Teknologi penyimpanan Google mendukung beberapa aplikasi terbesar di dunia. Namun, skala tidak selalu merupakan hasil otomatis dari penggunaan sistem ini. Desainer harus memikirkan dengan cermat cara membuat model data untuk memastikan bahwa aplikasi mereka dapat diskalakan dan berperforma saat berkembang dalam berbagai dimensi.
Spanner adalah database terdistribusi, dan penggunaannya secara efektif memerlukan cara berpikir yang berbeda tentang desain skema dan pola akses dibandingkan dengan database tradisional. Sistem terdistribusi, pada dasarnya, memaksa desainer untuk memikirkan lokalitas data dan pemrosesan.
Spanner mendukung kueri dan transaksi SQL dengan kemampuan untuk melakukan penskalaan horizontal. Desain yang cermat sering kali diperlukan untuk mewujudkan manfaat penuh Spanner. Makalah ini membahas beberapa ide utama yang akan membantu Anda memastikan bahwa aplikasi Anda dapat diskalakan ke tingkat arbitrer, dan untuk memaksimalkan performanya. Dua alat secara khusus memiliki dampak besar pada skalabilitas: definisi kunci dan interleaving.
Tata letak tabel
Baris dalam tabel Spanner diatur secara leksikografis oleh PRIMARY
KEY. Secara konseptual, kunci diurutkan berdasarkan penyambungan kolom dalam urutan yang dideklarasikan dalam klausa PRIMARY KEY. Ini menunjukkan semua
properti lokalitas standar:
- Memindai tabel dalam urutan leksikografis akan lebih efisien.
- Baris yang cukup dekat akan disimpan dalam blok disk yang sama, dan akan dibaca dan di-cache bersama.
Spanner mereplikasi data Anda di beberapa zona untuk ketersediaan dan skala. Setiap zona menyimpan replika lengkap data Anda. Saat menyediakan node instance Spanner, Anda menentukan kapasitas komputasi-nya. Kapasitas komputasi adalah jumlah resource komputasi yang dialokasikan ke instance Anda di setiap zona ini. Meskipun setiap replika adalah kumpulan lengkap data Anda, data dalam replika dipartisi di seluruh resource komputasi di zona tersebut.
Data dalam setiap replika Spanner diatur ke dalam dua tingkat hierarki fisik: pemisahan database, lalu blok. Pemisahan menyimpan rentang baris yang berdekatan, dan merupakan unit yang digunakan Spanner untuk mendistribusikan database Anda di seluruh resource komputasi. Seiring waktu, pemisahan dapat dibagi menjadi bagian yang lebih kecil, digabungkan, atau dipindahkan ke node lain di instance Anda untuk meningkatkan paralelisme dan memungkinkan aplikasi Anda diskalakan. Operasi yang mencakup pemisahan lebih mahal daripada operasi setara yang tidak, karena peningkatan komunikasi. Hal ini berlaku meskipun pemisahan tersebut kebetulan ditayangkan oleh node yang sama.
Ada dua jenis tabel di Spanner: tabel root (terkadang disebut tabel tingkat atas), dan tabel sisipan. Tabel yang diselingi ditentukan dengan menentukan tabel lain sebagai induk, sehingga baris dalam tabel yang diselingi dikelompokkan dengan baris induk. Tabel root tidak memiliki induk, dan setiap baris dalam tabel root menentukan baris tingkat teratas baru, atau baris root. Baris yang diselingi dengan baris root ini disebut baris turunan, dan kumpulan baris root beserta semua turunannya disebut hierarki baris. Baris induk harus ada sebelum Anda dapat menyisipkan baris turunan. Baris induk mungkin sudah ada di database atau dapat disisipkan sebelum penyisipan baris turunan dalam transaksi yang sama.
Spanner secara otomatis mempartisi bagian jika dianggap perlu karena ukuran atau beban. Untuk mempertahankan lokalitas data, Spanner lebih memilih menambahkan batas pemisahan sesegera mungkin ke tabel root, sehingga hierarki baris tertentu dapat disimpan dalam satu pemisahan. Artinya, operasi dalam hierarki baris cenderung lebih efisien karena tidak mungkin memerlukan komunikasi dengan pemisahan lain.
