Numa base de dados do Spanner, o Spanner cria automaticamente um índice para a chave primária de cada tabela. Por exemplo, não tem de fazer nada para indexar a chave primária de Singers, porque é indexada automaticamente.
Também pode criar índices secundários para outras colunas. Adicionar um índice secundário a uma coluna torna a procura de dados nessa coluna mais eficiente. Por exemplo, se precisar de procurar rapidamente um álbum por título, deve criar um índice secundário em AlbumTitle, para que o Spanner não precise de analisar toda a tabela.
Se a pesquisa no exemplo anterior for feita numa transação de leitura/escrita,
a pesquisa mais eficiente também evita manter bloqueios na tabela inteira,
o que permite inserções e atualizações simultâneas na tabela para linhas fora do
AlbumTitle intervalo de pesquisa.
Além das vantagens que oferecem às pesquisas, os índices secundários também podem ajudar o Spanner a executar análises de forma mais eficiente, permitindo análises de índices em vez de análises completas de tabelas.
O Spanner armazena os seguintes dados em cada índice secundário:
- Todas as colunas principais da tabela de base
- Todas as colunas incluídas no índice
- Todas as colunas especificadas na cláusula
STORINGopcional (bases de dados de dialeto GoogleSQL) ou na cláusulaINCLUDE(bases de dados de dialeto PostgreSQL) da definição do índice.
Ao longo do tempo, o Spanner analisa as suas tabelas para garantir que os índices secundários são usados para as consultas adequadas.
Adicione um índice secundário
O momento mais eficiente para adicionar um índice secundário é quando cria a tabela. Para criar uma tabela e os respetivos índices em simultâneo, envie as declarações DDL para a nova tabela e os novos índices num único pedido ao Spanner.
No Spanner, também pode adicionar um novo índice secundário a uma tabela existente enquanto a base de dados continua a servir tráfego. Tal como acontece com quaisquer outras alterações ao esquema no Spanner, a adição de um índice a uma base de dados existente não requer que a base de dados seja colocada offline e não bloqueia colunas nem tabelas inteiras.
Sempre que um novo índice é adicionado a uma tabela existente, o Spanner preenche automaticamente ou preenche o índice para refletir uma vista atualizada dos dados que estão a ser indexados. O Spanner gere este processo de preenchimento para si, e o processo é executado em segundo plano usando recursos de nós com prioridade baixa. A velocidade do preenchimento de dados alternativos do índice adapta-se à alteração dos recursos dos nós durante a criação do índice, e o preenchimento de dados alternativos não afeta significativamente o desempenho da base de dados.
A criação do índice pode demorar de vários minutos a muitas horas. Uma vez que a criação de índices é uma atualização do esquema, está sujeita às mesmas restrições de desempenho que qualquer outra atualização do esquema. O tempo necessário para criar um índice secundário depende de vários fatores:
- O tamanho do conjunto de dados
- A capacidade de computação da instância
- A carga na instância
Para ver o progresso de um processo de preenchimento de índice, consulte a secção de progresso.
Tenha em atenção que a utilização da coluna commit timestamp como a primeira parte do índice secundário pode criar hotspots e reduzir o desempenho de escrita.
Use a declaração CREATE INDEX para definir um índice secundário no seu esquema. Seguem-se alguns exemplos:
Para indexar todos os Singers na base de dados pelo respetivo nome próprio e apelido:
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Para criar um índice de todos os Songs na base de dados pelo valor de SongName:
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
Para indexar apenas as músicas de um determinado cantor, use a cláusula INTERLEAVE IN para intercalar o índice na tabela Singers:
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
Para indexar apenas as músicas de um álbum específico:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
Para indexar por ordem descendente de SongName:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
Tenha em atenção que a anotação DESC anterior aplica-se apenas a SongName. Para indexar por ordem descendente de outras chaves de índice, anote-as também com DESC:
SingerId DESC, AlbumId DESC.
