En este documento se describe cómo usar el panel de control Estadísticas del sistema para monitorizar instancias y bases de datos de Spanner.
Acerca de las estadísticas del sistema
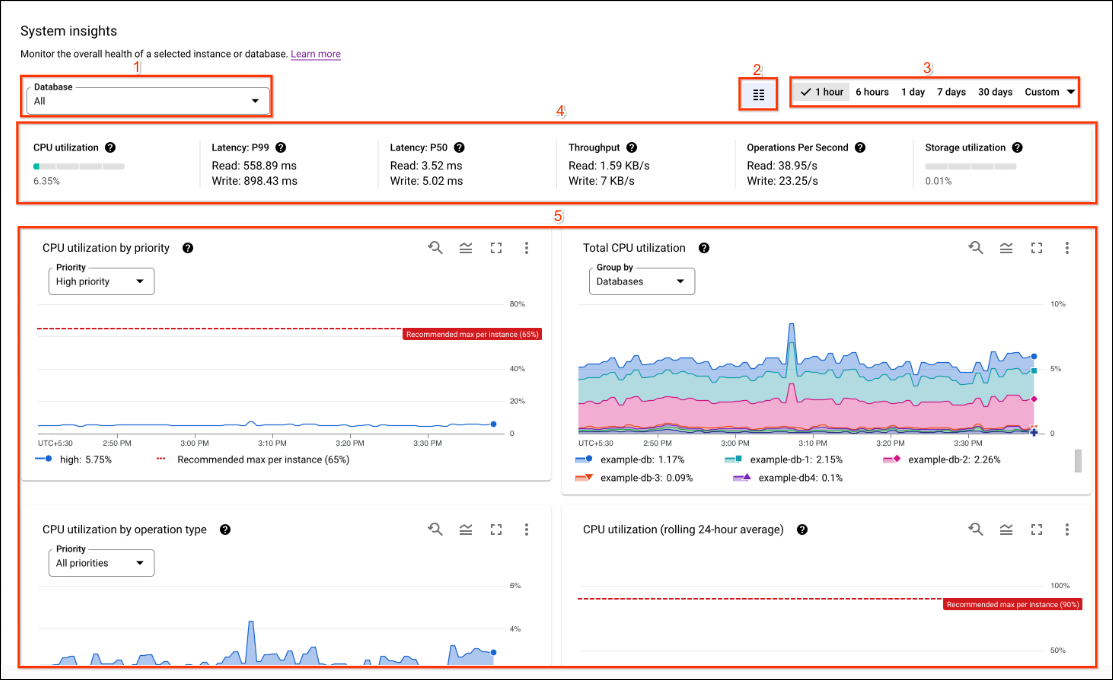
El panel de control Estadísticas del sistema muestra tarjetas de resultados y gráficos sobre una instancia o una base de datos seleccionadas, y proporciona medidas de latencias, uso de CPU, almacenamiento, rendimiento y otras estadísticas de rendimiento. Puedes ver gráficos de los periodos que selecciones, que van desde la última hora hasta los últimos 30 días.
El panel de control Estadísticas del sistema incluye las siguientes secciones, con números que corresponden a la siguiente captura de pantalla de la interfaz de usuario:
- Selectores de estadísticas: selecciona las bases de datos, las particiones de instancias y las regiones que rellenan el panel de control. Estadísticas del sistema muestra las particiones de instancias y las selecciones de regiones cuando hay varias particiones de instancias o regiones disponibles en la instancia.
- Filtro de periodo: filtra las estadísticas por un periodo, como horas, días o un periodo personalizado.
- Selector de panel de control: selecciona vistas personalizadas por el usuario o restablece las estadísticas del sistema a la vista predefinida predeterminada.
- Anotaciones: selecciona los tipos de eventos de alerta de estadísticas que quieras usar para anotar los gráficos.
- Personalizar paneles de control: personaliza el aspecto, la ubicación y el contenido de los widgets de los paneles de control y del panel de estadísticas del sistema. En este documento se describe la presentación del panel de control predefinido.
- Tarjetas de resultados: muestran estadísticas en un momento concreto del periodo seleccionado.
- Gráficos: muestra gráficos de uso de CPU, rendimiento, latencias, uso de almacenamiento y más. Las alertas de estadísticas definidas por Anotaciones se muestran en los gráficos con iconos de campana.
