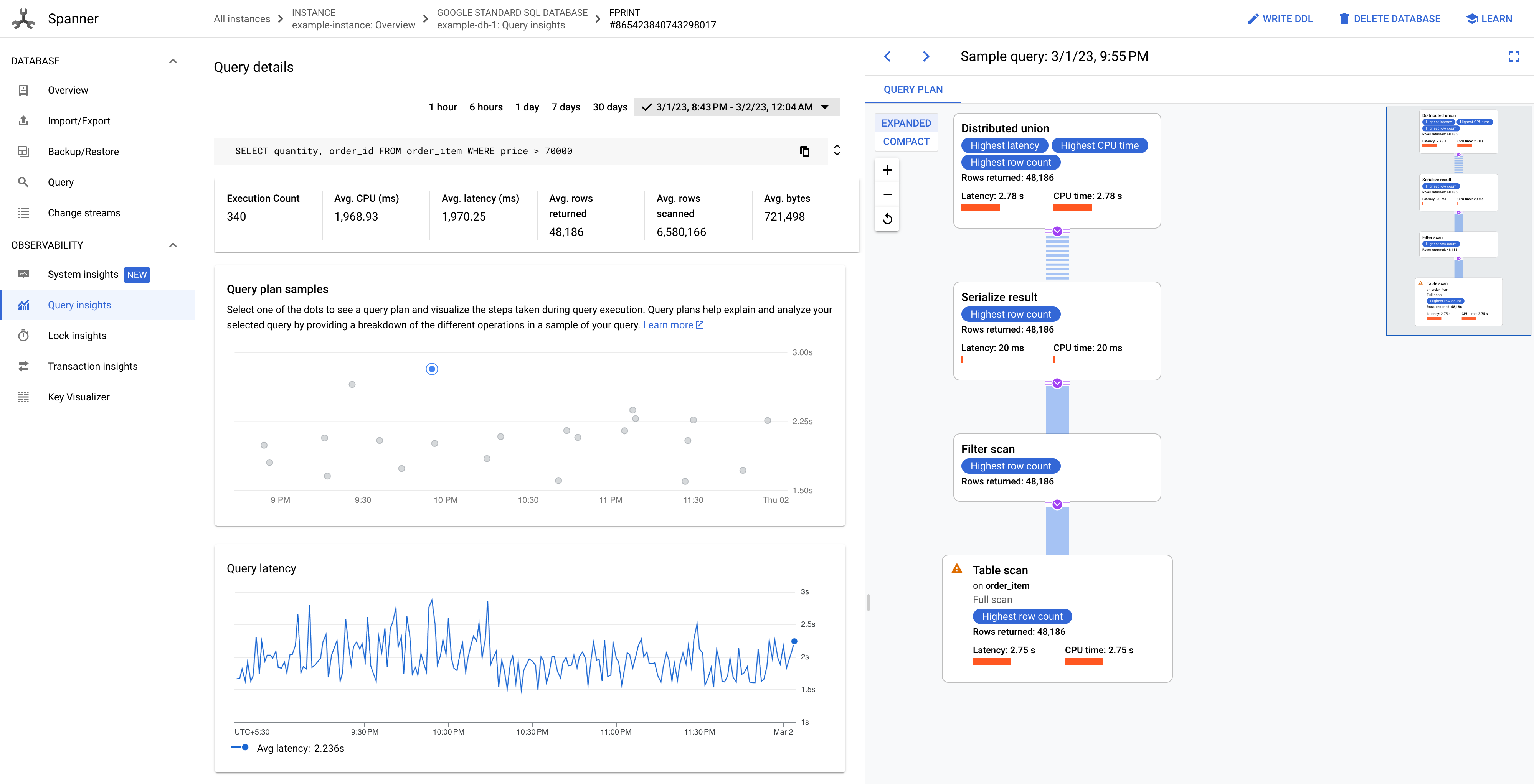
Figure 8. Graphique "Exemples de plans de requête".
Dans certains cas, vous pouvez afficher des plans de requête échantillonnés et comparer les performances d'une requête au fil du temps. Pour les requêtes qui consomment plus de CPU, Spanner conserve les plans de requête échantillonnés pendant 30 jours sur la page Insights sur les requêtes de la console Google Cloud . Pour afficher les plans de requêtes échantillonnés :
Visite guidée de l'outil de visualisation de plans de requête
Les composants clés de l'outil de visualisation sont annotés dans la capture d'écran suivante et décrits plus en détail. Après avoir exécuté une requête dans un onglet de requête, sélectionnez l'onglet Explication sous l'éditeur de requête pour ouvrir l'outil de visualisation des plans d'exécution de requêtes.
Le flux de données du schéma suivant est de bas en haut, c'est-à-dire que toutes les tables et tous les index se trouvent en bas du schéma, et la sortie finale figure en haut.
