Dalam database Spanner, Spanner secara otomatis membuat
indeks untuk kunci utama setiap tabel. Misalnya, Anda tidak perlu melakukan apa pun untuk mengindeks kunci utama Singers, karena kunci tersebut diindeks secara otomatis untuk Anda.
Anda juga dapat membuat indeks sekunder untuk kolom lain. Menambahkan indeks sekunder pada kolom akan membuat pencarian data di kolom tersebut menjadi lebih efisien. Misalnya, jika Anda perlu mencari album dengan cepat berdasarkan judul, Anda harus membuat indeks sekunder pada AlbumTitle, sehingga Spanner tidak perlu memindai seluruh tabel.
Jika pencarian dalam contoh sebelumnya dilakukan dalam transaksi baca-tulis,
pencarian yang lebih efisien juga menghindari penahanan kunci pada seluruh tabel,
yang memungkinkan penyisipan dan pembaruan serentak ke tabel untuk baris di luar
rentang pencarian AlbumTitle.
Selain manfaat yang diberikan untuk pencarian, indeks sekunder juga dapat membantu Spanner mengeksekusi pemindaian dengan lebih efisien, sehingga memungkinkan pemindaian indeks, bukan pemindaian tabel penuh.
Spanner menyimpan data berikut di setiap indeks sekunder:
- Semua kolom kunci dari tabel dasar
- Semua kolom yang disertakan dalam indeks
- Semua kolom yang ditentukan dalam klausa
STORINGopsional (database dialek GoogleSQL) atau klausaINCLUDE(database dialek PostgreSQL) dari definisi indeks.
Seiring waktu, Spanner menganalisis tabel Anda untuk memastikan indeks sekunder Anda digunakan untuk kueri yang sesuai.
Menambahkan indeks sekunder
Waktu yang paling efisien untuk menambahkan indeks sekunder adalah saat Anda membuat tabel. Untuk membuat tabel dan indeksnya secara bersamaan, kirim pernyataan DDL untuk tabel baru dan indeks baru dalam satu permintaan ke Spanner.
Di Spanner, Anda juga dapat menambahkan indeks sekunder baru ke tabel yang ada saat database terus melayani traffic. Seperti perubahan skema lainnya di Spanner, penambahan indeks ke database yang ada tidak memerlukan penonaktifan database dan tidak mengunci seluruh kolom atau tabel.
Setiap kali indeks baru ditambahkan ke tabel yang ada, Spanner akan otomatis mengisi ulang, atau mengisi, indeks untuk mencerminkan tampilan terbaru data yang diindeks. Spanner mengelola proses pengisian ulang ini untuk Anda, dan proses ini berjalan di latar belakang menggunakan resource node dengan prioritas rendah. Kecepatan pengisian ulang indeks beradaptasi dengan perubahan resource node selama pembuatan indeks, dan pengisian ulang tidak memengaruhi performa database secara signifikan.
Pembuatan indeks dapat memakan waktu beberapa menit hingga beberapa jam. Karena pembuatan indeks adalah update skema, maka pembuatan indeks terikat oleh batasan performa yang sama seperti update skema lainnya. Waktu yang diperlukan untuk membuat indeks sekunder bergantung pada beberapa faktor:
- Ukuran set data
- Kapasitas komputasi instance
- Beban pada instance
Untuk melihat progres yang dibuat untuk proses pengisian ulang indeks, lihat bagian progres.
Perhatikan bahwa penggunaan kolom stempel waktu commit sebagai bagian pertama dari indeks sekunder dapat membuat hotspot dan mengurangi performa penulisan.