Roles obligatorios
Para obtener los permisos que necesitas para ver o modificar los paneles de control de estadísticas, incluidos los personalizados, pide a tu administrador que te conceda los siguientes roles de gestión de identidades y accesos en el proyecto:
-
Para crear y editar paneles de control personalizados, sigue estos pasos:
Editor de configuración del panel de control de Monitoring (
roles/monitoring.dashboardEditor) -
Para abrir y ver gráficos del explorador de métricas, sigue estos pasos:
Lector de configuraciones del panel de control de Monitoring (
roles/monitoring.dashboardViewer) -
Para crear y editar alertas del Explorador de métricas, siga estos pasos:
Editor de monitorización (
roles/monitoring.editor)
Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar el acceso a proyectos, carpetas y organizaciones.
Estos roles predefinidos contienen los permisos necesarios para ver o modificar los paneles de control de estadísticas, incluidos los personalizados. Para ver los permisos exactos que se necesitan, despliega la sección Permisos necesarios:
Permisos obligatorios
Para ver o modificar los paneles de estadísticas, incluidos los personalizados, se necesitan los siguientes permisos:
-
Para crear paneles de control personalizados, sigue estos pasos:
monitoring.dashboards.create -
Para editar paneles de control personalizados, siga estos pasos:
monitoring.dashboards.update -
Para ver los paneles de control personalizados, siga estos pasos:
monitoring.dashboards.get, monitoring.dashboards.list
También puedes obtener estos permisos con roles personalizados u otros roles predefinidos.
Personalizar el panel de control Estadísticas del sistema
El panel de control Estadísticas del sistema es un panel predefinido que puedes personalizar para que muestre la información que más te interese. Puede añadir gráficos, cambiar el diseño y filtrar los datos para centrarse en recursos específicos.
Los cambios que se hagan en el panel de estadísticas del sistema no son permanentes y se pueden deshacer si se cambia el selector de panel de control a Predefinido.
Modificar el panel de control
Para modificar el panel de control, haz clic en Personalizar paneles de control. Estas son las opciones disponibles:
- Añadir un widget: en la barra de herramientas del panel de control, haz clic en Añadir widget, selecciona el widget que quieras añadir y, a continuación, configúralo.
- Editar un widget: coloca el cursor sobre un widget para que se muestre su barra de herramientas y, a continuación, haz clic en Editar. Puedes cambiar el tipo de widget y personalizar los datos que muestra.
- Clonar un widget: coloca el cursor sobre un widget para que se muestre su barra de herramientas, haz clic en Más opciones de gráfico y, a continuación, en Clonar widget.
- Eliminar un widget: coloca el cursor sobre un widget para mostrar su barra de herramientas, haz clic en Más opciones de gráfico y, a continuación, en Eliminar widget.
- Cambiar el diseño: puedes arrastrar los widgets para cambiar su posición y arrastrar sus esquinas para cambiar su tamaño.
- Asigna un nombre a la vista personalizada: puedes hacerlo en el cuadro Nombre de la vista personalizada.
- Guardar el panel de control: puedes guardar la vista personalizada haciendo clic en Guardar. También puedes salir sin guardar los cambios haciendo clic en Salir del modo de edición.
Tarjetas de resultados, gráficos y métricas de estadísticas del sistema
El panel de control Estadísticas del sistema proporciona los siguientes gráficos y métricas para mostrar el estado actual e histórico de una instancia. La mayoría de los gráficos y las métricas están disponibles a nivel de instancia. También puedes ver muchos gráficos y métricas de una sola base de datos de una instancia.