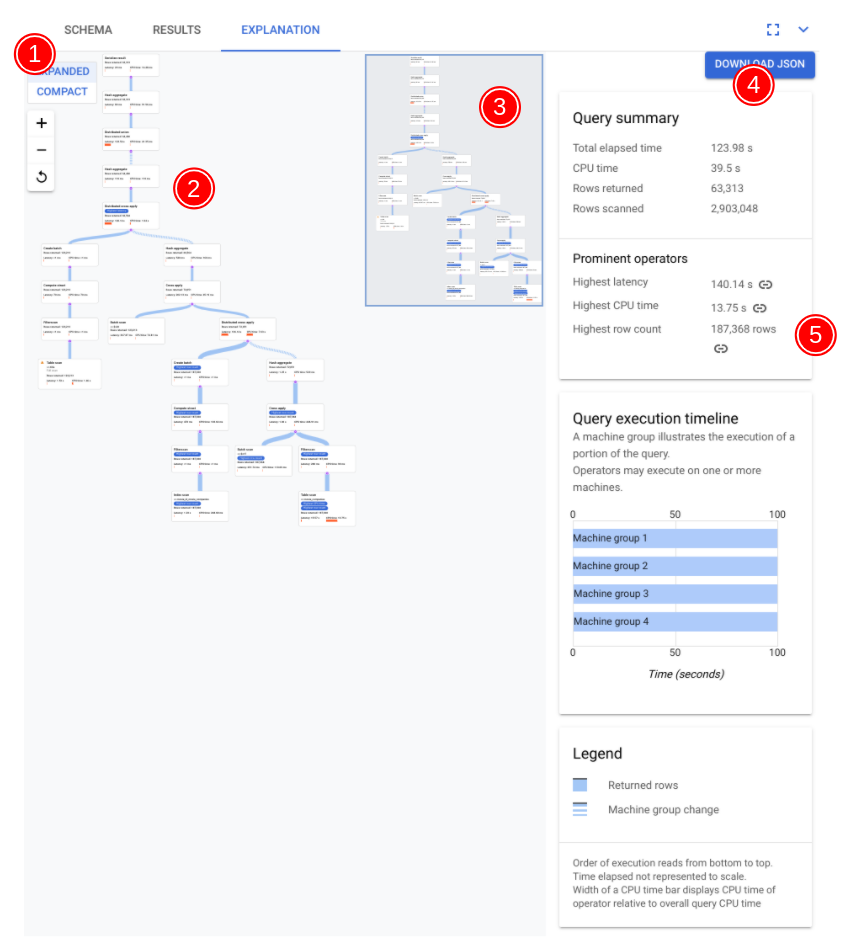
- La visualisation de votre plan peut être grande, suivant la requête que vous avez exécutée. Pour masquer ou afficher les détails, activez le sélecteur de vue DÉVELOPPÉE/COMPACTE. Vous pouvez personnaliser à tout moment la partie visible du plan à l'aide de la commande de zoom.
- L'algèbre qui explique comment Spanner exécute la requête est représentée par un graphe acyclique, où chaque nœud correspond à un itérateur qui consomme les lignes de ses entrées et produit des lignes vers son parent. La Figure 9 présente un exemple de plan. Cliquez sur le schéma pour afficher une vue développée de certains détails du plan.
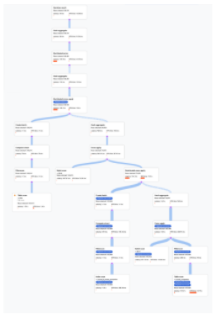
Figure 9. Exemple de plan visuel (cliquez pour zoomer). 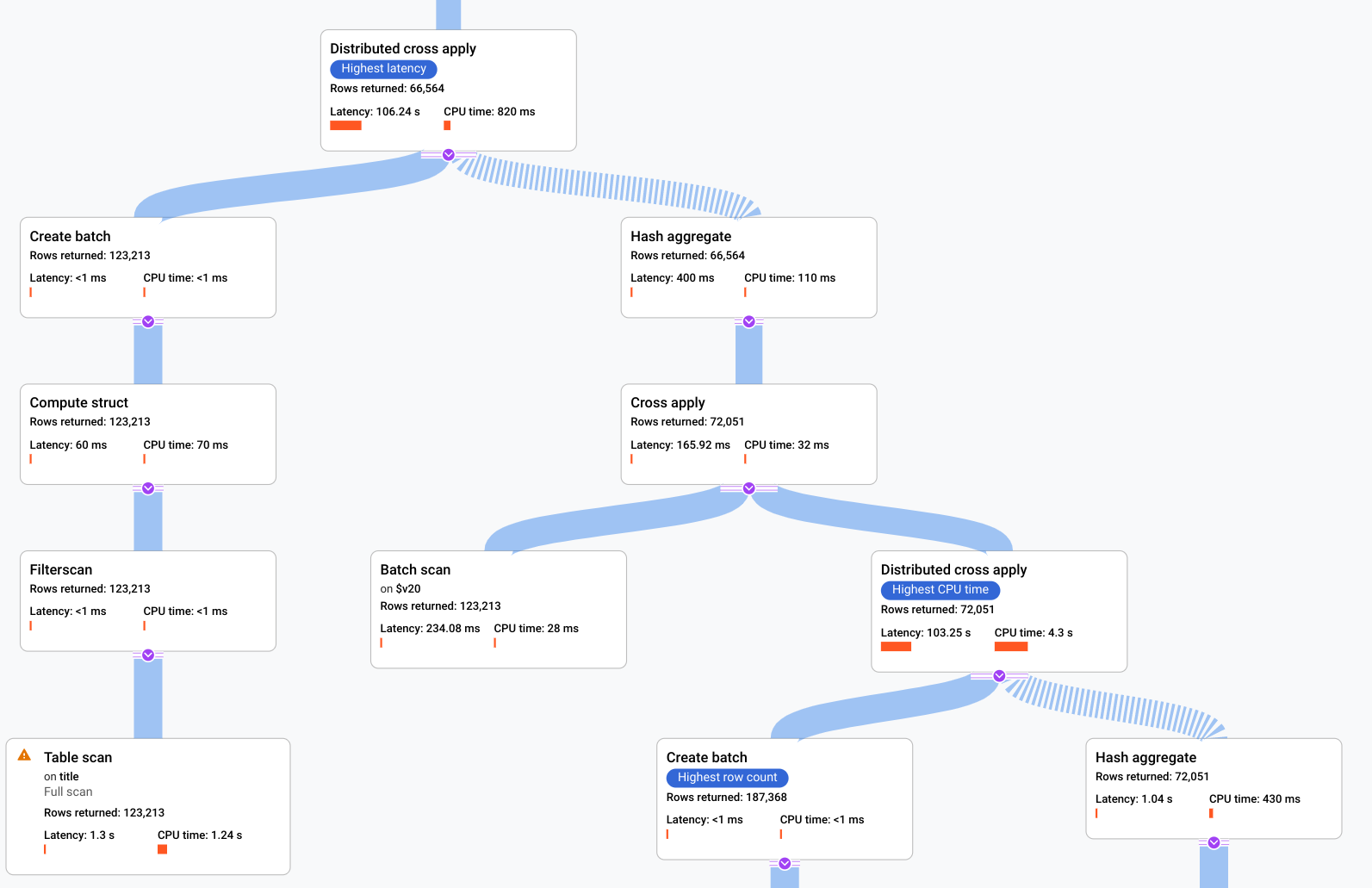
Chaque nœud, ou fiche, du graphique représente un itérateur et contient les informations suivantes :
- Le nom de l'itérateur. Un itérateur consomme les lignes de son entrée et produit des lignes.
- Des statistiques d'exécution qui vous indiquent le nombre de lignes renvoyées, la latence et la quantité de processeur consommée.
- Nous fournissons les indicateurs visuels suivants pour vous aider à identifier les problèmes potentiels dans le plan d'exécution de la requête.
- Les barres rouges dans un nœud sont des indicateurs visuels du pourcentage de latence ou de temps CPU pour cet itérateur par rapport au total de la requête.
- L'épaisseur des traits qui connectent chaque nœud représente le nombre de lignes. Plus le trait est épais, plus le nombre de lignes transmises au nœud suivant est élevé. Le nombre réel de lignes s'affiche dans chaque fiche et lorsque vous pointez sur un connecteur.
- Un triangle d'avertissement s'affiche sur un nœud au niveau duquel une analyse complète de la table a été effectuée. Le panneau d'informations fournit des détails supplémentaires, par exemple des recommandations telles que l'ajout d'un index, ou la révision de la requête ou du schéma par d'autres biais si possible afin d'éviter une analyse complète.
- Sélectionnez une fiche dans le plan pour afficher les détails dans le panneau d'informations à droite (5).
