Sur cette page, vous trouverez des instructions concernant la migration d'une base de données PostgreSQL Open Source vers Spanner.
La migration implique les tâches suivantes :
- Mapper un schéma PostgreSQL sur un schéma Spanner
- Créer une instance, une base de données et un schéma Spanner
- Retravailler l'application pour qu'elle fonctionne avec votre base de données Spanner
- Effectuer la migration des données
- Vérifier le nouveau système et le passer à l'état de production
Elle fournit également des exemples de schémas utilisant des tables de la base de données PostgreSQL MusicBrainz.
Mapper votre schéma PostgreSQL sur Spanner
La première étape du transfert d'une base de données de PostgreSQL vers Spanner consiste à déterminer les modifications à apporter au schéma. Utilisez pg_dump pour créer des instructions DDL (Data Definition Language) définissant les objets de votre base de données PostgreSQL, puis modifiez-les comme décrit dans les sections suivantes. Une fois les instructions DDL modifiées, utilisez-les pour créer votre base de données dans une instance Spanner.
Types de données
Le tableau suivant décrit les correspondances entre les types de données PostgreSQL et les types de données Spanner. Dans vos instructions DDL, modifiez les données de type PostgreSQL en données de type Spanner.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING, au format CIDR standard. |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64 pour préciser une valeur en millisecondes ou STRING pour utiliser un format d'intervalle défini par l'application. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING, au format d'adresse MAC standard. |
money |
INT64, ou STRING pour les nombres de précision arbitraire. |
numeric [ (p, s) ]
|
Dans PostgreSQL, les types de données NUMERIC et DECIMAL acceptent jusqu'à 217 chiffres dans les paramètres de précision et 214 - 1 chiffres dans les paramètres d'échelle, comme défini dans la déclaration de colonne.Le type de données Spanner NUMERIC accepte jusqu'à 38 chiffres dans les paramètres de précision et 9 chiffres décimaux dans les paramètres d'échelle.Si vous avez besoin d'une plus grande précision, consultez la section Stocker des données numériques de précision arbitraire pour découvrir d'autres mécanismes. |
path |
ARRAY<FLOAT64> |
pg_lsn |
Ce type de données est spécifique à PostgreSQL. Il n'y a donc pas d'équivalent Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, au format HH:MM:SS.sss. |
time [ (p) ] with time zone
|
STRING, au format HH:MM:SS.sss+ZZZZ. Vous pouvez également diviser ces données en deux colonnes, l'une de type TIMESTAMP et l'autre contenant le fuseau horaire. |
timestamp [ (p) ] [ without time zone ] |
Aucun équivalent. Vous pouvez stocker ces données en tant que STRING ou TIMESTAMP, à votre guise. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
Aucun équivalent. Définissez plutôt un mécanisme de stockage dans votre application. |
tsvector |
Aucun équivalent. Définissez plutôt un mécanisme de stockage dans votre application. |
txid_snapshot |
Aucun équivalent. Définissez plutôt un mécanisme de stockage dans votre application. |
uuid |
STRING ou BYTES |
xml |
STRING |
Clés primaires
Pour les tables de votre base de données Spanner que vous ajoutez fréquemment, évitez d'utiliser des clés primaires qui augmentent ou diminuent de façon linéaire. Cette approche crée en effet des hotspots pendant les écritures. Modifiez plutôt les instructions DDL CREATE TABLE afin qu'elles utilisent les stratégies de clé primaire compatibles. Si vous utilisez une fonctionnalité PostgreSQL telle qu'un type ou une fonction de données UUID, des types de données SERIAL, une colonne IDENTITY ou une séquence, vous pouvez utiliser les stratégies de migration de clés générées automatiquement que nous recommandons.
Notez qu'une fois que vous avez désigné votre clé primaire, vous ne pouvez plus ajouter ni supprimer de colonne de clé primaire, ni modifier une valeur de clé primaire ultérieurement sans supprimer et recréer la table. Pour en savoir plus sur la manière de désigner votre clé primaire, consultez la section Schéma et modèle de données – clés primaires.
Pendant la migration, vous devrez peut-être conserver certaines clés entières croissantes monotones. Si vous devez conserver ces types de clés sur une table fréquemment modifiée rassemblant de nombreuses opérations sur ces clés, vous pouvez éviter de créer des hotspots en ajoutant à la clé existante un préfixe pseudo-aléatoire. Cette technique amène Spanner à redistribuer les lignes. Pour en savoir plus sur l'utilisation de cette approche, consultez l'article Ce que les administrateurs de base de données doivent savoir sur Spanner, partie 1: Clés et index.
