이 튜토리얼에서는 Amazon DynamoDB에서 Spanner로 마이그레이션하는 방법을 설명합니다. 이 튜토리얼은 기본적으로 NoSQL 시스템에서 Spanner로 이전하고자 하는 앱 소유자를 위한 것입니다. Spanner는 트랜잭션을 지원하는 확장성이 뛰어난 완전 관계형 내결함성 SQL 데이터베이스 시스템입니다. 유형과 레이아웃 측면에서 Amazon DynamoDB 테이블을 꾸준히 사용하는 경우 Spanner에 간단하게 매핑할 수 있습니다. Amazon DynamoDB 테이블에 임의 데이터 유형과 값이 포함된 경우에는 Datastore 또는 Firestore와 같은 다른 NoSQL 서비스로 이전하는 것이 더 간단할 수도 있습니다.
이 튜토리얼에서는 사용자가 데이터베이스 스키마, 데이터 유형, NoSQL의 기본 정보, 관계형 데이터베이스 시스템에 익숙하다고 가정합니다. 이 튜토리얼은 사전 정의된 작업을 실행하여 이전 작업 예시를 수행합니다. 튜토리얼 진행 후에는 제공된 코드 및 단계를 수정하여 사용자 환경에 맞출 수 있습니다.
다음의 아키텍처 다이어그램은 데이터를 마이그레이션하는 튜토리얼에서 사용된 구성요소를 간략하게 보여줍니다.

목표
- Amazon DynamoDB에서 Spanner로 데이터를 마이그레이션합니다.
- Spanner 데이터베이스 및 마이그레이션 테이블을 만듭니다.
- NoSQL 스키마를 관계형 스키마에 매핑합니다.
- Amazon DynamoDB를 사용하는 샘플 데이터 세트를 만들고 내보냅니다.
- Amazon S3 및 Cloud Storage 간에 데이터를 전송합니다.
- Dataflow를 사용하여 데이터를 Spanner에 로드합니다.
비용
이 튜토리얼에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud구성요소를 사용합니다.
Spanner 비용은 인스턴스의 컴퓨팅 용량과 월별 결제 주기 중에 저장된 데이터 양을 기준으로 청구됩니다. 이 튜토리얼에서는 이러한 리소스의 최소 구성을 사용하며 끝날 때 삭제됩니다. 실제 시나리오의 경우 처리량과 스토리지 요구사항을 추정한 후 Spanner 인스턴스 문서를 사용하여 필요한 컴퓨팅 용량을 결정합니다.
이 튜토리얼에서는 Google Cloud 리소스 외에도 다음 Amazon Web Services(AWS) 리소스를 사용합니다.
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
이러한 서비스는 이전 프로세스를 진행하는 동안에만 필요합니다. 튜토리얼을 마치면 안내에 따라 모든 리소스를 삭제하여 불필요한 비용 청구를 방지하세요. AWS 가격 계산기를 사용하여 비용을 추산하세요.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- 기본 Compute Engine 영역을 설정합니다. 예를 들면
us-central1-b입니다. gcloud config set compute/zone us-central1-b - 샘플 코드가 포함된 GitHub 저장소를 클론합니다. git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- 복제된 디렉터리로 이동합니다. cd dynamodb-spanner-migration
- Python 가상 환경을 만듭니다. pip3 install virtualenv virtualenv env
- 가상 환경을 활성화합니다. source env/bin/activate
- 필수 Python 모듈을 설치합니다. pip3 install -r requirements.txt
- AWS 콘솔에서 IAM 섹션으로 이동하여 Roles(역할)를 클릭한 다음 Create role(역할 만들기)을 선택합니다.
- 신뢰할 수 있는 항목 유형에서 AWS 서비스가 선택되어 있는지 확인합니다.
- 사용 사례에서 Lambda를 선택한 후 다음을 클릭합니다.
- 권한 정책 필터 상자에
AWSLambdaDynamoDBExecutionRole을 입력하고Return을 눌러 검색합니다. - AWSLambdaDynamoDBExecutionRole 체크박스를 선택한 후 다음을 클릭합니다.
- Role name(역할 이름) 상자에
dynamodb-spanner-lambda-role을 입력한 다음 Create role(역할 만들기)을 클릭합니다. - AWS 콘솔의 IAM 섹션에 있는 상태에서 사용자를 클릭한 후 사용자 추가를 선택합니다.
- 사용자 이름 상자에
dynamodb-spanner-migration을 입력합니다. 액세스 유형에서 액세스 키 - 프로그래매틱 방식으로 액세스 왼쪽에 있는 체크박스를 선택합니다.
다음: 권한을 클릭합니다.
