Cette page explique comment migrer votre base de données NoSQL de Cassandra vers Spanner.
Cassandra et Spanner sont toutes deux des bases de données distribuées à grande échelle conçues pour les applications qui nécessitent une évolutivité élevée et une faible latence. Bien que les deux bases de données puissent prendre en charge les charges de travail NoSQL exigeantes, Spanner offre des fonctionnalités avancées pour la modélisation, l'interrogation et les opérations transactionnelles sur les données. Spanner est compatible avec le langage de requête Cassandra (CQL).
Pour en savoir plus sur la façon dont Spanner répond aux critères des bases de données NoSQL, consultez Spanner pour les charges de travail non relationnelles.
Contraintes de migration
Pour réussir la migration de Cassandra vers le point de terminaison Cassandra sur Spanner, consultez Spanner pour les utilisateurs Cassandra afin de découvrir les différences entre l'architecture, le modèle de données et les types de données de Spanner et Cassandra. Examinez attentivement les différences fonctionnelles entre Spanner et Cassandra avant de commencer votre migration.
Processus de migration
Le processus de migration se déroule en plusieurs étapes :
- Convertissez votre schéma et votre modèle de données.
- Configurer la double écriture pour les données entrantes
- Exportez vos données historiques de manière groupée de Cassandra vers Spanner.
- Validez les données pour assurer leur intégrité tout au long du processus de migration.
- Faites pointer votre application vers Spanner au lieu de Cassandra.
- Facultatif. Effectuez une réplication inversée de Spanner vers Cassandra.
Convertir votre schéma et votre modèle de données
La première étape de la migration de vos données de Cassandra vers Spanner consiste à adapter le schéma de données Cassandra au schéma Spanner, tout en gérant les différences de types de données et de modélisation.
La syntaxe de déclaration des tables est assez similaire entre Cassandra et Spanner. Vous spécifiez le nom de la table, les noms et types de colonnes, ainsi que la clé primaire qui identifie de manière unique une ligne. La principale différence est que Cassandra est partitionné par hachage et fait la distinction entre les deux parties de la clé primaire : la clé de partition hachée et les colonnes de clustering triées, tandis que Spanner est partitionné par plage. Vous pouvez considérer que la clé primaire de Spanner ne comporte que des colonnes de clustering, avec des partitions automatiquement gérées en arrière-plan. Comme Cassandra, Spanner accepte les clés primaires composites.
Nous vous recommandons de suivre les étapes ci-dessous pour convertir votre schéma de données Cassandra en schéma Spanner :
- Consultez la présentation de Cassandra pour comprendre les similitudes et les différences entre les schémas de données Cassandra et Spanner, et pour apprendre à mapper différents types de données.
- Utilisez l'outil de schéma Cassandra vers Spanner pour extraire et convertir votre schéma de données Cassandra en schéma Spanner.
- Avant de commencer la migration de vos données, assurez-vous que vos tables Spanner ont été créées avec les schémas de données appropriés.
Configurer la migration en direct pour les données entrantes
Pour effectuer une migration sans temps d'arrêt de Cassandra vers Spanner, configurez la migration en direct pour les données entrantes. La migration à chaud vise à minimiser les temps d'arrêt et à assurer la disponibilité continue des applications en utilisant la réplication en temps réel.
Commencez par la migration à chaud avant la migration groupée. Le schéma suivant illustre l'architecture d'une migration en direct.