- La mini-carte du plan d'exécution montre une vue en zoom arrière du plan complet. Elle est utile pour déterminer la forme globale du plan d'exécution et pour accéder rapidement aux différentes parties du plan. Faites glisser la souris sur la mini-carte ou cliquez sur la zone à cibler pour accéder à une autre partie du plan visuel.
Sélectionnez Télécharger au format JSON pour télécharger une version JSON du plan d'exécution, ce qui est utile pour le dépannage. Vous pouvez également le partager lorsque vous contactez l'équipe Spanner pour obtenir de l'aide. L'enregistrement du fichier JSON n'enregistre pas le résultat de la requête.
Pour télécharger et enregistrer une version JSON du plan d'exécution afin de le visualiser ultérieurement :
- Dans Spanner Studio, exécutez une requête.
- Sélectionnez l'onglet Explication.
- Cliquez sur Télécharger au format JSON pour télécharger la version JSON du plan d'exécution.
- Enregistrez et copiez le contenu du fichier JSON.
- Ouvrez un nouvel onglet de l'éditeur de requête.
- Dans l'onglet de l'éditeur, saisissez :
PROTO: CONTENT_OF_JSON
- Cliquez sur Exécuter.
- Sélectionnez l'onglet Explication sous l'éditeur de requête pour afficher une représentation visuelle du plan d'exécution téléchargé.
- Le panneau d'informations affiche des informations contextuelles détaillées sur le nœud sélectionné dans le schéma du plan de requête. Les informations sont organisées suivant les catégories ci-dessous.
- Les informations sur l'itérateur fournissent des détails et des statistiques d'exécution sur la fiche d'itérateur que vous avez sélectionnée dans le graphique.
- Le récapitulatif de la requête fournit des détails sur le nombre de lignes renvoyées et le temps nécessaire à l'exécution de la requête. Les opérateurs principaux sont ceux qui présentent une latence significative, consomment une quantité de processeur importante par rapport aux autres opérateurs et renvoient un nombre élevé de lignes de données.
- La chronologie d'exécution de la requête est un graphique basé sur le temps qui indique la durée pendant laquelle chaque groupe de machines exécute sa portion de la requête. Un groupe de machines ne s'exécute pas nécessairement pour l'intégralité de la durée d'exécution de la requête. Il est également possible qu'un groupe de machines s'exécute plusieurs fois lors de l'exécution de la requête, mais la chronologie ne représente alors que le début de la première exécution et la fin de la dernière exécution.