기존 정책 직접 연결을 클릭하고 검색 상자를 사용하여 필터링한 후 다음 세 가지 정책 옆에 있는 체크박스를 선택합니다.
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
다음: 태그 및 다음: 검토를 클릭한 후 사용자 만들기를 클릭합니다.
표시를 클릭하여 사용자 인증 정보를 봅니다. 새로 생성된 사용자의 액세스 키 ID 및 비밀 액세스 키가 표시됩니다. 다음 섹션에서 사용자 인증 정보가 필요하기 때문에 이 창을 열어놓습니다. 이러한 사용자 인증 정보를 안전하게 보관하세요. 사용자 인증 정보가 있으면 계정을 변경하고 사용 환경에 영향을 미칠 수 있습니다. 이 튜토리얼이 끝나면 IAM 사용자를 삭제할 수 있습니다.
Cloud Shell에서 AWS 명령줄 인터페이스(CLI)를 구성합니다.
aws configure
다음과 같은 출력이 표시됩니다.
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- 만든 AWS IAM 계정의
ACCESS KEY ID및SECRET ACCESS KEY를 입력합니다. - 기본 리전 이름 필드에
us-west-2를 입력합니다. 다른 필드는 기본값으로 둡니다.
- 만든 AWS IAM 계정의
AWS IAM 콘솔 창을 닫습니다.
Cloud Shell에서 샘플 테이블 속성을 사용하는 Amazon DynamoDB 테이블을 만듭니다.
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75테이블 상태가
ACTIVE인지 확인합니다.aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'샘플 데이터로 테이블을 채웁니다.
python3 make-fake-data.py --table Migration --items 25000
기본 Compute Engine 영역을 설정한 리전과 동일한 리전에서 Spanner 인스턴스를 만듭니다. 예를 들면
us-central1입니다.gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Spanner 인스턴스에서 데이터베이스를 샘플 테이블과 함께 만듭니다.
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"Cloud Shell에서 소스 테이블의 Amazon DynamoDB 스트림을 사용 설정합니다.
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES변경사항을 수신하도록 Pub/Sub 주제를 설정합니다.
gcloud pubsub topics create spanner-migration
다음과 같은 출력이 표시됩니다.
Created topic [projects/your-project/topics/spanner-migration].
IAM 서비스 계정을 만들어 테이블 업데이트를 Pub/Sub 주제로 푸시합니다.
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"다음과 같은 출력이 표시됩니다.
Created service account [spanner-migration].
서비스 계정이 Pub/Sub에 게시할 수 있는 권한을 갖도록 IAM 정책 binding을 만듭니다.
GOOGLE_CLOUD_PROJECT를 Google Cloud 프로젝트 이름으로 바꿉니다.gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com다음과 같은 출력이 표시됩니다.
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
서비스 계정의 사용자 인증 정보를 만듭니다.
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com다음과 같은 출력이 표시됩니다.
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
AWS Lambda 함수를 준비하고 패키징하여 Amazon DynamoDB 테이블 변경사항을 Pub/Sub 주제로 푸시합니다.
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
앞서 만든 Lambda 실행 역할의 Amazon 리소스 이름(ARN)을 캡처하기 위한 변수를 만듭니다.
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)pubsub-lambda.zip패키지를 사용하여 AWS Lambda 함수를 만듭니다.aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"다음과 같은 출력이 표시됩니다.
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }테이블의 Amazon DynamoDB 스트림 ARN을 캡처할 변수를 만듭니다.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Lambda 함수를 Amazon DynamoDB 테이블에 연결합니다.
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZON테스트 중 응답성을 최적화하려면 항목을 생성, 업데이트 또는 삭제할 때마다 함수를 트리거하는 이전 명령어 끝에
--batch-size 1을 추가합니다.다음과 비슷한 출력이 표시됩니다.
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...Cloud Shell에서 여러 후속 섹션에 사용할 버킷 이름의 변수를 만듭니다.
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportDynamoDB를 내보낼 Amazon S3 버킷을 만듭니다.
aws s3 mb s3://${BUCKET}AWS 관리 콘솔에서 DynamoDB로 이동하여 테이블을 클릭합니다.
Migration테이블을 클릭합니다.내보내기 및 스트림 탭에서 S3로 내보내기를 클릭합니다.
메시지가 표시되면
point-in-time-recovery(PITR)를 사용 설정합니다.S3 찾아보기를 클릭하여 이전에 만든 S3 버킷을 선택합니다.
내보내기를 클릭합니다.
새로고침 아이콘을 클릭하여 내보내기 작업 상태를 업데이트합니다. 작업에서 내보내기를 완료하는 데 몇 분 정도 걸립니다.