Namun, jika ada hotspot di baris turunan, Spanner akan mencoba menambahkan batas pemisahan ke tabel sisipan untuk mengisolasi baris hotspot tersebut, beserta semua baris turunan di bawahnya.
Memilih tabel mana yang harus menjadi root adalah keputusan penting dalam mendesain aplikasi Anda untuk diskalakan. Root biasanya berupa hal-hal seperti Pengguna, Akun, Project, dan sejenisnya, dan tabel turunannya menyimpan sebagian besar data lainnya tentang entitas yang dimaksud.
Rekomendasi:
- Gunakan awalan kunci umum untuk baris terkait dalam tabel yang sama untuk meningkatkan lokalitas.
- Gabungkan data terkait ke dalam tabel lain jika memungkinkan.
Kompromi lokalitas
Jika data sering ditulis atau dibaca bersama, hal ini dapat menguntungkan latensi dan throughput untuk mengelompokkan data dengan memilih kunci utama dengan cermat dan menggunakan interleaving. Hal ini karena ada biaya tetap untuk berkomunikasi dengan server atau blok disk apa pun, jadi mengapa tidak mendapatkan sebanyak mungkin saat berada di sana? Selain itu, semakin banyak server yang Anda komunikasikan, semakin tinggi kemungkinan Anda akan menemukan server yang sibuk untuk sementara, sehingga meningkatkan latensi ekor. Terakhir, transaksi yang mencakup pemisahan, meskipun otomatis dan transparan di Spanner, memiliki biaya dan latensi CPU yang sedikit lebih tinggi karena sifat terdistribusi dari commit dua fase.
Di sisi lain, jika data terkait tetapi tidak sering diakses bersama, pertimbangkan untuk memisahkannya. Hal ini memiliki manfaat paling besar jika data yang jarang diakses berukuran besar. Misalnya, banyak database menyimpan data biner besar di luar band dari data baris utama, dengan hanya referensi ke data besar yang diselingi.
Perhatikan bahwa beberapa tingkat operasi data non-lokal dan commit dua fase tidak dapat dihindari dalam database terdistribusi. Jangan terlalu khawatir dengan mendapatkan cerita lokalitas yang sempurna untuk setiap operasi. Berfokuslah untuk mendapatkan lokalitas yang diinginkan untuk entity root yang paling penting dan pola akses yang paling umum, dan biarkan operasi terdistribusi yang kurang sering atau kurang sensitif terhadap performa terjadi saat diperlukan. Commit dua fase dan pembacaan terdistribusi ada untuk membantu menyederhanakan skema dan meringankan beban programmer: dalam semua kasus penggunaan kecuali kasus penggunaan yang paling penting untuk performa, sebaiknya biarkan saja.
Rekomendasi:
- Atur data Anda ke dalam hierarki sehingga data yang dibaca atau ditulis bersama cenderung berada di sekitar.
- Pertimbangkan untuk menyimpan kolom besar dalam tabel yang tidak disisipkan jika lebih jarang diakses.
Opsi indeks
Indeks sekunder memungkinkan Anda menemukan baris dengan cepat berdasarkan nilai selain kunci utama. Spanner mendukung indeks yang tidak interleaved dan interleaved. Indeks non-interleaved adalah default dan jenis yang paling analog dengan yang didukung di RDBMS tradisional. Algoritma ini tidak menempatkan batasan apa pun pada kolom yang diindeks dan, meskipun canggih, algoritma ini tidak selalu menjadi pilihan terbaik. Indeks interleaved harus ditentukan di kolom yang memiliki awalan yang sama dengan tabel induk, dan memungkinkan kontrol lokalitas yang lebih besar.
