- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- 試してみましょう機能。この機能は Spanner API リファレンス ドキュメントから利用可能です。このページで紹介している例では試してみましょう機能を使用しています。
- Google APIs Explorer。Cloud Spanner API などの Google API が含まれています。
- HTTP REST 呼び出しをサポートするその他のツールまたはフレームワーク。
ここでの例では
[PROJECT_ID]を Google Cloud プロジェクト ID として使用しています。[PROJECT_ID]は使用するGoogle Cloud プロジェクト ID に置き換えます。プロジェクト ID には[と]を使用しないでください。ここでの例ではインスタンス ID
test-instanceを作成して使用します。test-instanceを使用しない場合は自分のインスタンス ID に置き換えてください。ここでの例ではデータベース ID
example-dbを作成して使用します。example-dbを使用しない場合は自分のデータベース ID に置き換えてください。ここでの例では
[SESSION]をセッション名の一部として使用しています。[SESSION]は、セッションの作成時に生成される値に置き換えてください。(セッション名には[と]を使用しないでください。)ここでの例ではトランザクション ID
[TRANSACTION_ID]を使用します。[TRANSACTION_ID]はトランザクションの作成時に生成される値に置き換えてください。(トランザクション ID には[と]を使用しないでください。)試してみましょう機能を使用すると、各 HTTP リクエスト フィールドをインタラクティブに追加できます。このトピックの例の大部分では、リクエストに個別のフィールドをインタラクティブに追加する方法を説明する代わりに、リクエスト全体を使用しています。
projects.instanceConfigs.listをクリックします。[parent] に以下のように入力します。
projects/[PROJECT_ID][実行] をクリックします。使用可能なインスタンス構成がレスポンスに表示されます。レスポンスの例を以下にあげます(実際のプロジェクトではインスタンス構成が異なる場合があります)。
{ "instanceConfigs": [ { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-south1", "displayName": "asia-south1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-east1", "displayName": "asia-east1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-northeast1", "displayName": "asia-northeast1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-europe-west1", "displayName": "europe-west1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-east4", "displayName": "us-east4" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-central1", "displayName": "us-central1" } ] }projects.instances.createをクリックします。[parent] に以下のように入力します。
projects/[PROJECT_ID][Add request body parameters] をクリックして
instanceを選択します。インスタンスのヒントのふきだしをクリックして、使用可能なフィールドを確認します。以下のフィールドで値を追加します。
nodeCount: 「1」を入力します。config: インスタンス構成の一覧表示で返されたいずれかのリージョン インスタンス構成のname値を入力します。displayName: 「Test Instance」を入力します。
インスタンスの閉じかっこの後にあるヒントのふきだしをクリックして instanceId を選択します。
instanceIdに「test-instance」を入力します。
試してみましょうのインスタンス作成ページは次のようになります。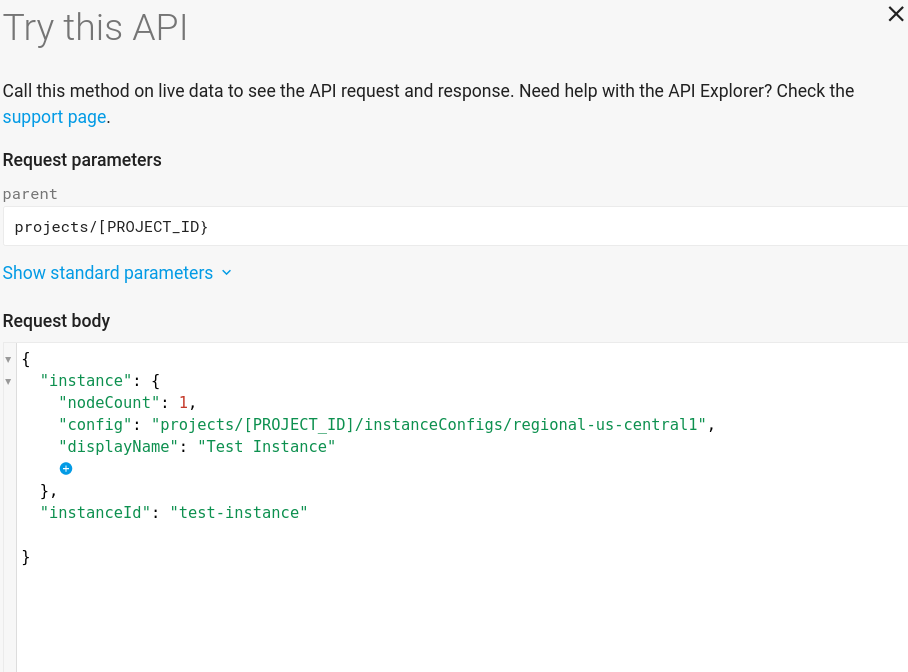
[実行] をクリックします。レスポンスで長時間実行オペレーションが返されます。これをクエリするとステータスを確認できます。
projects.instances.databases.createをクリックします。[parent] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance[Add request body parameters] をクリックして
createStatementを選択します。createStatementに以下のように入力します。CREATE DATABASE `example-db`(データベース名
example-dbにはハイフンがあるため、バッククォート(`)で囲む必要があります)[実行] をクリックします。レスポンスで長時間実行オペレーションが返されます。これをクエリするとステータスを確認できます。
projects.instances.databases.updateDdlをクリックします。[database] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db[Request body] で以下のように入力します。
{ "statements": [ "CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)", "CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE" ] }statements配列にはスキーマを定義する DDL ステートメントが含まれます。[実行] をクリックします。レスポンスで長時間実行オペレーションが返されます。これをクエリするとステータスを確認できます。
