En esta página, se describen varias formas de implementar múltiples usuarios en Spanner. También se analizan los patrones de administración de datos y la administración del ciclo de vida de los usuarios. Está dirigido a los arquitectos de bases de datos, los arquitectos de datos y los ingenieros que implementan aplicaciones multiusuario en Spanner como su base de datos relacional. Con ese contexto, se describen varios enfoques para almacenar datos multiusuario. Los términos “usuario”, “cliente” y “organización” se usan de manera intercambiable en todo el artículo para indicar la entidad que accede a la aplicación multiusuario. Los ejemplos que se proporcionan en esta página se basan en la implementación de una aplicación multiusuario de un proveedor de SaaS de recursos humanos (RR.HH.) en Google Cloud. Un requisito es que varios clientes del proveedor de SaaS de RR.HH. deben acceder a la aplicación multiusuario. Estos clientes se denominan usuarios.
Multiusuario
La configuración multiusuario se aplica cuando una sola instancia, o algunas instancias, de una aplicación de software se entrega a varios usuarios o clientes. Este patrón de software puede escalar de un solo usuario o cliente a cientos o miles. Este enfoque es fundamental para las plataformas de computación en la nube en las que la infraestructura subyacente se comparte entre varias organizaciones.
Piensa en el uso de la arquitectura multiusuario como una forma de partición basada en recursos de procesamiento compartidos, como las bases de datos. Una analogía son los inquilinos en un edificio de apartamentos: los inquilinos comparten la infraestructura, como las tuberías de agua y las líneas eléctricas, pero cada inquilino tiene un espacio dedicado en un apartamento. La arquitectura multiusuario es parte de la mayoría de las aplicaciones de software como servicio (SaaS), si no de todas.
Spanner es la base de datos uniforme, distribuida y completamente administrada de Google Cloudque combina los beneficios del modelo de base de datos relacional con escalabilidad horizontal no relacional. Spanner tiene semántica relacional con esquemas, tipos de datos aplicados, coherencia sólida, transacciones ACID de varias instrucciones y un lenguaje de consulta en SQL que implementa SQL ANSI 2011. Proporciona un tiempo de inactividad cero para el mantenimiento planificado o los fallos regionales, con un ANS de disponibilidad del 99.999%. Spanner también admite aplicaciones modernas multiusuario, ya que proporciona alta disponibilidad y escalabilidad.
Criterios para la asignación de datos de usuarios
En una aplicación multiusuario, los datos de cada instancia se aíslan en uno de varios enfoques de arquitectura en la base de datos subyacente de Spanner. En la siguiente lista, se describen los diferentes enfoques de arquitectura que se usan para asignar los datos de un usuario a Spanner:
- Instancia: Un usuario reside de forma exclusiva en una instancia de Spanner, con exactamente una base de datos para ese usuario.
- Base de datos: Un usuario reside en una base de datos en una sola instancia de Spanner que contiene varias bases de datos.
- Tabla: Un usuario reside en tablas exclusivas dentro de una base de datos y se pueden encontrar varios usuarios en la misma base de datos.
- Fila: Los datos de usuarios son filas en tablas de bases de datos. Esas tablas se comparten con otros usuarios.
Los criterios anteriores se denominan patrones de administración de datos y se analizan en detalle en la sección Patrones de administración de datos multiusuario. Ese análisis se basa en los siguientes criterios:
- Aislamiento de datos: El grado de aislamiento de datos entre varios usuarios es una consideración importante para los usuarios múltiples. Por ejemplo, si los datos deben separarse de forma física o lógica, y si hay LCA (listas de control de acceso) independientes que se pueden establecer para los datos de cada arrendatario. El aislamiento se debe a las decisiones que se tomaron para los criterios de otras categorías. Por ejemplo, ciertos requisitos normativos y de cumplimiento pueden dictar un mayor grado de aislamiento.
- Agilidad: La facilidad de incorporación y desvinculación de las actividades de un usuario respecto de la creación de una instancia, una base de datos, una tabla o una fila.
- Operaciones: La disponibilidad o complejidad de la implementación de operaciones típicas, específicas del inquilino y actividades de administración de bases de datos. Por ejemplo, mantenimiento regular, registros, copias de seguridad u operaciones de recuperación ante desastres.
- Escalamiento: La capacidad de escalar sin problemas para permitir el crecimiento futuro. La descripción de cada patrón contiene la cantidad de usuarios que admite el patrón.
