Cuando usas consultas SQL para buscar datos, Spanner utiliza automáticamente los índices secundarios que puedan ayudarte a recuperar los datos de forma más eficiente. Sin embargo, en algunos casos, Spanner puede elegir un índice que provoque que las consultas sean más lentas. Por eso, es posible que algunas consultas se ejecuten más lentamente que antes.
En esta página se explica cómo detectar cambios en la velocidad de ejecución de las consultas, inspeccionar el plan de ejecución de las consultas y especificar un índice diferente para futuras consultas, si es necesario.
Detectar cambios en la velocidad de ejecución de las consultas
Es muy probable que observes un cambio en la velocidad de ejecución de las consultas después de hacer uno de estos cambios:
- Cambiar significativamente una gran cantidad de datos que tengan un índice secundario.
- Añadir, cambiar o eliminar un índice secundario.
Puedes usar varias herramientas diferentes para identificar una consulta específica que Spanner esté ejecutando más lentamente de lo habitual:
- Información útil sobre la consulta y Estadísticas de consultas.
Métricas específicas de la aplicación que se recogen y analizan con Cloud Monitoring. Por ejemplo, puede monitorizar la métrica Número de consultas para determinar el número de consultas de una instancia a lo largo del tiempo y averiguar qué versión del optimizador de consultas se ha usado para ejecutar una consulta.
Herramientas de monitorización del lado del cliente que miden el rendimiento de tu aplicación.
Nota sobre las bases de datos nuevas
Al consultar bases de datos recién creadas con datos recién insertados o importados, es posible que Spanner no seleccione los índices más adecuados, ya que el optimizador de consultas tarda hasta tres días en recoger estadísticas de optimización automáticamente. Para optimizar el uso de los índices de una nueva base de datos de Spanner antes de ese momento, puede crear manualmente un nuevo paquete de estadísticas.
Revisar el esquema
Una vez que hayas encontrado la consulta que ha ralentizado el proceso, consulta la instrucción SQL de la consulta e identifica las tablas que usa la instrucción y las columnas que obtiene de esas tablas.
A continuación, busca los índices secundarios que haya en esas tablas. Determina si alguno de los índices incluye las columnas que estás consultando, lo que significa que Spanner podría usar uno de los índices para procesar la consulta.
- Si hay índices aplicables, el siguiente paso es buscar el índice que Spanner ha usado para la consulta.
Si no hay ningún índice aplicable, usa el comando
gcloud spanner operations listpara comprobar si has eliminado recientemente un índice aplicable:gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"Si has eliminado un índice aplicable, es posible que ese cambio haya afectado al rendimiento de las consultas. Vuelva a añadir el índice secundario a la tabla. Una vez que Spanner haya añadido el índice, vuelve a ejecutar la consulta y comprueba su rendimiento. Si el rendimiento no mejora, el siguiente paso es buscar el índice que Spanner ha usado para la consulta.
Si no ha eliminado ningún índice aplicable, la selección de índices no ha provocado que el rendimiento de la consulta empeore. Busca otros cambios en tus datos o patrones de uso que puedan haber afectado al rendimiento.
Buscar el índice usado en una consulta
.Para saber qué índice usa Spanner para procesar una consulta, consulta el plan de ejecución de la consulta en la Google Cloud consola:
Ve a la página Instancias de Spanner en la Google Cloud consola.
Haga clic en el nombre de la instancia que quiera consultar.
En el panel de la izquierda, haz clic en la base de datos que quieras consultar y, a continuación, en Spanner Studio.
Introduce la consulta que quieras probar.
En la lista desplegable Ejecutar consulta, selecciona Solo explicación. Spanner muestra el plan de consulta.
Busca al menos uno de los siguientes operadores en el plan de consulta:
- Análisis de tabla
- Index scan
- Aplicación cruzada o aplicación cruzada distribuida
En las siguientes secciones se explica el significado de cada operador.
Operador de análisis de tabla
El operador table scan indica que Spanner no ha usado un índice secundario:
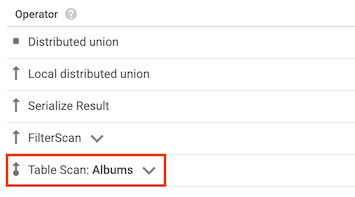
Por ejemplo, supongamos que la tabla Albums no tiene ningún índice secundario y ejecutas la siguiente consulta:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
Como no hay índices que usar, el plan de consulta incluye un operador de análisis de tabla.
Operador de búsqueda de índice
El operador index scan indica que Spanner ha usado un índice secundario al procesar la consulta:
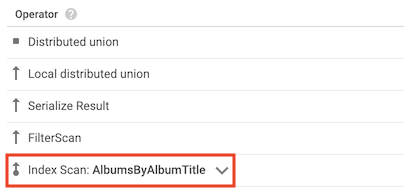
Por ejemplo, supongamos que añade un índice a la tabla Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
A continuación, ejecuta la siguiente consulta:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
El índice AlbumsByAlbumTitle contiene AlbumTitle, que es la única columna que selecciona la consulta. Como resultado, el plan de consulta incluye un operador de análisis de índice.
Operador de aplicación cruzada
En algunos casos, Spanner usa un índice que contiene solo algunas de las columnas que selecciona la consulta. Por lo tanto, Spanner debe combinar el índice con la tabla base.
