Spanner Data Boost는 지원되는 Spanner 워크로드에 독립적인 컴퓨팅 리소스를 제공하는 완전 관리형 서버리스 서비스입니다. Data Boost를 사용하면 프로비저닝된 Spanner 인스턴스의 기존 워크로드에 거의 영향을 주지 않고 분석 쿼리 및 데이터 내보내기를 실행할 수 있습니다. 이 서비스는 Google에서 리전 수준에서 관리하는 Spanner 클러스터로 구성됩니다. 적격한 쿼리로 Data Boost를 요청하는 경우 Spanner가 워크로드를 이러한 서버로 투명하게 라우팅합니다. 적격한 쿼리는 쿼리 실행 계획의 첫 번째 연산자가 분산 통합인 쿼리입니다. 이러한 쿼리는 Data Boost를 활용하기 위해 변경할 필요가 없습니다.
Data Boost는 리소스 경합으로 인해 기존 트랜잭션 시스템에 부정적인 영향을 주지 않도록 하려는 경우에 가장 효과적입니다.
- 대량의 데이터 처리를 포함하는 임시 또는 간헐적인 쿼리. BigQuery에서 Spanner로의 통합 쿼리가 그 예에 해당합니다.
- 보고 또는 데이터 내보내기 작업. Spanner 데이터를 Cloud Storage로 내보내는 Dataflow 작업이 그 예에 해당합니다.
다음 다이어그램에서는 Data Boost가 Spanner 인스턴스와 조율하여 독립적인 컴퓨팅 리소스를 제공하는 방법을 보여줍니다.
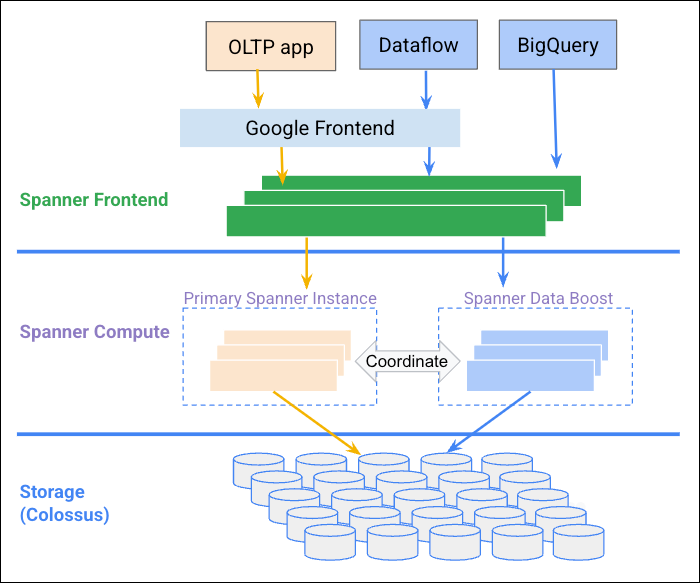
이점
Data Boost는 다음과 같은 이점을 제공합니다.
- 워크로드 격리를 제공합니다. 쿼리 복잡성 또는 처리되는 데이터 양과 관계없이 기존 트랜잭션 워크로드에 거의 영향을 주지 않고 최신 데이터에 대해 지원되는 쿼리를 실행할 수 있습니다.
- 같거나 더 짧은 지연 시간을 제공합니다.
- 가끔 필요한 분석 쿼리를 지원하기 위해 Spanner 인스턴스를 초과 프로비저닝하는 것을 막아줍니다.
- 버스트 부하로 탄력적으로 확장되는 뛰어난 쿼리 동시 로드로 높은 수준의 확장성을 제공합니다.
- 포괄적인 측정항목을 제공하여 관리자가 가장 비용이 많이 드는 쿼리를 식별하고 최적화할 비용 구성요소를 결정할 수 있습니다. 이후 관리자는 다음 실행에서 쿼리의 서버리스 처리 단위 소비를 모니터링하여 최적화의 효과를 확인할 수 있습니다.
- 추가 운영 오버헤드가 필요하지 않습니다. 관리할 추가 서비스가 없으며 용량 계획이나 프로비저닝이 필요하지 않고 확장을 기다릴 필요가 없으며 유지보수도 필요하지 않습니다.
권한
Data Boost를 요청하는 쿼리 또는 내보내기를 실행하는 모든 주 구성원은 spanner.databases.useDataBoost Identity and Access Management(IAM) 권한이 있어야 합니다. Cloud Spanner Database Reader With DataBoost(roles/spanner.databaseReaderWithDataBoost) IAM 역할을 사용하는 것이 좋습니다.
결제 및 할당량
Data Boost에서 실행되는 쿼리에 사용되는 실제 처리 단위에 대해서만 비용을 지불합니다. 관리자는 비용 초과를 방지하기 위해 사용량 한도를 설정할 수 있습니다.
다음 단계
- Data Boost로 통합 쿼리 실행
- Data Boost로 데이터 내보내기
- 애플리케이션에서 Data Boost 사용
- Data Boost 사용량 모니터링
- Data Boost 할당량 사용량 모니터링 및 관리