- Rendimiento:
- Aislamiento de recursos: La capacidad de asignar recursos exclusivos a cada usuario, abordar el fenómeno de vecino real y habilitar el rendimiento de lectura y escritura predecible para cada usuario.
- Recursos mínimos por arrendatario: Es la cantidad mínima promedio de recursos por arrendatario. Esto no significa necesariamente que debas pagar al menos esta cantidad por cada inquilino individual, sino que debes pagar al menos N * esta cantidad por todos los N inquilinos juntos.
- Eficiencia de recursos: Es la capacidad de usar los recursos inactivos de otros inquilinos para ahorrar costos generales.
- Selección de ubicación para la optimización de la latencia: Capacidad de elegir una topología de replicación específica para cada arrendatario, de modo que los datos de cada arrendatario se puedan colocar en la ubicación que proporcione la mejor latencia para el arrendatario.
- Reglamentaciones y cumplimiento: Capacidad para abordar los requisitos de industrias y países altamente regulados que exigen el aislamiento completo de los recursos y las operaciones de mantenimiento. Por ejemplo, los requisitos de residencia de datos de Francia exigen que la información de identificación personal se almacene físicamente solo dentro de Francia. Las industrias financieras suelen requerir claves de encriptación administradas por el cliente (CMEK), y es posible que cada arrendatario quiera usar su propia clave de encriptación.
Cada patrón de administración de datos relacionado con estos criterios se detalla en la siguiente sección. Usa los mismos criterios cuando selecciones un patrón de administración de datos para un conjunto específico de usuarios.
Patrones de administración de datos multiusuario
En las siguientes secciones, se describen los cuatro patrones principales de administración de datos: instancias, bases de datos, tablas y filas.
Instancia
Para proporcionar un aislamiento completo, el patrón de administración de datos de la instancia almacena los datos de cada usuario en su propia instancia y base de datos de Spanner. Una instancia de Spanner puede tener una o más bases de datos. En este patrón, solo se crea una base de datos. En la aplicación de RR.HH. que se explicó antes, se crea una instancia de Spanner independiente con una base de datos para cada organización del cliente.
Como se ve en el siguiente diagrama, el patrón de administración de datos tiene un usuario por instancia.
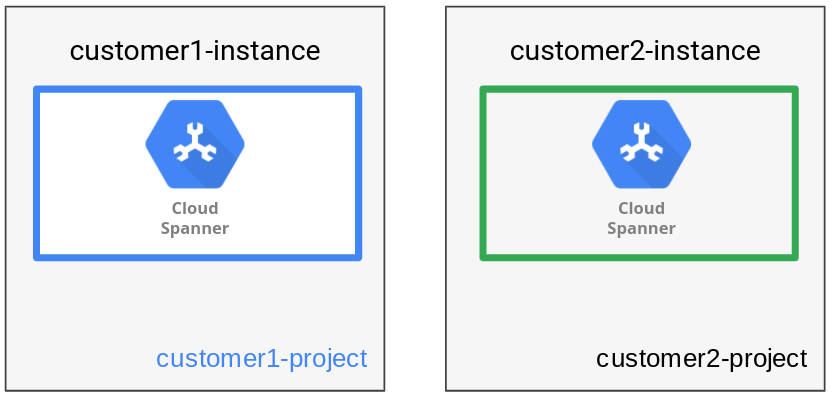
Tener instancias separadas para cada usuario permite el uso de proyectos deGoogle Cloud separados para lograr límites de confianza separados para diferentes usuarios. Un beneficio adicional es que se puede elegir cada configuración de instancia según la ubicación de cada usuario (ya sea regional o multirregional), lo que optimiza la flexibilidad y el rendimiento de la ubicación.
La arquitectura puede escalar a cualquier cantidad de usuarios. Los proveedores de SaaS pueden crear cualquier cantidad de instancias en las regiones deseadas, sin límites estrictos.
En la siguiente tabla, se describe cómo el patrón de administración de datos de instancia afecta a los diferentes criterios.
| Criterios | Instancia: un usuario por patrón de administración de datos de instancia |
|---|---|
| Aislamiento de datos |
|
| Agilidad |
|
| Operaciones |
|
| Escala |
|
| Rendimiento |
|
| Requisitos reglamentarios y de cumplimiento |
|
En resumen, los puntos clave son los siguientes:
- Ventaja: El nivel más alto de aislamiento
- Desventaja: Mayor sobrecarga operativa y, posiblemente, mayor costo debido al mínimo de 100 PU por usuario. No se admite el uso compartido de recursos entre diferentes organizaciones.
