Übersicht
Diese Seite enthält Konzepte zu Abfrageausführungsplänen sowie dazu, wie diese von Spanner verwendet werden, um Abfragen in einer verteilten Umgebung durchzuführen. Informationen zum Abrufen eines Ausführungsplans für eine bestimmte Abfrage mit derGoogle Cloud -Konsole finden Sie unter So werden Abfragen von Spanner ausgeführt. Sie können sich auch Stichproben aus vergangenen Abfrageplänen ansehen und die Leistung einer Abfrage im Zeitverlauf für bestimmte Abfragen vergleichen. Weitere Informationen finden Sie unter Abgetastete Abfragepläne.
Spanner verwendet deklarative SQL-Anweisungen, um Datenbankabfragen durchzuführen. SQL-Anweisungen definieren, was der Nutzer möchte, ohne anzugeben, wie die Ergebnisse zu erhalten sind. Ein Abfrageausführungsplan beinhaltet eine Reihe von Schritten, mit denen die Ergebnisse erzielt werden sollen. Bei einer gegebenen SQL-Anweisung kann es mehrere Möglichkeiten geben, die Ergebnisse zu erhalten. Das Abfrageoptimierungstool von Spanner wertet verschiedene Ausführungspläne aus und wählt denjenigen aus, der als der effizienteste betrachtet wird. Anschließend verwendet Spanner den Ausführungsplan, um die Ergebnisse abzurufen.
Das Konzept eines Abfrageausführungsplans ist eine Struktur relationaler Operatoren. Jeder Operator liest Zeilen aus seinen Eingaben und erzeugt Ausgabezeilen. Das Ergebnis des Operators am Stammverzeichnis der Ausführung wird als Ergebnis der SQL-Abfrage zurückgegeben.
Im Folgenden ist ein Beispiel aufgeführt. Die Abfrage
SELECT s.SongName FROM Songs AS s;
führt zu einem Abfrageausführungsplan, der so visualisiert werden kann:
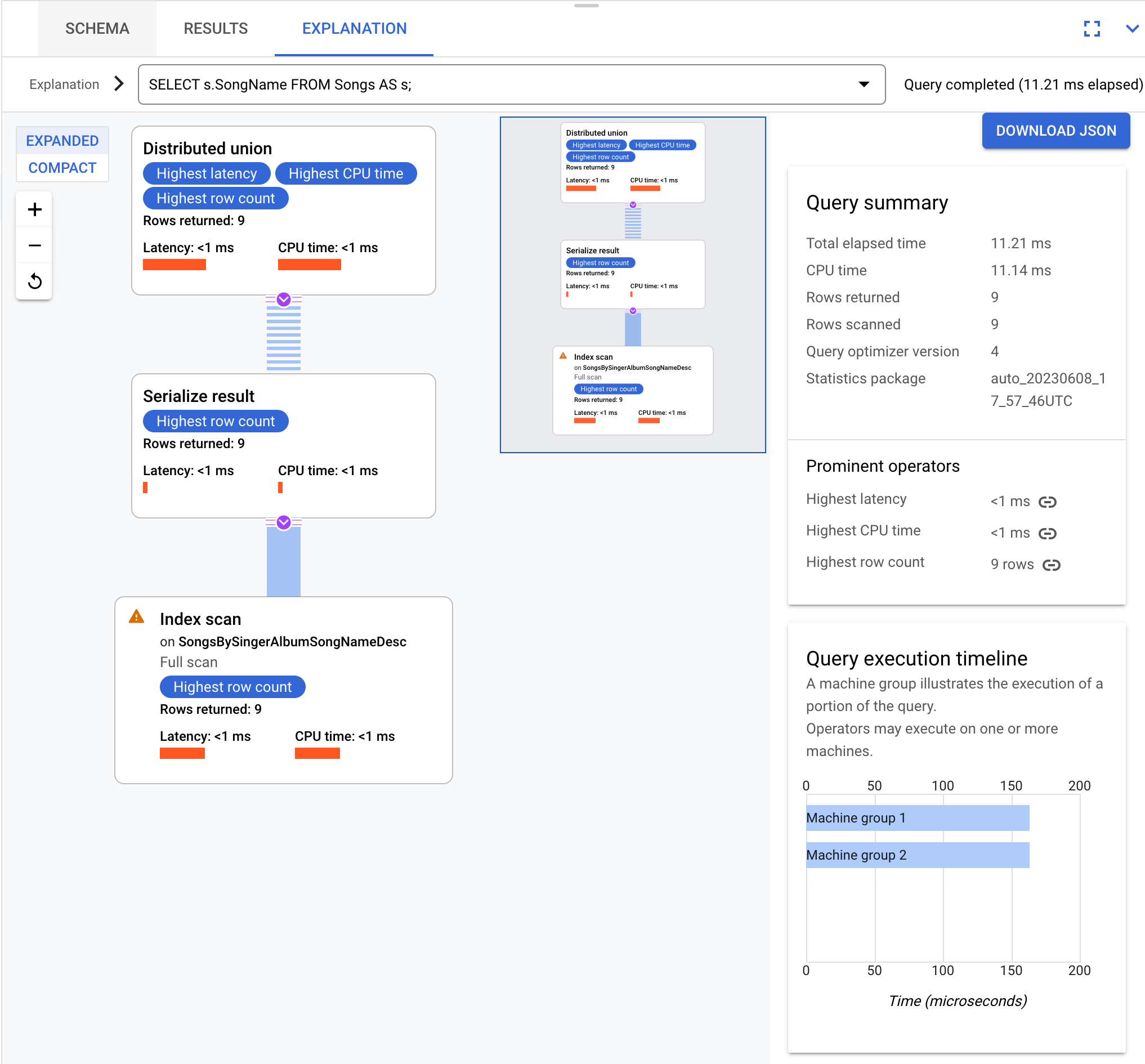