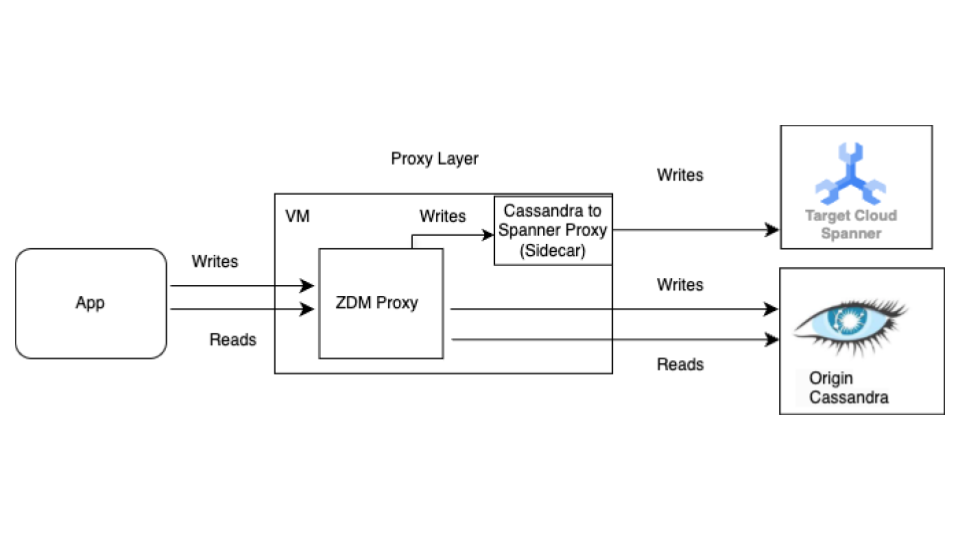
L'architecture de migration à chaud comprend les composants clés suivants :
- Origine : votre base de données Cassandra source.
- Cible : base de données Spanner de destination vers laquelle vous effectuez la migration. Nous partons du principe que vous avez déjà provisionné votre instance Spanner et votre base de données avec un schéma compatible avec votre schéma Cassandra (avec les adaptations nécessaires pour le modèle de données et les fonctionnalités de Spanner).
Proxy ZDM Datastax : le proxy ZDM est un proxy à double écriture conçu par DataStax pour les migrations de Cassandra vers Cassandra. Le proxy imite un cluster Cassandra, ce qui permet à une application d'utiliser le proxy sans modification. C'est à cet outil que votre application s'adresse et qu'elle utilise en interne pour effectuer des écritures doubles dans les bases de données source et cible. Bien qu'il soit généralement utilisé avec les clusters Cassandra comme origine et cible, notre configuration le configure pour qu'il utilise le proxy Cassandra-Spanner (exécuté en tant que side-car) comme cible. Cela garantit que chaque lecture entrante n'est transférée qu'à l'origine et renvoie la réponse d'origine à l'application. De plus, chaque écriture entrante est dirigée à la fois vers l'origine et la cible.
- Si les écritures vers l'origine et la cible réussissent, l'application reçoit un message de réussite.
- Si les écritures vers l'origine échouent et que les écritures vers la cible réussissent, l'application reçoit le message d'échec de l'origine.
- Si les écritures dans la cible échouent et que les écritures dans l'origine réussissent, l'application reçoit le message d'échec de la cible.
- Si les écritures vers l'origine et la cible échouent, l'application reçoit le message d'échec de l'origine.
Proxy Cassandra-Spanner : application side-car qui intercepte le trafic Cassandra Query Language (CQL) destiné à Cassandra et le traduit en appels d'API Spanner. Il permet aux applications et aux outils d'interagir avec Spanner à l'aide du client Cassandra.
Application cliente : application qui lit et écrit des données dans le cluster Cassandra source.
Configuration du proxy
La première étape pour effectuer une migration à chaud consiste à déployer et à configurer les proxys. Le proxy Cassandra-Spanner s'exécute en tant que side-car du proxy ZDM. Le proxy side-car sert de cible pour les opérations d'écriture du proxy ZDM dans Spanner.
Test d'une seule instance à l'aide de Docker
Vous pouvez exécuter une seule instance du proxy localement ou sur une VM pour les tests initiaux à l'aide de Docker.
Prérequis
- Vérifiez que la VM sur laquelle le proxy s'exécute dispose d'une connectivité réseau à l'application, à la base de données Cassandra d'origine et à la base de données Spanner.
- Installez Docker.
- Vérifiez qu'il existe un fichier de clé de compte de service disposant des autorisations nécessaires pour écrire dans votre instance et votre base de données Spanner.
- Configurez votre instance, votre base de données et votre schéma Spanner.
- Assurez-vous que le nom de la base de données Spanner est identique à celui de l'espace de clés Cassandra d'origine.
- Clonez le dépôt spanner-migration-tool.
Télécharger et configurer le proxy ZDM
- Accédez au répertoire
sources/cassandra. - Assurez-vous que les fichiers
entrypoint.shetDockerfilese trouvent dans le même répertoire que le fichier Dockerfile. Exécutez la commande suivante pour créer une image locale :
docker build -t zdm-proxy:latest .
