概览
本页面介绍有关查询执行计划的概念以及 Spanner 如何使用它们在分布式环境中执行查询。如需了解如何使用Google Cloud 控制台检索特定查询的执行计划,请参阅了解 Spanner 如何执行查询。您还可以查看采样历史查询计划,并针对某些查询比较一段时间内的查询性能。如需了解详情,请参阅采样查询计划。
Spanner 使用声明性 SQL 语句来查询其数据库。SQL 语句定义用户想要什么结果,而不指定如何获取结果。查询执行计划是旨在获取结果的一系列步骤。对于指定的 SQL 语句,获取结果的方式可能有多种。Spanner 查询优化器会评估不同的执行计划,并选择其认为最高效的计划。然后,Spanner 使用该执行计划检索结果。
从概念上讲,执行计划是关系运算符构成的树。每个运算符从其输入读取行并生成输出行。位于执行计划根部的运算符的结果会作为 SQL 查询结果返回。
以下为一个示例查询:
SELECT s.SongName FROM Songs AS s;
上述查询会生成一个查询执行计划,该计划的可视化图表如下:
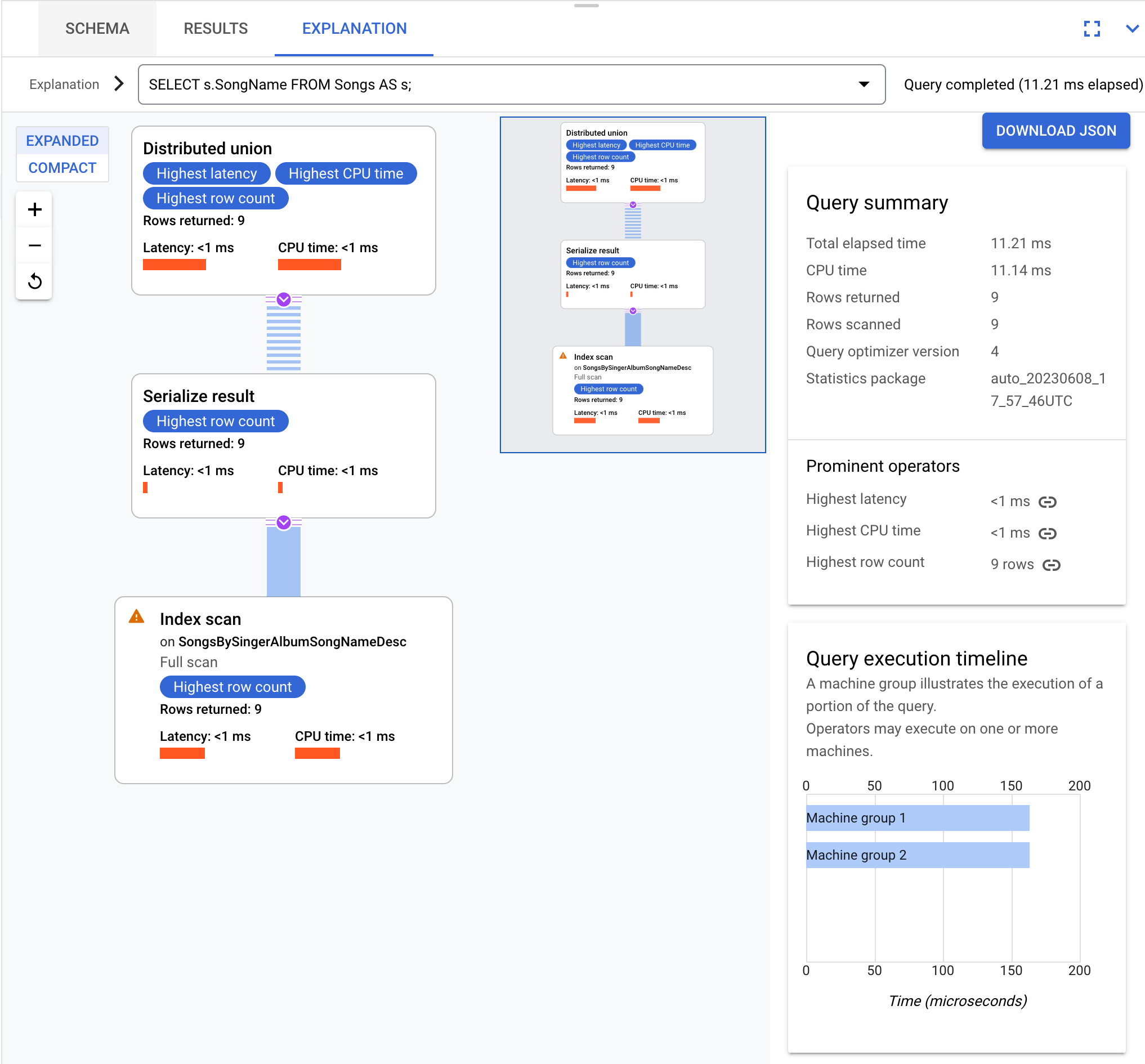
此页面上的查询和执行计划基于以下数据库架构:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
您可以使用以下数据操纵语言 (DML) 语句向这些表中添加数据:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
