- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- La función Pruébalo que se encuentra en la documentación de referencia de la API de Spanner. En los ejemplos que se muestran en esta página, se usa la función Pruébalo.
- El Explorador de API de Google, que contiene la API de Cloud Spanner y otras API de Google.
- Otras herramientas o marcos de trabajo compatibles con las llamadas REST de HTTP.
En los ejemplos, se usa
[PROJECT_ID]como el ID del proyecto Google Cloud . Sustituye tu ID del proyectoGoogle Cloud por[PROJECT_ID]. No incluyas[ni]en el ID del proyecto.En los ejemplos, se crea y se usa un ID de instancia de
test-instance. Sustituye el ID de tu instancia si no usastest-instance.En los ejemplos, se crea y se usa un ID de base de datos de
example-db. Sustituye el ID de tu base de datos si no usasexample-db.En los ejemplos, se usa
[SESSION]como parte de un nombre de sesión. Sustituye el valor que recibes cuando creas una sesión para[SESSION]. No incluyas[ni]en el nombre de tu sesión.En los ejemplos, se usa un ID de transacción de
[TRANSACTION_ID]. Sustituye el valor que recibes cuando creas una transacción para[TRANSACTION_ID]. No incluyas[ni]en el ID de tu transacción.La función Pruébalo admite el agregado interactivo de campos de solicitud HTTP individuales. En la mayoría de los ejemplos de este tema, se proporciona toda la solicitud en lugar de describir cómo agregar de forma interactiva campos a la solicitud.
- Haz clic en
projects.instanceConfigs.list. En superior, ingresa lo siguiente:
projects/[PROJECT_ID]Haz clic en Ejecutar. Las opciones de configuración de instancias disponibles se mostrarán en la respuesta. A continuación, se muestra una respuesta de ejemplo (tu proyecto puede tener otra configuración de instancia):
{ "instanceConfigs": [ { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-south1", "displayName": "asia-south1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-east1", "displayName": "asia-east1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-northeast1", "displayName": "asia-northeast1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-europe-west1", "displayName": "europe-west1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-east4", "displayName": "us-east4" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-central1", "displayName": "us-central1" } ] }- Haz clic en
projects.instances.create. En superior, ingresa lo siguiente:
projects/[PROJECT_ID]Haz clic en Agregar parámetros del cuerpo de la solicitud y selecciona
instance.Haz clic en el cuadro de sugerencias de la instancia para ver los campos posibles. Agrega valores para los siguientes campos:
nodeCount: Ingresa1.config: Ingresa el valornamede una de las opciones de configuración de instancias regionales que se muestran cuando generas una lista de las opciones de configuración de instancias.displayName: IngresaTest Instance.
Haz clic en el cuadro de sugerencia después del corchete de cierre en instancia y selecciona instanceId.
En
instanceId, ingresatest-instance.
Tu página de creación de instancias de Pruébalo debería tener este aspecto: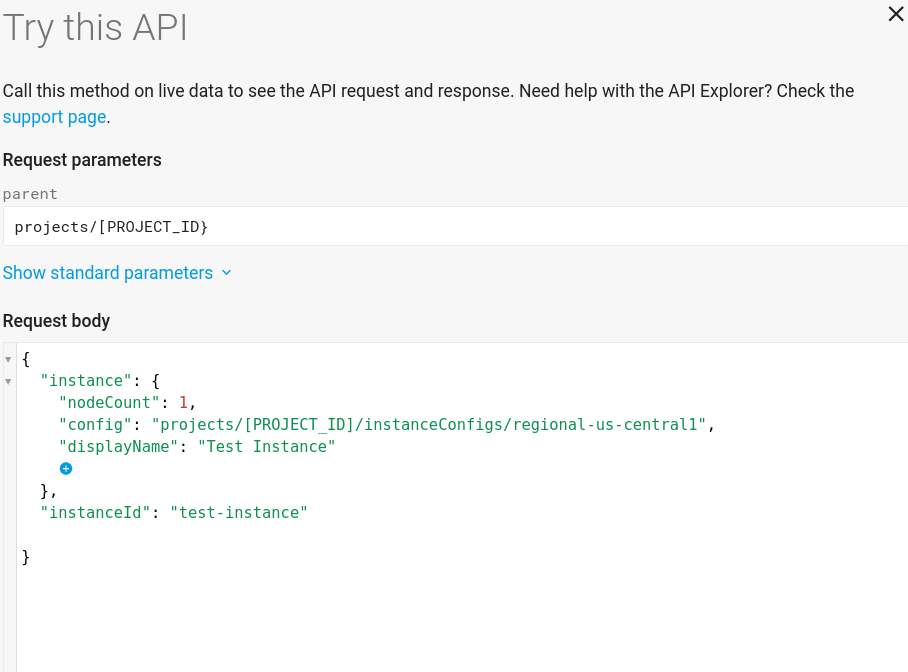
Haz clic en Ejecutar. En la respuesta, se muestra una operación de larga duración que puedes consultar para comprobar su estado.