Régler une requête qui présente de mauvaises performances
Imaginons que votre entreprise gère une base de données de films en ligne contenant des informations sur des films telles que le casting, les sociétés de production, les détails des films, etc. Le service s'exécute sur Spanner, mais depuis peu vous rencontrez certains problèmes de performances.
En tant que développeur principal de ce service, il vous est demandé d'enquêter sur ces problèmes de performances, car ils génèrent des notes médiocres pour le service. Ouvrez la console Google Cloud , accédez à votre instance de base de données, puis ouvrez l'éditeur de requête. Vous saisissez la requête suivante dans l'éditeur et vous l'exécutez.
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
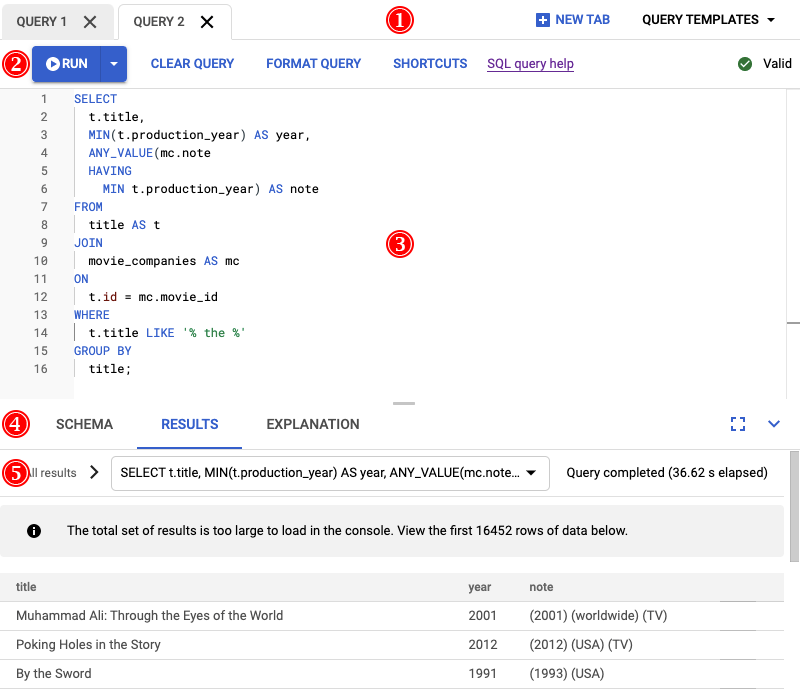