Tarjetas de resultados disponibles
| Nombre | Descripción |
|---|---|
| Uso de CPU | Uso total de CPU en una instancia o en una base de datos seleccionada. En una instancia multirregional o de doble región, esta métrica representa la media de la utilización de la CPU en todas las regiones. |
| Latencia (percentil 99) | Latencia del percentil 99 de las operaciones de lectura y escritura de una instancia o una base de datos seleccionada, que representa el tiempo en el que se completa el 99% de estas operaciones. |
| Latencia (p50) | Latencia del percentil 50 de las operaciones de lectura y escritura de una instancia o una base de datos seleccionada, que representa el tiempo en el que se completa el 50% de estas operaciones. |
| Rendimiento | Cantidad de datos sin comprimir que se han leído o escrito en la instancia o la base de datos cada segundo. Este valor se mide en bytes binarios, como KiB, MiB o GiB. |
| Operaciones por segundo | Número de operaciones por segundo (tasa) de lectura y escritura en una instancia o en una base de datos seleccionada. |
| Uso de almacenamiento | A nivel de instancia, es el porcentaje total de uso del almacenamiento de una instancia. A nivel de base de datos, es el espacio de almacenamiento total utilizado por la base de datos seleccionada. |
Gráficos y métricas disponibles
A continuación, se muestra un gráfico de una métrica de ejemplo, la utilización de la CPU por tipo de operación:
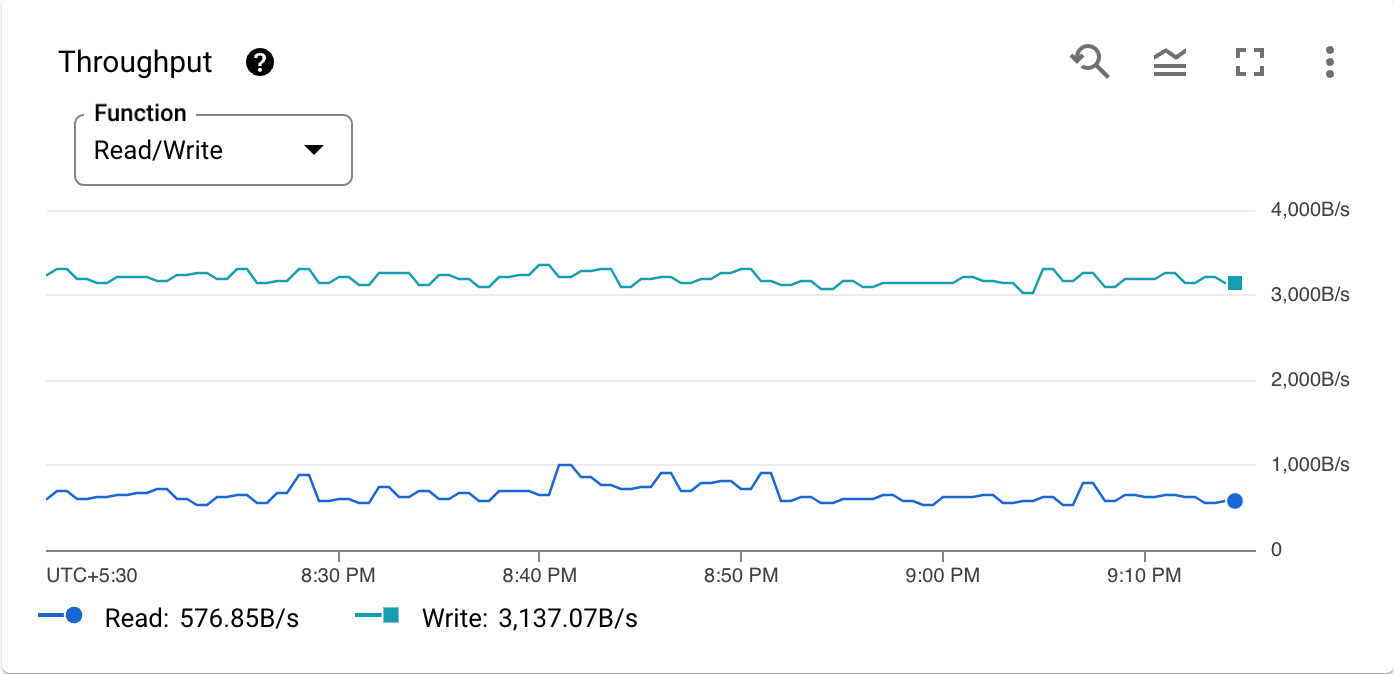
La barra de herramientas de cada gráfico ofrece las siguientes opciones estándar. Algunos elementos están ocultos a menos que mantengas el puntero sobre el gráfico.
Para ampliar una sección concreta de un gráfico, arrastra el puntero por la sección que quieras ver. Esta acción define un intervalo de tiempo personalizado que puedes ajustar o revertir con el filtro de intervalo de tiempo.
Para ver una descripción del gráfico y sus datos, haz clic en help.
Para ver los filtros y los agrupamientos que se han aplicado al gráfico, haz clic en info.
Para crear una alerta basada en los datos del gráfico, haz clic en add_alert.
Para consultar los datos del gráfico, haz clic en query_stats.
Para ver más opciones de gráficos, haz clic en more_vert Más opciones de gráficos.
Para ver un gráfico en modo de pantalla completa, haz clic en Ver en pantalla completa. Para salir de la pantalla completa, haz clic en Cancelar o pulsa Esc.
Para mostrar u ocultar la leyenda del gráfico, haz clic en Mostrar u ocultar leyenda del gráfico.
Para descargar el gráfico, haz clic en Descargar y, a continuación, selecciona un formato de descarga.
Para cambiar el formato visual del gráfico, haga clic en Modo y, a continuación, seleccione un modo de vista.