프로세스가 완료되면 출력 버킷을 살펴봅니다.
aws s3 ls --recursive s3://${BUCKET}이 단계를 완료하는 데 약 5분이 걸릴 수 있습니다. 완료되면 다음과 같은 출력이 표시됩니다.
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
Cloud Shell에서 Cloud Storage 버킷을 만들어 Amazon S3에서 내보낸 파일을 받습니다.
gcloud storage buckets create gs://${BUCKET}파일을 Amazon S3에서 Cloud Storage로 동기화합니다. 대부분의 복사 작업에서는
rsync명령어가 효과적입니다. 내보내기 파일의 용량이 큰 경우(수 GB 이상) Cloud Storage Transfer Service를 사용하여 백그라운드에서 전송을 관리합니다.gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objects내보낸 파일의 데이터를 Spanner 테이블에 쓰려면 Dataflow 작업을 샘플 Apache Beam 코드와 함께 실행합니다.
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"가져오기 작업의 진행률을 보려면 Google Cloud 콘솔에서 Dataflow로 이동합니다.
작업을 실행하는 동안 실행 그래프를 살펴보고 로그를 검토할 수 있습니다. 상태가 실행 중으로 표시되는 작업을 클릭합니다.
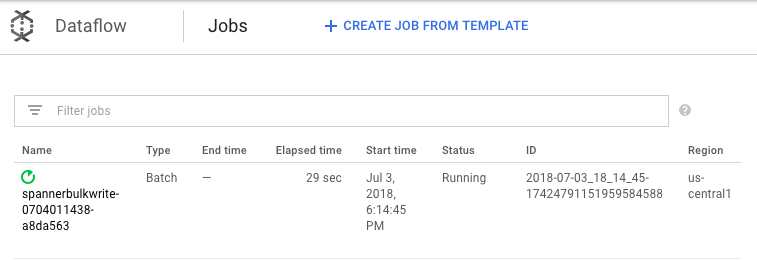
각 단계를 클릭하여 얼마나 많은 요소가 처리되었는지 확인합니다. 가져오기가 완료되면 모든 단계가 성공이라고 표시됩니다. Amazon DynamoDB 테이블에서 만든 것과 동일한 수의 요소가 각 단계에서 처리된 것으로 표시됩니다.
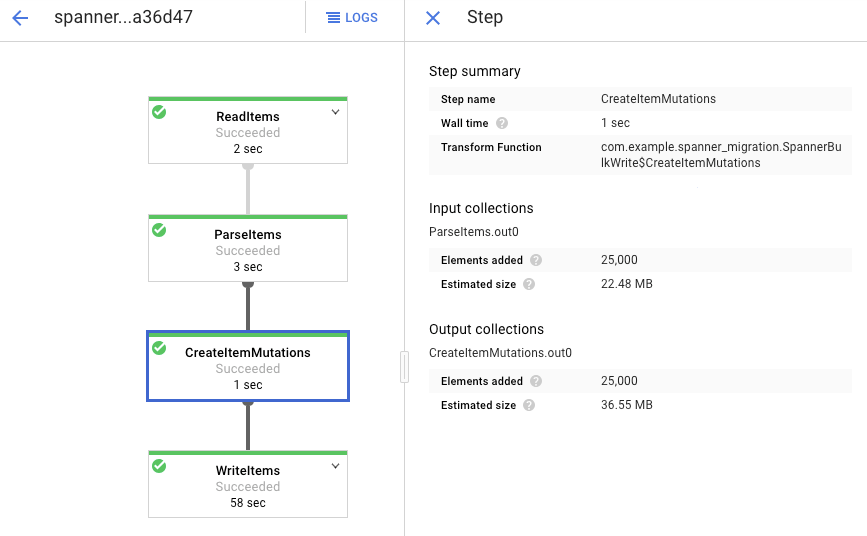
대상 Spanner 테이블의 레코드 수가 Amazon DynamoDB 테이블의 항목 수와 일치하는지 확인합니다.
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
다음과 같은 출력이 표시됩니다.
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
각 테이블에서 임의 항목을 샘플링하여 데이터가 일관적인지 확인합니다.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"다음과 같은 출력이 표시됩니다.
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
이전 단계에서 Spanner 쿼리에서 반환된 것과 동일한
Username로 Amazon DynamoDB 테이블을 쿼리합니다. 예를 들면aallen2538입니다. 이 값은 데이터베이스의 샘플 데이터에만 관련됩니다.aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'다른 필드의 값이 Spanner 출력의 값과 일치해야 합니다. 다음과 같은 출력이 표시됩니다.
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }AWS Lambda가 이벤트를 전송하는 Pub/Sub 주제에 대한 구독을 만듭니다.