Spanner menyimpan data indeks dengan cara yang sama seperti tabel, dengan satu baris per entri indeks. Banyak pertimbangan desain untuk tabel juga berlaku untuk indeks. Indeks non-interleaved menyimpan data dalam tabel root. Karena tabel root dapat dibagi di antara baris root mana pun, hal ini memastikan bahwa indeks non-interleaved dapat diskalakan ke ukuran arbitrer dan, dengan mengabaikan hot spot, ke hampir semua beban kerja. Sayangnya, hal ini juga berarti bahwa entri indeks biasanya tidak berada dalam bagian yang sama dengan data utama. Hal ini akan menimbulkan pekerjaan dan latensi tambahan untuk setiap proses penulisan, dan menambahkan pemisahan tambahan untuk dikonsultasikan pada waktu pembacaan.
Sebaliknya, indeks interleaved menyimpan data dalam tabel interleaved. Fungsi ini cocok saat Anda menelusuri dalam domain satu entitas. Indeks yang diselingi memaksa data dan entri indeks tetap berada dalam hierarki baris yang sama, sehingga penggabungan di antara keduanya jauh lebih efisien. Contoh penggunaan untuk indeks interleave:
- Mengakses foto Anda berdasarkan berbagai urutan pengurutan seperti tanggal diambil, tanggal terakhir diubah, judul, album, dll.
- Menemukan semua postingan Anda yang memiliki kumpulan tag tertentu.
- Menemukan pesanan belanja saya sebelumnya yang berisi item tertentu.
Rekomendasi:
- Gunakan indeks non-interleaved jika Anda perlu menemukan baris dari mana saja di database.
- Pilih indeks yang diselingi setiap kali penelusuran Anda dicakupkan ke satu entitas.
Klausa indeks STORING
Indeks sekunder memungkinkan Anda menemukan baris berdasarkan atribut selain kunci utama. Jika semua data yang diminta ada dalam indeks itu sendiri, data tersebut dapat dikonsultasikan sendiri tanpa membaca data utama. Hal ini dapat menghemat resource yang signifikan karena tidak diperlukan penggabungan.
Sayangnya, kunci indeks dibatasi hingga 16 dan ukuran agregatnya sebesar 8 KiB, sehingga membatasi apa yang dapat dimasukkan ke dalamnya. Untuk mengimbangi batasan ini,
Spanner memiliki kemampuan untuk menyimpan data tambahan dalam indeks apa pun, melalui
klausa STORING. STORING kolom dalam indeks akan menyebabkan nilainya
diduplikasi, dengan salinan yang disimpan dalam indeks. Anda dapat menganggap indeks dengan
STORING sebagai tampilan terwujud tabel tunggal sederhana (tampilan tidak didukung secara native
di Spanner saat ini).
Aplikasi STORING lainnya yang berguna adalah sebagai bagian dari indeks NULL_FILTERED.
Hal ini memungkinkan Anda menentukan tampilan terwujud yang efektif dari subkumpulan tabel
yang jarang yang dapat Anda pindai secara efisien. Misalnya, Anda dapat membuat
indeks tersebut di kolom is_unread kotak surat agar dapat menayangkan
tampilan pesan yang belum dibaca dalam satu pemindaian tabel, tetapi tanpa membayar salinan lengkap
setiap kotak surat.
Rekomendasi:
- Gunakan
STORINGdengan cermat untuk mengorbankan performa waktu baca dengan ukuran penyimpanan dan performa waktu tulis. - Gunakan
NULL_FILTEREDuntuk mengontrol biaya penyimpanan indeks jarang.
Antipola
Anti-pola: pengurutan stempel waktu
Banyak desainer skema cenderung menentukan tabel root yang diurutkan berdasarkan stempel waktu, dan diperbarui pada setiap operasi tulis. Sayangnya, ini adalah salah satu hal yang paling tidak dapat diskalakan yang dapat Anda lakukan. Alasannya adalah desain ini menghasilkan hot spot besar di akhir tabel yang tidak dapat dimitigasi dengan mudah. Seiring peningkatan kecepatan tulis, RPC ke satu bagian juga akan meningkat, begitu juga dengan peristiwa pertentangan kunci dan masalah lainnya. Sering kali masalah semacam ini tidak muncul dalam pengujian beban kecil, dan muncul setelah aplikasi diproduksi selama beberapa waktu. Pada saat itu, sudah terlambat.