Die Abfragen und Ausführungspläne auf dieser Seite basieren auf dem folgenden Datenbankschema:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Sie können die folgenden DML-Anweisungen (Data Manipulation Language) verwenden, um diesen Tabellen Daten hinzuzufügen:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Die Erstellung effizienter Ausführungspläne ist schwierig, da Spanner die Daten in Splits unterteilt. Splits können sich unabhängig voneinander bewegen und verschiedenen Servern zugewiesen werden, die sich an verschiedenen physischen Standorten befinden können. Um die Ausführungspläne über die verteilten Daten auszuwerten, verwendet Spanner eine Ausführung basierend auf:
- der lokalen Ausführung von Teilplänen auf Servern, die die Daten enthalten
- der Orchestrierung und Aggregation mehrerer Remote-Ausführungen mit aggressiver Distributionsbereinigung
Spanner verwendet den einfachen Operator distributed union zusammen mit dessen Varianten distributed cross apply und distributed outer apply, um dieses Modell zu aktivieren.
Stichproben für Abfragepläne
Mit Stichproben von Abfrageplänen in Spanner können Sie sich Beispiele für bisherige Abfragepläne ansehen und die Leistung einer Abfrage im Zeitverlauf vergleichen. Für nicht alle Abfragen sind Stichprobenabfragepläne verfügbar. Es werden möglicherweise nur Abfragen mit höherem CPU-Verbrauch abgetastet. Die Datenaufbewahrung für Spanner-Abfrageplanproben beträgt 30 Tage. Beispielabfragepläne finden Sie auf der Seite Abfragestatistiken der Google Cloud Console. Eine Anleitung finden Sie unter Beispielabfragepläne ansehen.
Ein Beispielabfrageplan ist mit einem regulären Abfrageausführungsplan identisch. Weitere Informationen zu visuellen Plänen und ihrer Verwendung zur Fehlerbehebung bei Abfragen finden Sie unter Einführung in den Abfrageplanervisualisierer.
