Este artigo explica como migrar a sua base de dados dos sistemas de processamento de transações online (OLTP) da Oracle® para o Spanner.
O Spanner usa determinados conceitos de forma diferente de outras ferramentas de gestão de bases de dados empresariais, pelo que pode ter de ajustar a sua aplicação para tirar total partido das respetivas capacidades. Também pode ter de complementar o Spanner com outros serviços da Google Cloud para satisfazer as suas necessidades.
Restrições de migração
Quando migra a sua aplicação para o Spanner, tem de ter em conta as diferentes funcionalidades disponíveis. Provavelmente, tem de reformular a arquitetura da sua aplicação para se adequar ao conjunto de funcionalidades do Spanner e integrar-se com Google Cloud serviços adicionais.
Procedimentos armazenados e acionadores
O Spanner não suporta a execução de código do utilizador ao nível da base de dados. Como tal, no âmbito da migração, tem de mover a lógica empresarial implementada por procedimentos e acionadores armazenados ao nível da base de dados para a aplicação.
Sequências
Recomendamos que use a versão 4 do UUID como o método predefinido para gerar valores de chave primária.
A função GENERATE_UUID() (GoogleSQL,
PostgreSQL)
devolve valores da versão 4 do UUID como um tipo STRING.
Se precisar de gerar valores inteiros de 64 bits, o Spanner suporta sequências invertidas de bits positivas (GoogleSQL, PostgreSQL), que produzem valores que se distribuem uniformemente pelo espaço de números positivos de 64 bits. Pode usar estes números para evitar problemas de uso excessivo de recursos de chaves.
Para mais informações, consulte as estratégias de valor predefinido da chave principal.
Controlos de acesso
A Identity and Access Management (IAM) permite-lhe controlar o acesso de utilizadores e grupos aos recursos do Spanner ao nível do projeto, da instância do Spanner e da base de dados do Spanner. Para mais informações, consulte a vista geral do IAM.
Reveja e implemente políticas de IAM seguindo o princípio do menor privilégio para todos os utilizadores e contas de serviço que acedem à sua base de dados. Se a aplicação exigir acesso restrito a tabelas, colunas, vistas ou streams de alterações específicas, implemente o controlo de acesso detalhado (FGAC). Para mais informações, consulte a vista geral do controlo de acesso detalhado.
Restrições de validação de dados
O Spanner pode suportar um conjunto limitado de restrições de validação de dados na camada da base de dados.
Se precisar de restrições de dados mais complexas, implemente-as na camada de aplicação.
A tabela seguinte aborda os tipos de restrições comuns nas bases de dados Oracle® e como implementá-las com o Spanner.
| Restrição | Implementação com o Spanner |
|---|---|
| Não nulo | NOT NULLrestrição de coluna |
| únicas | Índice secundário com restrição UNIQUE |
| Chave externa (para tabelas normais) | Consulte o artigo Crie e faça a gestão de relações de chaves externas. |
Ações de chave externa ON DELETE/ON UPDATE |
Só é possível para tabelas intercaladas. Caso contrário, é implementado na camada de aplicação |
Verificações e validação de valores através de CHECK restrições ou acionadores
|
Implementado na camada de aplicação |
Tipos de dados suportados
As bases de dados Oracle® e o Spanner suportam diferentes conjuntos de tipos de dados. A tabela seguinte apresenta os tipos de dados da Oracle e o respetivo equivalente no Spanner. Para ver definições detalhadas de cada tipo de dados do Spanner, consulte o artigo Tipos de dados.
Também pode ter de fazer transformações adicionais nos seus dados, conforme descrito na coluna Notas, para que os dados do Oracle se ajustem à sua base de dados do Spanner.