El patrón de administración de datos de instancia es más adecuado para las siguientes situaciones:
- Usuarios diferentes que se distribuyen en una amplia variedad de regiones y necesitan una solución localizada.
- Los requisitos regulatorios y de cumplimiento para algunos usuarios exigen niveles más altos de protocolos de seguridad y auditoría.
- El tamaño de los usuarios varía significativamente, de modo que compartir recursos entre usuarios de alto volumen y de tráfico alto puede causar contención y degradación mutua.
Base de datos
En el patrón de administración de datos de la base de datos, cada usuario reside en una base de datos dentro de una única instancia de Spanner. Puede haber varias bases de datos en una sola instancia. Si una instancia no es suficiente para la cantidad de usuarios, crea varias instancias. Este patrón implica que una sola instancia de Spanner se comparte entre varios usuarios.
Spanner tiene un límite estricto de 100 bases de datos por instancia. Este límite significa que, si el proveedor de SaaS necesita escalar más allá de 100 clientes, debe crear y usar varias instancias de Spanner.
En la aplicación de RR.HH., el proveedor de SaaS crea y administra cada usuario con una base de datos separada en una instancia de Spanner.
Como se ve en el siguiente diagrama, el patrón de administración de datos tiene un usuario por base de datos.
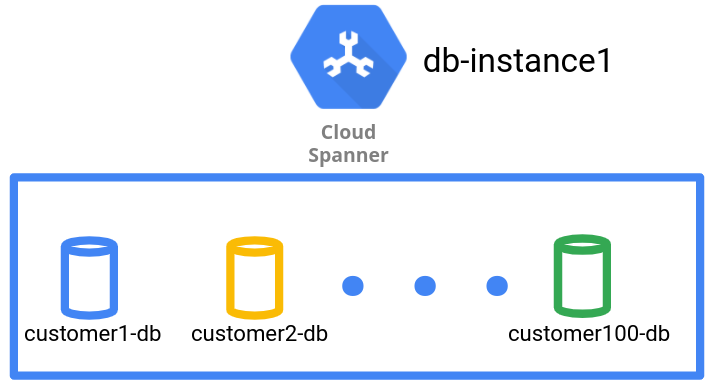
El patrón de administración de datos de base de datos logra un aislamiento lógico en el nivel de la base de datos para los datos de diferentes usuarios. Sin embargo, debido a que es una sola instancia de Spanner, todas las bases de datos de usuarios comparten la misma topología de replicación y la configuración de procesamiento y almacenamiento subyacente, a menos que se use la función de particionamiento geográfico. Puedes usar la función de partición geográfica de Spanner para crear particiones de instancias en diferentes ubicaciones y usar diferentes particiones de instancias para diferentes bases de datos en la misma instancia.
En la siguiente tabla, se describe cómo el patrón de administración de datos de base de datos afecta a los diferentes criterios.
| Criterios | Base de datos: un usuario por patrón de administración de datos de base de datos |
|---|---|
| Aislamiento de datos |
|
| Agilidad |
|
| Operaciones |
|
| Escala |
|
| Rendimiento |
|
| Requisitos reglamentarios y de cumplimiento |
|
En resumen, los puntos clave son los siguientes:
- Ventaja: Nivel moderado de aislamiento de datos y de recursos; nivel moderado de eficiencia de recursos; cada arrendatario puede tener su propia copia de seguridad y su propia CMEK.
- Desventaja: La cantidad de usuarios por instancia es limitada; inflexibilidad de la ubicación si no se usa la función de partición geográfica.
El patrón de administración de datos de base de datos es más adecuado para las siguientes situaciones:
- Varios clientes se encuentran en la misma residencia de datos o están bajo la misma autoridad reguladora.
- Los usuarios requieren separación de datos basada en el sistema y la capacidad de crear copias de seguridad y restablecer sus datos, pero funcionan bien con el uso compartido de recursos de infraestructura.
- Los arrendatarios requieren su propia CMEK.
- El costo es una consideración importante. Los recursos mínimos necesarios por inquilino son inferiores al costo de una instancia. Es conveniente que los inquilinos usen los recursos inactivos de otros inquilinos.
Tabla
En el patrón de administración de datos de tabla, se usa una sola base de datos, que implementa un solo esquema, para varios usuarios y un conjunto de tablas separado para los datos de cada usuario. Estas tablas se pueden diferenciar incluyendo tenant ID en los nombres de las tablas como un prefijo, un sufijo o como esquemas con nombre.