Gunakan pernyataan CREATE INDEX untuk menentukan indeks sekunder
dalam skema Anda. Berikut beberapa contohnya:
Untuk mengindeks semua Singers dalam database berdasarkan nama depan dan belakangnya:
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Untuk membuat indeks semua Songs dalam database berdasarkan nilai SongName:
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
Untuk mengindeks hanya lagu untuk penyanyi tertentu, gunakan klausa
INTERLEAVE IN untuk menyisipkan indeks dalam
tabel Singers:
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
Untuk mengindeks hanya lagu di album tertentu:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
Untuk mengindeks berdasarkan urutan menurun SongName:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
Perhatikan bahwa anotasi DESC sebelumnya hanya berlaku untuk SongName. Untuk mengindeks berdasarkan
urutan menurun kunci indeks lainnya, beri anotasi juga dengan DESC:
SingerId DESC, AlbumId DESC.
Perhatikan juga bahwa PRIMARY_KEY adalah kata khusus dan tidak dapat digunakan sebagai nama
indeks. Nama ini diberikan ke pseudo-index
yang dibuat saat tabel dengan spesifikasi PRIMARY KEY dibuat
Untuk mengetahui detail dan praktik terbaik selengkapnya dalam memilih indeks non-sisipan dan indeks sisipan, lihat Opsi indeks dan Gunakan indeks sisipan pada kolom yang nilainya meningkat atau menurun secara monoton.
Indeks dan Penyelipan
Indeks Spanner dapat disisipkan dengan tabel lain untuk menempatkan baris indeks bersama dengan baris tabel lain. Serupa dengan penyisipan tabel Spanner, kolom kunci utama indeks induk harus berupa awalan kolom yang diindeks, yang cocok dalam jenis dan urutan pengurutan. Tidak seperti tabel yang disisipkan, pencocokan nama kolom tidak diperlukan. Setiap baris indeks yang disisipkan disimpan secara fisik bersama dengan baris induk terkait.
Misalnya, perhatikan skema berikut:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
Untuk mengindeks semua Singers dalam database berdasarkan nama depan dan belakangnya, Anda harus membuat indeks. Berikut cara menentukan indeks SingersByFirstLastName:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Jika ingin membuat indeks Songs pada (SingerId, AlbumId, SongName),
Anda dapat melakukan hal berikut:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
Atau, Anda dapat membuat indeks yang disisipkan dengan ancestor Songs,
seperti berikut:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
Selain itu, Anda juga dapat membuat indeks Songs di
(PublisherId, SingerId, AlbumId, SongName) yang diselingi dengan tabel
yang bukan ancestor Songs, seperti Publishers. Perhatikan bahwa kunci utama
untuk tabel Publishers (id), bukan merupakan awalan dari kolom yang diindeks dalam
contoh berikut. Hal ini masih diizinkan karena Publishers.Id dan