Le résultat de l'exécution de cette requête est illustré dans la capture d'écran suivante. Nous avons mis en forme la requête dans l'éditeur en sélectionnant Mettre en forme la requête. Une note en haut à droite de l'écran nous indique également que la requête est valide.
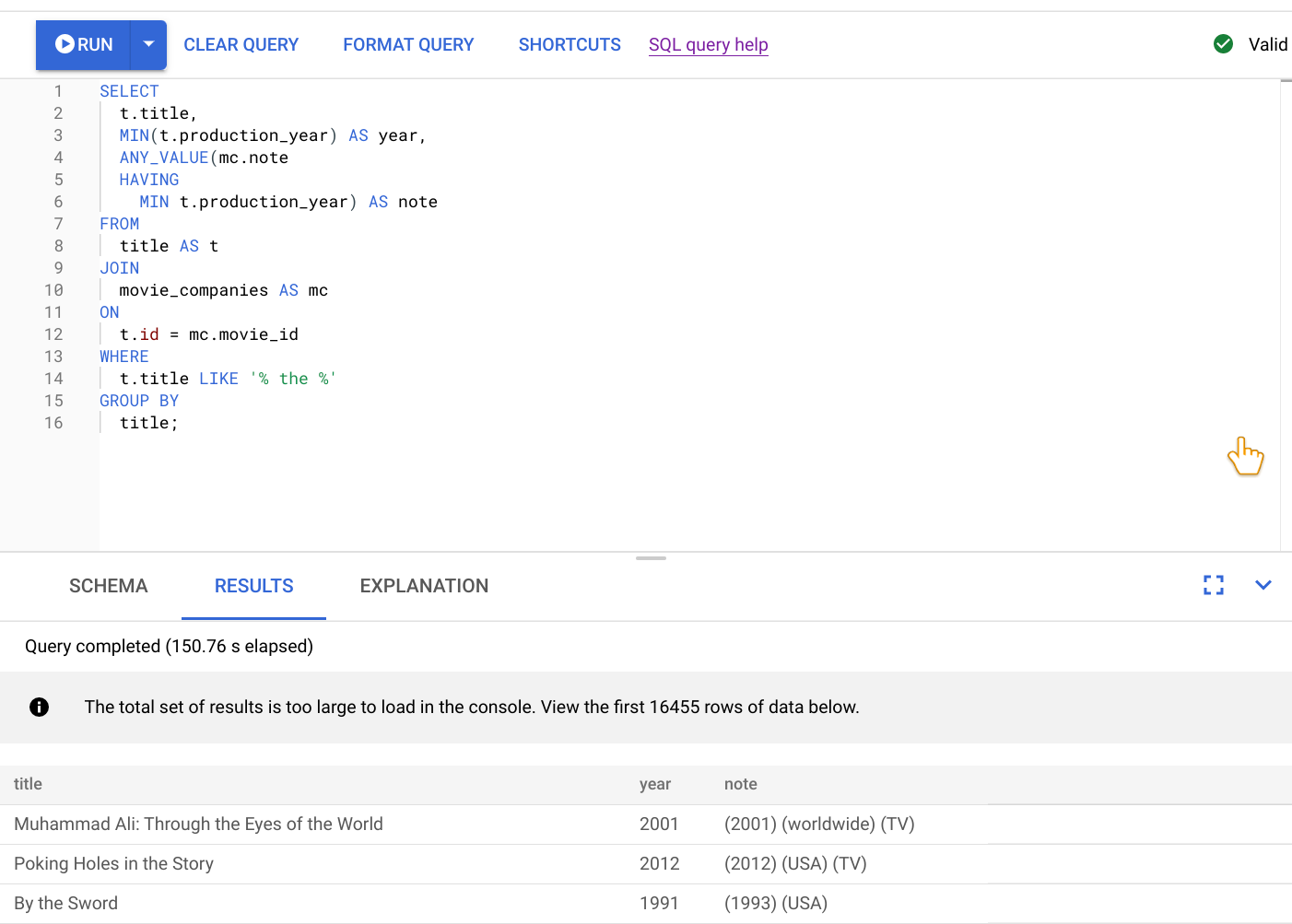
L'onglet Résultats sous l'éditeur de requête indique que la requête s'est terminée en un peu plus de deux minutes. Vous décidez d'examiner de plus près la requête pour voir si elle est efficace.
Analyser une requête lente avec l'outil de visualisation de plans de requête
À ce stade, nous savons que la requête de l'étape précédente prend plus de deux minutes, mais nous ne savons pas si elle est aussi efficace que possible et, par conséquent, si cette durée est attendue.
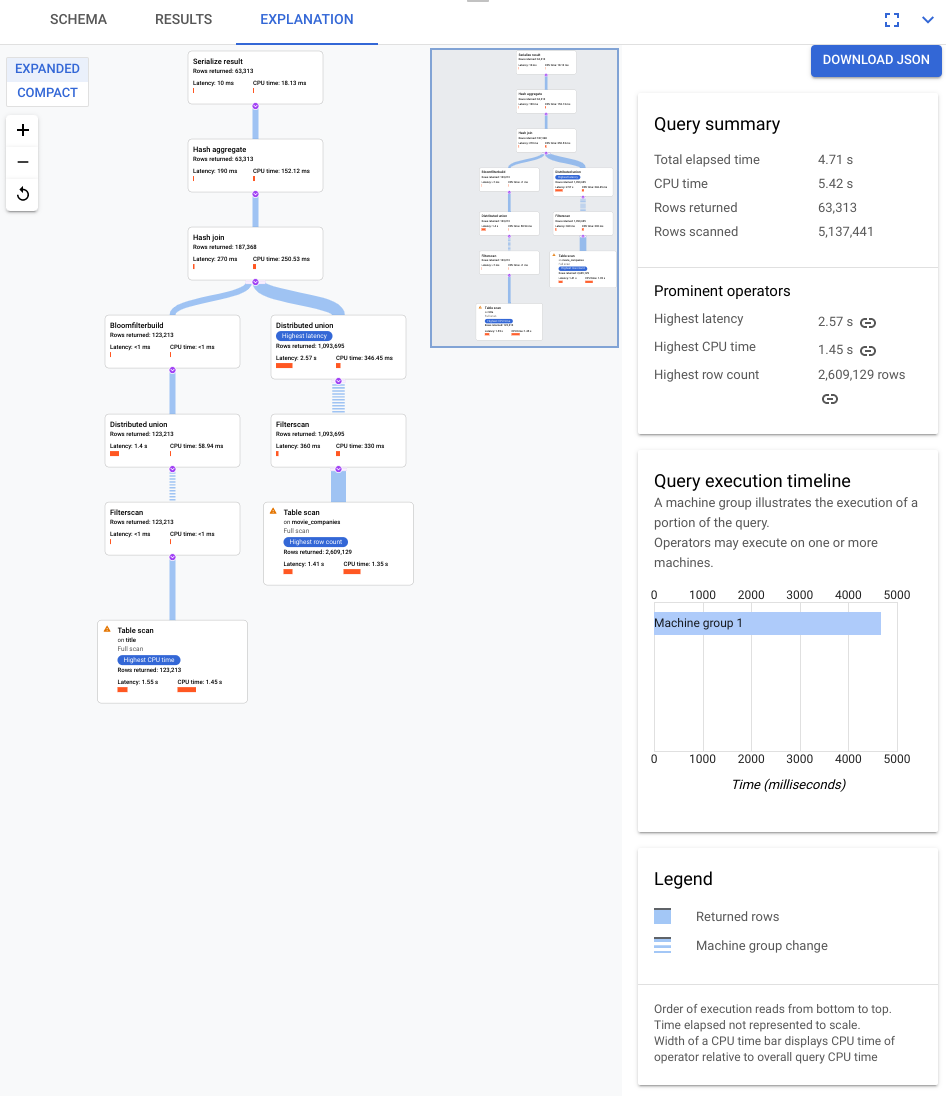
Sélectionnez l'onglet EXPLICATION juste en dessous de l'éditeur de requête pour afficher une représentation visuelle du plan d'exécution créé par Spanner pour exécuter la requête et renvoyer des résultats.