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migration다음과 같은 출력이 표시됩니다.
Created subscription [projects/your-project/subscriptions/spanner-migration].
Pub/Sub로 들어오는 변경사항을 스트리밍하여 Spanner 테이블에 변경사항을 쓰려면 Cloud Shell에서 Dataflow 작업을 실행합니다.
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"일괄 로드 단계와 마찬가지로 작업 진행률을 보려면 Google Cloud 콘솔에서 Dataflow로 이동합니다.
상태가 실행 중인 작업을 클릭합니다.
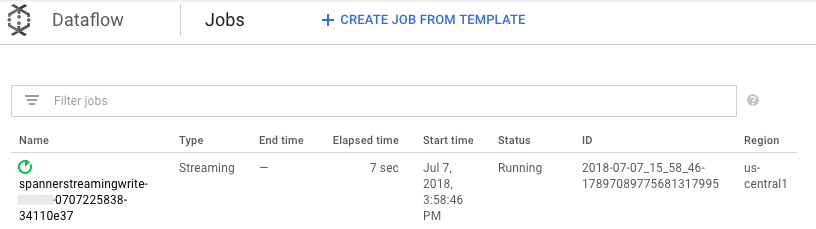
처리 그래프는 이전과 비슷한 출력을 표시하지만, 처리된 항목은 각각 상태 창에서 계산됩니다. 시스템 지연 시간은 변경사항이 Spanner 테이블에 반영되기 전에 예상되는 지연 시간을 대략적으로 추정한 시간입니다.
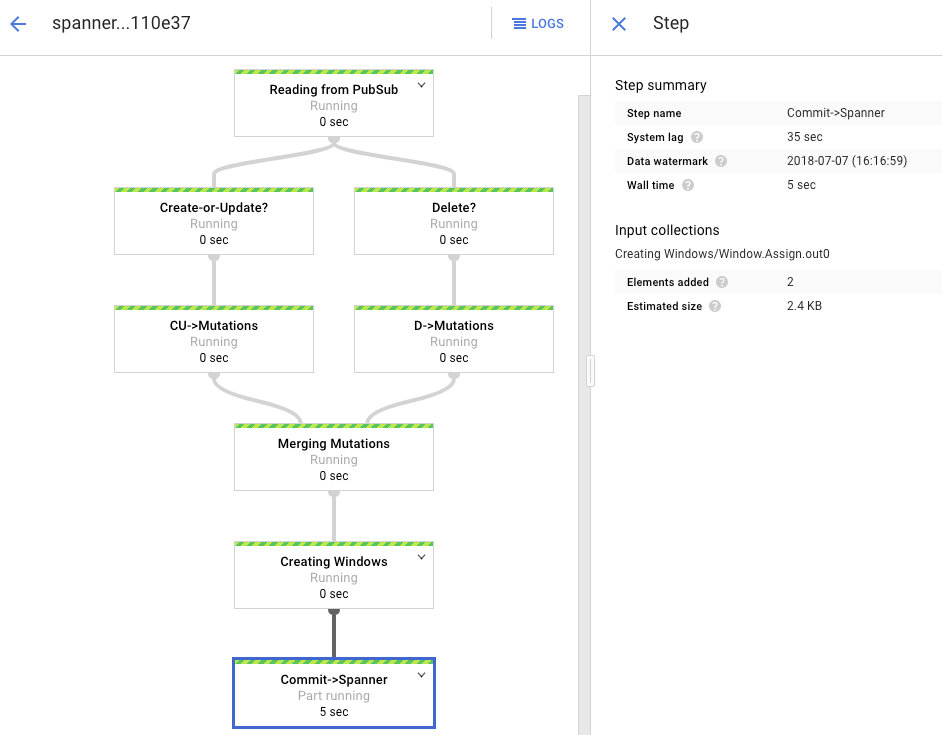
Spanner에 존재하지 않는 행을 쿼리합니다.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"이 작업은 결과를 반환하지 않습니다.
Spanner 쿼리에 사용한 것과 동일한 키를 사용하여 Amazon DynamoDB에서 레코드를 만듭니다. 명령어가 성공적으로 실행될 경우 출력되는 내용은 없습니다.
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'같은 쿼리를 다시 실행하여 이제 해당 행이 Spanner에 있는지 확인합니다.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"삽입된 행이 출력에 표시됩니다.
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
원래 항목에서 일부 속성을 변경하고 Amazon DynamoDB 테이블을 업데이트합니다.
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEW다음과 비슷한 출력이 표시됩니다.
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }변경사항이 Spanner 테이블에 전파되었는지 확인합니다.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"다음과 같이 출력이 표시됩니다.
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Amazon DynamoDB 소스 테이블에서 테스트 항목을 삭제합니다.