获取高效的执行计划具有挑战性,因为 Spanner 会将数据划分为多个分块。各个分片可以彼此独立移动并被分配给不同的服务器,这些服务器可以位于不同的物理位置。为了评估针对分布式数据的执行计划,Spanner 使用的执行基于以下内容:
- 包含数据的服务器中子计划的本地执行
- 多个远程执行的编排和聚合(通过积极的分布修剪)
Spanner 使用初始运算符 distributed union 及其变体 distributed cross apply 和 distributed outer apply 来启用此模型。
采样查询计划
借助 Spanner 采样查询计划,您可以查看历史查询计划的样本,并比较一段时间内的查询性能。并非所有查询都具有采样查询计划。系统可能只会对 CPU 耗用量较高的查询进行采样。Spanner 查询计划样本的数据保留期限为 30 天。您可以在 Google Cloud 控制台的 Query Insights 页面上找到查询计划样本。如需查看相关说明,请参阅查看采样查询计划。
采样查询计划的结构与常规查询执行计划的结构相同。如需详细了解如何理解可视化计划并使用它们来调试查询,请参阅浏览查询计划可视化工具。
采样查询计划的常见应用场景:
采样查询计划的一些常见应用场景包括:
- 观察因架构更改(例如,添加或移除索引)而导致的查询计划变化。
- 观察因优化器版本更新而导致的查询计划变化。