Cuando se produce este tipo de combinación, el plan de consulta incluye un operador aplicación cruzada o aplicación cruzada distribuida que tiene las siguientes entradas:
- Operador de análisis de índice de un índice de una tabla.
- Un operador de análisis de tabla de la tabla que contiene el índice
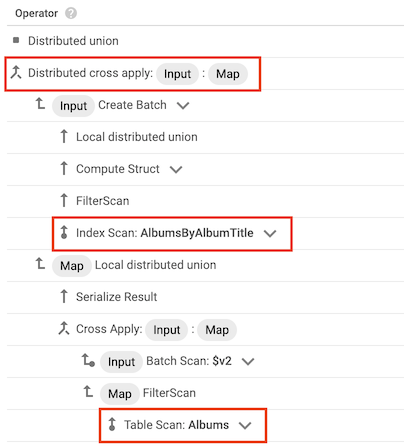
Por ejemplo, supongamos que añade un índice a la tabla Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
A continuación, ejecuta la siguiente consulta:
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
El índice AlbumsByAlbumTitle contiene AlbumTitle, pero la consulta selecciona todas las columnas de la tabla, no solo AlbumTitle. Como resultado, el plan de consulta incluye un operador de aplicación cruzada distribuido, con un análisis de índice de AlbumsByAlbumTitle y un análisis de tabla de Albums como entradas.
Elige otro índice
Una vez que hayas encontrado el índice que ha usado Spanner para tu consulta, prueba a ejecutarla con otro índice o escaneando la tabla base en lugar de usar un índice. Para especificar el índice, añade una directiva FORCE_INDEX a la consulta.
Si encuentras una versión más rápida de la consulta, actualiza tu aplicación para usarla.
Directrices para elegir un índice
Sigue estas directrices para decidir qué índice probar en la consulta:
Si tu consulta cumple alguno de estos criterios, prueba a usar la tabla base en lugar de un índice secundario:
- La consulta comprueba la igualdad con un prefijo de la clave principal de la tabla base (por ejemplo,
SELECT * FROM Albums WHERE SingerId = 1). - Un gran número de filas cumplen los predicados de la consulta (por ejemplo,
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title"). - La consulta usa una tabla base que contiene solo unos cientos de filas.
- La consulta comprueba la igualdad con un prefijo de la clave principal de la tabla base (por ejemplo,
Si la consulta contiene un predicado muy selectivo (por ejemplo,
REGEXP_CONTAINS,STARTS_WITH,<,<=,>,>=o!=), prueba a usar un índice que incluya las mismas columnas que usas en el predicado.
Probar la consulta actualizada
Usa la Google Cloud consola para probar la consulta actualizada y averiguar cuánto tiempo tarda en procesarse.
Si tu consulta incluye parámetros de consulta y un parámetro de consulta se vincula a algunos valores con mucha más frecuencia que a otros, vincula el parámetro de consulta con uno de esos valores en tus pruebas. Por ejemplo, si la consulta incluye un predicado como WHERE country = @countryId y casi todas las consultas vinculan @countryId al valor US, vincula @countryId a US en las pruebas de rendimiento. Este enfoque te ayuda a optimizar las consultas que ejecutas con más frecuencia.
Para probar la consulta actualizada en la Google Cloud consola, sigue estos pasos:
Ve a la página Instancias de Spanner en la Google Cloud consola.
Haga clic en el nombre de la instancia que quiera consultar.
En el panel de la izquierda, haz clic en la base de datos que quieras consultar y, a continuación, en Spanner Studio.
Introduce la consulta que quieras probar, incluida la directiva
FORCE_INDEX, y haz clic en Ejecutar consulta.La consola Google Cloud abre la pestaña Tabla de resultados y, a continuación, muestra los resultados de la consulta, incluido el tiempo que ha tardado el servicio de Spanner en procesarla.
Esta métrica no incluye otras fuentes de latencia, como el tiempo que ha tardado la consola en interpretar y mostrar los resultados de la consulta. Google Cloud
Obtener el perfil detallado de una consulta en formato JSON mediante la API REST
De forma predeterminada, solo se devuelven los resultados de las instrucciones cuando ejecutas una consulta.
Esto se debe a que QueryMode tiene el valor NORMAL.
Para incluir estadísticas de ejecución detalladas con los resultados de la consulta, asigna el valor PROFILE a QueryMode.
Crear una sesión
Antes de actualizar el modo de consulta, cree una sesión, que representa un canal de comunicación con el servicio de base de datos de Spanner.
- Haz clic en
projects.instances.databases.sessions.create. Proporciona el ID del proyecto, la instancia y la base de datos en el siguiente formulario:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]Haz clic en la opción para ejecutar. La respuesta muestra la sesión que has creado en este formulario:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]Lo usarás para realizar el perfil de consulta en el siguiente paso. La sesión creada estará activa durante un máximo de una hora entre usos consecutivos antes de que la base de datos la elimine.
Crear un perfil de la consulta
Habilita el modo PROFILE en la consulta.
- Haz clic en
projects.instances.databases.sessions.executeSql. En session (sesión), introduce el ID de sesión que has creado en el paso anterior:
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]En el campo de cuerpo de la petición, utiliza lo siguiente:
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }Haz clic en la opción para ejecutar. La respuesta devuelta incluirá los resultados de la consulta, el plan de consulta y las estadísticas de ejecución de la consulta.