- Haz clic en
projects.instances.databases.create. En superior, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instanceHaz clic en Agregar parámetros del cuerpo de la solicitud y selecciona
createStatement.En
createStatement, ingresa lo siguiente:CREATE DATABASE `example-db`El nombre de la base de datos,
example-db, contiene un guion, por lo que debe incluirse entre comillas,`.Haz clic en Ejecutar. En la respuesta, se muestra una operación de larga duración que puedes consultar para comprobar su estado.
- Haz clic en
projects.instances.databases.updateDdl. En base de datos, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbEn el cuerpo de la solicitud, usa lo siguiente:
{ "statements": [ "CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)", "CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE" ] }El arreglo de
statementscontiene las declaraciones DDL que definen el esquema.Haz clic en Ejecutar. En la respuesta, se muestra una operación de larga duración que puedes consultar para comprobar su estado.
- Haz clic en
projects.instances.databases.sessions.create. En base de datos, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbHaz clic en Ejecutar.
En la respuesta, se muestra la sesión que creaste de la siguiente forma:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Usarás esta sesión cuando leas o escribas en tu base de datos.
- Haz clic en
projects.instances.databases.sessions.commit. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "insertOrUpdate": { "table": "Singers", "columns": [ "SingerId", "FirstName", "LastName" ], "values": [ [ "1", "Marc", "Richards" ], [ "2", "Catalina", "Smith" ], [ "3", "Alice", "Trentor" ], [ "4", "Lea", "Martin" ], [ "5", "David", "Lomond" ] ] } }, { "insertOrUpdate": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "values": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ] } } ] }Haz clic en Ejecutar. En la respuesta, se muestra la marca de tiempo de la confirmación.
- Haz clic en
projects.instances.databases.sessions.executeSql. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums" }Haz clic en Ejecutar. En la respuesta, se muestran los resultados de la consulta.
- Haz clic en
projects.instances.databases.sessions.read. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true } }Haz clic en Ejecutar. En la respuesta, se muestran los resultados de la lectura.
- Haz clic en
projects.instances.databases.updateDdl. En base de datos, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbEn el cuerpo de la solicitud, usa lo siguiente:
{ "statements": [ "ALTER TABLE Albums ADD COLUMN MarketingBudget INT64" ] }El arreglo de
statementscontiene las declaraciones DDL que definen el esquema.Haz clic en Ejecutar. Este proceso puede tomar unos minutos en completarse, incluso después de que la llamada REST muestre una respuesta. En la respuesta, se muestra una operación de larga duración que puedes consultar para comprobar su estado.
- Haz clic en
projects.instances.databases.sessions.commit. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "update": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "MarketingBudget" ], "values": [ [ "1", "1", "100000" ], [ "2", "2", "500000" ] ] } } ] }Haz clic en Ejecutar. En la respuesta, se muestra la marca de tiempo de la confirmación.
- Haz clic en
projects.instances.databases.sessions.executeSql. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "sql": "SELECT SingerId, AlbumId, MarketingBudget FROM Albums" }Haz clic en Ejecutar. Como parte de la respuesta, deberías ver dos filas que contengan los valores
MarketingBudgetactualizados:"rows": [ [ "1", "1", "100000" ], [ "1", "2", null ], [ "2", "1", null ], [ "2", "2", "500000" ], [ "2", "3", null ] ]- Haz clic en
projects.instances.databases.updateDdl. En base de datos, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbEn el cuerpo de la solicitud, usa lo siguiente:
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle)" ] }Haz clic en Ejecutar. Este proceso puede tomar unos minutos en completarse, incluso después de que la llamada REST muestre una respuesta. En la respuesta, se muestra una operación de larga duración que puedes consultar para comprobar su estado.
- Haz clic en
projects.instances.databases.sessions.executeSql. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "sql": "SELECT AlbumId, AlbumTitle, MarketingBudget FROM Albums WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo'" }Haz clic en Ejecutar. Como parte de la respuesta, deberías ver las siguientes filas:
"rows": [ [ "2", "Go, Go, Go", null ], [ "2", "Forever Hold Your Peace", "500000" ] ]- Haz clic en
projects.instances.databases.sessions.read. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle" }Haz clic en Ejecutar. Como parte de la respuesta, deberías ver las siguientes filas:
"rows": [ [ "2", "Forever Hold Your Peace" ], [ "2", "Go, Go, Go" ], [ "1", "Green" ], [ "3", "Terrified" ], [ "1", "Total Junk" ] ]- Haz clic en
projects.instances.databases.updateDdl. En base de datos, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbEn el cuerpo de la solicitud, usa lo siguiente:
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget)" ] }Haz clic en Ejecutar. Este proceso puede tomar unos minutos en completarse, incluso después de que la llamada REST muestre una respuesta. En la respuesta, se muestra una operación de larga duración que puedes consultar para comprobar su estado.