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'해당 행이 Spanner 테이블에서 삭제되었는지 확인합니다. 변경사항이 전파되면 다음 명령어가 행을 반환하지 않습니다.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Spanner로 이동합니다.
Spanner 스튜디오를 클릭합니다.
쿼리 필드에 다음 쿼리를 입력하고 쿼리 실행을 클릭합니다.
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
쿼리가 실행되면 설명을 클릭하고 스캔된 행과 반환된 행을 기록합니다. 색인이 없으면 Spanner가 전체 테이블을 스캔하여 쿼리와 일치하는 소규모 데이터 하위 집합을 반환합니다.
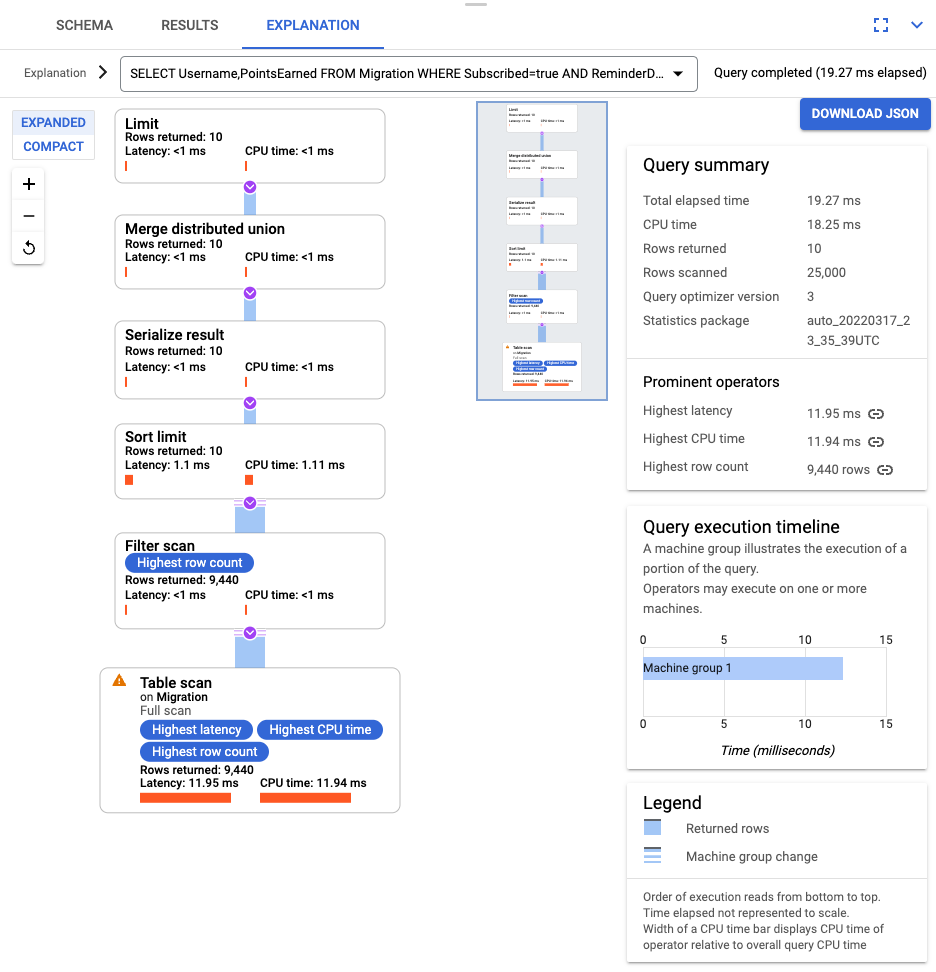
이 데이터 집합이 자주 수행되는 쿼리를 나타내는 경우에는 Subscribed 및 ReminderDate 열에서 복합 색인을 만듭니다. Spanner 콘솔에서 색인 왼쪽 탐색 창을 선택한 후 색인 만들기를 클릭합니다.
텍스트 상자에 색인 정의를 입력합니다.
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
백그라운드에서 데이터베이스를 만들기 시작하려면 만들기를 클릭합니다.