Para ver la métrica en el explorador de métricas, haz clic en Ver en explorador de métricas. Puede ver otras métricas de Spanner en el explorador de métricas después de seleccionar el tipo de recurso Base de datos de Spanner.
En la siguiente tabla se describen los gráficos que aparecen de forma predeterminada en el panel de control Estadísticas del sistema. Se indica el tipo de métrica de cada gráfico. Las cadenas de tipo de métrica
siguen este prefijo: spanner.googleapis.com/. El tipo de métrica describe las mediciones que se pueden recoger de un recurso monitorizado.
| Nombre del gráfico y tipo de métrica |
Descripción | Disponible para instancias | Disponible para bases de datos |
|---|---|---|---|
|
Cronología del estado del quórum birregional instance/dual_region_quorum_availability |
Este gráfico solo se muestra en las configuraciones de instancias de dos regiones. Muestra el estado de tres quórums: el quórum birregional ( Global) y el quórum de una sola región en cada región (por ejemplo, Sydney y Melbourne).
Muestra una barra naranja en la línea de tiempo cuando hay una interrupción del servicio. Puedes colocar el cursor sobre la barra para ver las horas de inicio y finalización de la interrupción. Usa este gráfico junto con las métricas de latencia y tasas de errores para tomar decisiones sobre la conmutación por error autogestionada en caso de fallos regionales. Para obtener más información, consulta Conmutación por error y recuperación tras un fallo. Para conmutar por error y volver a la configuración original manualmente, consulta el artículo sobre cómo cambiar el quórum de la región dual. |
done |
done |
Uso de CPU por prioridad instance/cpu/utilization_by_priority |
Porcentaje de los recursos de CPU de la instancia para tareas de prioridad alta, media o baja, o para todas las tareas por prioridad. Estas tareas incluyen las solicitudes que inicias y las tareas de mantenimiento que Spanner debe completar rápidamente. En las instancias birregionales o multirregionales, las métricas se agrupan por región y prioridad. Más información sobre las tareas de alta prioridad Consulta más información sobre la utilización de la CPU. |
done |
close |
|
Uso de CPU por región instance/cpu/utilization_by_priority |
Utilización de la CPU en la instancia o la base de datos seleccionadas, agrupada por región. | done |
done |
|
Uso de CPU por base de datos instance/cpu/utilization_by_priority |
Uso de la CPU en la instancia seleccionada, agrupado por base de datos y región. | done |
close |
|
Uso de CPU por usuario o sistema instance/cpu/utilization_by_priority |
Utilización de la CPU en la instancia o base de datos seleccionada, agrupada por tareas de usuario y del sistema, y por prioridad. | done |
done |
Uso de CPU por tipo de operación instance/cpu/utilization_by_operation_type |
Gráfico de áreas apiladas del uso de la CPU como porcentaje de los recursos de CPU de la instancia, agrupados por operaciones iniciadas por el usuario, como lecturas, escrituras y confirmaciones. Usa esta métrica para obtener un desglose detallado del uso de la CPU y solucionar problemas, tal como se explica en el artículo Investigar un uso de CPU elevado. También puedes filtrar por prioridad de las tareas mediante la lista de opciones. En el caso de las instancias birregionales o multirregionales, las métricas del gráfico de líneas muestran el porcentaje medio entre las regiones. |
done |
done |
Uso de CPU (promedio de 24 horas) instance/cpu/smoothed_utilization |
Promedio del uso total de CPU de Spanner, como porcentaje de los recursos de CPU de la instancia, para cada base de datos. Cada punto de datos es una media de las 24 horas anteriores. |
done |
close |
Latencia api/request_latencies |
Tiempo que ha tardado Spanner en gestionar una solicitud de lectura o escritura. Esta medición comienza cuando Spanner recibe una solicitud y termina cuando Spanner empieza a enviar una respuesta. Puedes ver las métricas de latencia de los percentiles 50 y 99 mediante la lista de opciones. |
close |
done |
Latencia por base de datos api/request_latencies |
El tiempo que ha tardado Spanner en gestionar una solicitud de lectura o escritura, agrupado por base de datos. Esta medición empieza cuando Spanner recibe una solicitud y termina cuando Spanner empieza a enviar una respuesta. Para ver las métricas de latencia de los percentiles 50 y 99, usa la lista de vistas de este gráfico. |
done |
close |
Latencia por método de API api/request_latencies |