Exécuter le proxy ZDM
- Assurez-vous que
zdm-config.yamletkeyfilessont présents localement à l'emplacement où la commande suivante est exécutée. - Ouvrez l'exemple de fichier zdm-config yaml.
- Consultez la liste détaillée des indicateurs acceptés par ZDM.
Exécutez le conteneur à l'aide de la commande suivante :
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
Vérifier la configuration du proxy
Utilisez la commande
docker logspour vérifier si des erreurs se sont produites dans les journaux du proxy au démarrage :docker logs container-idExécutez la commande
cqlshpour vérifier que le proxy est correctement configuré :cqlsh VM-IP 14002Remplacez VM-IP par l'adresse IP de votre VM.
Configuration de production à l'aide de Terraform :
Pour un environnement de production, nous vous recommandons d'utiliser les modèles Terraform fournis pour orchestrer le déploiement du proxy Cassandra-Spanner.
Prérequis
- Installez Terraform.
- Vérifiez que l'application dispose d'identifiants par défaut avec les autorisations appropriées pour créer des ressources.
- Vérifiez que le fichier de clé de service dispose des autorisations nécessaires pour écrire dans Spanner. Ce fichier est utilisé par le proxy.
- Configurez votre instance, votre base de données et votre schéma Spanner.
- Vérifiez que le fichier Dockerfile,
entrypoint.sh, et le fichier de clé de service se trouvent dans le même répertoire que le fichiermain.tf.
Configurer les variables Terraform
- Assurez-vous de disposer du modèle Terraform pour le déploiement du proxy.
- Mettez à jour le fichier
terraform.tfvarsavec les variables de votre configuration.
Déploiement de modèles à l'aide de Terraform
Le script Terraform effectue les opérations suivantes :
- Crée des VM optimisées pour les conteneurs en fonction d'un nombre spécifié.
- Crée des fichiers
zdm-config.yamlpour chaque VM et lui attribue un index de topologie. Le proxy ZDM nécessite des configurations multi-VM pour configurer la topologie à l'aide des champsPROXY_TOPOLOGY_ADDRESSESetPROXY_TOPOLOGY_INDEXdans le fichier de configurationyaml. - Transfère les fichiers concernés vers chaque VM, exécute Docker Build à distance et lance les conteneurs.
Pour déployer le modèle, procédez comme suit :
Utilisez la commande
terraform initpour initialiser Terraform :terraform initExécutez la commande
terraform planpour voir les modifications que Terraform prévoit d'apporter à votre infrastructure :terraform plan -var-file="terraform.tfvars"Lorsque les ressources vous conviennent, exécutez la commande
terraform apply:terraform apply -var-file="terraform.tfvars"Une fois le script Terraform arrêté, exécutez la commande
cqlshpour vous assurer que les VM sont accessibles.cqlsh VM-IP 14002Remplacez VM-IP par l'adresse IP de votre VM.
Faites pointer vos applications clientes vers le proxy ZDM
Modifiez la configuration de votre application cliente en définissant les points de contact comme étant les VM exécutant les proxys au lieu de votre cluster Cassandra d'origine.
Testez votre application de façon exhaustive. Vérifiez que les opérations d'écriture sont appliquées à la fois au cluster Cassandra d'origine et, en vérifiant votre base de données Spanner, qu'elles atteignent également Spanner à l'aide du proxy Cassandra-Spanner. Les lectures sont effectuées à partir de l'instance Cassandra d'origine.
Exporter vos données de manière groupée vers Spanner
La migration groupée de données consiste à transférer de grands volumes de données entre des bases de données. Elle nécessite souvent une planification et une exécution minutieuses pour minimiser les temps d'arrêt et garantir l'intégrité des données. Ces techniques incluent les processus ETL (Extract, Transform, Load), la réplication directe de bases de données et les outils de migration spécialisés. Elles visent toutes à transférer efficacement les données tout en préservant leur structure et leur précision.
Nous vous recommandons d'utiliser le modèle Dataflow SourceDB vers Spanner de Spanner pour migrer vos données de Cassandra vers Spanner de manière groupée. Dataflow est le service ETL (Extract, Transform, Load) distribué Google Cloud qui fournit une plate-forme pour exécuter des pipelines de données afin de lire et de traiter de grandes quantités de données en parallèle sur plusieurs machines. Le modèle Dataflow SourceDB vers Spanner est conçu pour effectuer des lectures hautement parallélisées à partir de Cassandra, transformer les données sources selon les besoins et écrire dans Spanner en tant que base de données cible.