Songs.PublisherId memiliki jenis, urutan pengurutan, dan kemampuan nilai null yang sama.
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
Memeriksa progres pengisian ulang indeks
Konsol
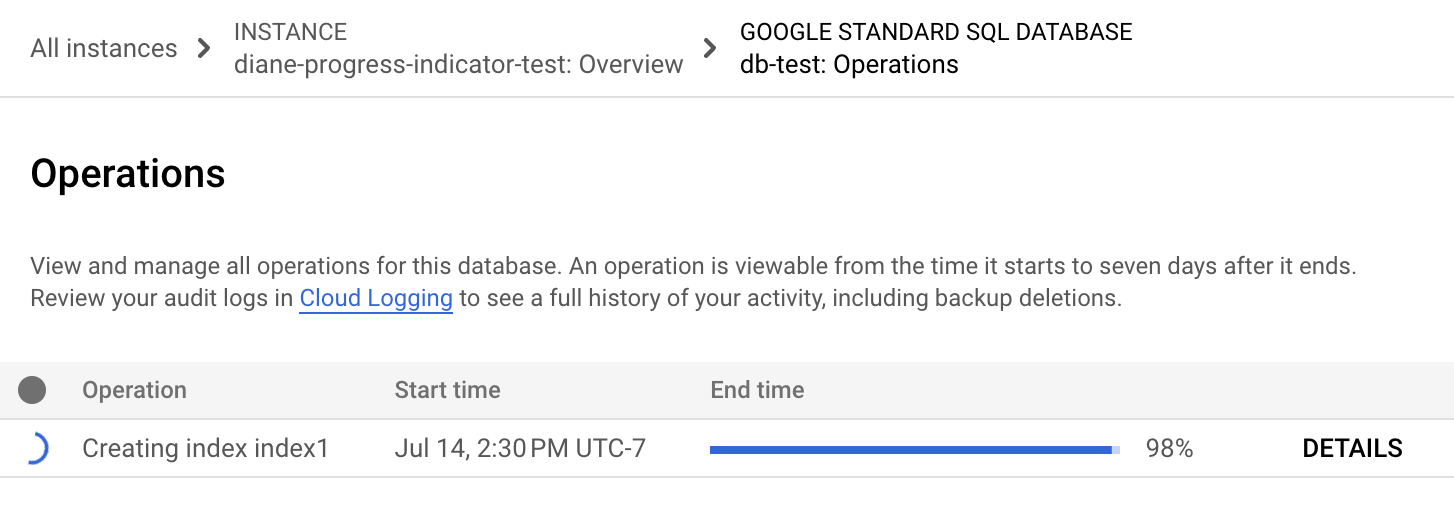
Di menu navigasi Spanner, klik tab Operations. Halaman Operations menampilkan daftar operasi yang sedang berjalan.
Temukan operasi pengisian ulang dalam daftar. Jika masih berjalan, indikator progres di kolom Waktu berakhir menunjukkan persentase operasi yang telah selesai, seperti yang ditunjukkan pada gambar berikut:
gcloud
Gunakan gcloud spanner operations describe
untuk memeriksa progres operasi.
Dapatkan ID operasi:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Ganti kode berikut:
- INSTANCE-NAME dengan nama instance Spanner.
- DATABASE-NAME dengan nama database.
Catatan penggunaan:
Untuk membatasi daftar, tentukan flag
--filter. Contoh:--filter="metadata.name:example-db"hanya mencantumkan operasi pada database tertentu.--filter="error:*"hanya mencantumkan operasi pencadangan yang gagal.
Untuk mengetahui informasi tentang sintaksis filter, lihat filter topik gcloud. Untuk mengetahui informasi tentang memfilter operasi pencadangan, lihat kolom
filterdi ListBackupOperationsRequest.Flag
--typetidak peka huruf besar/kecil.
Outputnya terlihat mirip dengan yang berikut ini:
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadataJalankan
gcloud spanner operations describe:gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
Ganti kode berikut:
- INSTANCE-NAME: Nama instance Spanner.
- DATABASE-NAME: Nama database Spanner.
- PROJECT-NAME: Nama project.
- OPERATION-ID: ID operasi yang ingin Anda periksa.
Bagian
progressdalam output menunjukkan persentase operasi yang telah selesai. Outputnya akan terlihat mirip dengan berikut ini:done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
Dapatkan ID operasi:
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Ganti kode berikut:
- INSTANCE-NAME dengan nama instance Spanner.
- DATABASE-NAME dengan nama database.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT-ID: project ID.
- INSTANCE-ID: ID instance.
- DATABASE-ID: ID database.
- OPERATION-ID: ID operasi.
Metode HTTP dan URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
Untuk mengirim permintaan, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Untuk gcloud dan REST, Anda dapat menemukan progres setiap pernyataan pengisian ulang indeks di bagian progress. Untuk setiap pernyataan dalam array pernyataan,
ada kolom yang sesuai dalam array progres. Urutan array progres ini
sesuai dengan urutan array pernyataan. Setelah tersedia, kolom
startTime, progressPercent, dan endTime akan diisi dengan tepat.
Perhatikan bahwa output tidak menampilkan perkiraan waktu selesainya progres pengisian ulang.