Tiempo que ha tardado Spanner en gestionar una solicitud, agrupado por métodos de la API de Spanner. Esta medición empieza cuando Spanner recibe una solicitud y termina cuando Spanner empieza a enviar una respuesta. Para ver las métricas de las latencias de los percentiles 50 y 99, usa la lista de vistas de este gráfico. |
close |
done |
Latencia de las transacciones api/request_latencies_by_transaction_type |
Tiempo que ha tardado Spanner en procesar una transacción. Puede seleccionar si quiere ver las métricas de las transacciones de tipo lectura y escritura o de solo lectura. La principal diferencia entre el gráfico Latencia y el gráfico Latencia de las transacciones es que este último te permite ver la participación del líder en el tipo de solo lectura. Las lecturas que impliquen al líder pueden experimentar una latencia mayor. Puedes usar este gráfico para evaluar si debes usar lecturas obsoletas sin comunicarte con el líder, suponiendo que el límite de marca de tiempo sea de al menos 15 segundos. En las transacciones de lectura y escritura, el líder siempre participa en la transacción, por lo que los datos que se muestran en el gráfico siempre incluyen el tiempo que ha tardado la solicitud en llegar al líder y en recibir una respuesta. La ubicación corresponde a la región del frontend de la API Cloud Spanner. Para ver las métricas de las latencias de los percentiles 50 y 99, usa la lista de vistas de este gráfico. |
close |
done |
Latencia de las transacciones por base de datos api/request_latencies_by_transaction_type |
Tiempo que ha tardado Spanner en procesar una transacción. La principal diferencia entre el gráfico Latencia y el gráfico Latencia de las transacciones por base de datos es que este último te permite ver la participación del líder en el tipo de solo lectura. Las lecturas que impliquen al líder pueden experimentar una latencia mayor. Puedes usar este gráfico para evaluar si debes usar lecturas obsoletas sin comunicarte con el líder, siempre que el límite de marca de tiempo sea de al menos 15 segundos. En las transacciones de lectura y escritura, el líder siempre participa en la transacción, por lo que los datos que se muestran en el gráfico siempre incluyen el tiempo que ha tardado la solicitud en llegar al líder y en recibir una respuesta. La ubicación corresponde a la región del frontend de la API Cloud Spanner. Para ver las métricas de las latencias de los percentiles 50 y 99, usa la lista de vistas de este gráfico. |
done |
close |
Latencia de las transacciones por método de la API api/request_latencies_by_transaction_type |
Tiempo que ha tardado Spanner en procesar una transacción. La principal diferencia entre el gráfico Latencia y el gráfico Latencia de las transacciones por método de API es que este último te permite ver la participación del líder en el tipo de solo lectura. Las lecturas que implican al líder pueden experimentar una latencia mayor. Puedes usar este gráfico para evaluar si debes usar lecturas obsoletas sin comunicarte con el líder, suponiendo que el límite de marca de tiempo sea de al menos 15 segundos. En las transacciones de lectura y escritura, el líder siempre participa en la transacción, por lo que los datos que se muestran en el gráfico siempre incluyen el tiempo que ha tardado la solicitud en llegar al líder y recibir una respuesta. La ubicación corresponde a la región del frontend de la API Cloud Spanner. |
close |
done |
Operaciones por segundo api/api_request_count |
El número de operaciones de lectura y escritura que Spanner realiza por segundo o el número de errores del servidor de Spanner por segundo. Puedes elegir qué operaciones quieres ver en este gráfico:
|
close |
done |
Operaciones por segundo por base de datos api/api_request_count |
El número de operaciones de lectura y escritura que Spanner realiza por segundo o el número de errores del servidor de Spanner por segundo. Este gráfico se agrupa por base de datos. Puedes elegir qué operaciones quieres ver en este gráfico:
|
done |
close |
Operaciones por segundo por método de la API api/api_request_count |
Número de operaciones que ha realizado Spanner por segundo, agrupadas por método de la API de Spanner. |
close |
done |
Rendimiento api/sent_bytes_count (lectura) api/received_bytes_count (escritura) |
Cantidad de datos sin comprimir leídos y escritos en la base de datos cada segundo. Este valor se mide en bytes binarios, como KiB, MiB o GiB. El rendimiento de lectura incluye las solicitudes y las respuestas de los métodos de la API de lectura y de las consultas SQL. También incluye solicitudes y respuestas de instrucciones DML. El rendimiento de escritura incluye las solicitudes y las respuestas para confirmar datos a través de la API Mutation. No incluye solicitudes ni respuestas de instrucciones DML. |