Este patrón de administración de datos con el uso de un conjunto separado de tablas para cada usuario proporciona un nivel de aislamiento mucho menor en comparación con las opciones anteriores (los patrones de administración de instancia y base de datos). La incorporación implica crear tablas nuevas, y la integridad referencial y los índices asociados.
Existe un límite de 5,000 tablas por base de datos. Para algunos clientes, ese límite podría restringir el uso de la aplicación.
Además, el uso de tablas separadas para cada cliente puede generar una gran acumulación de operaciones de actualización del esquema. Estas tareas pendientes tardan mucho tiempo en resolverse.
En la aplicación de RR.HH., el proveedor de SaaS puede crear un conjunto de tablas para cada cliente con tenant ID como prefijo en los nombres de las tablas. Por ejemplo, customer1_employee, customer1_payroll y customer1_department.
Como alternativa, pueden usar el ID de inquilino como un esquema con nombre y nombrar su tabla como customer1.employee, customer1.payroll y customer1.department.
Como se muestra en el siguiente diagrama, el patrón de administración de datos de tabla tiene un conjunto de tablas para cada usuario.
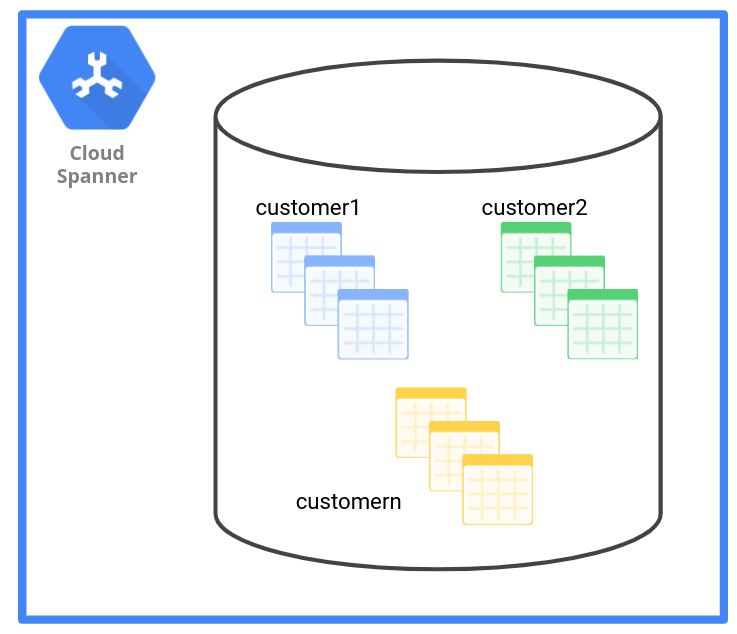
En la siguiente tabla, se describe cómo el patrón de administración de datos de tabla afecta a los diferentes criterios.
| Criterios | Tabla: Un conjunto de tablas para cada patrón de administración de datos de usuarios |
|---|---|
| Aislamiento de datos |
|
| Agilidad |
|
| Operaciones |
|
| Escala |
|
| Rendimiento |
|
| Requisitos reglamentarios y de cumplimiento |
|
En resumen, los puntos clave son los siguientes:
- Ventajas: Nivel moderado de escalabilidad y eficiencia de recursos.
- Desventaja:
- Nivel moderado de aislamiento de datos y aislamiento de recursos
- La ubicación es inflexible si no se usa la nueva función de partición geográfica.
- No se pueden supervisar los usuarios por separado. La única información disponible sobre el consumo de recursos a nivel de la tabla son las estadísticas de tamaño de la tabla.
- Los arrendatarios no pueden tener sus propias CMEK ni copias de seguridad.
El patrón de administración de datos de tabla es más adecuado para las siguientes situaciones:
- Aplicaciones multiusuario que no requieren legalmente la separación de datos, pero en las que deseas tener separación lógica y control de seguridad.
- El costo es una consideración importante. El costo mínimo por arrendatario es más económico que el costo por base de datos.
Fila
El patrón final de administración de datos entrega usuarios múltiples con un conjunto común de tablas, y cada fila pertenece a un usuario específico. Este patrón de administración de datos representa un nivel extremo de patrón multiusuario en el que todo, desde la infraestructura hasta el esquema y el modelo de datos, se comparte entre varios usuarios. Dentro de una tabla, las filas se particionan en función de las claves primarias, con tenant ID como el primer elemento de la clave. Desde la perspectiva del escalamiento, Spanner admite mejor este patrón porque puede escalar tablas sin límites.
En la aplicación de RR. HH., la clave primaria de la tabla de nóminas puede ser una combinación de customerID y payrollID.