Jika operasi membutuhkan waktu terlalu lama, Anda dapat membatalkannya. Untuk mengetahui informasi selengkapnya, lihat Membatalkan pembuatan indeks.
Skenario saat melihat progres pengisian ulang indeks
Ada berbagai skenario yang dapat Anda temui saat mencoba memeriksa progres pengisian ulang indeks. Pernyataan pembuatan indeks yang memerlukan pengisian ulang indeks adalah bagian dari operasi update skema, dan ada beberapa pernyataan yang merupakan bagian dari operasi update skema.
Skenario pertama adalah yang paling sederhana, yaitu saat pernyataan pembuatan indeks
adalah pernyataan pertama dalam operasi update skema. Karena pernyataan pembuatan indeks adalah pernyataan pertama, pernyataan tersebut adalah pernyataan pertama yang diproses dan dieksekusi karena urutan eksekusi.
Segera, kolom startTime pernyataan pembuatan indeks akan
diisi dengan waktu mulai operasi pembaruan skema. Selanjutnya, kolom progressPercent pernyataan pembuatan
indeks akan diisi saat progres pengisian ulang indeks lebih dari 0%. Terakhir, kolom endTime diisi setelah
pernyataan dilakukan.
Skenario kedua adalah saat pernyataan pembuatan indeks bukan pernyataan
pertama dalam operasi update skema. Tidak ada kolom yang terkait dengan pernyataan pembuatan indeks yang akan diisi hingga pernyataan sebelumnya dilakukan karena urutan eksekusi.
Mirip dengan skenario sebelumnya, setelah pernyataan sebelumnya dilakukan, kolom
startTime dari pernyataan pembuatan indeks akan diisi terlebih dahulu, diikuti dengan
kolom progressPercent. Terakhir, kolom endTime akan terisi setelah
pernyataan selesai di-commit.
Membatalkan pembuatan indeks
Anda dapat menggunakan Google Cloud CLI untuk membatalkan pembuatan indeks. Untuk mengambil daftar operasi pembaruan skema untuk database Spanner, gunakan perintah gcloud spanner operations list, dan sertakan opsi --filter:
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
Temukan OPERATION_ID untuk operasi yang ingin Anda batalkan, lalu gunakan perintah
gcloud spanner operations cancel untuk membatalkannya:
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
Melihat indeks yang ada
Untuk melihat informasi tentang indeks yang ada dalam database, Anda dapat menggunakan konsolGoogle Cloud atau Google Cloud CLI:
Konsol
Buka halaman Instances Spanner di konsol Google Cloud .
Klik nama instance yang ingin Anda lihat.
Di panel kiri, klik database yang ingin Anda lihat, lalu klik tabel yang ingin Anda lihat.
Klik tab Indeks. Konsol Google Cloud menampilkan daftar indeks.
Opsional: Untuk mendapatkan detail tentang indeks, seperti kolom yang disertakan, klik nama indeks.
gcloud
Gunakan perintah gcloud spanner databases ddl describe:
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
CLI gcloud mencetak pernyataan Bahasa Definisi Data (DDL)
untuk membuat tabel dan indeks database. Pernyataan CREATE
INDEX menjelaskan indeks yang ada. Misalnya:
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
Membuat kueri dengan indeks tertentu
Bagian berikut menjelaskan cara menentukan indeks dalam pernyataan SQL dan
dengan antarmuka baca untuk Spanner. Contoh di bagian ini mengasumsikan bahwa Anda telah menambahkan kolom MarketingBudget ke tabel Albums dan membuat indeks bernama AlbumsByAlbumTitle:
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Menentukan indeks dalam pernyataan SQL
Saat Anda menggunakan SQL untuk membuat kueri tabel Spanner, Spanner akan otomatis
menggunakan indeks apa pun yang cenderung membuat kueri lebih efisien. Akibatnya, Anda tidak perlu menentukan indeks untuk kueri SQL. Namun,
untuk kueri yang penting bagi beban kerja Anda, Google menyarankan agar Anda menggunakan
direktif FORCE_INDEX dalam pernyataan SQL untuk performa yang lebih konsisten.