Le plan présenté dans la capture d'écran suivante est relativement volumineux mais, même à ce niveau d'agrandissement, vous pouvez effectuer les observations suivantes.
Le résumé de la requête dans le panneau d'information de droite indique que près de trois millions de lignes ont été analysées et que moins de 64 000 ont finalement été renvoyées.
Nous pouvons également voir dans le panneau Chronologie d'exécution de la requête que quatre groupes de machines ont été impliqués dans la requête. Un groupe de machines est responsable de l'exécution d'une partie de la requête. Les opérateurs peuvent s'exécuter sur une ou plusieurs machines. La sélection d'un groupe de machines dans la chronologie met en évidence dans le plan visuel quelle partie de la requête a été exécutée sur ce groupe.
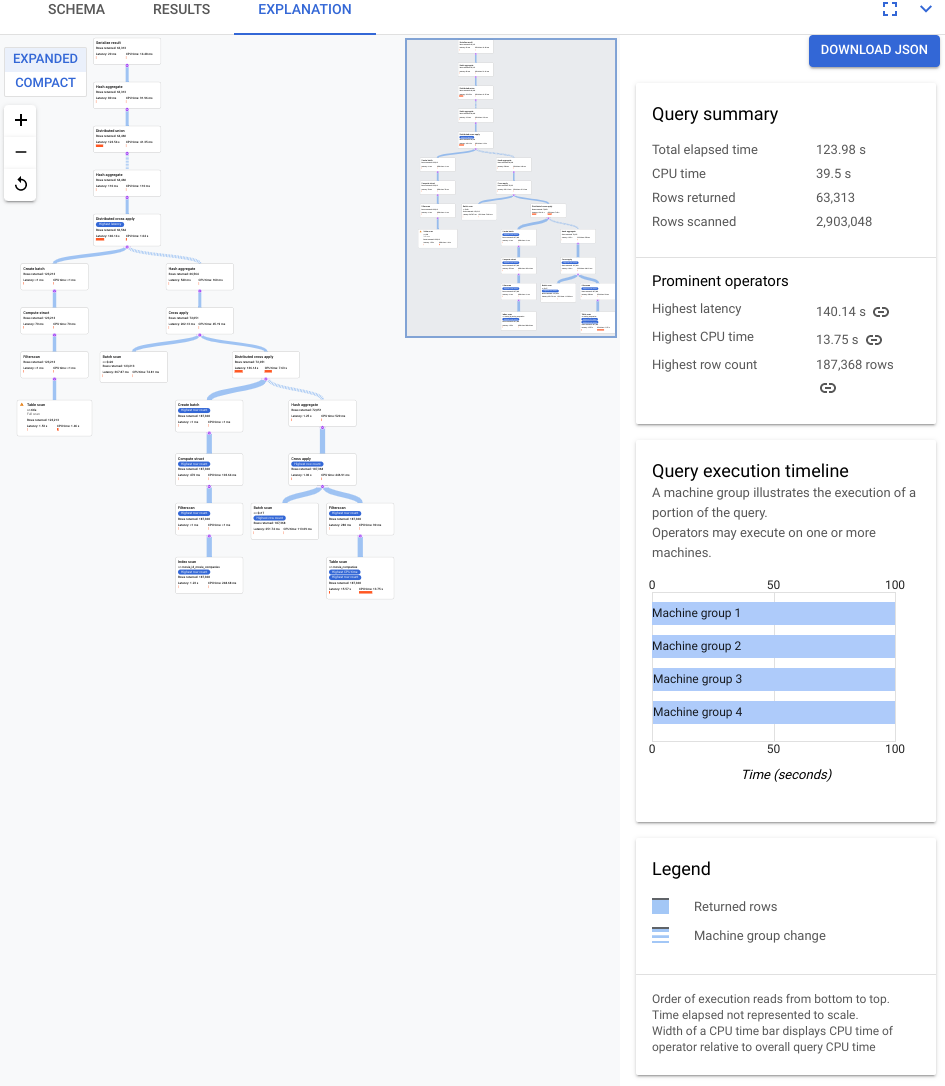
Pour ces raisons, vous décidez qu'il est possible d'améliorer les performances en remplaçant la jointure d'application, sélectionnée par défaut par Spanner, par une jointure de hachage.
Améliorer la requête
Pour améliorer les performances de la requête, vous utilisez une optimisation de jointure afin de remplacer la méthode de jointure par une jointure de hachage. Cette implémentation de jointure exécute un traitement basé sur des ensembles.
Voici la requête mise à jour :
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
La capture d'écran suivante illustre la requête mise à jour. Comme le montre la capture d'écran, la requête s'est terminée en moins de 5 secondes, soit une amélioration significative par rapport à la durée d'exécution de plus de 120 secondes avant cette modification.