Como se ve en el siguiente diagrama, el patrón de administración de datos de fila tiene una tabla para varios usuarios.

A diferencia de todos los demás patrones, el acceso a los datos en el patrón de fila no se puede controlar por separado para diferentes usuarios. Usar menos tablas significa que las operaciones de actualización de esquema se completan más rápido cuando cada usuario tiene sus propias tablas de base de datos. En gran medida, este enfoque simplifica la integración, la desvinculación y las operaciones.
En la siguiente tabla, se describe cómo el patrón de administración de datos de fila afecta a los diferentes criterios.
| Criterios | Fila: Un conjunto de filas para cada patrón de administración de datos de usuarios |
|---|---|
| Aislamiento de datos |
|
| Agilidad |
|
| Operaciones |
|
| Escala |
|
| Rendimiento |
|
| Requisitos reglamentarios y de cumplimiento |
|
En resumen, los puntos clave son los siguientes:
- Ventajas: Es altamente escalable, tiene una sobrecarga operativa baja y simplifica la administración de esquemas.
- Desventaja: Alta clasificación del recurso; falta de controles de seguridad y supervisión para cada usuario
Este patrón resulta más adecuado para las siguientes situaciones:
- Aplicaciones internas que se dirigen a diferentes departamentos en los que el aislamiento estricto de seguridad de datos no es una preocupación importante en comparación con la facilidad de mantenimiento.
- Uso compartido máximo de recursos para usuarios que usan la aplicación de nivel gratuito cuando minimizan el aprovisionamiento de recursos al mismo tiempo.
Patrones de administración de datos y administración del ciclo de vida de los usuarios
En la siguiente tabla, se comparan los diversos patrones de administración de datos en todos los criterios a un alto nivel.
| Instancia | Base de datos | Tabla | Fila | |
|---|---|---|---|---|
| Aislamiento de datos | Completado | Alta | Moderado | Baja |
| Agilidad | Bajo | Moderado | Moderado | Más alto |
| Facilidad de operaciones | Alto | Alto | Bajo | Bajo |
| Escala | Alta | Limitado (a menos que se usen instancias adicionales cuando se alcance el límite) | Limitada (a menos que se usen bases de datos adicionales cuando se alcance el límite) | El más alto |
| Rendimiento1: Aislamiento de recursos | Alta | Bajo | Baja | Baja |
| Rendimiento1: Recursos mínimos por arrendatario | Alta | Moderada alta | Moderado | Sin mínimo por usuario |
| Rendimiento1: Eficiencia de recursos | Baja | Alto | Alta | Alta |
| Rendimiento1: Selección de la ubicación para la optimización de la latencia | Alta | Moderado | Moderado | Moderado |
| Reglamentos y cumplimiento | Más alto | Alta | Moderado | Baja |
1 El rendimiento depende en gran medida del diseño del esquema y de las prácticas recomendadas de consultas. Los valores que aparecen aquí son solo una expectativa promedio.
Los mejores patrones de administración de datos para una aplicación multiusuario específica son los que satisfacen la mayoría de sus requisitos según los criterios. Si no se requiere un criterio en particular, puedes ignorar la fila en la que se encuentra.
Patrones de administración de datos combinados
A menudo, un patrón de administración de datos único es suficiente para abordar los requisitos de una aplicación multiusuario. Cuando ese es el caso, el diseño puede adoptar un solo patrón de administración de datos.
Algunas aplicaciones multiusuario requieren varios patrones de administración de datos al mismo tiempo. Por ejemplo, una aplicación multiusuario que admite un nivel gratuito, un nivel regular y un nivel empresarial.
Nivel gratuito:
- Debe ser rentable
- Debe tener un límite superior de volumen de datos
- Por lo general, admite funciones limitadas
- El patrón de administración de datos de fila es un buen candidato de nivel gratuito
- La administración de usuarios es sencilla
- No es necesario crear recursos de usuarios específicos o exclusivos
Nivel regular:
- Ideal para clientes que pagan, que no tienen altos requisitos de escalamiento o aislamiento
- El patrón de administración de datos de tabla o el patrón de administración de datos de base de datos son buenos candidatos para el nivel regular:
- Las tablas y los índices son exclusivos del usuario.
- Las copias de seguridad son sencillas en el patrón de administración de datos de base de datos
- La copia de seguridad no es compatible con el patrón de administración de datos de la tabla.
- La copia de seguridad de usuario debe implementarse como una utilidad fuera de Spanner.