Clés étrangères et intégrité du référentiel
En savoir plus sur la prise en charge des clés étrangères dans Spanner
Index
Les index B-tree PostgreSQL sont semblables aux index secondaires dans Spanner. Dans une base de données Spanner, vous utilisez des index secondaires pour indexer les colonnes couramment recherchées afin d'obtenir de meilleures performances, et pour remplacer les contraintes UNIQUE spécifiées dans vos tables. Par exemple, imaginons que votre DDL PostgreSQL affiche l'instruction suivante :
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Vous utiliserez alors l'instruction suivante dans le DDL Spanner:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
Vous pouvez trouver les index de toutes vos tables PostgreSQL en exécutant la méta-commande \di dans psql.
Une fois que vous avez déterminé les index dont vous avez besoin, ajoutez des instructions CREATE INDEX pour les créer. Pour ce faire, suivez les instructions de la section Créer des index.
Spanner implémente les index sous forme de tables. Par conséquent, l'indexation de colonnes de façon croissante et linéaire (comme celles contenant des données TIMESTAMP) peut provoquer un hotspot.
Pour en savoir plus sur la façon d'éviter les hotspots, consultez l'article Ce que les administrateurs de base de données doivent savoir sur Spanner, partie 1: Clés et index.
Vérifier les contraintes
En savoir plus sur la compatibilité de la contrainte CHECK dans Spanner
Autres objets de base de données
Vous devez créer la fonctionnalité des objets suivants dans la logique de votre application :
- Vues
- Déclencheurs
- Procédures stockées
- Fonctions définies par l'utilisateur
- Colonnes utilisant des types de données
serialen tant que générateurs de séquence
Pour la migration de cette fonctionnalité dans la logique de l'application, tenez compte des conseils suivants :
- Vous devez réaliser la migration des instructions SQL utilisées depuis le dialecte SQL de PostgreSQL vers celui de GoogleSQL.
- Si vous utilisez des curseurs, vous pouvez retravailler la requête pour utiliser des décalages et des limites.
Créer votre instance Spanner
Une fois vos instructions DDL modifiées pour qu'elles soient conformes aux exigences du schéma Spanner, utilisez-les pour créer une base de données dans Spanner.
Créez une instance Spanner. Suivez les instructions fournies sur la page Instances pour déterminer la configuration régionale appropriée, ainsi que la capacité de calcul nécessaire à l'atteinte de vos objectifs de performances.
Créez la base de données à l'aide de la console Google Cloud ou de l'outil de ligne de commande
gcloud:
Console
- Accéder à la page Instances
- Cliquez sur le nom de l'instance dans laquelle vous souhaitez créer l'exemple de base de données pour ouvrir la page Détails de l'instance.
- Cliquez sur Créer une base de données.
- Saisissez un nom pour la base de données, puis cliquez sur Continuer.
- Dans la section Définir le schéma de votre base de données, cliquez sur le bouton Modifier sous forme de texte.
- Copiez et collez vos instructions DDL dans le champ Instructions DDL.
- Cliquez sur Créer.
gcloud
- Installer gcloud CLI
- Utilisez la commande
gcloud spanner databases createpour créer la base de données :gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME correspond au nom de votre base de données.
- INSTANCE_NAME correspond à l'instance Spanner que vous avez créée.
- DDLn correspond à vos instructions LDD modifiées.
Une fois la base de données créée, suivez les instructions de la page Attribuer des rôles IAM pour créer des comptes d'utilisateurs et accorder des autorisations à l'instance et à la base de données Spanner.
Retravailler les applications et les couches d'accès aux données
En plus du code nécessaire pour remplacer les objets de base de données précédents, vous devez ajouter une logique d'application pour gérer les fonctionnalités suivantes :
- Hachage de clés primaires pour les écritures, pour les tables avec des taux d'écriture élevés en clés séquentielles
- Validation des données pour le moment non couvertes par les contraintes
CHECK. - Vérifications de l'intégrité du référentiel pour le moment non couvertes par les clés étrangères, l'entrelacement de tables ou la logique de l'application, y compris les fonctionnalités gérées par les déclencheurs du schéma PostgreSQL
Nous vous recommandons d'utiliser le processus suivant lors du retravail :
- Trouvez tout le code de votre application qui accède à la base de données, puis retravaillez-le en un seul module ou une seule bibliothèque. De cette façon, vous savez exactement quel code accède à la base de données, et donc exactement quel code doit être modifié.