Tenha também em atenção que PRIMARY_KEY é uma palavra reservada e não pode ser usada como nome de um índice. É o nome atribuído ao pseudo-índice
criado quando é criada uma tabela com a especificação PRIMARY KEY
Para mais detalhes e práticas recomendadas para escolher índices não intercalados e índices intercalados, consulte as Opções de índice e Use um índice intercalado numa coluna cujo valor aumenta ou diminui monotonicamente.
Índices e intercalação
Os índices do Spanner podem ser intercalados com outras tabelas para colocar as linhas de índice com as de outra tabela. Semelhante à intercalação de tabelas do Spanner, as colunas da chave primária do elemento principal do índice têm de ser um prefixo das colunas indexadas, correspondendo ao tipo e à ordem de ordenação. Ao contrário das tabelas intercaladas, não é necessário fazer a correspondência dos nomes das colunas. Cada linha de um índice intercalado é armazenada fisicamente em conjunto com a linha principal associada.
Por exemplo, considere o seguinte esquema:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
Para indexar todos os Singers na base de dados pelo respetivo nome próprio e apelido, tem de
criar um índice. Veja como definir o índice SingersByFirstLastName:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Se quiser criar um índice de Songs em (SingerId, AlbumId, SongName),
pode fazer o seguinte:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
Em alternativa, pode criar um índice intercalado com um antepassado de Songs, como o seguinte:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
Além disso, também pode criar um índice de Songs em (PublisherId, SingerId, AlbumId, SongName) que esteja intercalado com uma tabela que não seja um antepassado de Songs, como Publishers. Tenha em atenção que a chave principal
da tabela Publishers (id) não é um prefixo das colunas indexadas no
exemplo seguinte. Isto continua a ser permitido porque Publishers.Id e Songs.PublisherId partilham o mesmo tipo, ordem de ordenação e capacidade de ser nulo.
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
Verifique o progresso do preenchimento de dados do índice
Consola
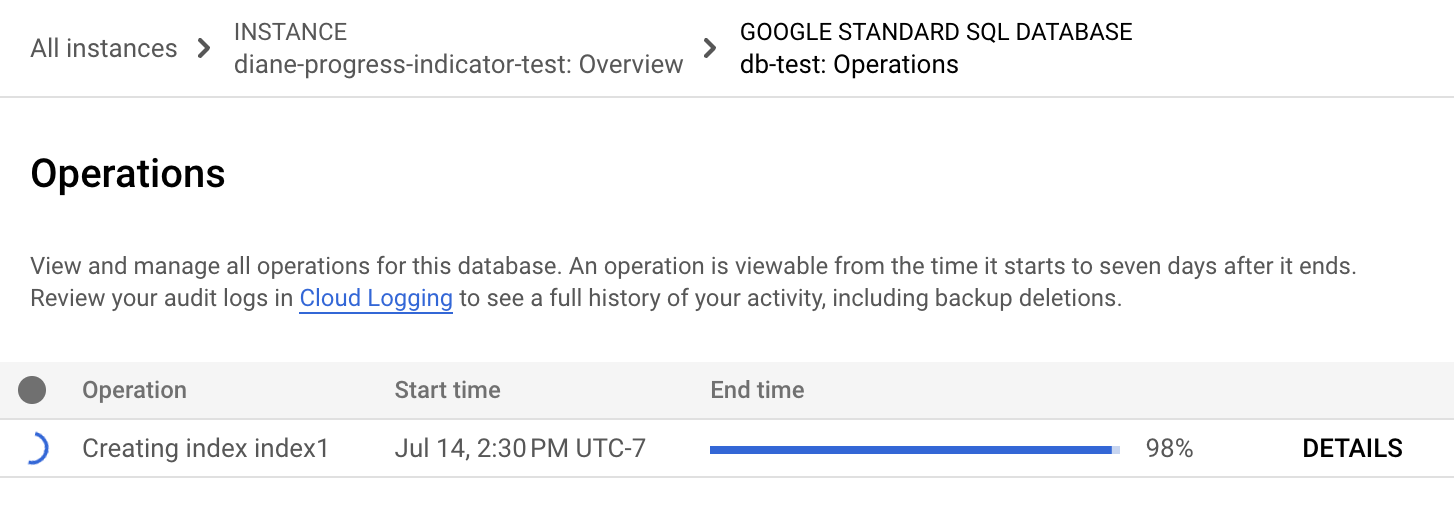
No menu de navegação do Spanner, clique no separador Operations (Operações). A página Operações mostra uma lista de operações em execução.