Dalam beberapa kasus, Spanner mungkin memilih indeks yang menyebabkan latensi kueri meningkat. Jika Anda telah mengikuti langkah-langkah pemecahan masalah untuk regresi performa dan mengonfirmasi bahwa sebaiknya mencoba indeks lain untuk kueri, Anda dapat menentukan indeks sebagai bagian dari kueri.
Untuk menentukan indeks dalam pernyataan SQL, gunakan petunjuk FORCE_INDEX
untuk memberikan petunjuk indeks. Petunjuk pengindeksan menggunakan sintaksis berikut:
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
Anda juga dapat menggunakan direktif indeks untuk memberi tahu Spanner agar memindai tabel dasar, bukan menggunakan indeks:
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
Anda dapat menggunakan direktif indeks untuk memberi tahu Spanner agar memindai indeks dalam tabel dengan skema bernama:
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
Contoh berikut menunjukkan kueri SQL yang menentukan indeks:
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
Petunjuk indeks dapat memaksa pemroses kueri Spanner untuk membaca kolom tambahan yang diperlukan oleh kueri, tetapi tidak disimpan dalam indeks.
Prosesor kueri mengambil kolom ini dengan menggabungkan indeks dan tabel dasar. Untuk menghindari gabungan tambahan ini, gunakan klausa
STORING (database dialek GoogleSQL) atau klausa INCLUDE (database dialek PostgreSQL) untuk
menyimpan kolom tambahan dalam indeks.
Pada contoh sebelumnya, kolom MarketingBudget tidak
disimpan dalam indeks, tetapi kueri SQL memilih kolom ini. Akibatnya, Spanner harus mencari kolom MarketingBudget di tabel dasar, lalu menggabungkannya dengan data dari indeks, untuk menampilkan hasil kueri.
Spanner akan memunculkan error jika direktif indeks memiliki salah satu masalah berikut:
- Indeks tidak ada.
- Indeks berada di tabel dasar yang berbeda.
- Kueri tidak memiliki ekspresi pemfilteran
NULLyang diperlukan untuk indeksNULL_FILTERED.
Contoh berikut menunjukkan cara menulis dan menjalankan kueri yang mengambil
nilai AlbumId, AlbumTitle, dan MarketingBudget menggunakan indeks
AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Menentukan indeks di antarmuka baca
Saat menggunakan antarmuka baca ke Spanner, dan Anda ingin Spanner menggunakan indeks, Anda harus menentukan indeks. Antarmuka baca tidak memilih indeks secara otomatis.
Selain itu, indeks Anda harus berisi semua data yang muncul dalam hasil kueri, tidak termasuk kolom yang merupakan bagian dari kunci utama. Batasan ini ada karena antarmuka baca tidak mendukung gabungan antara indeks dan tabel dasar. Jika perlu menyertakan kolom lain dalam hasil kueri, Anda memiliki beberapa opsi:
- Gunakan klausa
STORINGatauINCLUDEuntuk menyimpan kolom tambahan dalam indeks. - Kueri tanpa menyertakan kolom tambahan, lalu gunakan kunci utama untuk mengirim kueri lain yang membaca kolom tambahan.
Spanner menampilkan nilai dari indeks dalam urutan pengurutan menaik menurut kunci indeks. Untuk mengambil nilai dalam urutan menurun, selesaikan langkah-langkah berikut:
Anotasikan kunci indeks dengan
DESC. Contoh:CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);Anotasi
DESCberlaku untuk satu kunci indeks. Jika indeks menyertakan lebih dari satu kunci, dan Anda ingin hasil kueri muncul dalam urutan menurun berdasarkan semua kunci, sertakan anotasiDESCuntuk setiap kunci.Jika pembacaan menentukan rentang kunci, pastikan rentang kunci juga dalam urutan menurun. Dengan kata lain, nilai kunci awal harus lebih besar daripada nilai kunci akhir.
