Cette page décrit la capacité de calcul de Spanner et les deux unités de mesure utilisées pour la quantifier : les nœuds et les unités de traitement.
Capacité de calcul
Lorsque vous créez une instance, vous choisissez une configuration d'instance et une quantité de capacité de calcul pour votre instance. La capacité de calcul de votre instance présente les caractéristiques suivantes :
- Il détermine la quantité de ressources de serveur et de stockage disponibles pour les bases de données de votre instance, y compris la charge du disque. La charge de disque ne s'applique qu'aux charges de travail qui accèdent aux données stockées sur un disque dur. Pour en savoir plus, consultez Présentation du stockage par niveaux.
Elle est mesurée en unités de traitement ou en nœuds, 1 000 unités de traitement étant égales à 1 nœud.
- Un nœud ou 1 000 unités de traitement constituent une unité logique de capacité de calcul et ne représentent pas un seul serveur physique. Les ressources de calcul de chaque nœud sont réparties sur plusieurs machines physiques sous-jacentes, ou serveurs. Le nombre de serveurs par nœud dépend de la configuration de votre instance. Par exemple, une instance régionale utilise au moins trois serveurs par nœud, tandis qu'une instance multirégionale en utilise au moins cinq. Pour en savoir plus, consultez Capacité de calcul et configurations d'instance.
- Lorsque vous définissez ou modifiez la capacité de calcul d'une instance, vous devez spécifier des unités de traitement par multiples de 100 (par exemple, 100, 200, 300). Lorsque le nombre d'UP atteint 1 000, vous pouvez spécifier des quantités plus importantes sous forme de multiples de 1 000 UP (par exemple, 1 000, 2 000, 3 000) ou de nœuds (par exemple, 1, 2, 3).
Spanner met à disposition la capacité de calcul spécifiée (répliquée) dans son intégralité dans chaque zone qui héberge une réplique de vos données. Par exemple, si vous provisionnez 1 000 UP pour une instance régionale, qui comporte généralement des répliques dans trois zones, chacune de ces trois zones dispose de la totalité des 1 000 UP de puissance de calcul pour desservir sa réplique. Spanner ne divise ni ne répartit les UTP totales entre les zones. L'unité de mesure que vous utilisez n'a pas d'importance, sauf si vous créez une instance dont la capacité de calcul est inférieure à 1 000 unités de traitement (1 nœud). Dans ce cas, vous devez utiliser les unités de traitement pour spécifier la capacité de calcul de l'instance.
Les instances comptant moins de 1 000 unités de traitement sont conçues pour les plus petits volumes de données, requêtes et charges de travail. Elles disposent de ressources de calcul limitées, ce qui peut entraîner un scaling non linéaire et des problèmes de performances pour certaines charges de travail. Ces instances peuvent également connaître des augmentations intermittentes de la latence.
Disponibilité de Spanner
Spanner est conçu pour la haute disponibilité. Comme la capacité de calcul de chaque instance est répartie sur plusieurs serveurs dans différentes zones, Spanner est résilient en cas de défaillance d'un serveur. La perte d'un serveur individuel ne constitue pas une défaillance de nœud. Spanner gère automatiquement ses ressources sous-jacentes pour assurer la disponibilité continue de votre instance.
Limites de stockage des données
Comme indiqué dans la section Quotas et limites, Spanner utilise la capacité de calcul d'une instance comme base pour déterminer les limites de stockage afin de fournir une haute disponibilité et une faible latence lors de l'accès à une base de données, en suivant les consignes suivantes :
- Pour les instances inférieures à un nœud (1 000 unités de traitement), Spanner alloue 1 024 Gio de données pour 100 unités de traitement de la base de données.
- Pour les instances de 1 nœud et plus, Spanner alloue 10 Tio de données pour chaque nœud.
Par exemple, pour créer une instance d'une base de données de 300 Go, vous pouvez définir sa capacité de calcul sur 100 UP. Cette capacité de calcul maintient l'instance en deçà de la limite jusqu'à ce que la base de données atteigne plus de 1 024 Gio. Au-delà de cette taille, il faut ajouter 100 unités de traitement supplémentaires afin de permettre à la base de données de croître. Sinon, Spanner risque de refuser les écritures dans la base de données. Pour en savoir plus, consultez Recommandations pour l'utilisation du stockage de bases de données.
Spanner facture le stockage réellement utilisé par les instances, et non leur quota de stockage total.
Performances
Les valeurs maximales de débit en lecture et en écriture qu'une quantité donnée de capacité de calcul peut fournir dépendent de la configuration de l'instance, de la conception du schéma et des caractéristiques de l'ensemble de données. Pour en savoir plus, consultez la présentation des performances.
Vous utilisez des instances avec moins de 1 000 UP pour les plus petits volumes de données, requêtes et charges de travail. Pour les charges de travail plus importantes, leurs ressources de calcul limitées peuvent entraîner une mise à l'échelle et des performances non linéaires, avec des augmentations intermittentes de la latence.
Capacité de calcul et configurations d'instances
Comme décrit dans Configurations régionales, birégionales et multirégionales, Spanner distribue une instance sur plusieurs zones d'une ou de plusieurs régions afin de fournir des performances élevées et une haute disponibilité. Par conséquent, Spanner distribue également les ressources de serveur fournies par la capacité de calcul de l'instance.