- 观察因新的优化器统计信息而导致的查询计划变化(这些统计信息每三天自动收集一次,也可以使用
ANALYZE命令手动收集)。
如果查询的性能随时间推移而出现显著差异,或者您想提高查询的性能,请参阅 SQL 最佳实践来构建优化的查询语句,以帮助 Spanner 找到高效的执行计划。
查询生命周期
Spanner 中的 SQL 查询首先被编译为执行计划,然后发送给初始根服务器以便执行。选择根服务器是为了尽量减少到达所查询数据所需的跃点数。然后根服务器会执行以下操作:
- 启动子计划的远程执行(如有必要)
- 等待远程执行的结果
- 处理剩余的本地执行步骤,例如聚合结果
- 返回查询的结果
接收子计划的远程服务器充当其子计划的“根”服务器,采用与最顶层根服务器相同的模型。其结果是一个远程执行树。从概念上讲,查询执行从上到下进行,而查询结果自下而上返回。下图展示了这种模式:

以下示例更详细地说明了这种模式。
聚合查询
聚合查询实现 GROUP BY 查询。
例如,使用以下查询:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
以下为查询结果:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
从概念上讲,以下为执行计划:
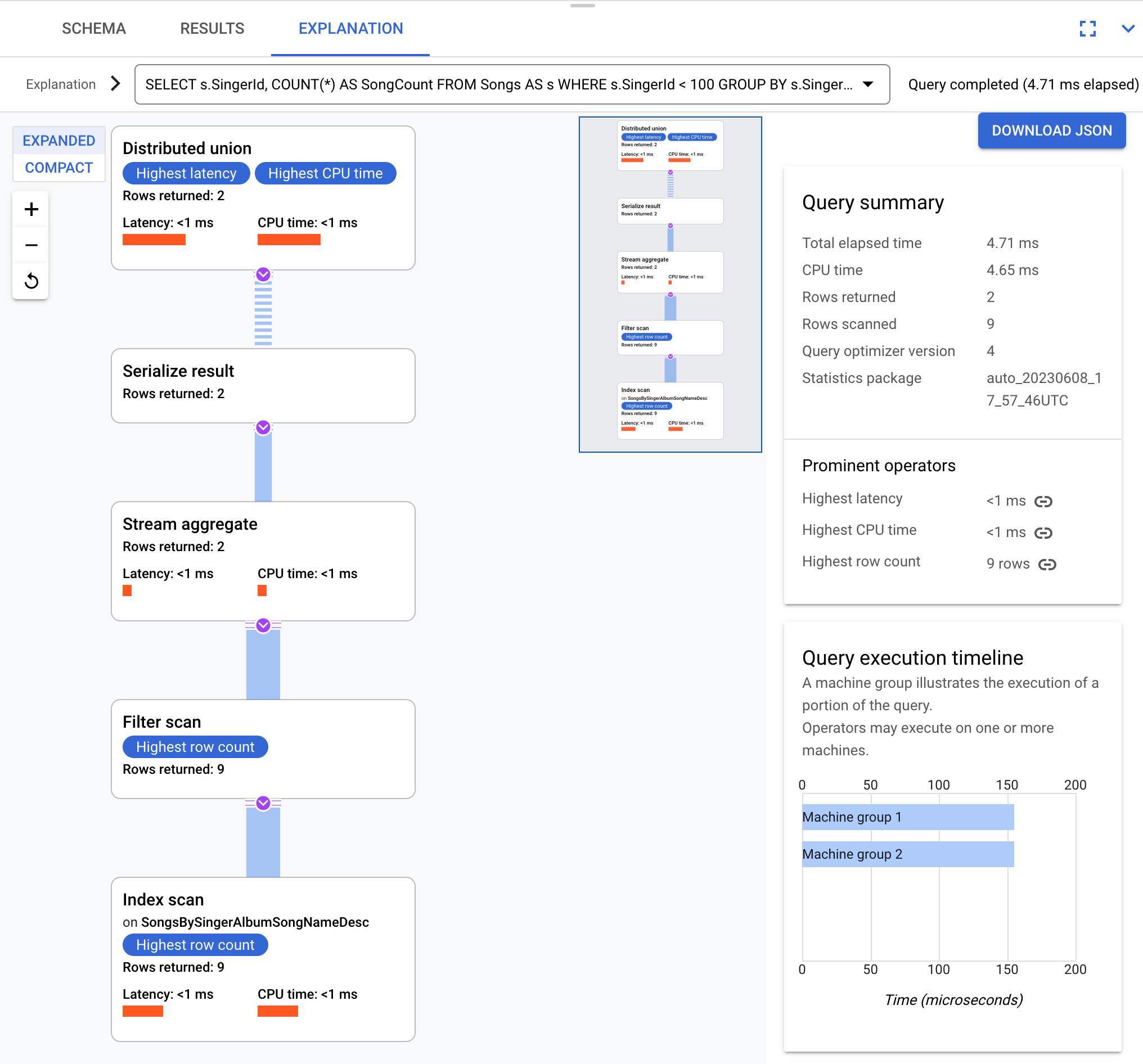