Encontre a operação de preenchimento na lista. Se ainda estiver em execução, o indicador de progresso na coluna Hora de conclusão mostra a percentagem da operação concluída, conforme apresentado na imagem seguinte:
gcloud
Use gcloud spanner operations describe
para verificar o progresso de uma operação.
Obtenha o ID da operação:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Substitua o seguinte:
- INSTANCE-NAME com o nome da instância do Spanner.
- DATABASE-NAME com o nome da base de dados.
Notas de utilização:
Para limitar a lista, especifique a flag
--filter. Por exemplo:--filter="metadata.name:example-db"só lista as operações numa base de dados específica.--filter="error:*"apenas lista as operações de cópia de segurança que falharam.
Para ver informações sobre a sintaxe dos filtros, consulte o artigo Filtros de tópicos do gcloud. Para informações sobre a filtragem de operações de cópia de segurança, consulte o campo
filterem ListBackupOperationsRequest.O indicador
--typenão é sensível a maiúsculas e minúsculas.
O resultado tem um aspeto semelhante ao seguinte:
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadataCorrida
gcloud spanner operations describe:gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
Substitua o seguinte:
- INSTANCE-NAME: o nome da instância do Spanner.
- DATABASE-NAME: o nome da base de dados do Spanner.
- PROJECT-NAME: o nome do projeto.
- OPERATION-ID: o ID da operação que quer verificar.
A secção
progressna saída mostra a percentagem da operação concluída. O resultado tem um aspeto semelhante ao seguinte:done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
Obtenha o ID da operação:
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Substitua o seguinte:
- INSTANCE-NAME com o nome da instância do Spanner.
- DATABASE-NAME com o nome da base de dados.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT-ID: o ID do projeto.
- INSTANCE-ID: o ID da instância.
- DATABASE-ID: o ID da base de dados.
- OPERATION-ID: o ID da operação.
Método HTTP e URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Para gcloud e REST, pode encontrar o progresso de cada declaração de preenchimento retroativo do índice na secção progress. Para cada declaração na matriz de declarações, existe um campo correspondente na matriz de progresso. Esta ordem da matriz de progresso corresponde à ordem da matriz de declarações. Assim que estiverem disponíveis, os campos startTime, progressPercent e endTime são preenchidos em conformidade.
Tenha em atenção que o resultado não mostra uma hora estimada para a conclusão do progresso do preenchimento.
Se a operação demorar demasiado tempo, pode cancelá-la. Para mais informações, consulte o artigo Cancele a criação do índice.
Cenários ao ver o progresso do repreenchimento do índice
Existem diferentes cenários que pode encontrar quando tenta verificar o progresso do preenchimento de dados do índice. As declarações de criação de índice que requerem um preenchimento de índice fazem parte das operações de atualização do esquema, e podem existir várias declarações que fazem parte de uma operação de atualização do esquema.
O primeiro cenário é o mais simples, ou seja, quando a declaração de criação de índice é a primeira declaração na operação de atualização do esquema. Uma vez que a declaração de criação do índice é a primeira declaração, é a primeira a ser processada e executada devido à ordem de execução.
Imediatamente, o campo startTime da declaração de criação do índice é preenchido com a hora de início da operação de atualização do esquema. Em seguida, o campo progressPercent da declaração de criação do índice é preenchido quando o progresso do preenchimento do índice é superior a 0%. Por último, o campo endTime é preenchido assim que a declaração for confirmada.