Gängige Anwendungsfälle für Stichprobenerhebungen:
Hier einige häufige Anwendungsfälle für Stichprobenerhebungen:
- Beobachten Sie Änderungen am Abfrageplan aufgrund von Schemaänderungen, z. B. das Hinzufügen oder Entfernen eines Index.
- Beobachten Sie Änderungen am Abfrageplan aufgrund einer Aktualisierung der Optimizerversion.
- Beobachten Sie Änderungen am Abfrageplan aufgrund von neuen Optimierungsstatistiken, die alle drei Tage automatisch erfasst oder manuell mit dem Befehl
ANALYZEausgeführt werden.
Wenn sich die Leistung einer Abfrage im Laufe der Zeit erheblich unterscheidet oder Sie die Leistung einer Abfrage verbessern möchten, lesen Sie die Best Practices für SQL. Dort erfahren Sie, wie Sie optimierte Abfrageanweisungen erstellen, mit denen Spanner effiziente Ausführungspläne finden kann.
Phasen einer Abfrage
Eine SQL-Abfrage in Spanner wird zuerst in einen Ausführungsplan kompiliert und anschließend zur Ausführung an einen ersten Root-Server gesendet. Der Root-Server ist so gewählt, dass die Anzahl der Sprünge (Hops), die die abgefragten Daten erreichen, minimiert wird. Anschließend führt der Root-Server folgende Schritte durch:
- Initiierung der Remote-Ausführung von Teilplänen (falls erforderlich)
- Warten auf die Ergebnisse der Remote-Ausführungen
- Verwaltung aller verbleibenden lokalen Ausführungsschritte, z. B. das Aggregieren von Ergebnissen
- Zurückgabe der Ergebnisse für die Abfrage
Remote-Server, die einen Teilplan erhalten, fungieren als "Root"-Server für ihren Teilplan und folgen demselben Modell wie der oberste Root-Server. Das Ergebnis ist eine Struktur von Remote-Ausführungen. Die Abfrageausführung wird konzeptionell von oben nach unten ausgeführt und Abfrageergebnisse werden von unten nach oben zurückgegeben. Das folgende Diagramm veranschaulicht das Muster:

Die folgenden Beispiele veranschaulichen dieses Muster genauer.
Aggregatabfragen
Eine Aggregatabfrage implementiert GROUP BY-Abfragen.
Wenn Sie zum Beispiel diese Abfrage verwenden:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
Dies sind die Ergebnisse:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
Dies ist das Konzept des Ausführungsplans:
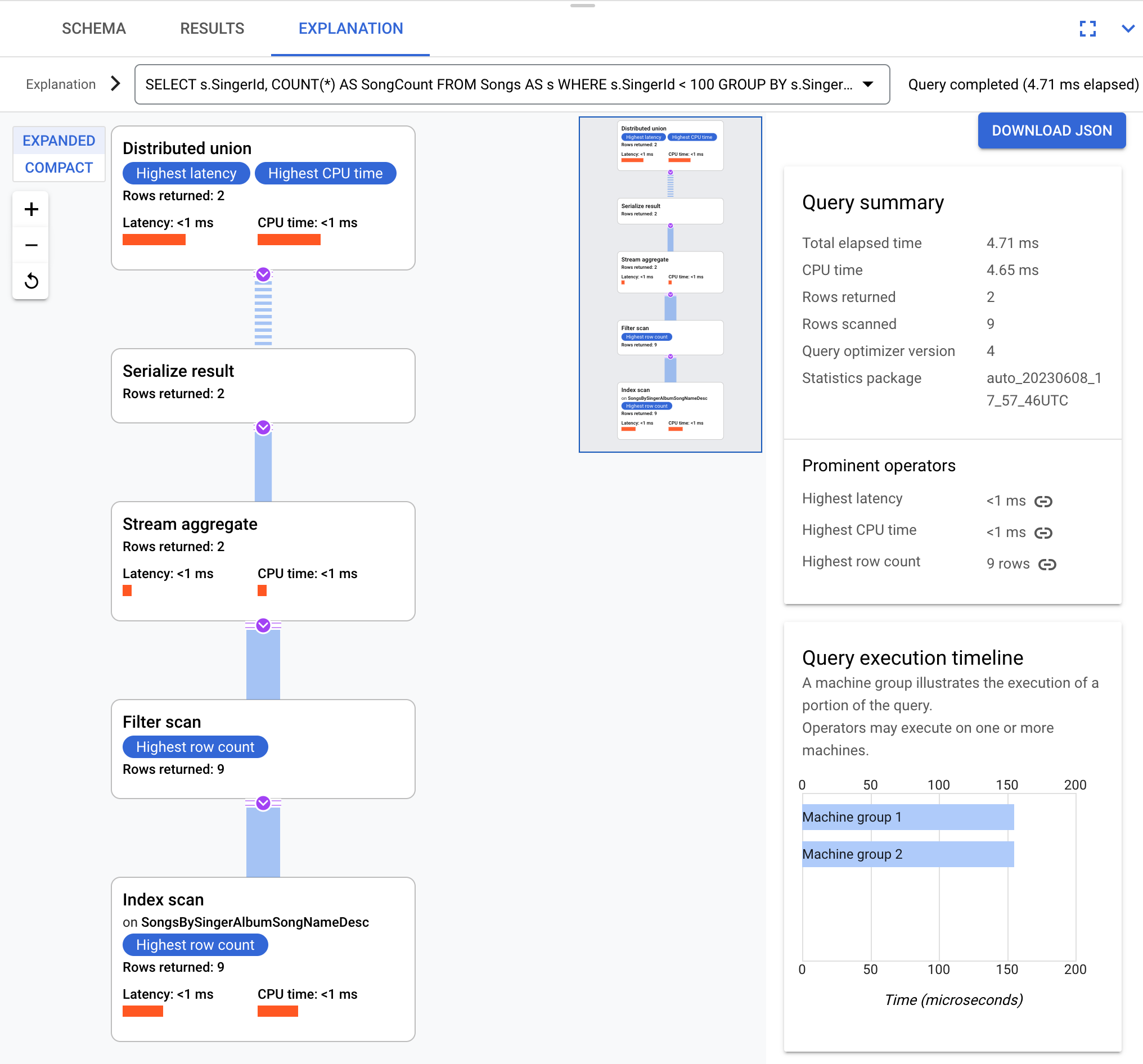
Spanner sendet den Ausführungsplan an einen Root-Server, der die Abfrageausführung koordiniert und die Fernverteilung von Teilplänen ausführt.
Dieser Ausführungsplan beginnt mit dem verteilten Operator „Distributed Union“, der Teilpläne an Remoteserver verteilt, deren Aufteilung SingerId < 100 erfüllt. Nach Abschluss des Scans der einzelnen Teilungen werden mit dem Operator Stream Aggregate Zeilen zusammengefasst, um die Anzahlen für jede SingerId zu erhalten. Der Operator Serialize Result serialisiert dann das Ergebnis. Schließlich werden alle Ergebnisse von der Distributed Union zusammengeführt und die Abfrageergebnisse zurückgegeben.
Unter Operator Aggregate können Sie mehr über Aggregate erfahren.
Zusammengelegte Join-Abfragen
Verschränkte Tabellen werden gemeinsam mit ihren Zeilen zusammengehöriger Tabellen gespeichert. Ein zusammengelegter Join ist eine Verbindung zwischen verschränkten Tabellen. Zusammengelegte Joins können Leistungsverbesserungen gegenüber Joins bieten, für die Indizes oder Back-Joins erforderlich sind.
Wenn Sie zum Beispiel diese Abfrage verwenden:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(Bei dieser Abfrage wird davon ausgegangen, dass Songs mit Albums verschränkt ist.)