Contoh berikut menunjukkan cara mengambil nilai AlbumId dan
AlbumTitle menggunakan indeks AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Membuat indeks untuk pemindaian khusus indeks
Secara opsional, Anda dapat menggunakan klausa STORING (untuk database dialek GoogleSQL) atau klausa INCLUDE (untuk database dialek PostgreSQL) untuk menyimpan salinan kolom dalam
indeks. Jenis indeks ini memberikan keuntungan untuk kueri dan panggilan baca yang menggunakan indeks, dengan biaya penggunaan penyimpanan tambahan:
- Kueri SQL yang menggunakan indeks dan memilih kolom yang disimpan dalam klausa
STORINGatauINCLUDEtidak memerlukan gabungan tambahan ke tabel dasar. - Panggilan
read()yang menggunakan indeks dapat membaca kolom yang disimpan oleh klausaSTORING/INCLUDE.
Misalnya, Anda membuat versi alternatif AlbumsByAlbumTitle
yang menyimpan salinan kolom MarketingBudget dalam indeks (perhatikan
klausa STORING atau INCLUDE dalam huruf tebal):
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
Dengan indeks AlbumsByAlbumTitle lama, Spanner harus menggabungkan indeks
dengan tabel dasar, lalu mengambil kolom dari tabel dasar. Dengan indeks
AlbumsByAlbumTitle2 baru, Spanner membaca kolom secara langsung dari
indeks, yang lebih efisien.
Jika Anda menggunakan antarmuka baca, bukan SQL, indeks AlbumsByAlbumTitle2
baru juga memungkinkan Anda membaca kolom MarketingBudget secara langsung:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Mengubah indeks
Anda dapat menggunakan pernyataan ALTER INDEX untuk menambahkan kolom tambahan
ke indeks yang ada atau menghapus kolom. Hal ini dapat memperbarui daftar kolom yang ditentukan oleh klausa STORING (database dialek GoogleSQL) atau klausa INCLUDE (database dialek PostgreSQL) saat Anda membuat indeks. Anda tidak dapat menggunakan pernyataan ini untuk menambahkan kolom ke atau menghapus
kolom dari kunci indeks. Misalnya, daripada membuat
indeks AlbumsByAlbumTitle2 baru, Anda dapat menggunakan ALTER INDEX untuk menambahkan
kolom ke AlbumsByAlbumTitle, seperti yang ditunjukkan dalam contoh berikut:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
Saat Anda menambahkan kolom baru ke indeks yang ada, Spanner
menggunakan proses pengisian ulang di latar belakang. Saat pengisian ulang sedang berlangsung, kolom dalam indeks tidak dapat dibaca, sehingga Anda mungkin tidak mendapatkan peningkatan performa yang diharapkan. Anda dapat menggunakan perintah gcloud spanner operations
untuk mencantumkan operasi yang berjalan lama dan melihat statusnya.
Untuk mengetahui informasi selengkapnya, lihat describe operation.
Anda juga dapat menggunakan cancel operation untuk membatalkan operasi yang sedang berjalan.
Setelah pengisian ulang selesai, Spanner akan menambahkan kolom ke dalam indeks. Seiring bertambahnya ukuran Indeks, hal ini dapat memperlambat kueri yang menggunakan indeks.
Contoh berikut menunjukkan cara menghapus kolom dari indeks:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
Indeks nilai NULL
Secara default, Spanner mengindeks nilai NULL. Misalnya, ingat kembali
definisi indeks SingersByFirstLastName pada tabel Singers:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Semua baris Singers diindeks meskipun FirstName atau LastName, atau
keduanya, NULL.