projects.instances.databases.sessions.createをクリックします。[database] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db[実行] をクリックします。
応答には作成したセッションが以下の形式で表示されます。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]このセッションはデータベースで読み取りまたは書き込みを行う場合に使用します。
projects.instances.databases.sessions.commitをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "insertOrUpdate": { "table": "Singers", "columns": [ "SingerId", "FirstName", "LastName" ], "values": [ [ "1", "Marc", "Richards" ], [ "2", "Catalina", "Smith" ], [ "3", "Alice", "Trentor" ], [ "4", "Lea", "Martin" ], [ "5", "David", "Lomond" ] ] } }, { "insertOrUpdate": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "values": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ] } } ] }[実行] をクリックします。レスポンスに commit タイムスタンプが表示されます。
projects.instances.databases.sessions.executeSqlをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums" }[実行] をクリックします。レスポンスにクエリの結果が表示されます。
projects.instances.databases.sessions.readをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true } }[実行] をクリックします。レスポンスに読み取りの結果が表示されます。
projects.instances.databases.updateDdlをクリックします。[database] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db[Request body] で以下のように入力します。
{ "statements": [ "ALTER TABLE Albums ADD COLUMN MarketingBudget INT64" ] }statements配列にはスキーマを定義する DDL ステートメントが含まれます。[実行] をクリックします。この処理は完了まで数分かかることがあります。これは REST 呼び出しがレスポンスを返した後であっても同様です。レスポンスで長時間実行オペレーションが返されます。これをクエリするとステータスを確認できます。
projects.instances.databases.sessions.commitをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "update": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "MarketingBudget" ], "values": [ [ "1", "1", "100000" ], [ "2", "2", "500000" ] ] } } ] }[実行] をクリックします。レスポンスに commit タイムスタンプが表示されます。
projects.instances.databases.sessions.executeSqlをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "sql": "SELECT SingerId, AlbumId, MarketingBudget FROM Albums" }[実行] をクリックします。レスポンスの中に、更新された
MarketingBudget値を含む 2 行が次のように表示されます。"rows": [ [ "1", "1", "100000" ], [ "1", "2", null ], [ "2", "1", null ], [ "2", "2", "500000" ], [ "2", "3", null ] ]projects.instances.databases.updateDdlをクリックします。[database] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db[Request body] で以下のように入力します。
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle)" ] }[実行] をクリックします。この処理は完了まで数分かかることがあります。これは REST 呼び出しがレスポンスを返した後であっても同様です。レスポンスで長時間実行オペレーションが返されます。これをクエリするとステータスを確認できます。
projects.instances.databases.sessions.executeSqlをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "sql": "SELECT AlbumId, AlbumTitle, MarketingBudget FROM Albums WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo'" }[実行] をクリックします。レスポンスの中に次のような行が表示されます。
"rows": [ [ "2", "Go, Go, Go", null ], [ "2", "Forever Hold Your Peace", "500000" ] ]projects.instances.databases.sessions.readをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle" }[実行] をクリックします。レスポンスの中に次のような行が表示されます。