Por exemplo, pode armazenar um grande BLOB como um objeto num contentor do Cloud Storage, em vez de na base de dados, e, em seguida, armazenar a referência do URI ao objeto do Cloud Storage na base de dados como um STRING.
| Tipo de dados Oracle | Equivalente do Spanner | Notas |
|---|---|---|
Tipos de carateres (CHAR, VARCHAR, NCHAR,
NVARCHAR)
|
STRING
|
Nota: o Spanner usa strings Unicode em todo o lado. O Oracle suporta um comprimento máximo de 32 000 bytes ou carateres (consoante o tipo), enquanto o Spanner suporta até 2 621 440 carateres. |
BLOB, LONG RAW, BFILE
|
BYTES ou STRING que contém o URI para o objeto.
|
Os objetos pequenos (inferiores a 10 MiB) podem ser armazenados como BYTES.Pondere usar ofertas Google Cloud alternativas, como o Cloud Storage, para armazenar objetos maiores. |
CLOB, NCLOB, LONG
|
STRING (contendo dados ou URI para objeto externo)
|
Os objetos pequenos (com menos de 2 621 440 carateres) podem ser armazenados como STRING. Considere usar ofertas Google Cloud alternativas, como o
Cloud Storage, para armazenar objetos maiores.
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
O tipo de dados NUMBER do Oracle é equivalente ao tipo de dados NUMERIC do GoogleSQL. Cada um suporta 38 dígitos de precisão e nove dígitos de escala: (P,S) = (38,9). O tipo de dados PostgreSQL
NUMERIC armazena
dados numéricos de precisão arbitrária.
O tipo de dados FLOAT64GoogleSQL suporta até 16 dígitos
de precisão. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT, BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
A representação STRING predefinida do tipo Spanner
DATE é yyyy-mm-dd, que é diferente da de
Oracle, por isso, tenha cuidado ao converter automaticamente para e a partir de
representações STRING de datas. As funções SQL são fornecidas para converter datas numa string formatada.
|
DATETIME
|
TIMESTAMP
|
O Spanner armazena a hora independentemente do fuso horário. Se precisar de
armazenar um fuso horário, tem de usar uma coluna STRING separada.
São fornecidas funções SQL para converter indicações de tempo numa string formatada através de fusos horários.
|
XML
|
STRING (contendo dados ou URI para objeto externo)
|
Os pequenos objetos XML (com menos de 2 621 440 carateres) podem ser armazenados como STRING. Pondere usar Google Cloud ofertas alternativas, como o Cloud Storage, para armazenar objetos maiores. |
URI, DBURI, XDBURI,
HTTPURI
|
STRING
|
|
ROWID
|
PRIMARY KEY
|
O Spanner usa a chave primária da tabela para ordenar e referenciar linhas internamente, pelo que, no Spanner, é efetivamente o mesmo que o tipo de dados ROWID. |
SDO_GEOMETRY, SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
O Spanner não suporta tipos de dados geoespaciais. Tem de armazenar estes dados usando tipos de dados padrão e implementar qualquer lógica de pesquisa e filtragem na camada de aplicação. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature
|
O Spanner não suporta tipos de dados de multimédia. Considere usar o Cloud Storage para armazenar dados multimédia. |
Processo de migração
Uma linha cronológica geral do processo de migração seria:
- Converta o esquema e o modelo de dados.
- Traduzir quaisquer consultas SQL.
- Migre a sua aplicação para usar o Spanner além do Oracle.
- Exporte em massa os seus dados do Oracle e importe-os para o Spanner através do Dataflow.
- Mantenha a consistência entre ambas as bases de dados durante a migração.
- Migre a sua aplicação da Oracle.
Passo 1: converta a base de dados e o esquema
Converte o seu esquema existente num esquema do Spanner para armazenar os seus dados. Isto deve corresponder o mais possível ao esquema do Oracle existente para simplificar as modificações da aplicação. No entanto, devido às diferenças nas funcionalidades, são necessárias algumas alterações.
A utilização de práticas recomendadas no design de esquemas pode ajudar a aumentar a taxa de transferência e reduzir os pontos críticos na sua base de dados do Spanner.