Jika nilai NULL diindeks, Anda dapat melakukan kueri dan pembacaan SQL yang efisien
terhadap data yang menyertakan nilai NULL. Misalnya, gunakan pernyataan kueri SQL ini
untuk menemukan semua Singers dengan NULL FirstName:
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
Urutan pengurutan untuk nilai NULL
Spanner mengurutkan NULL sebagai nilai terkecil untuk jenis tertentu. Untuk kolom dalam urutan menaik (ASC), nilai NULL diurutkan terlebih dahulu. Untuk kolom dalam urutan menurun (DESC), nilai NULL diurutkan terakhir.
Menonaktifkan pengindeksan nilai NULL
GoogleSQL
Untuk menonaktifkan pengindeksan nilai null, tambahkan kata kunci NULL_FILTERED ke definisi indeks. Indeks NULL_FILTERED sangat berguna untuk mengindeks kolom jarang, yang sebagian besar barisnya berisi nilai NULL. Dalam kasus ini, indeks
NULL_FILTERED dapat jauh lebih kecil dan lebih efisien untuk dipertahankan
daripada indeks normal yang menyertakan nilai NULL.
Berikut definisi alternatif SingersByFirstLastName yang tidak mengindeks nilai NULL:
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
Kata kunci NULL_FILTERED berlaku untuk semua kolom kunci indeks. Anda tidak dapat menentukan
pemfilteran NULL per kolom.
PostgreSQL
Untuk mengecualikan baris dengan nilai null dalam satu atau beberapa kolom yang diindeks, gunakan predikat
WHERE COLUMN IS NOT NULL.
Indeks yang difilter null sangat berguna untuk mengindeks kolom sparse, yang sebagian besar barisnya berisi nilai NULL. Dalam kasus ini, indeks yang difilter null dapat jauh lebih kecil dan lebih efisien untuk dipertahankan daripada indeks normal yang menyertakan nilai NULL.
Berikut definisi alternatif SingersByFirstLastName yang tidak mengindeks nilai NULL:
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
Memfilter nilai NULL akan mencegah Spanner menggunakannya untuk beberapa kueri. Misalnya, Spanner tidak menggunakan indeks untuk kueri ini,
karena indeks menghilangkan baris Singers yang LastName-nya adalah NULL; akibatnya, penggunaan indeks akan mencegah kueri menampilkan baris yang benar:
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Agar Spanner dapat menggunakan indeks, Anda harus menulis ulang kueri sehingga mengecualikan baris yang juga dikecualikan dari indeks:
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
Kolom proto indeks
Gunakan kolom yang dihasilkan untuk mengindeks kolom dalam buffer protokol yang disimpan di kolom PROTO, selama kolom yang diindeks menggunakan jenis data primitif atau ENUM.
Jika Anda menentukan indeks pada kolom pesan protokol, Anda tidak dapat mengubah atau menghapus kolom tersebut dari skema proto. Untuk mengetahui informasi selengkapnya, lihat Pembaruan pada skema yang berisi indeks pada kolom proto.
Berikut adalah contoh tabel Singers dengan kolom pesan proto SingerInfo. Untuk menentukan indeks pada kolom nationality dari PROTO,
Anda perlu membuat kolom yang dihasilkan tersimpan:
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
Memiliki definisi jenis proto googlesql.example.SingerInfo berikut:
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
Kemudian, tentukan indeks pada kolom nationality proto:
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
Kueri SQL berikut membaca data menggunakan indeks sebelumnya:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
Catatan:
- Gunakan direktif indeks untuk mengakses indeks di kolom buffer protokol.
- Anda tidak dapat membuat indeks pada kolom buffer protokol berulang.
Pembaruan pada skema yang berisi indeks pada kolom proto
Jika Anda menentukan indeks pada kolom pesan protokol, Anda tidak dapat mengubah atau menghapus kolom tersebut dari skema proto. Hal ini karena setelah Anda menentukan indeks, pemeriksaan jenis dilakukan setiap kali skema diperbarui. Spanner merekam informasi jenis untuk semua kolom dalam jalur yang digunakan dalam definisi indeks.