- Haz clic en
projects.instances.databases.sessions.read. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle", "MarketingBudget" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle2" }Haz clic en Ejecutar. Como parte de la respuesta, deberías ver las siguientes filas:
"rows": [ [ "2", "Forever Hold Your Peace", "500000" ], [ "2", "Go, Go, Go", null ], [ "1", "Green", null ], [ "3", "Terrified", null ], [ "1", "Total Junk", "100000" ] ]- Haz clic en
projects.instances.databases.sessions.beginTransaction. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]En el cuerpo de la solicitud, usa lo siguiente:
{ "options": { "readOnly": {} } }Haz clic en Ejecutar.
En la respuesta, se muestra el ID de la transacción que creaste.
- Haz clic en
projects.instances.databases.sessions.executeSql. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums", "transaction": { "id": "[TRANSACTION_ID]" } }Haz clic en Ejecutar. En la respuesta, deberías ver filas similares a las siguientes:
"rows": [ [ "2", "2", "Forever Hold Your Peace" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "3", "Terrified" ], [ "1", "1", "Total Junk" ] ]- Haz clic en
projects.instances.databases.sessions.read. En sesión, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Recibirás este valor cuando crees una sesión.
En el cuerpo de la solicitud, usa lo siguiente:
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "transaction": { "id": "[TRANSACTION_ID]" } }Haz clic en Ejecutar. En la respuesta, deberías ver filas similares a las siguientes:
"rows": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ]- Haz clic en
projects.instances.databases.dropDatabase. En nombre, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbHaz clic en Ejecutar.
- Haz clic en
projects.instances.delete. En nombre, ingresa lo siguiente:
projects/[PROJECT_ID]/instances/test-instanceHaz clic en Ejecutar.
Maneras de hacer llamadas REST
Puedes realizar llamadas a la API de Spanner REST con las siguientes opciones:
Convenciones usadas en esta página
Instancias
Cuando usas Spanner por primera vez, debes crear una instancia, que es una asignación de recursos que usan las bases de datos de Spanner. Cuando creas una instancia, eliges dónde se almacenan los datos y cuánta capacidad de procesamiento tiene la instancia.
Muestra configuraciones de instancias
Cuando creas una instancia, especificas una configuración de instancia, que define la ubicación geográfica y la replicación de las bases de datos en esa instancia. Puedes elegir una configuración regional, que almacena datos en una región, o una configuración de varias regiones, que distribuye los datos en varias regiones. Consulta Instancias para obtener más información.
Usa projects.instanceConfigs.list para determinar qué configuraciones están disponibles para tu proyecto Google Cloud .
Usas el valor name para una de las opciones de configuración de instancias cuando creas una.
Crea una instancia
Puedes generar una lista de tus instancias mediante projects.instances.list.
Crear una base de datos
Crea una base de datos con el nombre example-db.
Puedes generar una lista de tus bases de datos con projects.instances.databases.list.
Crea un esquema
Usa el lenguaje de definición de datos (DDL) de Spanner para crear, modificar o quitar tablas, y crear o quitar índices.
En el esquema, se definen dos tablas, Singers y Albums, para una aplicación de música básica. Estas tablas se usan en toda esta página. Si aún no lo has hecho, consulta el esquema de ejemplo.
Puedes recuperar tu esquema con projects.instances.databases.getDdl.
Crea una sesión
Antes de agregar, actualizar, borrar o consultar datos, debes crear una sesión, que representa un canal de comunicación con el servicio de base de datos de Spanner. Se recomienda no usar una sesión directamente si usas una biblioteca cliente de Spanner, ya que la biblioteca cliente administra las sesiones por ti.
El objetivo es que las sesiones duren mucho tiempo. El servicio de base de datos de Spanner puede borrar una sesión cuando esté inactiva por más de una hora. Los intentos de usar una sesión borrada darán como resultado NOT_FOUND. Si encuentras este error, crea y usa una sesión nueva. Para verificar si una sesión aún está activa, usa projects.instances.databases.sessions.get.
Para obtener información relacionada, consulta Conservar una sesión inactiva.