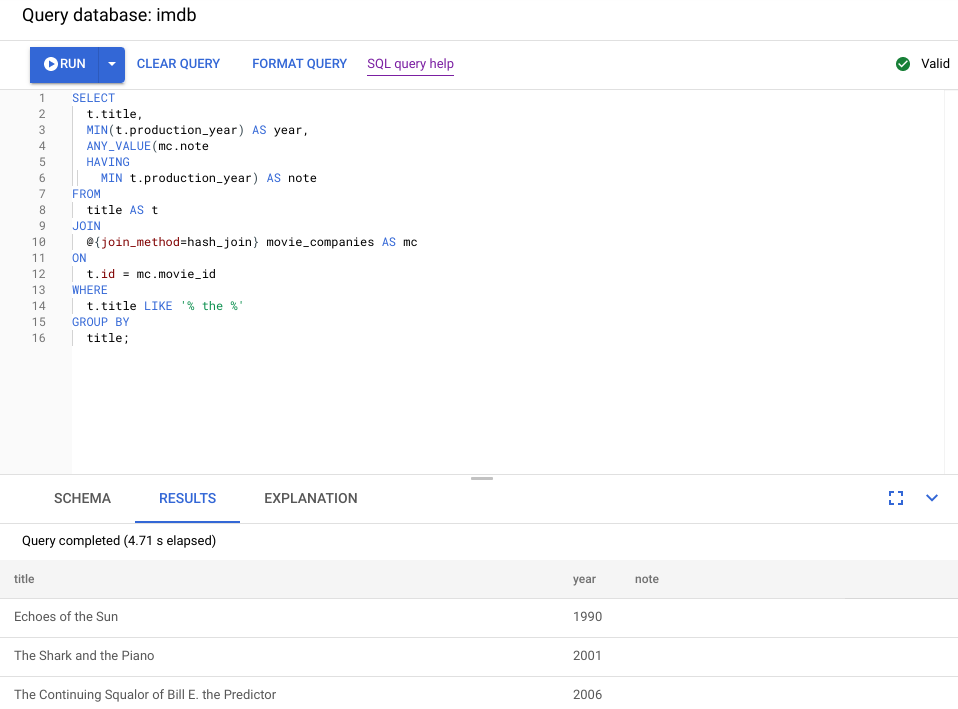
Examinons le nouveau plan visuel, illustré dans le diagramme suivant, pour découvrir ce qu'il nous apprend sur cette amélioration.
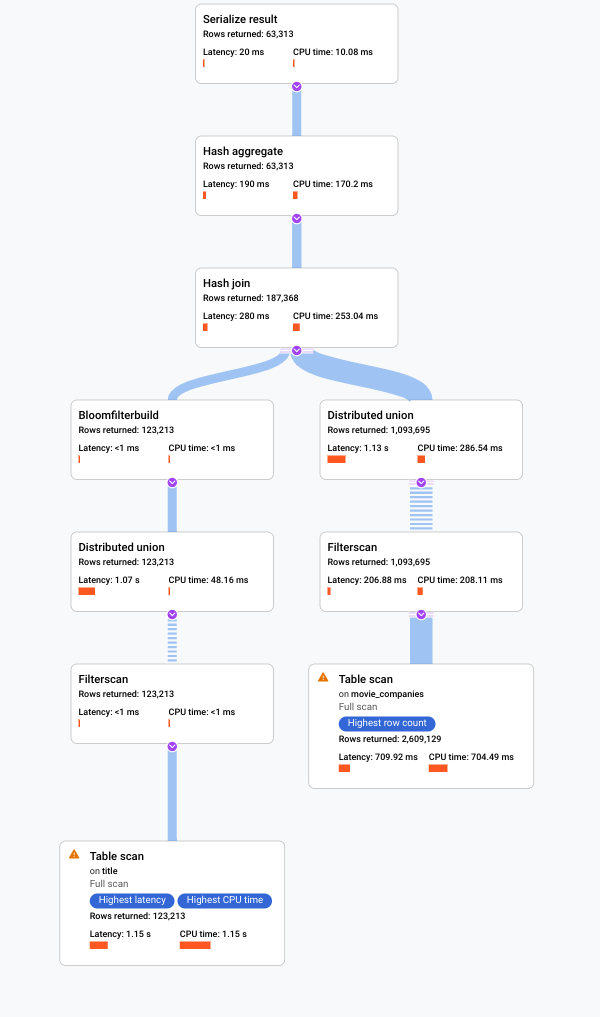
Vous remarquez immédiatement certaines différences :
Un seul groupe de machines a été impliqué dans l'exécution de cette requête.
Le nombre d'agrégations a été considérablement réduit.
Conclusion
Dans ce scénario, nous avons exécuté une requête lente et examiné son plan visuel pour rechercher des éléments inefficaces. Vous trouverez ci-dessous un récapitulatif des requêtes et des plans avant et après toute modification. Chaque onglet affiche la requête exécutée et une vue compacte de la visualisation complète du plan d'exécution de requête.
