AI 슈퍼컴퓨터에서 학습, 조정, 서비스 제공
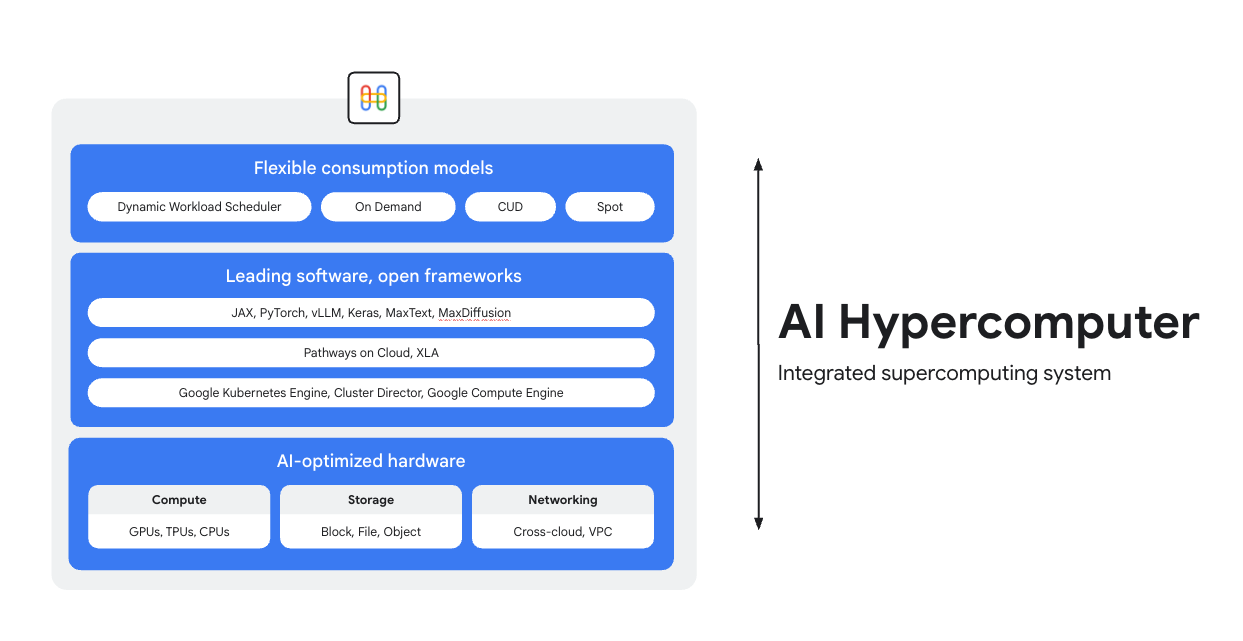
AI 하이퍼컴퓨터는 Google Cloud의 모든 AI 워크로드 기반의 통합형 슈퍼컴퓨팅 시스템입니다. AI 배포를 간소화하고 시스템 수준의 효율성을 개선하며 비용을 최적화하도록 설계된 하드웨어, 소프트웨어, 소비 모델로 구성되어 있습니다.
개요
AI 최적화 하드웨어
선도적인 소프트웨어, 개방형 프레임워크
개방형 프레임워크, 라이브러리, 컴파일러와 통합된 업계 최고의 소프트웨어를 통해 하드웨어의 성능을 최대한 활용하여 AI 개발, 통합, 관리를 더욱 효율적으로 수행하세요.
- PyTorch, JAX, Keras, vLLM, Megatron-LM, NeMo Megatron, MaxText, MaxDiffusion 등을 지원합니다.
- XLA 컴파일러와의 긴밀한 통합을 통해 다양한 가속기 간의 상호 운용이 가능하며, Pathways on Cloud를 사용하면 Google의 내부 대규모 학습 및 추론 인프라를 지원하는 동일한 분산 런타임을 사용할 수 있습니다.
- 이 모든 것은 Google Kubernetes Engine, Cluster Director 또는 Google Compute Engine 등 원하는 환경에 배포할 수 있습니다.
유연한 소비 모델
유연한 소비 옵션을 통해 고객은 약정 사용 할인이 적용된 고정 비용 또는 동적 주문형 모델을 선택하여 비즈니스 니즈를 충족할 수 있습니다. 동적 워크로드 스케줄러와 스팟 VM을 사용하면 과도한 할당 없이 필요한 용량을 확보할 수 있습니다. 또한 Google Cloud의 비용 최적화 도구는 리소스 사용을 자동화하여 엔지니어의 수동 작업을 줄여 줍니다.
비용 효율적으로 대규모 모델 제공
추론 워크로드의 가격 대비 성능과 안정성 극대화
추론은 빠르게 다양해지고 복잡해지고 있으며, 세 가지 주요 영역에서 발전하고 있습니다.
- 첫째, AI와 상호작용하는 방식이 바뀌고 있습니다. 이제 대화의 컨텍스트가 훨씬 길고 다양해졌습니다.