Spanner 将执行计划发送给协调查询执行的根服务器并执行子计划的远程分布。
此执行计划从分布式联合开始,这会将子计划分布到其分块满足 SingerId < 100 的远程服务器。在各个分块上完成扫描后,流聚合运算符会聚合行,以获取每个 SingerId 的数量。然后,序列化结果运算符会对结果进行序列化。最后,分布式联合会将所有结果组合在一起并返回查询结果。
如需详细了解聚合,请参阅聚合运算符。
同位联接查询
交错表以物理方式与它们的相关表的行存储于同一位置。同位联接是指交错表之间的联接。与需要索引的联接或后向联接相比,同位联接具备更高的性能优势。
例如,使用以下查询:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(此查询假定 Songs 在 Albums 中交错。)
以下为查询结果:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
以下为执行计划:
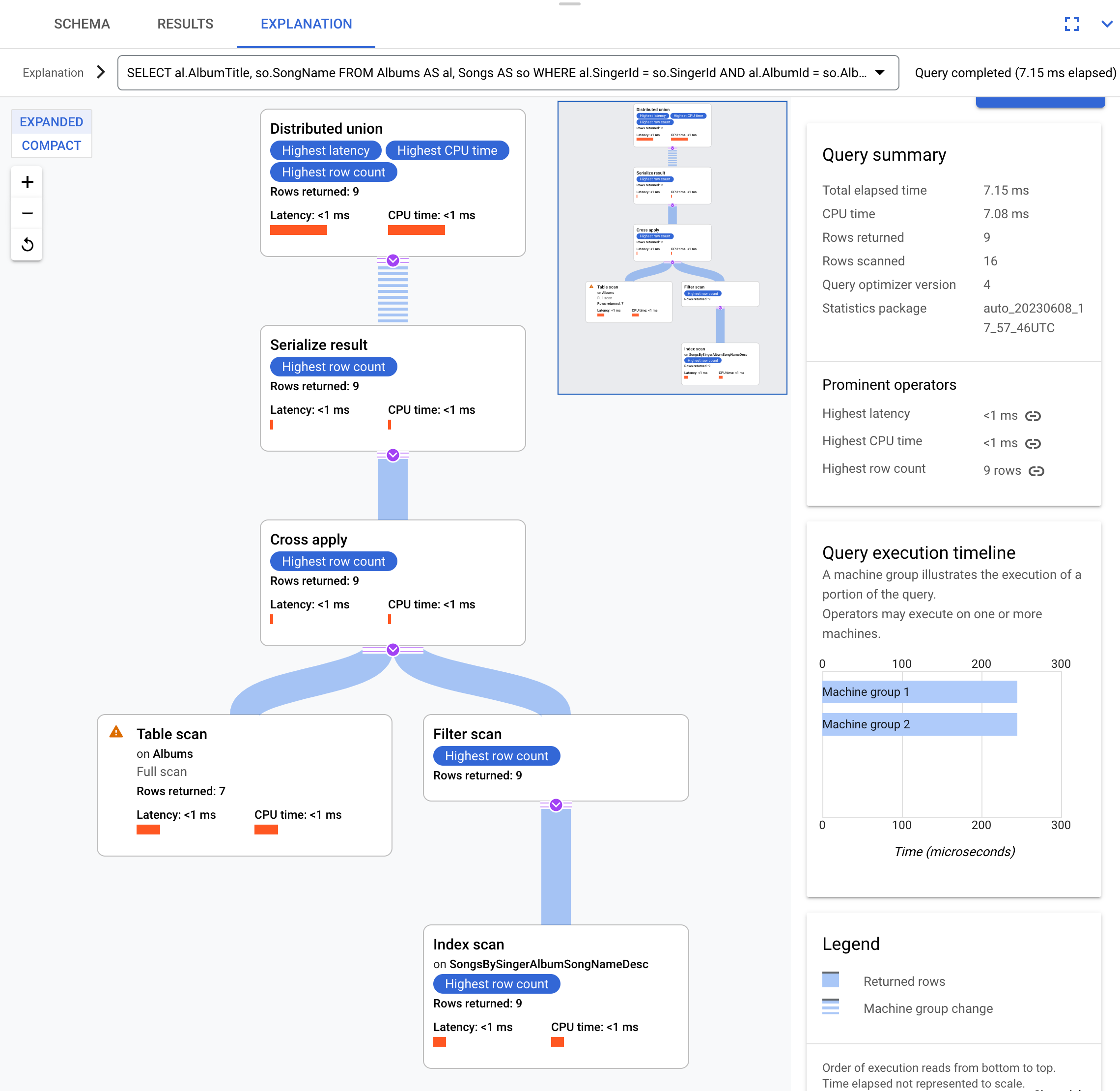
此执行计划从分布式联合开始,这会将子计划分布到具有表 Albums 的分块的远程服务器。由于 Songs 是 Albums 的交错表,因此每台远程服务器都可以在每台远程服务器上执行整个子计划,而无需联接不同的服务器。