Nivel empresarial:
- Por lo general, un nivel alto de autonomía total en todos los aspectos
- El usuario tiene recursos dedicados que incluyen escalamiento dedicado y aislamiento completo.
- El patrón de administración de datos de instancia es adecuado para el nivel empresarial.
Una práctica recomendada es mantener diferentes patrones de administración de datos en diferentes bases de datos. Si bien es posible combinar diferentes patrones de administración de datos en una base de datos de Spanner, hacerlo dificulta la implementación de la lógica de acceso de la aplicación y las operaciones del ciclo de vida.
En la sección sobre el diseño de aplicaciones, se describen algunas consideraciones de diseño de aplicaciones multiusuario que se aplican cuando se usa un patrón de administración de datos único o varios patrones de administración de datos.
Administra el ciclo de vida del usuario
Los usuarios tienen un ciclo de vida. Por lo tanto, debes implementar las operaciones de administración correspondientes dentro de tu aplicación multiusuario. Más allá de las operaciones básicas de creación, actualización y eliminación de usuarios, considera las siguientes operaciones adicionales relacionadas con los datos:
Exporta datos de usuario:
- Cuando se borra un usuario, se recomienda exportar primero sus datos y, en lo posible, hacer que el conjunto de datos esté disponible para ellos.
- Cuando se usa el patrón de administración de datos de fila o tabla, el sistema de aplicaciones multiusuario debe implementar la exportación o mapearla a la función de base de datos (exportación de bases de datos) y, luego, implementar una lógica personalizada para extraer la porción de datos que corresponde al usuario.
Crea una copia de seguridad de los datos del usuario:
- Cuando usas el patrón de administración de datos de instancia o de base de datos y las copias de seguridad de usuarios individuales, usa las funciones de exportación o copia de seguridad de la base de datos.
- Cuando usas el patrón de administración de datos de tabla o fila y creas copias de seguridad de los datos de usuarios individuales, la aplicación multiusuario debe implementar esta operación. La base de datos de Spanner no puede determinar qué datos pertenecen a qué usuario.
Mueve datos de usuario:
Para mover un usuario de un patrón de administración de datos a otro (o mover un usuario dentro del mismo patrón de administración de datos entre instancias o bases de datos), se requiere la extracción de los datos de un patrón de administración de datos y la inserción de esos datos en el nuevo patrón de administración de datos.
- Cuando la aplicación puede tener tiempo de inactividad, realiza una importación o exportación.
- Cuando no puede haber tiempo de inactividad, realiza una migración de base de datos sin tiempo de inactividad.
Mitigar una situación de vecino ruidoso es otra razón para mover usuarios.
Diseño de aplicaciones
Cuando diseñas una aplicación multiusuario, implementas una lógica empresarial optimizada para usuarios. Esto significa que cada vez que la aplicación ejecuta la lógica empresarial, siempre debe estar en el contexto de un usuario conocido.
Desde la perspectiva de la base de datos, el diseño de la aplicación implica que cada consulta debe ejecutarse en el patrón de administración de datos en el que reside el usuario. En las siguientes secciones, se destacan algunos de los conceptos centrales del diseño de aplicaciones multiusuario.
Conexión de usuario dinámica y configuración de consulta
La asignación dinámica de datos de usuario a solicitudes de aplicación de usuarios usa una configuración de asignación:
- En el caso de los patrones de administración de datos de la base de datos o los patrones de administración de datos de una instancia, una cadena de conexión es suficiente para acceder a los datos de un usuario.
- Para los patrones de administración de datos de tablas, se deben determinar los nombres correctos de las tablas.
- En el caso de los patrones de administración de datos de fila, usa los predicados adecuados para recuperar los datos de un usuario específico.
Una instancia puede estar en cualquiera de los cuatro patrones de administración de datos. La siguiente implementación de asignación aborda una configuración de conexión para el caso general de una aplicación multiusuario que usa todos los patrones de administración de datos al mismo tiempo. Cuando un usuario determinado reside en un patrón, algunas aplicaciones multiusuario usan un patrón de administración de datos para todos los usuarios. Este caso se cubre de forma implícita mediante la siguiente asignación.
Si un usuario ejecuta la lógica empresarial (por ejemplo, un empleado que accede con su ID de usuario), la lógica de la aplicación debe determinar el patrón de administración de datos del usuario, la ubicación de los datos para un ID de usuario determinado y, opcionalmente, la convención de nomenclatura de tablas (para el patrón de tabla).