O segundo cenário ocorre quando a declaração de criação de índice não é a primeira declaração na operação de atualização do esquema. Nenhum campo relacionado com a declaração de criação do índice é preenchido até que as declarações anteriores tenham sido confirmadas devido à ordem de execução.
Tal como no cenário anterior, assim que os extratos anteriores forem confirmados, o campo startTime da declaração de criação do índice é preenchido primeiro, seguido do campo progressPercent. Por último, o campo endTime é preenchido assim que a declaração terminar a confirmação.
Cancele a criação do índice
Pode usar a Google Cloud CLI para cancelar a criação do índice. Para obter uma lista de operações de atualização do esquema para uma base de dados do Spanner, use o comando gcloud spanner operations list e inclua a opção --filter:
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
Encontre o OPERATION_ID da operação que quer cancelar e, de seguida, use o comando
gcloud spanner operations cancel para a cancelar:
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
Veja os índices existentes
Para ver informações sobre os índices existentes numa base de dados, pode usar a Google Cloud consola ou a CLI Google Cloud:
Consola
Aceda à página Instances do Spanner na Google Cloud consola.
Clique no nome da instância que quer ver.
No painel do lado esquerdo, clique na base de dados que quer ver e, de seguida, clique na tabela que quer ver.
Clique no separador Índices. A Google Cloud consola mostra uma lista de índices.
Opcional: para ver detalhes sobre um índice, como as colunas que inclui, clique no nome do índice.
gcloud
Use o comando gcloud spanner databases ddl describe:
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
A CLI gcloud imprime as declarações da linguagem de definição de dados (LDD)
para criar as tabelas e os índices da base de dados. As declarações CREATE
INDEX descrevem os índices existentes. Por
exemplo:
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
Consulta com um índice específico
As secções seguintes explicam como especificar um índice numa declaração SQL e
com a interface de leitura do Spanner. Os exemplos nestas secções
partem do princípio de que adicionou uma coluna MarketingBudget à tabela Albums e
criou um índice denominado AlbumsByAlbumTitle:
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Especifique um índice numa declaração SQL
Quando usa SQL para consultar uma tabela do Spanner, o Spanner usa automaticamente todos os índices que provavelmente tornam a consulta mais eficiente. Consequentemente, não precisa de especificar um índice para consultas SQL. No entanto, para consultas críticas para a sua carga de trabalho, a Google recomenda que use diretivas FORCE_INDEX nas suas declarações SQL para um desempenho mais consistente.
Em alguns casos, o Spanner pode escolher um índice que faça com que a latência da consulta aumente. Se seguiu os passos de resolução de problemas para regressões de desempenho e confirmou que faz sentido experimentar um índice diferente para a consulta, pode especificar o índice como parte da consulta.
Para especificar um índice numa declaração SQL, use a sugestão FORCE_INDEX
para fornecer uma diretiva de índice. As diretivas de indexação usam a seguinte sintaxe:
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
Também pode usar uma diretiva de índice para indicar ao Spanner que analise a tabela base em vez de usar um índice:
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
Pode usar uma diretiva de índice para indicar ao Spanner que analise um índice numa tabela com esquemas com nome:
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
O exemplo seguinte mostra uma consulta SQL que especifica um índice:
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
Uma diretiva de índice pode forçar o processador de consultas do Spanner a ler colunas adicionais que são necessárias para a consulta, mas não estão armazenadas no índice.
O processador de consultas obtém estas colunas juntando o índice e a tabela base. Para evitar esta junção adicional, use uma cláusula
STORING (bases de dados de dialeto GoogleSQL) ou uma cláusula INCLUDE (bases de dados de dialeto PostgreSQL) para
armazenar as colunas adicionais no índice.
No exemplo anterior, a coluna MarketingBudget não está armazenada no índice, mas a consulta SQL seleciona esta coluna. Como resultado, o Spanner tem de procurar a coluna MarketingBudget na tabela base e, em seguida, juntá-la aos dados do índice para devolver os resultados da consulta.