Dies sind die Ergebnisse:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
Dies ist der Ausführungsplan:
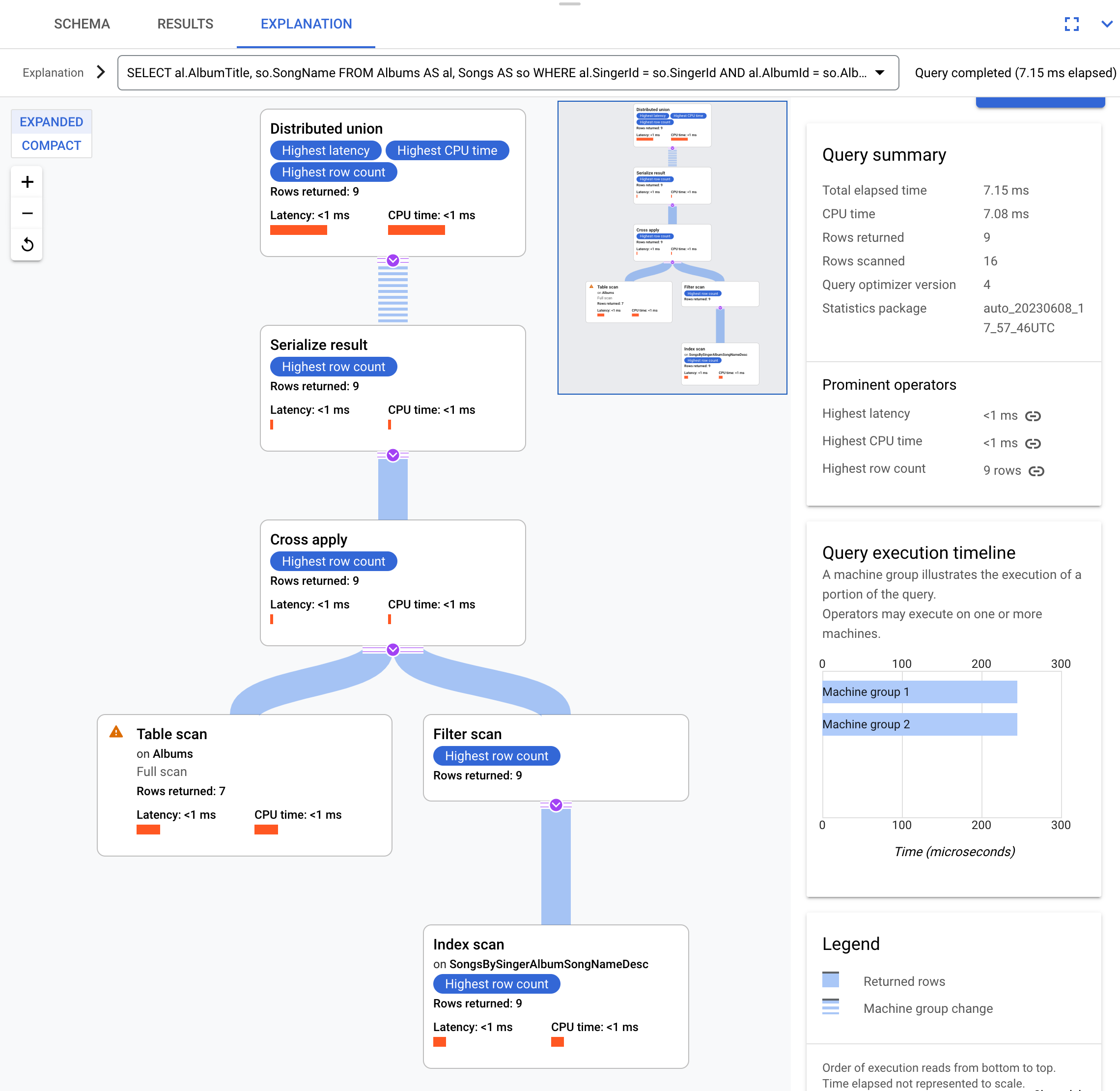
Dieser Ausführungsplan beginnt mit dem Operator Distributed Union. Er verteilt Teilpläne an Remoteserver, die Splits der Tabelle Albums haben.