Chaves principais
No Spanner, todas as tabelas que têm de armazenar mais de uma linha têm de ter uma chave principal composta por uma ou mais colunas da tabela. A chave principal da tabela identifica exclusivamente cada linha numa tabela, e as linhas da tabela são ordenadas pela chave principal. Uma vez que o Spanner é altamente distribuído, é importante que escolha uma técnica de geração de chaves primárias que seja bem dimensionada com o crescimento dos seus dados. Para mais informações, consulte as estratégias de migração de chaves primárias recomendadas.
Tenha em atenção que, depois de designar a chave principal, não pode adicionar nem remover uma coluna de chave principal, nem alterar um valor de chave principal posteriormente sem eliminar e recriar a tabela. Para mais informações sobre como designar a chave principal, consulte o artigo Esquema e modelo de dados – chaves principais.
Intercale as suas tabelas
O Spanner tem uma funcionalidade que lhe permite definir duas tabelas como tendo uma relação um-para-muitos, principal-secundário. Isto intercala as linhas de dados da criança com a respetiva linha principal no armazenamento, juntando efetivamente a tabela e melhorando a eficiência da obtenção de dados quando a principal e as crianças são consultadas em conjunto.
A chave primária da tabela secundária tem de começar com as colunas da chave primária da tabela principal. Do ponto de vista da linha secundária, a chave principal da linha principal é denominada chave externa. Pode definir até 6 níveis de relações principal-secundário.
Pode definir ações de eliminação para tabelas secundárias para determinar o que acontece quando a linha principal é eliminada: todas as linhas secundárias são eliminadas ou a eliminação da linha principal é bloqueada enquanto existirem linhas secundárias.
Segue-se um exemplo de criação de uma tabela Albums intercalada na tabela Singers principal definida anteriormente:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Crie índices secundários
Também pode criar índices secundários para indexar dados na tabela fora da chave primária.
O Spanner implementa índices secundários da mesma forma que as tabelas, pelo que os valores das colunas a usar como chaves de índice têm as mesmas restrições que as chaves primárias das tabelas. Isto também significa que os índices têm as mesmas garantias de consistência que as tabelas do Spanner.
As pesquisas de valores que usam índices secundários são efetivamente iguais a uma consulta com uma junção de tabelas. Pode melhorar o desempenho das consultas que usam índices armazenando cópias dos valores das colunas da tabela original no índice secundário através da cláusula STORING, tornando-o um índice de cobertura.
O otimizador de consultas do Spanner só usa automaticamente índices secundários quando o próprio índice armazena todas as colunas consultadas (uma consulta coberta). Para forçar a utilização de um índice ao consultar colunas na tabela original, tem de usar uma diretiva FORCE INDEX na declaração SQL, por exemplo:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
Os índices podem ser usados para aplicar valores únicos numa coluna de tabela, definindo
um
UNIQUE índice
nessa coluna. A adição de valores duplicados é impedida pelo índice.
Segue-se um exemplo de uma declaração DDL que cria um índice secundário para a tabela Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Tenha em atenção que, se criar índices adicionais depois de os dados serem carregados, o preenchimento do índice pode demorar algum tempo. Deve limitar a taxa à qual os adiciona a uma média de três por dia. Para mais orientações sobre a criação de índices secundários, consulte Índices secundários. Para mais informações sobre as limitações na criação de índices, consulte as atualizações de esquemas.
Passo 2: traduza quaisquer consultas SQL
O Spanner usa o dialeto ANSI 2011 de SQL com extensões e tem muitas funções e operadores para ajudar a traduzir e agregar os seus dados. Tem de converter todas as consultas SQL que usam sintaxe, funções e tipos específicos do Oracle para serem compatíveis com o Spanner.
Embora o Spanner não suporte dados estruturados como definições de colunas, os dados estruturados podem ser usados em consultas SQL com os tipos ARRAY e STRUCT.