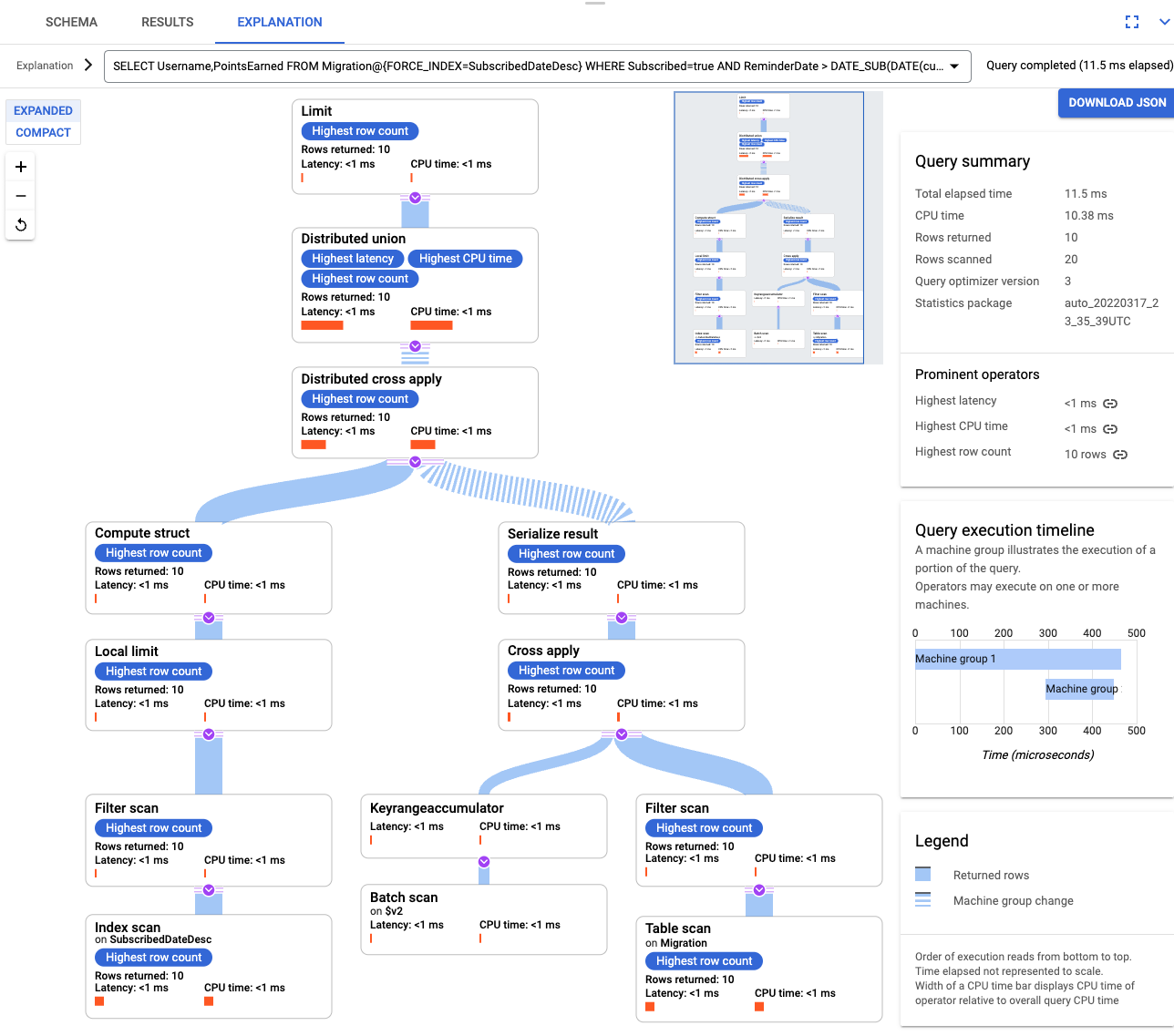
색인을 만든 후에는 쿼리를 다시 실행하고 색인을 추가합니다.
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10쿼리 설명을 다시 검토합니다. 스캔된 행 수가 줄어든 것을 볼 수 있습니다. 각 단계의 반환된 행은 쿼리가 반환한 횟수와 일치합니다.
수신한 JSON을 파싱하고 변형을 빌드하려면 GSON을 사용합니다. JSON 정의를 데이터에 맞게 조정합니다.
해당 JSON 매핑을 조정합니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Migration이라는 DynamoDB 테이블을 삭제합니다.
- 마이그레이션 단계 중에 만든 Amazon S3 버킷 및 Lambda 함수를 삭제합니다.
- 마지막으로 이 튜토리얼을 진행하면서 만든 AWS IAM 사용자를 삭제합니다.
- Spanner 스키마 최적화 방법 알아보기
- 더 복잡한 상황에서 Dataflow를 사용하는 방법 알아보기
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
개발 환경 준비
이 튜토리얼에서는 Cloud Shell에서 명령어를 실행합니다. Cloud Shell은 Google Cloud의 명령줄에 대한 액세스 권한을 제공하고 Google Cloud CLI 및 Google Cloud 개발에 필요한 기타 도구를 포함합니다. Cloud Shell은 초기화하는 데 몇 분 정도 걸릴 수 있습니다.