O Spanner gera um erro se a diretiva de índice tiver algum dos seguintes problemas:
- O índice não existe.
- O índice está numa tabela base diferente.
- A consulta tem em falta uma expressão de filtragem obrigatória
NULLpara um índiceNULL_FILTERED.
Os exemplos seguintes mostram como escrever e executar consultas que obtêm os valores de AlbumId, AlbumTitle e MarketingBudget usando o índice AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Especifique um índice na interface de leitura
Quando usa a interface de leitura para o Spanner e quer que o Spanner use um índice, tem de especificar o índice. A interface de leitura não seleciona o índice automaticamente.
Além disso, o índice tem de conter todos os dados que aparecem nos resultados da consulta, excluindo as colunas que fazem parte da chave primária. Esta restrição existe porque a interface de leitura não suporta junções entre o índice e a tabela base. Se precisar de incluir outras colunas nos resultados da consulta, tem algumas opções:
- Use uma cláusula
STORINGouINCLUDEpara armazenar as colunas adicionais no índice. - Consultar sem incluir as colunas adicionais e, em seguida, usar as chaves principais para enviar outra consulta que leia as colunas adicionais.
O Spanner devolve valores do índice por ordem ascendente de ordenação pela chave do índice. Para obter valores por ordem descendente, conclua estes passos:
Anotar a chave de índice com
DESC. Por exemplo:CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);A anotação
DESCaplica-se a uma única chave de índice. Se o índice incluir mais do que uma chave e quiser que os resultados da consulta apareçam por ordem descendente com base em todas as chaves, inclua uma anotaçãoDESCpara cada chave.Se a leitura especificar um intervalo de chaves, certifique-se de que o intervalo de chaves também está por ordem descendente. Por outras palavras, o valor da chave de início tem de ser superior ao valor da chave de fim.
O exemplo seguinte mostra como obter os valores de AlbumId e AlbumTitle através do índice AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Crie um índice para verificações apenas de índice
Opcionalmente, pode usar a cláusula STORING (para bases de dados de dialeto GoogleSQL) ou a cláusula INCLUDE (para bases de dados de dialeto PostgreSQL) para armazenar uma cópia de uma coluna no índice. Este tipo de índice oferece vantagens para consultas e chamadas de leitura que usam o índice, ao custo de usar armazenamento adicional:
- As consultas SQL que usam o índice e selecionam colunas armazenadas na cláusula
STORINGouINCLUDEnão requerem uma junção adicional à tabela base. - As chamadas
read()que usam o índice podem ler colunas armazenadas pela cláusulaSTORING/INCLUDE.
Por exemplo, suponhamos que criou uma versão alternativa de AlbumsByAlbumTitle
que armazena uma cópia da coluna MarketingBudget no índice (tenha em atenção a cláusula
STORING ou INCLUDE a negrito):
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
Com o índice AlbumsByAlbumTitle antigo, o Spanner tem de juntar o índice à tabela base e, em seguida, obter a coluna da tabela base. Com o novo índice AlbumsByAlbumTitle2, o Spanner lê a coluna diretamente do índice, o que é mais eficiente.
Se usar a interface de leitura em vez de SQL, o novo índice AlbumsByAlbumTitle2
também lhe permite ler a coluna MarketingBudget diretamente:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Altere um índice
Pode usar a declaração ALTER INDEX para adicionar colunas adicionais a um índice existente ou eliminar colunas. Isto pode atualizar a lista de colunas definida pela cláusula STORING (bases de dados de dialeto GoogleSQL) ou pela cláusula INCLUDE (bases de dados de dialeto PostgreSQL) quando cria o índice. Não pode usar esta declaração para adicionar colunas nem remover colunas da chave de índice. Por exemplo, em vez de criar um novo índice AlbumsByAlbumTitle2, pode usar ALTER INDEX para adicionar uma coluna a AlbumsByAlbumTitle, como mostrado no exemplo seguinte:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
Quando adiciona uma nova coluna a um índice existente, o Spanner usa um processo de preenchimento em segundo plano. Enquanto o preenchimento estiver em curso, a coluna no índice não é legível, pelo que pode não obter o aumento de desempenho esperado. Pode usar o comando gcloud spanner operations para listar a operação de longa duração e ver o respetivo estado.