Da es sich bei Songs um eine verschränkte Tabelle von Albums handelt, kann jeder Remote-Server den gesamten Teilplan auf jedem Remote-Server ausführen, ohne dass eine Verbindung zu einem anderen Server hergestellt werden muss.
Die Teilpläne enthalten einen Cross Apply. Jeder Cross Apply führt einen Tabellenscan (Scan) der Tabelle Albums aus, um SingerId, AlbumId und AlbumTitle abzurufen. Der Cross Apply-Vorgang ordnet dann die Ausgabe aus dem Tabellenscan der Ausgabe eines Indexscans des Indexes SongsBySingerAlbumSongNameDesc zu. Dazu muss die gefilterte SingerId im Index mit der SingerId aus der Ausgabe des Tabellenscans übereinstimmen. Jeder Cross Apply-Vorgang sendet seine Ergebnisse an einen Operator des Typs Serialize Result, der die Daten von AlbumTitle und SongName serialisiert und an die lokalen Distributed Unions zurückgibt. Die Distributed Union aggregiert die Ergebnisse der Local Distributed Unions und gibt sie als Abfrageergebnis zurück.
Index- und Back-Join-Abfragen
Bei dem oben stehenden Beispiel wurde ein Join für zwei Tabellen verwendet, von denen eine mit der anderen verschränkt ist. Ausführungspläne sind komplexer und weniger effizient, wenn zwei Tabellen oder eine Tabelle und ein Index nicht verschränkt sind.
Betrachten Sie einen Index, der mit dem folgenden Befehl erstellt wurde:
CREATE INDEX SongsBySongName ON Songs(SongName)
Verwenden Sie diesen Index in dieser Abfrage:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Dies sind die Ergebnisse:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
Dies ist der Ausführungsplan:
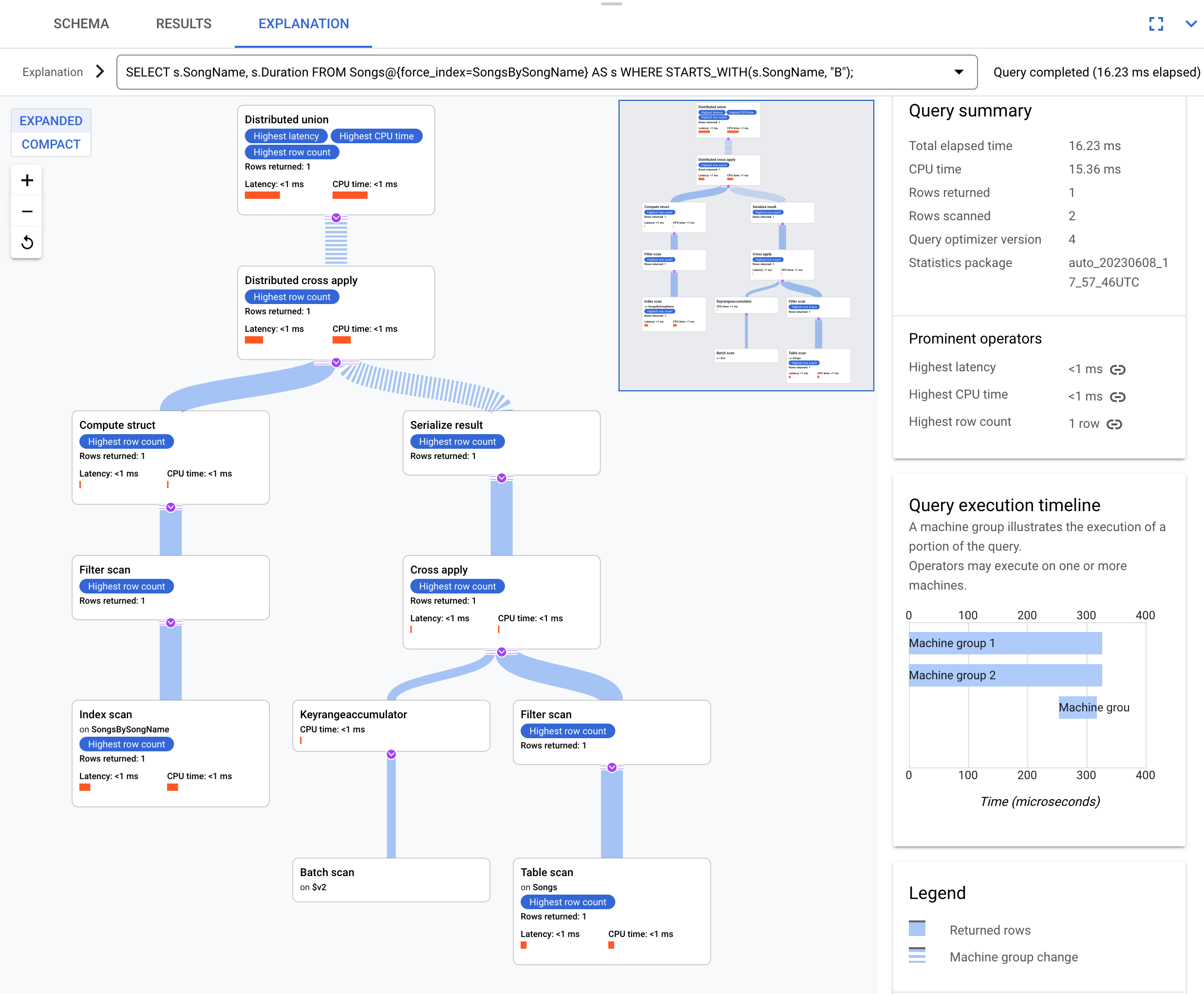
Der resultierende Ausführungsplan ist kompliziert, weil der Index SongsBySongName nicht die Spalte Duration enthält. Damit Sie den Wert Duration erhalten, muss Spanner die indexierten Ergebnisse per Back-Join mit der Tabelle Songs verschränken. Dies ist ein Join, der aber nicht den gleichen Standort hat, denn die Songs-Tabelle und der globale Index SongsBySongName sind nicht verschränkt. Der resultierende Ausführungsplan ist komplexer als das Beispiel für zusammengelegte Joins, da Spanner Optimierungen durchführt, um die Ausführung zu beschleunigen, wenn die Daten nicht zusammengelegt wurden.
Der oberste Operator ist ein Distributed Cross Apply. Auf der Eingabeseite des Operators befinden sich Reihen aus dem Index SongsBySongName, die das Prädikat STARTS_WITH(s.SongName, "B") erfüllen. Der Distributed Cross Apply ordnet diese Reihen anschließend den Remote-Servern zu, deren Splits die Duration-Daten enthalten. Die Remote-Server verwenden einen Tabellenscan, um die Spalte Duration abzurufen.
Der Tabellenscan verwendet den Filter Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), der den Operator TrackId aus der Tabelle Songs mit dem Operator TrackId der Zeilen verknüpft, die aus dem Index SongsBySongName übernommen wurden.
Die Ergebnisse werden in der abschließenden Abfrageantwort zusammengefasst. Die Eingangsseite des Distributed Cross Apply enthält wiederum ein Paar aus Distributed Union/Local Distributed Union, um Zeilen aus dem Index auszuwerten, die das Prädikat STARTS_WITH erfüllen.