Jika aplikasi Anda benar-benar harus menyertakan log yang diurutkan berdasarkan stempel waktu, pertimbangkan apakah Anda dapat membuat log menjadi lokal dengan menyisipkannya di salah satu tabel root lain. Hal ini memiliki manfaat untuk mendistribusikan hot spot ke banyak root. Namun, Anda tetap harus berhati-hati agar setiap root yang berbeda memiliki rasio tulis yang cukup rendah.
Jika Anda memerlukan tabel yang diurutkan berdasarkan stempel waktu global (lintas root), dan Anda perlu
mendukung kecepatan tulis yang lebih tinggi ke tabel tersebut daripada yang dapat dilakukan satu node, gunakan
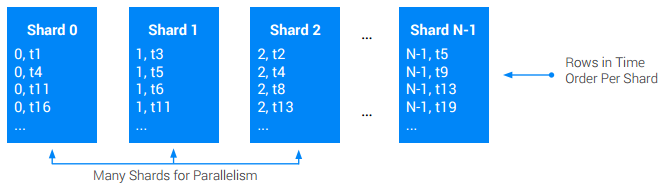
sharding tingkat aplikasi. Sharding tabel berarti mempartisi tabel menjadi beberapa pembagian yang kira-kira sama, yang disebut shard. Hal ini biasanya dilakukan dengan
menambahkan awalan kunci utama asli dengan kolom ShardId tambahan yang menyimpan
nilai bilangan bulat antara [0, N). ShardId untuk operasi tulis tertentu biasanya
dipilih secara acak, atau dengan melakukan hashing pada bagian kunci dasar. Hashing sering kali lebih disukai karena dapat digunakan untuk memastikan semua data dari jenis tertentu masuk ke shard yang sama, sehingga meningkatkan performa pengambilan. Apa pun caranya, tujuannya adalah
untuk memastikan bahwa, dari waktu ke waktu, operasi tulis didistribusikan di semua shard secara merata.
Pendekatan ini terkadang berarti bahwa pembacaan perlu memindai semua shard untuk merekonstruksi
urutan total penulisan asli.
Rekomendasi:
- Hindari tabel dan indeks yang diurutkan stempel waktu dengan kecepatan tulis tinggi dengan segala cara.
- Gunakan beberapa teknik untuk menyebarkan hot spot, baik interleaving di tabel lain atau sharding.
Antipola: urutan
Developer aplikasi suka menggunakan urutan database (atau penambahan otomatis) untuk membuat kunci utama. Sayangnya, kebiasaan ini dari masa RDBMS (disebut kunci pengganti) hampir sama berbahayanya dengan anti-pola pengurutan stempel waktu yang dijelaskan di atas. Alasannya adalah urutan database cenderung memunculkan nilai dengan cara kuasi-monoton, dari waktu ke waktu, untuk menghasilkan nilai yang dikelompokkan di dekat satu sama lain. Hal ini biasanya menghasilkan hot spot saat digunakan sebagai kunci utama, terutama untuk baris root.
Berbeda dengan pendapat umum RDBMS, sebaiknya gunakan atribut dunia nyata untuk kunci utama jika memungkinkan. Hal ini terutama berlaku jika atribut tidak akan pernah berubah.
Jika Anda ingin membuat kunci utama unik numerik, usahakan untuk mendapatkan bit urutan tinggi dari angka berikutnya yang didistribusikan secara merata di seluruh ruang angka. Salah satu triknya adalah membuat angka berurutan dengan cara konvensional, lalu membalikkan bit untuk mendapatkan nilai akhir. Atau, Anda dapat melihat generator UUID, tetapi berhati-hatilah: tidak semua fungsi UUID dibuat secara setara, dan beberapa menyimpan stempel waktu dalam bit urutan tinggi, yang secara efektif mengalahkan manfaatnya. Pastikan generator UUID Anda memilih bit urutan tinggi secara pseudo-acak.
Rekomendasi:
- Hindari penggunaan nilai urutan penambahan sebagai kunci utama. Sebagai gantinya, lakukan bit-reverse pada nilai urutan, atau gunakan UUID yang dipilih dengan cermat.
- Gunakan nilai dunia nyata untuk kunci utama, bukan kunci pengganti.