"rows": [ [ "2", "Forever Hold Your Peace" ], [ "2", "Go, Go, Go" ], [ "1", "Green" ], [ "3", "Terrified" ], [ "1", "Total Junk" ] ]projects.instances.databases.updateDdlをクリックします。[database] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db[Request body] で以下のように入力します。
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget)" ] }[実行] をクリックします。この処理は完了まで数分かかることがあります。これは REST 呼び出しがレスポンスを返した後であっても同様です。レスポンスで長時間実行オペレーションが返されます。これをクエリするとステータスを確認できます。
projects.instances.databases.sessions.readをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle", "MarketingBudget" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle2" }[実行] をクリックします。レスポンスの中に次のような行が表示されます。
"rows": [ [ "2", "Forever Hold Your Peace", "500000" ], [ "2", "Go, Go, Go", null ], [ "1", "Green", null ], [ "3", "Terrified", null ], [ "1", "Total Junk", "100000" ] ]projects.instances.databases.sessions.beginTransactionをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION][Request body] で以下のように入力します。
{ "options": { "readOnly": {} } }[実行] をクリックします。
作成したトランザクションの ID がレスポンスに表示されます。
projects.instances.databases.sessions.executeSqlをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums", "transaction": { "id": "[TRANSACTION_ID]" } }[実行] をクリックします。レスポンスに次のような行が表示されます。
"rows": [ [ "2", "2", "Forever Hold Your Peace" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "3", "Terrified" ], [ "1", "1", "Total Junk" ] ]projects.instances.databases.sessions.readをクリックします。[session] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION](この値はセッションの作成時に取得します)
[Request body] で以下のように入力します。
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "transaction": { "id": "[TRANSACTION_ID]" } }[実行] をクリックします。レスポンスに次のような行が表示されます。
"rows": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ]projects.instances.databases.dropDatabaseをクリックします。[name] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance/databases/example-db[実行] をクリックします。
projects.instances.deleteをクリックします。[name] に以下のように入力します。
projects/[PROJECT_ID]/instances/test-instance[実行] をクリックします。
REST 呼び出しの作成方法
Spanner REST 呼び出しは、以下の方法で作成できます。
このページで使用されている規則
インスタンス
Spanner を最初に使用する際は、インスタンスを作成する必要があります。インスタンスとは、Spanner データベースによって使用されるリソースの割り当てのことです。インスタンスの作成時には、データの保存場所とインスタンスの持つコンピューティング容量を選択します。
インスタンス設定を一覧表示する
インスタンスの作成時には「インスタンス構成」を指定し、そのインスタンスのデータベースの地理的位置とレプリケーションを定義します。1 つのリージョンにデータを格納するリージョン構成、または複数のリージョンにデータを分散するマルチ リージョン構成を選択できます。詳しくは、インスタンスをご覧ください。
projects.instanceConfigs.list を使用して、自分の Google Cloud プロジェクトで使用できる構成を特定します。
インスタンスの作成時にインスタンス構成のいずれかに name 値を使用します。
インスタンスを作成する
インスタンスを一覧表示するには、projects.instances.list を使用します。
データベースの作成
example-db という名前のデータベースを作成します。
データベースを一覧表示するには、projects.instances.databases.list を使用します。
スキーマを作成する
Spanner の データ定義言語(DDL)はテーブルの作成、変更、削除、またはインデックスの作成や削除に使用されます。
スキーマでは、基本的な音楽アプリケーション用の 2 つのテーブル Singers と Albums が定義されています。これらのテーブルはこのページ全体で使用されています。まだスキーマ例を見ていない場合は確認してください。