Por exemplo, pode escrever uma consulta para devolver todos os álbuns de um artista usando um ARRAY de STRUCTs numa única consulta (tirando partido dos dados pré-associados).
Para mais informações, consulte a secção Notas sobre subconsultas da documentação.
É possível criar perfis de consultas SQL através da página do Spanner Studio na consola para executar a consulta. Google Cloud Em geral, as consultas que fazem análises completas de tabelas grandes são muito dispendiosas e devem ser usadas com moderação.
Consulte a documentação de práticas recomendadas de SQL para obter mais informações sobre a otimização de consultas SQL.
Passo 3: migre a sua aplicação para usar o Spanner
O Spanner oferece um conjunto de bibliotecas cliente para vários idiomas e a capacidade de ler e escrever dados através de chamadas API específicas do Spanner, bem como através de consultas SQL e declarações de linguagem de modificação de dados (LMD). A utilização de chamadas API pode ser mais rápida para algumas consultas, como leituras diretas de linhas por chave, porque a declaração SQL não tem de ser traduzida.
Também pode usar o controlador Java Database Connectivity (JDBC) para se ligar ao Spanner, tirando partido das ferramentas e da infraestrutura existentes que não têm integração nativa.
Como parte do processo de migração, as funcionalidades não disponíveis no Spanner têm de ser implementadas na aplicação. Por exemplo, um acionador para validar valores de dados e atualizar uma tabela relacionada teria de ser implementado na aplicação através de uma transação de leitura/escrita para ler a linha existente, validar a restrição e, em seguida, escrever as linhas atualizadas em ambas as tabelas.
O Spanner oferece transações de leitura/escrita e só de leitura, que garantem a consistência externa dos seus dados. Além disso, as transações de leitura podem ter limites de data/hora aplicados, em que está a ler uma versão consistente dos dados especificados das seguintes formas:
- Numa hora exata no passado (até 1 hora atrás).
- No futuro (em que a leitura é bloqueada até essa altura).
- Com uma quantidade aceitável de desatualização limitada, que devolve uma vista consistente até um determinado momento no passado sem ter de verificar se os dados posteriores estão disponíveis noutra réplica. Isto pode oferecer vantagens em termos de desempenho, mas pode ter dados desatualizados.
Passo 4: transfira os seus dados do Oracle para o Spanner
Para transferir os seus dados do Oracle para o Spanner, tem de exportar a sua base de dados Oracle para um formato de ficheiro portátil, por exemplo, CSV, e, em seguida, importar esses dados para o Spanner através do Dataflow.
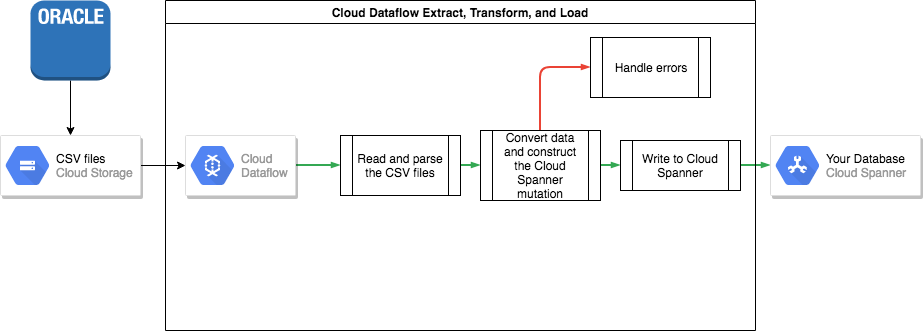
Exportação em massa da Oracle
A Oracle não fornece utilitários incorporados para exportar ou descarregar toda a sua base de dados para um formato de ficheiro portátil.
Algumas opções para fazer uma exportação estão listadas nas Perguntas frequentes da Oracle.