Avant
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
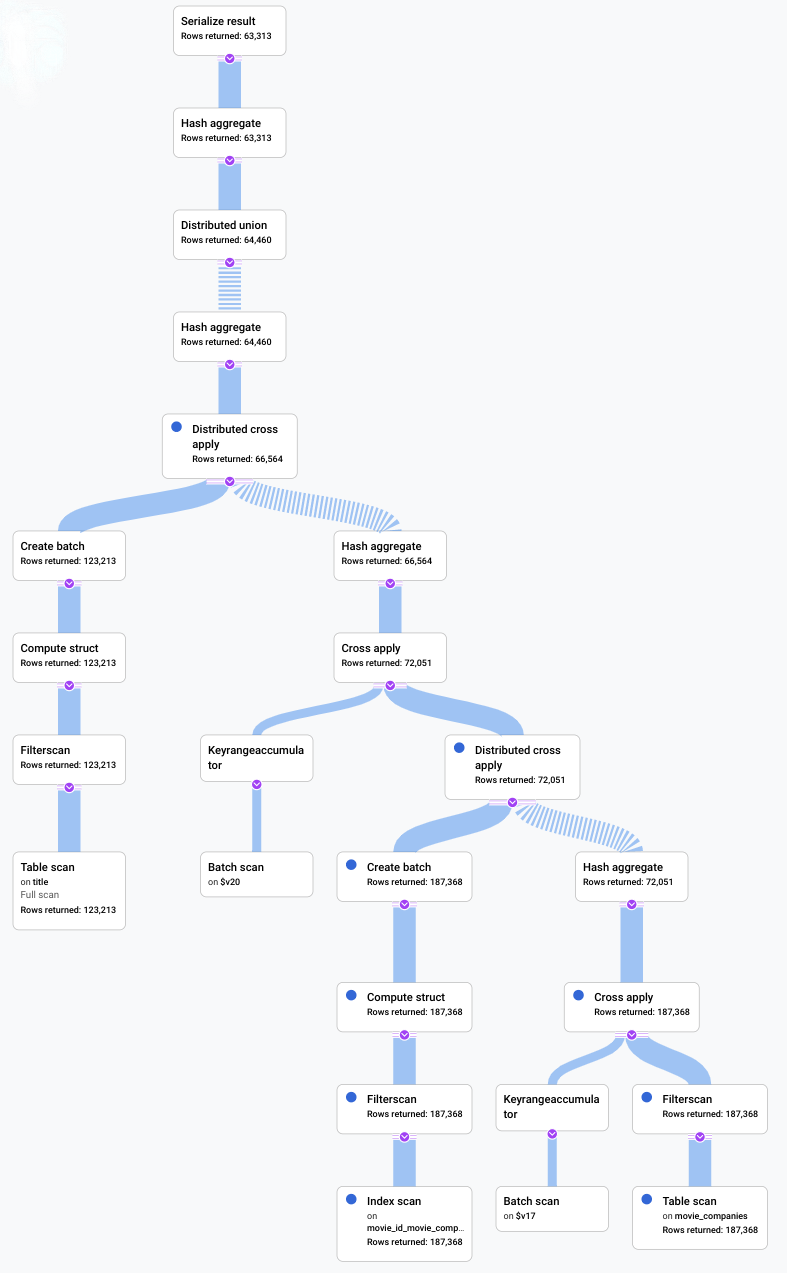
Après
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
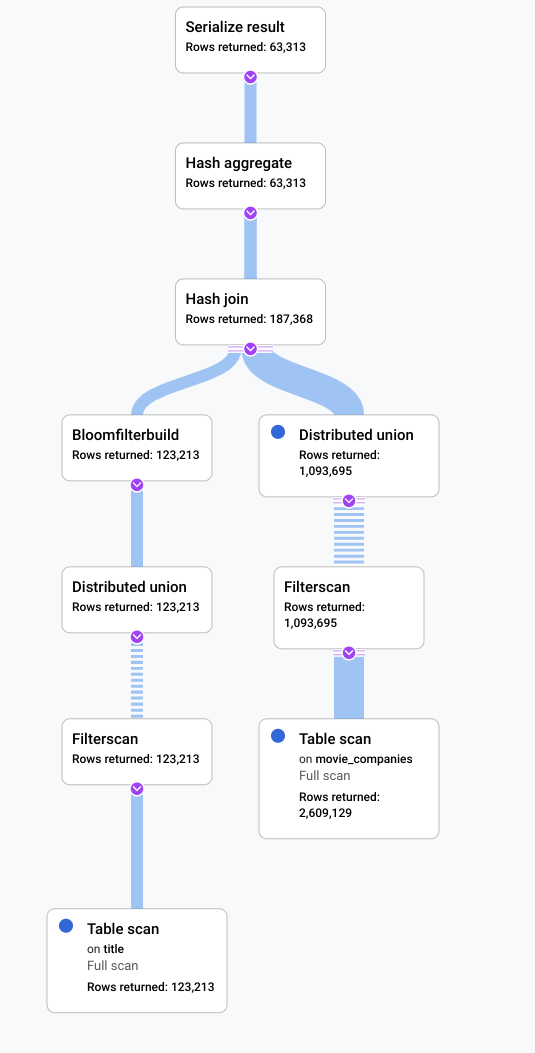
L'élément indiquant qu'une amélioration était possible dans ce scénario est qu'une grande partie des lignes de la table title correspondaient au filtre LIKE
'% the %'. Effectuer une recherche dans une autre table avec autant de lignes risque d'être coûteux. Le remplacement de notre mise en œuvre de jointure par une jointure de hachage a permis d'améliorer considérablement les performances.
Étapes suivantes
Pour obtenir la documentation de référence complète sur le plan, reportez-vous à la page Plans d'exécution de requêtes.
Pour obtenir la documentation de référence complète sur les opérateurs, reportez-vous à la section Opérateurs d'exécution de requêtes.