close |
done |
Rendimiento por base de datos api/sent_bytes_count (lectura) api/received_bytes_count (escritura) |
Cantidad de datos sin comprimir leídos y escritos en la instancia cada segundo, agrupados por base de datos. Este valor se mide en bytes binarios, como KiB, MiB o GiB. El rendimiento de lectura incluye las solicitudes y las respuestas de los métodos de la API de lectura y de las consultas SQL. También incluye solicitudes y respuestas de instrucciones DML. El rendimiento de escritura incluye las solicitudes y las respuestas para confirmar datos a través de la API Mutation. No incluye solicitudes ni respuestas de instrucciones DML. |
done |
close |
Rendimiento por método de la API api/sent_bytes_count (lectura) api/received_bytes_count (escritura) |
La cantidad de datos sin comprimir que se han leído o escrito en la instancia o la base de datos cada segundo, agrupados por método de API. Este valor se mide en bytes binarios, como KiB, MiB o GiB. El rendimiento de lectura incluye las solicitudes y las respuestas de los métodos de la API de lectura y de las consultas SQL. También incluye solicitudes y respuestas de instrucciones DML. El rendimiento de escritura incluye las solicitudes y las respuestas para confirmar datos a través de la API Mutation. No incluye solicitudes ni respuestas de instrucciones DML. |
close |
done |
Almacenamiento total instance/storage/used_bytes |
La cantidad de datos almacenados en la base de datos. Este valor se mide en bytes binarios, como KiB, MiB o GiB. |
close |
done |
Almacenamiento total de la base de datos por base de datos instance/storage/used_bytes |
La cantidad de datos almacenados en la instancia, agrupados por base de datos. Este valor se mide en bytes binarios, como KiB, MiB o GiB. |
done |
close |
Almacenamiento total de copias de seguridad instance/backup/used_bytes |
Cantidad de datos almacenados en las copias de seguridad asociadas a la base de datos. Este valor se mide en bytes binarios, como KiB, MiB o GiB. |
close |
done |
Tiempo de espera de bloqueo lock_stat/total/lock_wait_time |
El tiempo de espera de bloqueo de una transacción es el tiempo necesario para adquirir un bloqueo en un recurso que tiene otra transacción. El tiempo total de espera de bloqueo de los conflictos de bloqueo se registra en toda la base de datos. |
close |
done |
Tiempo de espera de bloqueo por base de datos lock_stat/total/lock_wait_time |
El tiempo de espera de bloqueo de una transacción es el tiempo necesario para adquirir un bloqueo en un recurso que tiene otra transacción, agrupado por base de datos. El tiempo total de espera de bloqueo de los conflictos de bloqueo se registra durante toda la instancia. |
done |
close |
Espacio de almacenamiento total de copias de seguridad por base de datos instance/backup/used_bytes |
La cantidad de datos almacenados en las copias de seguridad asociadas a la instancia, agrupados por base de datos. Este valor se mide en bytes binarios, como KiB, MiB o GiB. |
done |
close |
Capacidad de computación instance/processing_units instance/nodes |
La capacidad de computación es la cantidad de unidades de procesamiento o nodos disponibles en una instancia. Puede elegir si quiere mostrar la capacidad en unidades de procesamiento o en nodos. |
done |
close |
Distribución de líderes instance/leader_percentage_by_region |
En las instancias birregionales o multirregionales, puedes ver el número de bases de datos con la mayoría de los líderes (≥ 50%) en una región determinada. En el menú de lista Regiones, si seleccionas una región específica, el gráfico muestra el número total de bases de datos de esa instancia que tienen la región seleccionada como región principal. Si selecciona Todas las regiones en el menú de lista Regiones, el gráfico mostrará una línea por cada región. Cada línea muestra el número total de bases de datos de la instancia que tiene esa región como región principal. En las bases de datos de una instancia birregional o multirregional, puede ver el porcentaje de líderes agrupados por región. Por ejemplo, si una base de datos tiene cinco líderes, uno en us-west1 y cuatro en us-east1 en un momento dado, el gráfico "Todas las regiones" muestra dos líneas (una por región). Una línea de us-west1 está al 20 % y la otra línea de us-east1 está al 80%. El gráfico us-west1 muestra una sola línea al 20 % y el gráfico us-east1 muestra una sola línea al 80%.Ten en cuenta que, si se ha creado una base de datos recientemente o se ha modificado una región principal recientemente, es posible que los gráficos no se estabilicen de inmediato. Este gráfico solo está disponible en las instancias de dos regiones y multirregionales. |