Unten sehen Sie eine leicht abgewandelte Abfrage, bei der die Spalte s.Duration nicht ausgewählt ist:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Wie in diesem Ausführungsplan gezeigt wird, kann diese Abfrage den Index voll ausnutzen:
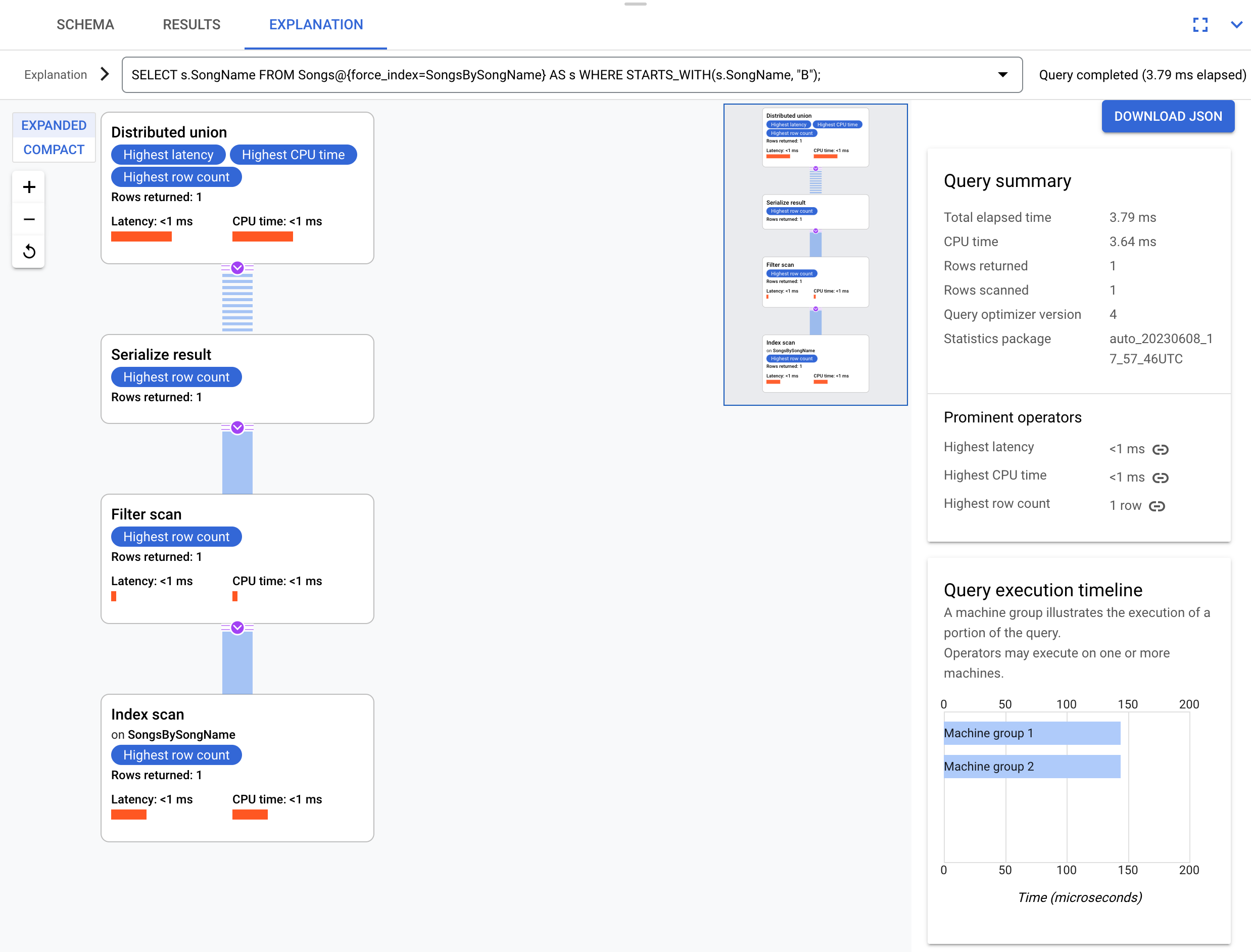
Der Ausführungsplan erfordert kein Back-Join, da alle von der Abfrage angeforderten Spalten im Index vorhanden sind.