スキーマを取得するには、projects.instances.databases.getDdl を使用します。
セッションを作成する
データの追加、更新、削除、クエリを行うには、その前にセッションを作成する必要があります。セッションは Spanner データベース サービスとの通信チャネルを表します。(Spanner クライアント ライブラリを使用している場合は直接セッションを使用せず、このクライアント ライブラリが代わりにセッションを管理します。)
セッションは長時間の使用を前提としています。Spanner データベース サービスでは、アイドル状態が 1 時間を超えたセッションを削除できます。削除済みのセッションの使用を試みると NOT_FOUND が発生します。このエラーが発生した場合は、新しいセッションを作成して使用します。セッションがまだ維持されているかどうかを確認するには、projects.instances.databases.sessions.get を使用します。関連情報については、アイドル セッションを維持するをご覧ください。
次のステップでは、データベースにデータを書き込みます。
データを書き込む
データを書き込むには、Mutation タイプを使用します。Mutation はミューテーション オペレーションのコンテナです。Mutation は、Spanner データベース内のさまざまな行やテーブルに対してアトミックに適用される一連の操作(挿入、更新、削除など)を表します。
この例では insertOrUpdate を使用しています。Mutations のその他のオペレーションには、insert、update、replace、delete があります。
データ型をエンコードする方法については、TypeCode をご覧ください。
SQL を使用してデータをクエリする
読み取り API を使用してデータを読み取る
データベース スキーマの更新
MarketingBudget という列を新たに Albums テーブルに追加する必要があるとします。そのためには、データベース スキーマの更新が必要です。Spanner では、データベースでのトラフィックの処理中にデータベースのスキーマを更新できます。スキーマのアップデートは、データベースをオフラインにする必要はなく、表全体や列もロックされないため、スキーマのアップデート中にデータベースへのデータの書き込みを続けることができます。
列を追加する
新しい列へのデータの書き込み
次のコードは、新しい列にデータを書き込みます。MarketingBudget の値を、キーが Albums(1, 1) の行は 100000 に、キーが Albums(2, 2) の行は 500000 に設定します。
SQL クエリまたは読み取り呼び出しを実行して、書き込んだばかりの値を取得することもできます。
クエリを実行する方法を次に示します。
セカンダリ インデックスを使用する
Albums から AlbumTitle の値が特定の範囲内にある行すべてを取得すると仮定します。SQL ステートメントまたは読み取り呼び出しを使用して AlbumTitle 列からすべての値を読み取り、基準を満たしていない行を破棄することもできますが、このようなテーブル全体のスキャンは割高です(特に、行数が多いテーブルの場合)。代わりに、テーブルにセカンダリ インデックスを作成することにより、主キー以外の列を検索するときの行の取得速度を上げることができます。
既存のテーブルにセカンダリ インデックスを追加するには、スキーマの更新が必要です。他のスキーマの更新と同様に、Spanner ではデータベースがトラフィックを提供している間にインデックスを追加できます。Spanner では、インデックスに既存のデータが自動的にバックフィルされます。バックフィルには数分かかることがありますが、このプロセスの間に、データベースをオフラインにしたり、特定のテーブルや列への書き込みを控えたりする必要はありません。詳細については、インデックスのバックフィリングをご覧ください。
セカンダリ インデックスを追加すると、インデックスの効果により実行速度が上がりそうな SQL クエリに対してそのセカンダリ インデックスが自動的に使用されるようになります。読み取りインターフェースを使用する場合は、使用するインデックスを指定する必要があります。
セカンダリ インデックスの追加
インデックスを追加するには、updateDdl を使用します。
インデックスを使用したクエリ
インデックスを使用して読み取る
STORING 句を使用したインデックスの追加
上記の読み取り例では、MarketingBudget 列の読み取りが含まれていませんでした。これは、Spanner の読み取りインターフェースが、インデックスとデータテーブルを結合してインデックスに格納されていない値を検索する機能をサポートしていないためです。
MarketingBudget のコピーをインデックスに格納する AlbumsByAlbumTitle の代替定義を作成します。
STORING インデックスを追加するには、updateDdl を使用します。
これで、インデックス AlbumsByAlbumTitle2 から AlbumId、AlbumTitle、MarketingBudget 列をすべて取得する読み取りを実行できるようになりました。
読み取り専用トランザクションを使用したデータを取得する
同じタイムスタンプで複数の読み取りを実行する場合について考えます。読み取り専用トランザクションはトランザクションの commit 履歴の一貫性のあるプレフィックスを監視しているので、アプリケーションは常に一貫性のあるデータを取得できます。
読み取り専用トランザクションを作成する
この読み取り専用トランザクションを使用して、一貫したタイムスタンプでデータを取得できます。これは、この読み取り専用トランザクションの作成後にデータが変更されている場合でも同様です。
読み取り専用トランザクションを使用してクエリを実行する
読み取り専用トランザクションを使用して読み取る
Spanner は読み取り / 書き込みトランザクションもサポートしています。このトランザクションでは、ある論理的な時点で一連の読み取りと書き込みをアトミックに実行します。詳細については、読み取り / 書き込みトランザクションをご覧ください。(試してみましょう機能は読み取り / 書き込みトランザクションのデモンストレーションには適切ではありません。)
クリーンアップ
このチュートリアルで使用したリソースについて Google Cloud アカウントに課金されないようにするには、作成したデータベースとインスタンスを削除します。