AWS 액세스 구성
이 튜토리얼에서는 Amazon DynamoDB 테이블, Amazon S3 버킷 및 기타 리소스를 만들고 삭제합니다. 이러한 리소스에 액세스하려면 먼저 필수 AWS Identity and Access Management(IAM) 권한을 만들어야 합니다. 테스트 또는 샌드박스 AWS 계정을 사용하여 같은 계정에서 프로덕션 리소스에 영향을 주는 것을 방지할 수 있습니다.
AWS Lambda를 위한 AWS IAM 역할 만들기
이 섹션에서는 AWS Lambda가 튜토리얼의 이후 단계에서 사용하는 AWS IAM 역할을 만듭니다.
AWS IAM 사용자 만들기
다음 단계를 따라 이 튜토리얼 전반에서 사용할 AWS 리소스에 대한 프로그래매틱 액세스 권한이 있는 AWS IAM 사용자를 만듭니다.
AWS 명령줄 인터페이스 구성
데이터 모델 이해
다음 섹션에서는 Amazon DynamoDB 및 Spanner의 데이터 유형, 키, 색인 간 유사점과 차이점을 간략하게 설명합니다.
데이터 유형
Spanner는 GoogleSQL 데이터 유형을 사용합니다. 다음 표에서는 Amazon DynamoDB 데이터 유형이 Spanner 데이터 유형에 매핑되는 방식을 설명합니다.
| Amazon DynamoDB | Spanner |
|---|---|
| 숫자 | 정밀도나 사용 용도에 따라 INT64, FLOAT64, TIMESTAMP, DATE에 매핑될 수 있습니다. |
| 문자열 | 문자열 |
| 불리언 | BOOL |
| Null | 명시적인 유형이 없습니다. 열에 null 값이 포함될 수 있습니다. |
| 바이너리 | 바이트 |
| 세트 | 배열 |
| 지도 및 목록 | 구조가 일관되고 테이블 DDL 구문을 사용하여 설명할 수 있는 경우의 구조체입니다. |
기본 키
Amazon DynamoDB 기본 키는 고유성을 설정하며 해시 키이거나 해시 키와 범위 키의 조합일 수 있습니다. 이 튜토리얼에서는 기본 키가 해시 키인 Amazon DynamoDB 테이블의 마이그레이션을 보여주는 것부터 시작합니다. 이 해시 키는 Spanner 테이블의 기본 키가 됩니다. 나중에 인터리브 처리된 테이블에 관한 섹션에서는 Amazon DynamoDB 테이블이 해시 키와 범위 키로 구성된 기본 키를 사용하는 상황을 모델링합니다.
보조 색인
Amazon DynamoDB와 Spanner 모두 기본 키가 아닌 속성에서 색인을 만드는 것을 지원합니다. 이 튜토리얼의 후반부에서 다루는 Spanner 테이블에서 색인을 만들 수 있도록 Amazon DynamoDB 테이블의 보조 색인을 기록해 두세요.
샘플 테이블
이 튜토리얼을 쉽게 활용하기 위해 다음 샘플 테이블을 Amazon DynamoDB에서 Spanner로 마이그레이션합니다.
| Amazon DynamoDB | Spanner | |
|---|---|---|
| 표 이름 |
Migration
|
Migration
|
| 기본 키 |
"Username" : String
|
"Username" : STRING(1024)
|
| 키 유형 | 해시 | 해당 없음 |
| 기타 필드 |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Amazon DynamoDB 테이블 준비
다음 섹션에서는 Amazon DynamoDB 소스 테이블을 만들고 데이터로 채웁니다.
Spanner 데이터베이스 만들기
가능한 최소 컴퓨팅 용량인 처리 단위 100개로 Spanner 인스턴스를 만듭니다. 이 컴퓨팅 용량은 이 튜토리얼 범위에 충분합니다. 프로덕션 배포의 경우 Spanner 인스턴스 문서를 참조하여 데이터베이스 성능 요구사항을 충족하는 데 적절한 컴퓨팅 용량을 결정합니다.
이 예시에서는 테이블 스키마를 데이터베이스와 동시에 만듭니다. 일반적으로 데이터베이스를 만든 후에 스키마 업데이트를 수행할 수 있습니다.
마이그레이션 준비
다음 섹션에서는 Amazon DynamoDB 소스 테이블을 내보내는 방법과 테이블을 내보내는 동안 발생하는 모든 데이터베이스 변경사항을 캡처하도록 Pub/Sub 복제를 설정하는 방법을 보여줍니다.
변경사항을 Pub/Sub에 스트리밍
AWS Lambda 함수를 사용하여 데이터베이스 변경사항을 Pub/Sub에 스트리밍합니다.