Esta lógica de aplicación requiere la asignación de patrones de administración de usuarios a datos. En la siguiente muestra de código, connection string hace referencia a la base de datos en la que residen los datos del usuario. En la muestra, se identifica la instancia de Spanner y la base de datos. Para la base de datos y la instancia de patrón de administración de datos, el siguiente código es suficiente a fin de que la aplicación conecte y ejecute consultas:
tenant id -> (data management pattern,
database connection string)
Se requiere un diseño adicional para los patrones de administración de datos de filas y tablas.
Patrón de administración de datos de tablas
Para el patrón de administración de datos de tabla, hay varios usuarios dentro de la misma base de datos. Cada grupo de usuarios tiene su propio conjunto de tablas. Las tablas se distinguen por su nombre. Qué tabla pertenece a qué usuario es determinista.
Un enfoque es colocar la tabla de cada usuario en un espacio de nombres con el nombre del usuario y calificar completamente el nombre de la tabla con namespace.name. Por ejemplo, puedes colocar una tabla EMPLOYEE dentro del espacio de nombres T356 para el usuario con el ID 356, y tu aplicación puede usar T356.EMPLOYEE para dirigir las solicitudes a la tabla.
Otro enfoque es anteponer el ID de usuario a los nombres de las tablas. Por ejemplo, la tabla EMPLOYEE se llama T356_EMPLOYEE para el usuario con el ID 356.
La aplicación debe anteponer cada tabla con el prefijo tenant
ID antes de enviar la consulta a la base de datos que devolvió la asignación.
Si deseas usar otro texto en lugar del ID de usuario, puedes mantener una asignación del ID de usuario al espacio de nombres del esquema con nombre o al prefijo de la tabla.
Para simplificar la lógica de la aplicación, puedes introducir un nivel de indirección. Por ejemplo, puedes usar una biblioteca común con tu aplicación para adjuntar automáticamente el prefijo de espacio de nombres o de tabla para la llamada del inquilino.
Patrón de administración de datos de filas
Se requiere un diseño similar para el patrón de administración de datos de filas. En este patrón, hay un solo esquema. Los datos de usuarios se almacenan como filas. Para acceder de forma correcta a los datos, agrega un predicado a cada consulta y selecciona el usuario adecuado.
Un enfoque para encontrar el usuario adecuado es tener una columna llamada TENANT en cada tabla. Para un mejor aislamiento de los datos, el valor de esta columna debe formar parte de la clave primaria. El valor de la columna es tenant ID. Cada consulta debe agregar un predicado AND TENANT = tenant ID a una cláusula WHERE existente o agregar una cláusula WHERE con el predicado AND TENANT = tenant
ID.
Para conectarse a la base de datos y crear las consultas adecuadas, el identificador de usuario debe estar disponible en la lógica de la aplicación. Se puede pasar como parámetro o almacenar como contexto de subproceso.
Algunas operaciones del ciclo de vida requieren que modifiques la configuración de asignación del patrón de administración de usuario a dato Por ejemplo, cuando mueves un usuario entre patrones de administración de datos, debes actualizar el patrón de administración de datos y la string de conexión a la base de datos. Es posible que también debas actualizar el prefijo de la tabla.
Generación y atribución de consultas
Un principio subyacente fundamental de las aplicaciones multiusuario es que varios usuarios pueden compartir un solo recurso de nube. Los patrones de administración de datos anteriores se dividen en esta categoría, excepto en el caso de que se asigne un usuario único a una sola instancia de Spanner.
El uso compartido de recursos va más allá de compartir datos. También se comparten la supervisión y el registro. Por ejemplo, en el patrón de administración de datos de tabla y el patrón de administración de datos de fila, todas las consultas de todos los usuarios se registran en el mismo registro de auditoría.
Si se registra una consulta, este debe examinarse el texto de la consulta para determinar para qué usuario se ejecutó. En el patrón de administración de datos de filas, debes analizar el predicado. En el patrón de administración de datos de tablas, debes analizar uno de los nombres de la tabla.
En el patrón de administración de datos de base de datos o en el de administración de datos de instancia, el texto de la consulta no tiene información de usuarios. Para obtener información del usuario para estos patrones, debes consultar la tabla de asignación de patrones de administración de datos a usuarios.
Sería más fácil analizar los registros y las consultas si se determina el usuario para una consulta determinada sin analizar el texto de la consulta. Una forma de identificar de manera uniforme un usuario para una consulta en todos los patrones de administración de datos es agregar un comentario al texto de la consulta que tiene tenant ID y, de forma opcional, una label.