Suivez les instructions de la section Migration groupée de Cassandra vers Spanner à l'aide du fichier de configuration Cassandra.
Valider les données pour garantir leur intégrité
La validation des données lors de la migration d'une base de données est essentielle pour garantir l'exactitude et l'intégrité des données. Il s'agit de comparer les données entre vos bases de données Cassandra source et Spanner cible pour identifier les écarts, tels que les données manquantes, corrompues ou non concordantes. Les techniques générales de validation des données incluent les sommes de contrôle, les nombres de lignes et les comparaisons détaillées des données. Elles visent toutes à garantir que les données migrées représentent fidèlement les données d'origine.
Une fois la migration groupée des données terminée et tant que les doubles écritures sont encore actives, vous devez valider la cohérence des données et corriger les écarts. Des différences entre Cassandra et Spanner peuvent se produire pendant la phase de double écriture pour diverses raisons, y compris les suivantes :
- Échec des doubles écritures. Une opération d'écriture peut réussir dans une base de données, mais échouer dans l'autre en raison de problèmes réseau temporaires ou d'autres erreurs.
- Transactions légères (LWT). Si votre application utilise des opérations LWT (comparer et définir), elles peuvent réussir sur une base de données, mais échouer sur l'autre en raison de différences dans les ensembles de données.
- Requêtes par seconde (RPS) élevées sur une seule clé primaire. En cas de charges d'écriture très élevées sur la même clé de partition, l'ordre des événements peut différer entre l'origine et la cible en raison de différents temps d'aller-retour réseau, ce qui peut entraîner des incohérences.
Exécution parallèle des jobs par lot et des doubles écritures : l'exécution parallèle de la migration par lot et des doubles écritures peut entraîner une divergence en raison de diverses conditions de concurrence, telles que les suivantes :
- Lignes supplémentaires sur Spanner : si la migration groupée s'exécute alors que les écritures doubles sont actives, l'application peut supprimer une ligne qui a déjà été lue par le job de migration groupée et écrite dans la cible.
- Conditions de concurrence entre les écritures groupées et doubles : il peut exister d'autres conditions de concurrence diverses dans lesquelles le job groupé lit une ligne de Cassandra et les données de la ligne deviennent obsolètes lorsque les écritures entrantes mettent à jour la ligne sur Spanner une fois les doubles écritures terminées.
- Mise à jour partielle des colonnes : la mise à jour d'un sous-ensemble de colonnes sur une ligne existante crée une entrée sur Spanner avec les autres colonnes définies sur "null". Étant donné que les mises à jour groupées n'écrasent pas les lignes existantes, cela entraîne une divergence entre les lignes de Cassandra et de Spanner.
Cette étape consiste à valider et à rapprocher les données entre les bases de données d'origine et cible. La validation consiste à comparer l'origine et la cible pour identifier les incohérences, tandis que la réconciliation vise à résoudre ces incohérences pour assurer la cohérence des données.
Comparer les données entre Cassandra et Spanner
Nous vous recommandons de valider à la fois le nombre de lignes et le contenu réel des lignes.
Le choix de la méthode de comparaison des données (correspondance du nombre et des lignes) dépend de la tolérance de votre application aux incohérences de données et de vos exigences en matière de validation exacte.
Il existe deux façons de valider les données :
La validation active est effectuée lorsque les écritures doubles sont actives. Dans ce scénario, les données de vos bases de données sont toujours en cours de mise à jour. Il est possible que le nombre ou le contenu des lignes ne correspondent pas exactement entre Cassandra et Spanner. L'objectif est de s'assurer que les différences ne sont dues qu'à la charge active sur les bases de données et non à d'autres erreurs. Si les écarts se situent dans ces limites, vous pouvez procéder à la transition.
La validation statique nécessite un temps d'arrêt. Si vos exigences nécessitent une validation statique forte avec une garantie de cohérence exacte des données, vous devrez peut-être arrêter temporairement toutes les écritures dans les deux bases de données. Vous pouvez ensuite valider les données et rapprocher les différences dans votre base de données Spanner.
Choisissez le moment de la validation et les outils appropriés en fonction de vos exigences spécifiques en termes de cohérence des données et de temps d'arrêt acceptable.