- Écrivez du code qui effectue des lectures et des écritures sur l'instance Spanner, fournissant une fonctionnalité parallèle au code d'origine qui lit et écrit dans PostgreSQL. Lors des écritures, mettez à jour l'ensemble de la ligne, et non seulement les colonnes qui ont été modifiées, pour vous assurer que les données dans Spanner sont identiques à celles de PostgreSQL.
- Écrivez un code qui remplace la fonctionnalité des objets et fonctions de la base de données non disponibles dans Spanner.
Migrer les données
Une fois votre base de données Spanner créée et le code de votre application retravaillé, vous pouvez migrer vos données vers Spanner.
- Utilisez la commande PostgreSQL
COPYpour transférer les données vers des fichiers .csv. Importez les fichiers .csv dans Cloud Storage.
- Créez un bucket Cloud Storage.
- Dans la console Cloud Storage, cliquez sur le nom du bucket pour ouvrir son navigateur.
- Cliquez sur Importer des fichiers.
- Accédez au répertoire contenant les fichiers .csv et sélectionnez-les.
- Cliquez sur Ouvrir.
Créez une application pour importer des données dans Spanner. Cette application peut utiliser Dataflow ou directement les bibliothèques clientes. Assurez-vous de suivre les instructions des bonnes pratiques de chargement groupé des données pour obtenir des performances optimales.
Tests
Testez toutes les fonctions de l'application sur l'instance Spanner pour vérifier qu'elles fonctionnent comme prévu. Exécutez des charges de travail en production pour vous assurer que les performances répondent bien à vos besoins. Modifiez la capacité de calcul en fonction de vos besoins pour atteindre vos objectifs de performances.
Passer au nouveau système
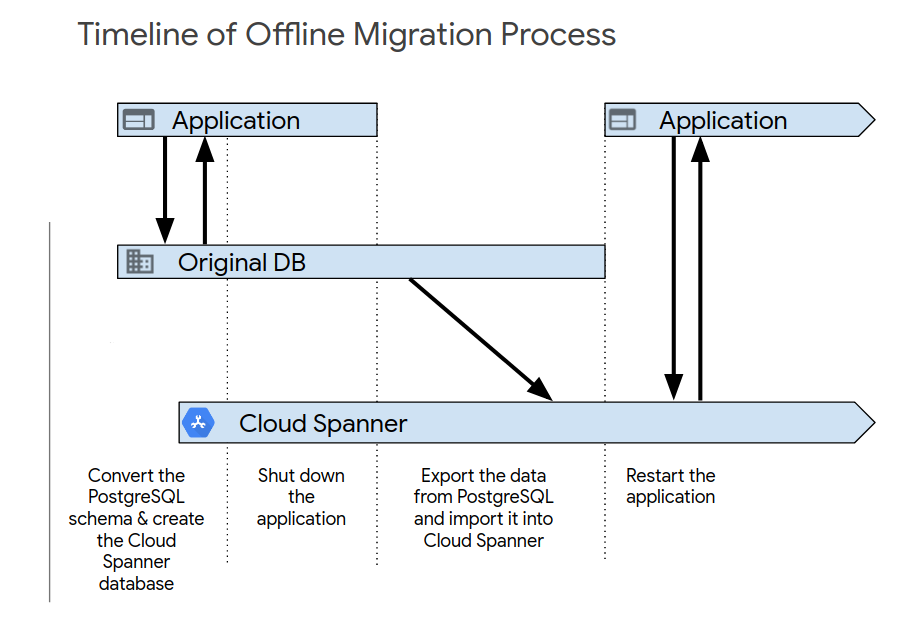
Une fois les tests d'application initiaux terminés, activez le nouveau système en utilisant l'un des processus suivants. La migration hors ligne est le moyen le plus simple d'effectuer la migration. Toutefois, cette approche rend votre application indisponible pendant un certain temps, et vous ne pourrez pas réaliser de rollback si vous détectez des problèmes de données ultérieurement. Pour effectuer une migration hors ligne, procédez comme suit :
- Supprimez toutes les données de la base de données Spanner.
- Fermez l’application qui cible la base de données PostgreSQL.
- Exportez toutes les données de la base de données PostgreSQL, puis importez-les dans la base de données Spanner, comme décrit dans la section Présentation de la migration.
Démarrez l'application qui cible la base de données Spanner.
La migration en direct est une solution possible. Cela implique toutefois d'apporter des modifications importantes à votre application pour qu'elle accepte la migration.
Exemples de migration de schéma
Ces exemples présentent les instructions CREATE TABLE pour plusieurs tables du schéma de la base de données PostgreSQL MusicBrainz.
Chaque exemple inclut à la fois le schéma PostgreSQL et le schéma Spanner.
Table "artist_credit"
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
Table "recording"
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
Table "recording-alias"
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);