Para mais informações, consulte o artigo Descreva a operação.
Também pode usar cancel operation para cancelar uma operação em execução.
Após o preenchimento, o Spanner adiciona a coluna ao índice. À medida que o índice aumenta, isto pode abrandar as consultas que usam o índice.
O exemplo seguinte mostra como remover uma coluna de um índice:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
Índice de valores NULL
Por predefinição, o Spanner indexa valores NULL. Por exemplo, recorde a definição do índice SingersByFirstLastName na tabela Singers:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Todas as linhas de Singers são indexadas, mesmo que FirstName ou LastName, ou ambos, sejam NULL.

Quando os valores NULL são indexados, pode executar consultas e leituras SQL eficientes sobre dados que incluem valores NULL. Por exemplo, use esta declaração de consulta SQL para encontrar todos os Singers com um NULL FirstName:
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
Ordem de ordenação para valores NULL
O Spanner ordena NULL como o valor mais pequeno para qualquer tipo específico. Para uma coluna por ordem ascendente (ASC), os valores NULL são ordenados primeiro. Para uma coluna por ordem descendente (DESC), os valores NULL são ordenados por último.
Desative a indexação de valores NULL
GoogleSQL
Para desativar a indexação de valores nulos, adicione a palavra-chave NULL_FILTERED à definição do índice. Os índices NULL_FILTERED são particularmente úteis para indexar colunas esparsas, em que a maioria das linhas contém um valor NULL. Nestes casos, o índice NULL_FILTERED pode ser consideravelmente mais pequeno e mais eficiente de manter do que um índice normal que inclua valores NULL.
Segue-se uma definição alternativa de SingersByFirstLastName que não indexa valores de NULL:
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
A palavra-chave NULL_FILTERED aplica-se a todas as colunas de chaves de índice. Não é possível especificar a filtragem de NULL por coluna.
PostgreSQL
Para filtrar linhas com valores nulos numa ou mais colunas indexadas, use o predicado WHERE COLUMN IS NOT NULL.
Os índices filtrados por nulos são particularmente úteis para indexar colunas esparsas, em que a maioria das linhas contém um valor NULL. Nestes casos, o índice filtrado por nulos pode ser consideravelmente mais pequeno e eficiente de manter do que um índice normal que inclua valores NULL.
Segue-se uma definição alternativa de SingersByFirstLastName que não indexa valores de NULL:
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
A filtragem de valores NULL impede que o Spanner os use para algumas consultas. Por exemplo, o Spanner não usa o índice para esta consulta, porque o índice omite todas as linhas Singers para as quais LastName é NULL. Como resultado, a utilização do índice impediria a consulta de devolver as linhas corretas:
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Para permitir que o Spanner use o índice, tem de reescrever a consulta para que exclua as linhas que também estão excluídas do índice:
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
Campos proto de índice
Use colunas geradas para indexar campos em buffers de protocolo armazenados em colunas PROTO, desde que os campos a serem indexados usem os tipos de dados primitivos ou ENUM.
Se definir um índice num campo de mensagem de protocolo, não pode modificar nem remover esse campo do esquema proto. Para mais informações, consulte o artigo Atualizações aos esquemas que contêm um índice em campos proto.
Segue-se um exemplo da tabela Singers com uma coluna de mensagem proto SingerInfo. Para definir um índice no campo nationality do PROTO,
tem de criar uma coluna gerada armazenada:
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
Tem a seguinte definição do tipo googlesql.example.SingerInfo proto:
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
Em seguida, defina um índice no campo nationality do proto:
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
A seguinte consulta SQL lê dados através do índice anterior:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
Notas:
- Use uma diretiva de índice para aceder a índices nos campos das colunas de protocolo de buffer.