Comparer le nombre de lignes dans Cassandra et Spanner
Une méthode de validation des données consiste à comparer le nombre de lignes des tables dans les bases de données source et cible. Il existe plusieurs façons de valider les nombres :
Lorsque vous migrez de petits ensembles de données (moins de 10 millions de lignes par table), vous pouvez utiliser ce script de correspondance du nombre de lignes pour compter les lignes dans Cassandra et Spanner. Cette approche renvoie des nombres exacts en peu de temps. Le délai avant expiration par défaut dans Cassandra est de 10 secondes. Envisagez d'augmenter le délai avant expiration de la requête du pilote et le délai avant expiration côté serveur si le script expire avant la fin du décompte.
Lorsque vous migrez de grands ensembles de données (plus de 10 millions de lignes par table), gardez à l'esprit que les requêtes de décompte Spanner sont bien adaptées à l'échelle, mais que les requêtes Cassandra ont tendance à expirer. Dans ce cas, nous vous recommandons d'utiliser l'outil DataStax Bulk Loader pour obtenir le nombre de lignes des tables Cassandra. Pour les décomptes Spanner, l'utilisation de la fonction SQL
count(*)est suffisante pour la plupart des charges à grande échelle. Nous vous recommandons d'exécuter le chargeur groupé pour chaque table Cassandra, de récupérer les nombres de la table Spanner et de les comparer. Vous pouvez le faire manuellement ou à l'aide d'un script.
Valider une incohérence de ligne
Nous vous recommandons de comparer les lignes des bases de données d'origine et cible pour identifier les incohérences. Il existe deux façons de valider les lignes. La méthode à utiliser dépend des exigences de votre application :
- Validez un ensemble aléatoire de lignes.
- Validez l'ensemble de données complet.
Valider un échantillon aléatoire de lignes
Valider un ensemble de données complet est coûteux et prend du temps pour les charges de travail volumineuses. Dans ce cas, vous pouvez utiliser l'échantillonnage pour valider un sous-ensemble aléatoire des données et vérifier les incohérences dans les lignes. Pour ce faire, vous pouvez sélectionner des lignes aléatoires dans Cassandra et récupérer les lignes correspondantes dans Spanner, puis comparer les valeurs (ou le hachage de ligne).
Cette méthode présente l'avantage d'être plus rapide que la vérification d'un ensemble de données complet et d'être simple à exécuter. L'inconvénient est que, comme il s'agit d'un sous-ensemble de données, il peut encore y avoir des différences dans les données présentes pour les cas extrêmes.
Pour échantillonner des lignes aléatoires à partir de Cassandra, vous devez procéder comme suit :
- Générez des nombres aléatoires dans la plage de jetons [
-2^63,2^63 - 1]. - Récupérer les lignes
WHERE token(PARTITION_KEY) > GENERATED_NUMBER
L'exemple de script validation.go récupère des lignes de manière aléatoire et les valide avec les lignes de la base de données Spanner.
Valider l'intégralité de l'ensemble de données
Pour valider un ensemble de données entier, récupérez toutes les lignes de la base de données Cassandra d'origine. Utilisez les clés primaires pour extraire toutes les lignes de base de données Spanner correspondantes. Vous pouvez ensuite comparer les lignes pour identifier les différences. Pour les grands ensembles de données, vous pouvez utiliser un framework basé sur MapReduce, tel qu'Apache Spark ou Apache Beam, pour valider l'ensemble des données de manière fiable et efficace.
L'avantage de cette méthode est que la validation complète offre une plus grande confiance dans la cohérence des données. Les inconvénients sont qu'il ajoute une charge de lecture sur Cassandra et qu'il nécessite un investissement pour créer des outils complexes pour les grands ensembles de données. La validation d'un ensemble de données volumineux peut également prendre beaucoup plus de temps.
Pour ce faire, vous pouvez partitionner les plages de jetons et interroger l'anneau Cassandra en parallèle. Pour chaque ligne Cassandra, la ligne Spanner équivalente est récupérée à l'aide de la clé de partition. Ces deux lignes sont ensuite comparées pour détecter d'éventuels écarts. Pour obtenir des conseils à suivre lors de la création de jobs de validation, consultez Conseils pour valider Cassandra à l'aide de la correspondance des lignes.