Por exemplo:
- Usar o SQL*plus ou o SQLcl para enviar uma consulta para um ficheiro de texto.
- Escrever uma função PL/SQL com UTL_FILE para descarregar uma tabela em paralelo para ficheiros de texto.
- Usando funcionalidades no Oracle APEX ou no Oracle SQL Developer para descarregar uma tabela para um ficheiro CSV ou XML.
Cada uma destas opções tem a desvantagem de só poder ser exportada uma tabela de cada vez, o que significa que tem de pausar a aplicação ou desativar a base de dados para que esta permaneça num estado consistente para exportação.
Outras opções incluem ferramentas de terceiros, conforme indicado na página de Perguntas frequentes da Oracle, algumas das quais podem descarregar uma vista consistente de toda a base de dados.
Depois de descarregados, deve carregar estes ficheiros de dados para um contentor do Cloud Storage para que sejam acessíveis para importação.
Importação em massa para o Spanner
Uma vez que os esquemas da base de dados provavelmente diferem entre o Oracle e o Spanner, pode ter de fazer algumas conversões de dados como parte do processo de importação.
A forma mais fácil de realizar estas conversões de dados e importar os dados para o Spanner é através do Dataflow.
O Dataflow é o serviço de Google Cloud extração, transformação e carregamento (ETL) distribuído. Oferece uma plataforma para executar pipelines de dados escritos com o SDK do Apache Beam, de modo a ler e processar grandes quantidades de dados em paralelo em várias máquinas.
O SDK Apache Beam requer que escreva um programa Java simples para definir a leitura, a transformação e a escrita dos dados. Existem conetores do Beam para o Cloud Storage e o Spanner, pelo que o único código que tem de ser escrito é a própria transformação de dados.
Veja um exemplo de um pipeline simples que lê a partir de ficheiros CSV e escreve no Spanner no repositório de código de exemplo que acompanha este artigo.
Se forem usadas tabelas intercaladas principal-secundário no seu esquema do Spanner, tem de ter cuidado no processo de importação para que a linha principal seja criada antes da linha secundária. O código do pipeline de importação do Spanner processa esta situação importando primeiro todos os dados das tabelas ao nível da raiz, depois todas as tabelas secundárias de nível 1, depois todas as tabelas secundárias de nível 2 e assim sucessivamente.
Pode usar o pipeline de importação do Spanner diretamente para importar os seus dados em massa,mas isto requer que os dados existam em ficheiros Avro com o esquema correto.
Passo 5: mantenha a consistência entre ambas as bases de dados
Muitas aplicações têm requisitos de disponibilidade que tornam impossível manter a aplicação offline durante o tempo necessário para exportar e importar os seus dados. Enquanto transfere os seus dados para o Spanner, a sua aplicação continua a modificar a base de dados existente. Tem de duplicar as atualizações na base de dados do Spanner enquanto a aplicação está em execução.
Existem vários métodos para manter as duas bases de dados sincronizadas, incluindo a captura de dados de alterações e a implementação de atualizações simultâneas na aplicação.
Captura de alterações de dados
O Oracle GoldenGate pode fornecer um fluxo de captura de dados de alterações (CDC) para a sua base de dados Oracle. O Oracle LogMiner ou o Oracle XStream Out são interfaces alternativas para a base de dados do Oracle para obter um fluxo de CDC que não envolve o Oracle GoldenGate.
Pode escrever uma aplicação que subscreva um destes streams e que aplique as mesmas modificações (depois da conversão de dados, naturalmente) à sua base de dados do Spanner. Uma aplicação de processamento de streams tem de implementar várias funcionalidades:
- Estabelecer ligação à base de dados Oracle (base de dados de origem).
- A estabelecer ligação ao Spanner (base de dados de destino).
- Realizar repetidamente o seguinte:
- Receber os dados produzidos por uma das streams de CDC da base de dados Oracle.