- Não pode criar um índice em campos de buffers de protocolo repetidos.
Atualizações aos esquemas que contêm um índice em campos proto
Se definir um índice num campo de mensagem de protocolo, não pode modificar nem remover esse campo do esquema proto. Isto deve-se ao facto de, depois de definir o índice, a verificação de tipos ser realizada sempre que o esquema é atualizado. O Spanner captura as informações de tipo de todos os campos no caminho que são usados na definição do índice.
Índices únicos
Os índices podem ser declarados UNIQUE. Os índices UNIQUE adicionam uma restrição aos dados que estão a ser indexados, o que proíbe entradas duplicadas para uma determinada chave de índice.
Esta restrição é aplicada pelo Spanner no momento da confirmação da transação.
Especificamente, qualquer transação que faça com que existam várias entradas de índice para a mesma chave não vai ser confirmada.
Se uma tabela contiver dados que não sejam UNIQUE, a tentativa de criar um índice UNIQUE falha.
Uma nota sobre os índices UNIQUE NULL_FILTERED
Um índice UNIQUE NULL_FILTERED não aplica a unicidade da chave do índice quando, pelo menos, uma das partes da chave do índice é NULL.
Por exemplo, suponha que criou a seguinte tabela e índice:
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
As duas linhas seguintes em ExampleTable têm os mesmos valores para as chaves de índice secundárias Key1, Key2 e Col1:
1, NULL, 1, 1
1, NULL, 2, 1
Uma vez que Key2 é NULL e o índice é filtrado por nulos, as linhas não estão presentes no índice ExampleIndex. Como não são inseridos no índice, o índice não os rejeita por violarem a unicidade em (Key1, Key2,
Col1).
Se quiser que o índice aplique a unicidade dos valores da tupla (Key1,
Key2, Col1), tem de anotar Key2 com NOT NULL na definição da tabela ou criar o índice sem filtrar nulos.
Elimine um índice
Use a declaração DROP INDEX para remover um índice secundário do seu esquema.
Para eliminar o índice com o nome SingersByFirstLastName:
DROP INDEX SingersByFirstLastName;
Indexe para uma análise mais rápida
Quando o Spanner precisa de executar uma análise de tabela (em vez de uma pesquisa indexada) para obter valores de uma ou mais colunas, pode receber resultados mais rápidos se existir um índice para essas colunas e na ordem especificada pela consulta. Se fizer frequentemente consultas que requerem verificações, considere criar índices secundários para ajudar a que estas verificações ocorram de forma mais eficiente.
Em particular, se precisar que o Spanner analise frequentemente a chave primária ou outro índice de uma tabela por ordem inversa, pode aumentar a respetiva eficiência através de um índice secundário que torne a ordem escolhida explícita.
Por exemplo, a seguinte consulta devolve sempre um resultado rápido, mesmo que o Spanner precise de analisar Songs para encontrar o valor mais baixo de SongId:
SELECT SongId FROM Songs LIMIT 1;
SongId é a chave principal da tabela, armazenada (como todas as chaves principais)
por ordem ascendente. O Spanner pode analisar o índice dessa chave e encontrar
o primeiro resultado rapidamente.
No entanto, sem a ajuda de um índice secundário, a seguinte consulta não
seria devolvida tão rapidamente, especialmente se Songs contiver muitos dados:
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
Embora SongId seja a chave principal da tabela, o Spanner não tem forma de obter o valor mais elevado da coluna sem recorrer a uma análise completa da tabela.
A adição do seguinte índice permitiria que esta consulta devolvesse resultados mais rapidamente:
CREATE INDEX SongIdDesc On Songs(SongId DESC);
Com este índice implementado, o Spanner usá-lo-ia para devolver um resultado para a segunda consulta muito mais rapidamente.
O que se segue?
- Saiba mais sobre as práticas recomendadas de SQL para o Spanner.
- Compreenda os planos de execução de consultas para o Spanner.
- Saiba como resolver problemas de regressões de desempenho em consultas SQL.