Indeks unik
Indeks dapat dideklarasikan UNIQUE. Indeks UNIQUE menambahkan batasan pada
data yang diindeks yang melarang entri duplikat untuk kunci indeks tertentu.
Batasan ini diterapkan oleh Spanner pada waktu commit transaksi.
Secara khusus, setiap transaksi yang akan menyebabkan beberapa entri indeks untuk
kunci yang sama ada akan gagal di-commit.
Jika tabel berisi data non-UNIQUE sejak awal, upaya untuk membuat indeks UNIQUE di tabel tersebut akan gagal.
Catatan tentang indeks UNIQUE NULL_FILTERED
Indeks UNIQUE NULL_FILTERED tidak menerapkan keunikan kunci indeks jika setidaknya salah satu bagian kunci indeks adalah NULL.
Misalnya, Anda membuat tabel dan indeks berikut:
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
Dua baris berikut di ExampleTable memiliki nilai yang sama untuk kunci indeks sekunder Key1, Key2, dan Col1:
1, NULL, 1, 1
1, NULL, 2, 1
Karena Key2 adalah NULL dan indeks difilter null, baris tidak akan
ada dalam indeks ExampleIndex. Karena tidak dimasukkan ke dalam
indeks, indeks tidak akan menolaknya karena melanggar keunikan pada (Key1, Key2,
Col1).
Jika Anda ingin indeks menerapkan keunikan nilai tuple (Key1, Key2, Col1), Anda harus memberi anotasi Key2 dengan NOT NULL dalam definisi tabel atau membuat indeks tanpa memfilter nilai null.
Menghapus indeks
Gunakan pernyataan DROP INDEX untuk menghapus indeks sekunder dari
skema Anda.
Untuk menghapus indeks bernama SingersByFirstLastName:
DROP INDEX SingersByFirstLastName;
Indeks untuk pemindaian yang lebih cepat
Saat Spanner perlu melakukan pemindaian tabel (bukan pencarian terindeks) untuk mengambil nilai dari satu atau beberapa kolom, Anda dapat menerima hasil yang lebih cepat jika ada indeks untuk kolom tersebut, dan dalam urutan yang ditentukan oleh kueri. Jika Anda sering menjalankan kueri yang memerlukan pemindaian, sebaiknya buat indeks sekunder untuk membantu pemindaian ini terjadi secara lebih efisien.
Khususnya, jika Anda sering kali memerlukan Spanner untuk memindai kunci primer atau indeks lain dalam urutan terbalik, Anda dapat meningkatkan efisiensinya melalui indeks sekunder yang membuat urutan yang dipilih menjadi eksplisit.
Misalnya, kueri berikut selalu menampilkan hasil yang cepat, meskipun Spanner perlu memindai Songs untuk menemukan nilai terendah dari SongId:
SELECT SongId FROM Songs LIMIT 1;
SongId adalah kunci utama tabel, yang disimpan (seperti semua kunci utama)
dalam urutan menaik. Spanner dapat memindai indeks kunci tersebut dan menemukan
hasil pertama dengan cepat.
Namun, tanpa bantuan indeks sekunder, kueri berikut tidak akan
dapat ditampilkan secepat mungkin, terutama jika Songs menyimpan banyak data:
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
Meskipun SongId adalah kunci utama tabel, Spanner tidak
dapat mengambil nilai tertinggi kolom tanpa melakukan pemindaian
tabel penuh.
Menambahkan indeks berikut akan memungkinkan kueri ini ditampilkan lebih cepat:
CREATE INDEX SongIdDesc On Songs(SongId DESC);
Dengan adanya indeks ini, Spanner akan menggunakannya untuk menampilkan hasil kueri kedua dengan jauh lebih cepat.
Langkah berikutnya
- Pelajari praktik terbaik SQL untuk Spanner.
- Pahami rencana eksekusi kueri untuk Spanner.
- Cari tahu cara memecahkan masalah regresi performa dalam kueri SQL.