Amazon S3로 Amazon DynamoDB 테이블 내보내기
마이그레이션 수행
이제 Pub/Sub가 제공되므로 내보내기 이후에 발생한 테이블 변경사항을 푸시해 전달할 수 있습니다.
내보낸 테이블을 Cloud Storage에 복사
데이터 일괄 가져오기
새 변경사항 복제
일괄 가져오기 작업이 완료되면 소스 테이블에서 Spanner로 진행중인 업데이트를 기록하도록 스트리밍 작업을 설정합니다. Pub/Sub의 이벤트를 구독하여 Spanner에 기록합니다.
사용자가 만든 Lambda 함수는 소스 Amazon DynamoDB 테이블의 변경사항을 캡처하여 Pub/Sub에 게시하도록 구성됩니다.
일괄 로드 단계에서 실행한 Dataflow 작업은 유한한 입력값 집합이었으며, 이를 제한된 데이터 세트라고도 합니다. 이 Dataflow 작업은 Pub/Sub를 스트리밍 소스로 사용하며, 무제한으로 간주됩니다. 이 2가지 유형의 소스에 대한 자세한 내용은 Apache Beam 프로그래밍 가이드의 PCollections 섹션을 참조하세요. 이 단계의 Dataflow 작업은 활성 상태를 유지해야 하므로 완료 시 종료되지 않습니다. Dataflow 스트리밍 작업은 성공 상태로 바뀌는 대신 실행 중 상태로 남아 있습니다.
복제 확인
소스 테이블을 변경하여 변경사항이 Spanner 테이블에 복제되었는지 확인합니다.
인터리브 처리된 테이블 사용
Spanner는 테이블 인터리브 처리 개념을 지원합니다. 이 개념은 최상위 항목에 해당 최상위 항목과 관련된 여러 개의 중첩된 항목이 있는 설계 모델입니다(예: 고객과 고객 주문, 플레이어와 플레이어 게임 점수). Amazon DynamoDB 소스 테이블이 해시 키와 범위 키로 구성된 기본 키를 사용하는 경우, 다음 다이어그램의 내용처럼 인터리브 처리된 테이블 스키마를 모델링할 수 있습니다. 이 구조를 사용하면 상위 테이블에서 필드를 결합할 때 인터리브 처리된 테이블을 효율적으로 쿼리할 수 있습니다.

보조 색인 적용
권장사항은 데이터를 로드한 후에 보조 색인을 Spanner 테이블에 적용하는 것입니다. 이제 복제를 할 수 있기 때문에 보조 색인을 설정하여 쿼리 속도를 높일 수 있습니다. Spanner 테이블과 마찬가지로 Spanner 보조 색인은 일관적입니다. 많은 NoSQL 데이터베이스에서 일반적으로 적용되는 eventual consistency를 가지지 않습니다. 이 기능을 사용하면 앱 설계가 간소화됩니다.
색인을 사용하지 않는 쿼리를 실행합니다. 특정 열 값을 기준으로 상위 N개의 일치하는 항목을 찾습니다. 데이터베이스 효율성을 보장하기 위해 Amazon DynamoDB에서 자주 사용하는 쿼리입니다.
인터리브 처리된 색인
Spanner에서 인터리브 처리된 색인을 설정할 수 있습니다. 이전 섹션에서 설명한 보조 색인은 데이터베이스 계층 구조의 루트에 있으며, 기존의 데이터베이스와 동일한 방법으로 색인을 사용합니다. 인터리브 처리된 색인은 인터리브 처리된 행의 컨텍스트 내에 있습니다. 인터리브 처리된 색인을 적용할 위치에 대한 자세한 내용은 색인 옵션을 참조하세요.
데이터 모델 조정
이 튜토리얼의 이전하기 부분을 사용자의 상황에 맞춰 조정하려면 Apache Beam 소스 파일을 수정하세요. 실제 마이그레이션 기간 중에 소스 스키마를 변경하지 않는 것이 중요합니다. 그렇지 않으면 데이터가 손실될 수 있습니다.
이전 단계에서는 Apache Beam 소스 코드를 수정해 일괄 가져오기 작업을 수행했습니다. 파이프라인의 스트리밍 부분에 대한 소스 코드를 비슷한 방식으로 수정하세요. 마지막으로 Spanner 대상 데이터베이스의 테이블 생성 스크립트, 스키마, 색인을 조정합니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트는 유지하되 개별 리소스를 삭제하세요.
프로젝트 삭제
AWS 리소스 삭제
이 튜토리얼 외의 다른 곳에서 AWS 계정을 사용하는 경우, 다음 리소스를 삭제할 때 주의하세요.