子计划包含交叉应用。每个交叉应用对表 Albums 执行表扫描以检索 SingerId、AlbumId 和 AlbumTitle。然后,交叉应用将表扫描的输出映射到对索引 SongsBySingerAlbumSongNameDesc 进行的索引扫描的输出,同时需满足以下过滤条件:索引中的 SingerId 与表扫描输出中的 SingerId 匹配。每个交叉应用会将其结果传递给序列化结果运算符,该运算符会将 AlbumTitle 和 SongName 数据序列化并将结果返回给局部分布式联合。分布式联合聚合来自局部分布式联合的结果,并将其作为查询结果返回。
索引和后向联接查询
上面的例子对两个表上使用了一个联接,两个表互相交错。当两个表(或一个表和一个索引)未交错时,执行计划会更复杂且效率更低。
请参考使用以下命令创建的索引:
CREATE INDEX SongsBySongName ON Songs(SongName)
在以下查询中使用该索引:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
以下为查询结果:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
以下为执行计划:
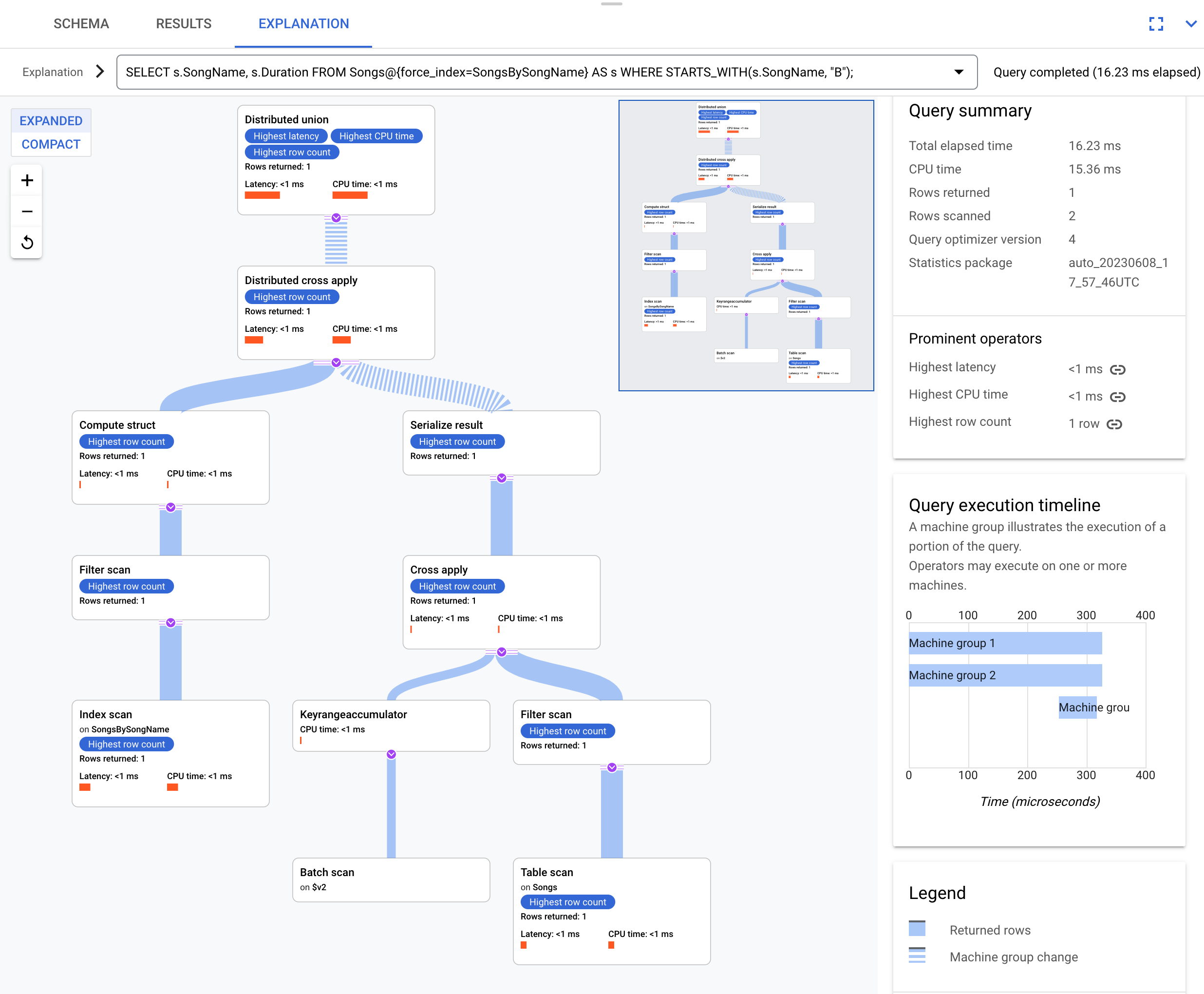
生成的执行计划很复杂,因为索引 SongsBySongName 不包含 Duration 列。如需获取 Duration 的值,Spanner 需要将索引结果后向联接到表 Songs。