En la siguiente consulta, se seleccionan todos los datos del empleado para el grupo de usuarios que identifica TENANT 356. Para evitar analizar la sintaxis de SQL y extraer el ID de usuario del predicado, el ID de usuario se agrega como un comentario. Se puede extraer un comentario sin tener que analizar la sintaxis de SQL.
SELECT * FROM EMPLOYEE
-- TENANT 356
WHERE TENANT = 'T356';
o
SELECT * FROM T356_EMPLOYEE;
-- TENANT 356
Con este diseño, cada ejecución de una consulta para un usuario se atribuye a ese usuario con independencia del patrón de administración de datos. Si un usuario se mueve de un patrón de administración de datos a otro, el texto de la consulta puede cambiar, pero la atribución se mantiene igual en el texto de consulta.
La muestra de código anterior es solo un método. Otro método es insertar un objeto JSON como un comentario en lugar de una etiqueta y un valor:
SELECT * FROM T356_EMPLOYEE;
-- {"TENANT": 356}
También puedes usar etiquetas para atribuir búsquedas a los inquilinos y ver las estadísticas en las tablas spanner_sys integradas.
Operaciones del ciclo de vida de acceso de usuario
Según tu filosofía de diseño, una aplicación multiusuario puede implementar directamente las operaciones del ciclo de vida de los datos descritas antes, o puede crear una herramienta de administración de usuarios separada.
Independientemente de la estrategia de implementación, es posible que las operaciones del ciclo de vida deban ejecutarse sin la lógica de la aplicación en ejecución al mismo tiempo. Por ejemplo, mientras se mueve un usuario de un patrón de administración de datos a otro, la lógica de la aplicación no pueden ejecutar porque los datos no están en una sola base de datos. Cuando los datos no están en una sola base de datos, requieren dos operaciones adicionales desde la perspectiva de una aplicación:
- Detener una instancia: Inhabilita todo el acceso a la lógica de la aplicación mientras permite las operaciones del ciclo de vida de los datos.
- Iniciar un usuario: La lógica de la aplicación puede acceder a los datos de un usuario mientras las operaciones del ciclo de vida que interfieren en la lógica de la aplicación están inhabilitadas.
Si bien no se usa con frecuencia, el cierre de un usuario de emergencia puede ser otra operación importante del ciclo de vida. Usa este cierre cuando sospeches un incumplimiento y debas prohibir todo el acceso a los datos del usuario, no solo la lógica de la aplicación, sino también las operaciones del ciclo de vida. Un incumplimiento se puede originar dentro o fuera de la base de datos.
También debe estar disponible una operación del ciclo de vida coincidente que quite el estado de emergencia. Esta operación puede requerir que dos o más administradores accedan al mismo tiempo para implementar el control mutuo.
Aislamiento de aplicaciones
Los diversos patrones de administración de datos admiten diferentes grados de aislamiento de datos de usuarios. Desde el nivel más aislado (instancia) hasta el menos aislado (fila), son posibles diferentes grados de aislamiento.
En el contexto de una aplicación multiusuario, se debe tomar una decisión de implementación similar: ¿todos los usuarios acceden a sus datos (en patrones de administración de datos posiblemente diferentes) con la misma implementación de la aplicación? Por ejemplo, un clúster de Kubernetes único podría ser compatible con todos los usuarios y cuando un usuario accede a sus datos, el mismo clúster ejecuta la lógica empresarial.
Como alternativa, como en el caso de los patrones de administración de datos, se pueden dirigir diferentes usuarios a distintas implementaciones de aplicaciones. Los usuarios grandes pueden tener acceso a una implementación de aplicación exclusiva para ellos, mientras que los usuarios más pequeños en el nivel gratuito comparten una implementación de aplicación.
En lugar de hacer coincidir de forma directa los patrones de administración de datos que se analizan en este documento con patrones de administración de datos de aplicación equivalentes, puedes usar el patrón de administración de datos de base de datos para que todos los usuarios compartan una implementación de aplicación única. Es posible que el patrón de administración de datos de base de datos y todos estos usuarios compartan una sola implementación de la aplicación.
La arquitectura multiusuarios es un patrón de administración de datos de aplicación importante, en especial cuando la eficiencia de los recursos juega una función fundamental. Spanner admite varios patrones de administración de datos; úsalo para implementar aplicaciones multiusuario. Proporciona un tiempo de inactividad cero para el mantenimiento planificado o los fallos regionales, con un ANS de disponibilidad del 99.999%. También admite aplicaciones modernas multiusuario, ya que proporciona alta disponibilidad y escalabilidad.