Régler les incohérences de données ou de nombre de lignes
En fonction des exigences de cohérence des données, vous pouvez copier des lignes de Cassandra vers Spanner pour corriger les écarts identifiés lors de la phase de validation. Une façon d'effectuer la réconciliation consiste à étendre l'outil utilisé pour la validation complète de l'ensemble de données et à copier la ligne correcte de Cassandra vers la base de données Spanner cible en cas d'incohérence. Pour en savoir plus, consultez Considérations sur l'implémentation.
Faites pointer votre application vers Spanner au lieu de Cassandra
Après avoir validé l'exactitude et l'intégrité de vos données après la migration, choisissez un moment pour migrer votre application afin qu'elle pointe vers Spanner au lieu de Cassandra (ou vers l'adaptateur de proxy utilisé pour la migration des données en direct). C'est ce qu'on appelle la transition.
Pour effectuer le basculement, procédez comme suit :
Créez une modification de configuration pour votre application cliente afin qu'elle puisse se connecter directement à votre instance Spanner à l'aide de l'une des méthodes suivantes :
- Connectez Cassandra à l'adaptateur Cassandra s'exécutant en tant que side-car.
- Remplacez le fichier jar du pilote par le client du point de terminaison.
Appliquez la modification que vous avez préparée à l'étape précédente pour que votre application pointe vers Spanner.
Configurez la surveillance de votre application pour détecter les erreurs ou les problèmes de performances. Surveillez les métriques Spanner à l'aide de Cloud Monitoring. Pour en savoir plus, consultez Surveiller les instances avec Cloud Monitoring.
Une fois le basculement réussi et le fonctionnement stable, mettez hors service les instances de proxy ZDM et de proxy Cassandra-Spanner.
Effectuer une réplication inverse de Spanner vers Cassandra
Vous pouvez effectuer une réplication inversée à l'aide du modèle Dataflow Spanner to
SourceDB.
La réplication inverse est utile lorsque vous rencontrez des problèmes imprévus avec Spanner et que vous devez revenir à la base de données Cassandra d'origine avec un minimum d'interruption du service.
Conseils pour valider Cassandra à l'aide de la correspondance des lignes
Il est lent et inefficace d'effectuer des analyses complètes de tables dans Cassandra (ou toute autre base de données) à l'aide de SELECT *. Pour résoudre ce problème, divisez l'ensemble de données Cassandra en partitions gérables et traitez-les simultanément. Pour ce faire, procédez comme suit :
- Diviser l'ensemble de données en plages de jetons
- Interroger des partitions en parallèle
- Lire les données de chaque partition
- Récupérer les lignes correspondantes dans Spanner
- Concevoir des outils de validation pour l'extensibilité
- Signaler et consigner les incohérences
Diviser l'ensemble de données en plages de jetons
Cassandra distribue les données sur les nœuds en fonction des jetons de clé de partition.
La plage de jetons d'un cluster Cassandra s'étend de -2^63 à 2^63 -
1. Vous pouvez définir un nombre fixe de plages de jetons de taille égale pour diviser l'ensemble de l'espace de clés en partitions plus petites. Nous vous recommandons de diviser la plage de jetons avec un paramètre partition_size configurable que vous pouvez ajuster pour traiter rapidement l'ensemble de la plage.
Interroger des partitions en parallèle
Une fois les plages de jetons définies, vous pouvez lancer plusieurs processus ou threads parallèles, chacun étant responsable de la validation des données dans une plage spécifique. Pour chaque plage, vous pouvez créer des requêtes CQL à l'aide de la fonction token() sur votre clé de partition (pk).
Voici un exemple de requête pour une plage de jetons donnée :
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
En parcourant vos plages de jetons définies et en exécutant ces requêtes en parallèle sur votre cluster Cassandra d'origine (ou via le proxy ZDM configuré pour lire à partir de Cassandra), vous lisez efficacement les données de manière distribuée.
Lire les données de chaque partition
Chaque processus parallèle exécute la requête basée sur la plage et récupère un sous-ensemble des données de Cassandra. Vérifiez la quantité de données récupérées par partition pour assurer un équilibre entre le parallélisme et l'utilisation de la mémoire.
Récupérer les lignes correspondantes depuis Spanner
Pour chaque ligne extraite de Cassandra, récupérez la ligne correspondante de votre base de données Spanner cible à l'aide de la clé de ligne source.