这是一种非同位联接,因为 Songs 表和全局索引 SongsBySongName 不交织。其生成的执行计划比同位联接的示例更复杂,原因是:如果数据不在同一位置,Spanner 将执行优化以加快执行速度。
顶层运算符为分布式交叉应用运算符。此运算符的输入端是索引 SongsBySongName 中满足谓词 STARTS_WITH(s.SongName, "B") 的批量行。然后,分布式交叉应用将这些批量行映射到其分块包含 Duration 数据的远程服务器。远程服务器使用表扫描来检索 Duration 列。表扫描使用过滤条件 Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId),将 Songs 表中的 TrackId 与来自索引 SongsBySongName 的批量行的 TrackId 进行联接。
结果会聚合为最终的查询结果。接下来,输入端包含分布式联合/局部分布式联合对的分布式交叉应用会评估索引中满足 STARTS_WITH 谓词的行。
以下是一个与上述查询略有不同(即不选择 s.Duration 列)的查询:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
此查询能够充分利用以下执行计划中所示的索引:
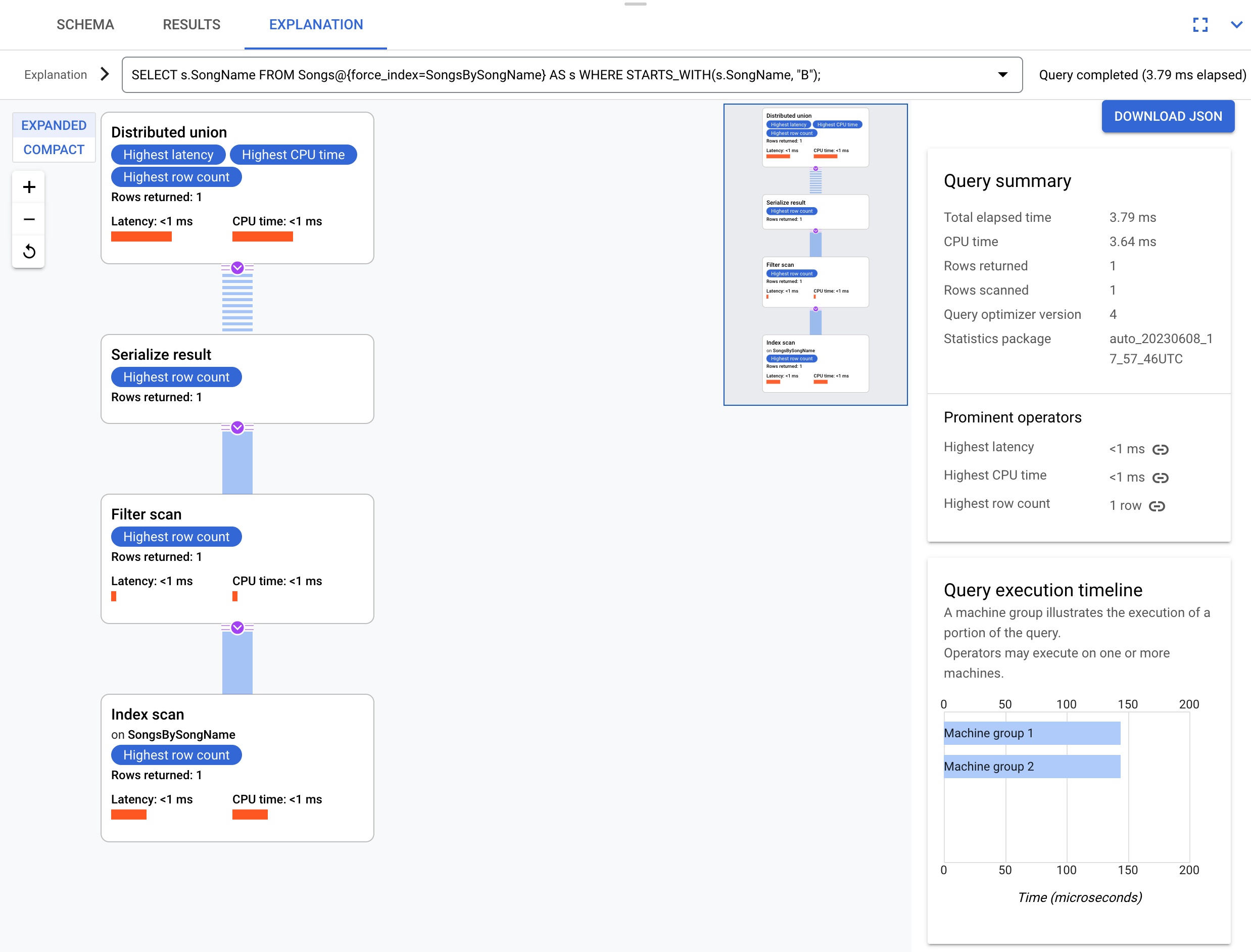
该执行计划不需要后向联接,因为查询所需的所有列都存在于索引中。