done |
done |
Puntuación máxima de uso de CPU dividida instance/peak_split_peak |
El uso máximo de CPU de pico observado en todas las divisiones de una base de datos. Esta métrica muestra el porcentaje de los recursos de la unidad de procesamiento que se están usando en una división. Un porcentaje superior al 50% indica una división activa, lo que significa que la división está usando la mitad de los recursos de la unidad de procesamiento del servidor host. Un porcentaje del 100% indica una división activa, es decir, una división que usa la mayoría de los recursos de la unidad de procesamiento del servidor host. Spanner usa la división basada en carga para resolver los puntos de acceso y equilibrar la carga. Sin embargo, es posible que Spanner no pueda equilibrar la carga, incluso después de varios intentos de división, debido a patrones problemáticos en la aplicación. Por lo tanto, es posible que los puntos de acceso que duren al menos 10 minutos necesiten más pasos para solucionar los problemas y que se requieran cambios en la aplicación. Para obtener más información, consulta Buscar puntos de acceso en divisiones. | done |
done |
|
Llamadas de servicio remotas query_stat/total/remote_service_calls_count |
Número de llamadas a servicios remotos, agrupadas por servicio y códigos de respuesta. Responde con un código de respuesta HTTP, como 200 o 500. |
done |
done |
|
Latencia: llamadas a servicios remotos query_stat/total/remote_service_calls_latencies |
La latencia de las llamadas al servicio remoto, agrupadas por servicio. Puede ver las métricas de latencia de los percentiles 50 y 99 mediante la lista de opciones. |
done |
done |
|
Filas procesadas del servicio remoto query_stat/total/remote_service_processed_rows_count |
Número de filas procesadas por un servicio remoto, agrupadas por el servicio y los códigos de respuesta. Responde con un código de respuesta HTTP, como 200 o 500. |
done |
done |
|
Latencia: filas de servicios remotos query_stat/total/remote_service_processed_rows_latencies |
Número de filas procesadas por un servicio remoto, agrupadas por el servicio y los códigos de respuesta. Puedes ver las métricas de latencia de los percentiles 50 y 99 mediante la lista de opciones. |
done |
done |
|
Bytes de red de servicio remoto query_stat/total/remote_service_network_bytes_sizes |
Bytes de red intercambiados con el servicio remoto, agrupados por servicio y dirección. Este valor se mide en bytes binarios, como KiB, MiB o GiB. Dirección se refiere al tráfico enviado o recibido. Puede ver las métricas de los percentiles 50 y 99 de intercambio de bytes de red mediante la lista de opciones. |
done |
done |
|
Llamadas de microservicios query_stat/total/remote_service_calls_count |
Número de llamadas de microservicios, agrupadas por microservicio y código de respuesta. | done |
done |
|
Latencia: llamadas de microservicios query_stat/total/remote_service_calls_latencies |
Latencias de las llamadas de microservicios, agrupadas por microservicio. | done |
done |
Almacenamiento en bases de datos por tabla (ninguno) |
Cantidad de datos almacenados en la instancia o la base de datos, agrupados por tablas en la base de datos seleccionada. Este valor se mide en bytes binarios, como KiB, MiB o GiB. Este gráfico obtiene sus datos consultando SPANNER_SYS.TABLE_SIZES_STATS_1HOUR. Para obtener más información, consulta
Estadísticas de tamaños de tablas. |
close |
done |
Tablas más usadas por operaciones (ninguna) |
Las 15 tablas e índices más usados de la instancia o la base de datos, determinados por el número de operaciones de lectura, escritura o eliminación. Este gráfico obtiene sus datos consultando las tablas de estadísticas de operaciones de tablas. Para obtener más información, consulta las estadísticas de operaciones de tablas. |
close |
done |
Tablas menos usadas por operaciones (ninguna) |
Las 15 tablas e índices menos usados de la instancia o la base de datos, determinados por el número de operaciones de lectura, escritura o eliminación. Este gráfico obtiene sus datos consultando las tablas de estadísticas de operaciones de tablas. Para obtener más información, consulta las estadísticas de operaciones de tablas. |
close |
done |
Gráficos y métricas de la herramienta de adaptación dinámica gestionada
Además de las opciones que se muestran en la sección anterior, cuando una instancia tiene habilitado el escalador automático gestionado, el gráfico de capacidad de computación tiene el botón Ver registros. Al hacer clic en este botón, se muestran los registros del escalador automático gestionado.