- Interpretar os dados produzidos pela stream de CDC.
- Converter os dados em declarações
INSERTdo Spanner. - Executar as declarações do Spanner
INSERT.
A tecnologia de migração de bases de dados é uma tecnologia de middleware que implementou as funcionalidades necessárias como parte da sua funcionalidade. A plataforma de migração de bases de dados é instalada como um componente separado na localização de origem ou na localização de destino, de acordo com os requisitos do cliente. A plataforma de migração de bases de dados só requer a configuração da conetividade das bases de dados envolvidas para especificar e iniciar a transferência de dados contínua da base de dados de origem para a base de dados de destino.
A Striim é uma plataforma de tecnologia de migração de bases de dados disponível no Google Cloud. Oferece conetividade a streams de CDC do Oracle GoldenGate, bem como do Oracle LogMiner e do Oracle XStream Out. O Striim fornece uma ferramenta gráfica que lhe permite configurar a conetividade da base de dados e quaisquer regras de transformação necessárias para transferir dados do Oracle para o Spanner.
Pode instalar o Striim a partir do Google Cloud Marketplace, estabelecer ligação às bases de dados de origem e de destino, implementar regras de transformação e começar a transferir dados sem ter de criar uma aplicação de processamento de streams.
Atualizações simultâneas a ambas as bases de dados a partir da aplicação
Um método alternativo é modificar a sua aplicação para realizar gravações em ambas as bases de dados. Uma base de dados (inicialmente Oracle) seria considerada a fonte de verdade e, após cada gravação na base de dados, a linha inteira é lida, convertida e gravada na base de dados do Spanner.
Desta forma, a aplicação substitui constantemente as linhas do Spanner pelos dados mais recentes.
Depois de se certificar de que todos os dados foram transferidos corretamente, pode mudar a fonte de verdade para a base de dados do Spanner.
Este mecanismo oferece um caminho de reversão se forem encontrados problemas ao mudar para o Spanner.
Valide a consistência dos dados
À medida que os dados são transmitidos para a sua base de dados do Spanner, pode executar periodicamente uma comparação entre os dados do Spanner e os dados do Oracle para garantir que os dados são consistentes.
Pode validar a consistência consultando ambas as origens de dados e comparando os resultados.
Pode usar o Dataflow para fazer uma comparação detalhada em grandes conjuntos de dados através da transformação de junção. Esta transformação usa 2 conjuntos de dados com chaves e faz corresponder os valores por chave. Em seguida, os valores correspondentes podem ser comparados quanto à igualdade.
Pode executar esta validação regularmente até que o nível de consistência corresponda aos requisitos da sua empresa.
Passo 6: mude para o Spanner como a fonte prioritária da sua aplicação
Quando tiver confiança na migração de dados, pode mudar a sua aplicação para usar o Spanner como a origem prioritária. Continuar a escrever alterações na base de dados Oracle para a manter atualizada, dando-lhe um caminho de reversão caso surjam problemas.
Por último, pode desativar e remover o código de atualização da base de dados do Oracle e encerrar a base de dados do Oracle.
Exporte e importe bases de dados do Spanner
Opcionalmente, pode exportar as suas tabelas do Spanner para um contentor do Cloud Storage através de um modelo do Dataflow para realizar a exportação. A pasta resultante contém um conjunto de ficheiros Avro e ficheiros de manifesto JSON com as suas tabelas exportadas. Estes ficheiros podem servir vários propósitos, incluindo:
- Fazer uma cópia de segurança da base de dados para conformidade com a política de retenção de dados ou recuperação de desastres.
- Importar o ficheiro Avro para outras Google Cloud ofertas, como o BigQuery.
Para mais informações sobre o processo de exportação e importação, consulte os artigos Exportar bases de dados e Importar bases de dados.
O que se segue?
- Leia sobre como otimizar o seu esquema do Spanner.
- Saiba como usar o Dataflow para situações mais complexas.