Comparer les lignes pour identifier les incohérences
Une fois que vous avez la ligne Cassandra et la ligne Spanner correspondante (si elle existe), vous devez comparer leurs champs pour identifier les éventuelles incohérences. Cette comparaison doit tenir compte des éventuelles différences de types de données et des transformations appliquées lors de la migration. Nous vous recommandons de définir des critères clairs pour déterminer ce qui constitue une incohérence en fonction des exigences de votre application.
Outils de validation de la conception pour l'extensibilité
Concevez votre outil de validation de manière à pouvoir l'étendre à la réconciliation. Par exemple, vous pouvez ajouter des fonctionnalités pour écrire les données correctes de Cassandra à Spanner pour les incohérences identifiées.
Signaler et enregistrer les incohérences
Nous vous recommandons de consigner toute incohérence identifiée avec suffisamment de contexte pour permettre une investigation et une réconciliation. Cela peut inclure les clés primaires, les champs spécifiques qui diffèrent et les valeurs de Cassandra et de Spanner. Vous pouvez également agréger les statistiques sur le nombre et les types d'incohérences détectées.
Activer et désactiver le TTL sur les données Cassandra
Cette section explique comment activer et désactiver la valeur TTL (Time To Live) sur les données Cassandra dans les tables Spanner. Pour en savoir plus, consultez Valeur TTL (Time to Live).
Activer le TTL sur les données Cassandra
Pour les exemples de cette section, supposons que vous disposez d'une table avec le schéma suivant :
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
Pour activer la valeur TTL au niveau de la ligne sur une table existante, procédez comme suit :
Ajoutez la colonne d'horodatage pour stocker l'horodatage d'expiration de chaque ligne. Dans cet exemple, la colonne est nommée
ExpiredAt, mais vous pouvez utiliser le nom de votre choix.ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;Ajoutez la règle de suppression de lignes pour supprimer automatiquement les lignes antérieures à la date d'expiration.
INTERVAL 0 DAYsignifie que les lignes sont supprimées immédiatement à l'expiration du délai.ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));Définissez
cassandra_ttl_modesurrowpour activer le TTL au niveau des lignes.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');Vous pouvez également définir
cassandra_default_ttlpour configurer la valeur TTL par défaut. La valeur est exprimée en secondes.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
Désactiver le TTL sur les données Cassandra
Pour les exemples de cette section, supposons que vous disposez d'une table avec le schéma suivant :
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
Pour désactiver la valeur TTL au niveau des lignes sur une table existante, procédez comme suit :
Vous pouvez également définir
cassandra_default_ttlsur zéro pour supprimer la valeur TTL par défaut.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);Définissez
cassandra_ttl_modesurnonepour désactiver la valeur TTL au niveau des lignes.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');Supprimez la règle de suppression de lignes.
ALTER TABLE Singers DROP ROW DELETION POLICY;Supprimez la colonne d'horodatage d'expiration.
ALTER TABLE Singers DROP COLUMN ExpiredAt;
Observations relatives à la mise en œuvre
- Frameworks et bibliothèques : pour une validation personnalisée évolutive, utilisez des frameworks basés sur MapReduce comme Apache Spark ou Dataflow (Beam). Choisissez un langage compatible (Python, Scala, Java) et utilisez des connecteurs pour Cassandra et Spanner, par exemple à l'aide d'un proxy. Ces frameworks permettent un traitement parallèle efficace des grands ensembles de données pour une validation complète.
- Gestion des erreurs et nouvelles tentatives : implémentez gestion des exceptions robuste pour gérer les problèmes potentiels tels que les problèmes de connectivité réseau ou l'indisponibilité temporaire de l'une ou l'autre base de données. Envisagez d'implémenter des mécanismes de réessai pour les échecs temporaires.
- Configuration : configurez les plages de jetons, les informations de connexion pour les deux bases de données et la logique de comparaison.
- Optimisation des performances : testez le nombre de processus parallèles et la taille des plages de jetons pour optimiser le processus de validation en fonction de votre environnement et du volume de données spécifiques. Surveillez la charge sur vos clusters Cassandra et Spanner pendant la validation.
Étape suivante
- Pour comparer Spanner et Cassandra, consultez la présentation de Cassandra.
- Découvrez comment vous connecter à Spanner à l'aide de l'adaptateur Cassandra.