Las siguientes métricas están disponibles para las instancias que tienen habilitado el escalador automático gestionado.
| Nombre y tipo de métrica | Descripción |
|---|---|
| Capacidad de computación | Con los nodos seleccionados. |
|
instance/autoscaling/min_node_count |
Número mínimo de nodos que el escalador automático está configurado para asignar a la instancia. |
|
instance/autoscaling/max_node_count |
Número máximo de nodos que el escalador automático puede asignar a la instancia. |
|
instance/autoscaling/recommended_node_count_for_cpu |
Número de nodos recomendado en función del uso de CPU de la instancia. |
|
instance/autoscaling/recommended_node_count_for_storage |
Número de nodos recomendado en función del uso del almacenamiento de la instancia. |
| Capacidad de computación | Con las unidades de procesamiento seleccionadas. |
|
instance/autoscaling/min_processing_units |
Número mínimo de unidades de procesamiento que se ha configurado para que la herramienta de ajuste automático asigne a la instancia. |
|
instance/autoscaling/max_processing_units |
Número máximo de unidades de procesamiento que el autoescalador puede asignar a la instancia. |
|
instance/autoscaling/recommended_processing_units_for_cpu |
Número recomendado de unidades de procesamiento. Esta recomendación se basa en el uso de CPU anterior de la instancia. |
|
instance/autoscaling/recommended_processing_units_for_storage |
Número recomendado de unidades de procesamiento que se deben usar. Esta recomendación se basa en el uso de almacenamiento anterior de la instancia. |
| Uso de CPU por prioridad | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
Objetivo de uso de CPU de prioridad alta que se usará para el autoescalado. |
| Espacio de almacenamiento total | Con las unidades de procesamiento seleccionadas. |
|
instance/storage/limit_bytes |
Límite de almacenamiento de la instancia en bytes. |
|
instance/autoscaling/storage_utilization_target |
Objetivo de utilización del almacenamiento que se va a usar para el autoescalado. |
Gráficos y métricas de almacenamiento por niveles
Las siguientes métricas están disponibles para las instancias que usan almacenamiento por niveles.
| Nombre y tipo de métrica | Descripción |
|---|---|
| instance/storage/used_bytes | Total de bytes de datos almacenados en almacenamiento SSD y HDD. |
| instance/storage/combined/limit_bytes | Límites de almacenamiento combinados de SSD y HDD. |
| instance/storage/combined/limit_per_processing_unit | Límite de almacenamiento combinado de SSD y HDD para cada unidad de procesamiento. |
| instance/storage/combined/utilization | Espacio de almacenamiento combinado de SSD y HDD utilizado en comparación con el límite de almacenamiento combinado. |
| instance/disk_load | Uso de carga de HDD. |
Conservación de datos
El periodo máximo de conservación de datos de la mayoría de las métricas del panel de control Estadísticas del sistema es de 6 semanas. Sin embargo, en el gráfico Almacenamiento de bases de datos por tabla, los datos se obtienen de la tabla SPANNER_SYS.TABLE_SIZES_STATS_1HOUR (en lugar de Spanner), que tiene un periodo de conservación máximo de 30 días.
Consulta más información sobre la conservación de datos.
Ver el panel de control Estadísticas del sistema
Para ver la página de estadísticas del sistema, necesitas los siguientes permisos de gestión de identidades y accesos (IAM), además de los permisos de Spanner y los permisos de Spanner a nivel de instancia y de base de datos:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Para obtener más información sobre los permisos de gestión de identidades y accesos de Spanner, consulta el artículo sobre el control de acceso con gestión de identidades y accesos.
Si habilitas la herramienta de adaptación dinámica gestionada en tu instancia, también necesitas los permisos logging.logEntries.list, logging.logs.list y logging.logServices.list para ver los registros de la herramienta de adaptación dinámica gestionada.
Para obtener más información sobre este permiso, consulta Roles predefinidos.
Para ver el panel de control Estadísticas del sistema, sigue estos pasos:
En la consola de Google Cloud , abre la lista de instancias de Spanner.
Elige una de estas opciones:
Para ver las métricas de una instancia, haga clic en el nombre de la instancia que le interese y, a continuación, en Estadísticas del sistema en el menú de navegación.
Para ver las métricas de una base de datos, haga clic en el nombre de la instancia, seleccione una base de datos y, a continuación, haga clic en Estadísticas del sistema en el menú de navegación.
Opcional: Para ver el historial de datos de otro periodo, busca los botones situados en la parte superior derecha de la página y haz clic en el periodo que quieras ver.
Opcional: Para controlar qué datos aparecen en el gráfico, haz clic en una de las listas del gráfico. Por ejemplo, si la instancia usa una configuración birregional o multirregional, algunos gráficos ofrecen una lista para ver los datos de una región específica. No todos los gráficos tienen listas de vistas.
Siguientes pasos
- Consulta las métricas de uso de CPU y latencia de Spanner.
- Configura gráficos y alertas personalizados con Monitoring.
- Consulta los detalles sobre los tipos de instancias de Spanner.