El siguiente paso consiste en escribir datos en tu base de datos.
Escribe datos
Los datos se escriben con el tipo Mutation. Una Mutation es un contenedor de operaciones de mutación. Una Mutation representa una secuencia de inserciones, actualizaciones, eliminaciones y otras acciones que se pueden aplicar de forma automática en distintas filas y tablas de una base de datos de Spanner.
En este ejemplo, se usó insertOrUpdate. Otras operaciones para Mutations son insert, update, replace y delete.
Para obtener información sobre cómo codificar tipos de datos, consulta TypeCode.
Consulta datos mediante SQL
Lee datos con la API de lectura
Actualizar el esquema de la base de datos
Supongamos que necesitas agregar una columna nueva llamada MarketingBudget a la tabla Albums, que requiere una actualización del esquema de tu base de datos. Spanner admite actualizaciones del esquema de una base de datos mientras esta sigue entregando tráfico. Las actualizaciones de esquema no requieren que la base de datos esté sin conexión y no bloquean tablas o columnas completas. Puedes continuar escribiendo datos en la base de datos durante la actualización del esquema.
Agrega una columna
Escribir datos en la columna nueva
Con el siguiente código, se escriben datos en la columna nueva. Establece MarketingBudget en 100000 para la fila marcada por Albums(1, 1) y en 500000 para la fila marcada por Albums(2, 2).
También puedes ejecutar una consulta de SQL o una llamada de lectura para recuperar los valores que acabas de escribir.
La consulta se ejecuta de este modo:
Usa un índice secundario
Supongamos que deseas recuperar todas las filas de Albums que tienen valores AlbumTitle en un rango determinado. Puedes leer todos los valores de la columna AlbumTitle con una instrucción de SQL o una llamada de lectura y, luego, descartar las filas que no cumplan con los criterios. Sin embargo, analizar tablas enteras es costoso, especialmente si tienen muchas filas. En su lugar, crea un índice secundario en la tabla para acelerar la recuperación de filas cuando realizas búsquedas por columnas sin claves primarias.
Para agregar un índice secundario a una tabla existente, es necesario actualizar el esquema. Al igual que otras actualizaciones de esquema, Spanner admite que se agregue un índice mientras la base de datos continúa entregando tráfico. Spanner reabastece de manera automática el índice con tus datos existentes. Los reabastecimientos pueden tomar unos minutos en completarse, pero no es necesario que uses la base de datos sin conexión o que evites escribir en ciertas tablas o columnas durante este proceso. Para obtener más detalles, consulta la sección sobre el reabastecimiento de índices.
Después de agregar un índice secundario, Spanner lo usa de forma automática en las consultas de SQL que probablemente se ejecuten más rápido con el índice. Si usas la interfaz de lectura, debes especificar el índice que deseas usar.
Agregar un índice secundario
Puedes agregar un índice con updateDdl.
Realizar consultas mediante el índice
Leer con el índice
Agregar un índice con la cláusula STORING
Quizás notaste que, en el ejemplo de lectura anterior, no se incluye la lectura de la columna MarketingBudget. Esto se debe a que la interfaz de lectura de Spanner no admite la posibilidad de unir un índice con una tabla de datos para buscar valores que no están almacenados en el índice.
Crea una definición alternativa de AlbumsByAlbumTitle que almacene una copia de MarketingBudget en el índice.
Puedes agregar un índice STORING con updateDdl.
Ahora puedes ejecutar una operación de lectura que recupere todas las columnas AlbumId, AlbumTitle y MarketingBudget del índice AlbumsByAlbumTitle2:
Recupera datos mediante transacciones de solo lectura
Supongamos que quieres ejecutar más de una lectura en la misma marca de tiempo. En las transacciones de solo lectura, se observa un prefijo coherente del historial de confirmaciones de transacciones, por lo que la aplicación siempre obtiene datos coherentes.
Crear una transacción de solo lectura
Ahora puedes usar la transacción de solo lectura para recuperar datos en una marca de tiempo coherente, incluso si los datos cambiaron desde que creaste la transacción de solo lectura.
Ejecutar una consulta mediante la transacción de solo lectura
Leer mediante la transacción de solo lectura
Spanner también admite transacciones de lectura y escritura, que ejecutan un conjunto de lecturas y escrituras de forma atómica en un único punto lógico en el tiempo. Para obtener más información, consulta la sección sobre transacciones de lectura y escritura. La función Pruébalo no es adecuada para demostrar una transacción de lectura y escritura.
Limpieza
Para evitar que se apliquen cargos adicionales a tu cuenta de Google Cloud por los recursos que se usaron en este instructivo, descarta la base de datos y borra la instancia que creaste.