Voici un diagramme illustrant cette répartition des ressources de serveur :
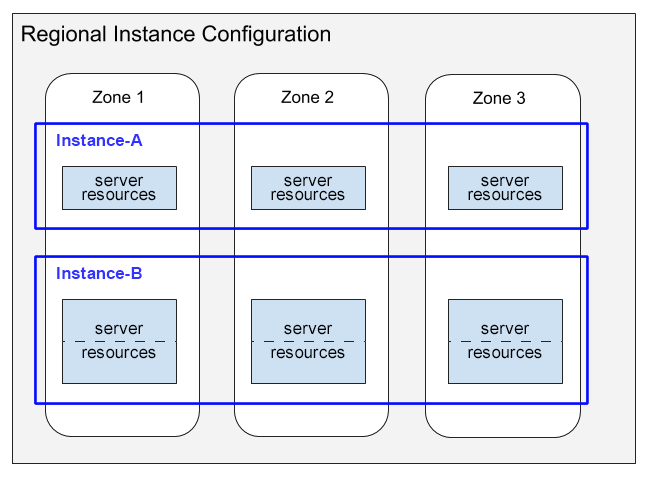
Ce diagramme illustre deux instances avec des configurations régionales :
- Instance-A est une instance de 1 000 UP (1 nœud) dont la capacité de calcul distribuée consomme des ressources serveur dans chacune des trois zones.
- Instance-B est une instance de 2000 UT (2 nœuds) dont la capacité de calcul distribuée consomme des ressources serveur dans chacune des trois zones.
Notez les points suivants dans ce schéma :
Pour chaque instance, Spanner alloue des ressources serveur dans chaque zone de la configuration régionale. Chaque ressource de serveur zonale utilise les données de l'instance dupliquée de sa zone. Pour en savoir plus sur les instances dupliquées dans les configurations d'instance, consultez Configurations régionales, birégionales et multirégionales. Pour savoir comment Spanner synchronise ces instances dupliquées des données, consultez la page Réplication.
Les ressources de serveur pour Instance-A sont affichées dans des cadres simples, tandis que les ressources pour Instance-B sont affichées dans des cadres subdivisés en deux parties. Cette différence illustre le fait que Spanner alloue les ressources de serveur différemment pour les instances de taille différente :
- Pour les instances de 1 000 UP (1 nœud) et moins, Spanner alloue les ressources de serveur dans une seule tâche de serveur par zone.
- Pour les instances de plus de 1 000 UP (1 nœud), Spanner alloue les ressources de serveur dans plusieurs tâches de serveur par zone, avec une tâche pour 1 000 UP. L'utilisation de plusieurs tâches de serveur par zone offre de meilleures performances et permet à Spanner de créer des partitions de base de données ainsi que d'optimiser les performances.
Modifier la capacité de calcul
Après avoir créé une instance, vous pouvez augmenter sa capacité de calcul ultérieurement. Dans la plupart des cas, les demandes sont traitées en quelques minutes. Dans de rares cas, une mise à l'échelle peut prendre jusqu'à une heure.
Vous pouvez réduire la capacité de calcul d'une instance Spanner, sauf dans les cas suivants :
Vous ne pouvez pas stocker plus de 10 Tio de données par nœud (1 000 unités de traitement).
Les données de votre instance sont réparties en un grand nombre de splits. Dans ce scénario, il est possible que Spanner ne soit plus en mesure de gérer les divisions après la réduction de la capacité de calcul. Vous pouvez essayer de réduire la capacité de calcul progressivement par petites quantités jusqu'à ce que vous trouviez la capacité minimale dont Spanner a besoin pour gérer toutes les divisions de l'instance.
Spanner peut créer un grand nombre de divisions pour s'adapter à vos schémas d'utilisation. Si vos schémas d'utilisation changent, Spanner peut fusionner certaines divisions au bout d'une ou deux semaines. Vous pouvez alors essayer de réduire la capacité de calcul de l'instance.
Lorsque vous supprimez de la capacité de calcul, surveillez l'utilisation du processeur et les latences des requêtes dans Cloud Monitoring pour vous assurer que l'utilisation du processeur reste inférieure à 65 % pour les instances régionales et à 45 % pour chaque région des instances multirégionales. Il est possible que la latence des requêtes augmente temporairement lors de la suppression de la capacité de calcul.
Spanner ne propose pas de mode "Suspendre". La capacité de calcul de Spanner est une ressource dédiée. Même lorsque vous n'exécutez pas de charge de travail, Spanner effectue des tâches en arrière-plan de manière fréquente afin d'optimiser et de protéger vos données.
Vous pouvez utiliser la consoleGoogle Cloud , Google Cloud CLI ou les bibliothèques clientes Spanner pour modifier la capacité de calcul. Pour en savoir plus, consultez Modifier la capacité de calcul.
Capacité de calcul et instances dupliquées
Si vous devez faire évoluer les ressources de serveur et de stockage de votre instance, augmentez la capacité de calcul de l'instance. Notez que l'augmentation de la capacité de calcul n'augmente pas le nombre d'instances dupliquées (fixe pour une configuration d'instance donnée), mais accroît les ressources de chaque instance dupliquée au sein de l'instance. L'augmentation de la capacité de calcul permet d'augmenter la capacité de processeur et de mémoire RAM de chaque instance dupliquée, ce qui augmente le débit de l'instance dupliquée. En d'autres termes, cela permet plus d'opérations de lecture et d'écriture par seconde.
Étapes suivantes
- Découvrez comment créer et gérer des instances.