- 둘째, 정교한 추론과 다단계 추론으로 인해 전문가 망(MoE) 모델이 더욱 보편화되고 있습니다. 이는 초기 입력부터 최종 출력까지 메모리와 컴퓨팅이 확장되는 방식을 재정의합니다.
- 마지막으로, 달러당 원시 토큰 수뿐만 아니라 응답의 유용성이 진정한 가치라는 점이 분명합니다. 모델이 적절한 전문성을 갖추고 있나요? 중요한 비즈니스 질문에 정확하게 답했나요? 따라서 고객은 프로세서 가격이 아닌 시스템 운영의 총비용에 초점을 맞춘 더 나은 측정 기준이 필요합니다.
AI 추론 리소스 살펴보기
- AI 추론이란 무엇인가요? 유형, 비교, 사용 사례에 대한 종합 가이드
- GKE 추론 빠른 시작으로 권장사항 추론 레시피 실행
- Cloud Run의 AI 추론에 대한 과정 수강
- 비용 효율적인 AI 추론의 비결에 대한 동영상 시청
- AI 추론 워크로드를 가속화하는 방법 알아보기
스포츠 팬을 유니폼 디자이너로 전환한 AI
PUMA는 통합 AI 인프라(AI 하이퍼컴퓨터)를 위해 Google Cloud와 파트너십을 맺고 Gemini를 사용자 프롬프트에 사용함과 동시에 동적 워크로드 스케줄러를 사용하여 GPU의 추론을 동적으로 확장함으로써 비용과 생성 시간을 획기적으로 줄였습니다.
영향:
- AI 유니폼 생성 시간을 2~5분에서 30초로 단축했습니다. 이러한 변화로 인해 플랫폼은 사용자의 참여를 유도하는 빠르고 진정한 양방향 환경으로 탈바꿈했습니다.
- 단 10일 만에 팬들은 180,000개의 유니폼을 만들고 170만 개의 평가를 제출했습니다.
- 이 프로젝트는 PUMA가 커뮤니티와 소통하는 새로운 방법이 되었습니다. 팬을 적극적인 공동 제작자로 성공적으로 전환하여 단순한 브랜드-소비자 관계를 넘어섰으며, 가장 열정적인 소비자의 창의적인 욕망에 대한 직접적인 실시간 인사이트를 회사에 제공했습니다.



방법
추론 워크로드의 가격 대비 성능과 안정성 극대화
추론은 빠르게 다양해지고 복잡해지고 있으며, 세 가지 주요 영역에서 발전하고 있습니다.
- 첫째, AI와 상호작용하는 방식이 바뀌고 있습니다. 이제 대화의 컨텍스트가 훨씬 길고 다양해졌습니다.
- 둘째, 정교한 추론과 다단계 추론으로 인해 전문가 망(MoE) 모델이 더욱 보편화되고 있습니다. 이는 초기 입력부터 최종 출력까지 메모리와 컴퓨팅이 확장되는 방식을 재정의합니다.
- 마지막으로, 달러당 원시 토큰 수뿐만 아니라 응답의 유용성이 진정한 가치라는 점이 분명합니다. 모델이 적절한 전문성을 갖추고 있나요? 중요한 비즈니스 질문에 정확하게 답했나요? 따라서 고객은 프로세서 가격이 아닌 시스템 운영의 총비용에 초점을 맞춘 더 나은 측정 기준이 필요합니다.
추가 리소스
AI 추론 리소스 살펴보기
- AI 추론이란 무엇인가요? 유형, 비교, 사용 사례에 대한 종합 가이드
- GKE 추론 빠른 시작으로 권장사항 추론 레시피 실행
- Cloud Run의 AI 추론에 대한 과정 수강
- 비용 효율적인 AI 추론의 비결에 대한 동영상 시청
- AI 추론 워크로드를 가속화하는 방법 알아보기
고객 사례
스포츠 팬을 유니폼 디자이너로 전환한 AI
PUMA는 통합 AI 인프라(AI 하이퍼컴퓨터)를 위해 Google Cloud와 파트너십을 맺고 Gemini를 사용자 프롬프트에 사용함과 동시에 동적 워크로드 스케줄러를 사용하여 GPU의 추론을 동적으로 확장함으로써 비용과 생성 시간을 획기적으로 줄였습니다.
영향:
- AI 유니폼 생성 시간을 2~5분에서 30초로 단축했습니다. 이러한 변화로 인해 플랫폼은 사용자의 참여를 유도하는 빠르고 진정한 양방향 환경으로 탈바꿈했습니다.
- 단 10일 만에 팬들은 180,000개의 유니폼을 만들고 170만 개의 평가를 제출했습니다.
- 이 프로젝트는 PUMA가 커뮤니티와 소통하는 새로운 방법이 되었습니다. 팬을 적극적인 공동 제작자로 성공적으로 전환하여 단순한 브랜드-소비자 관계를 넘어섰으며, 가장 열정적인 소비자의 창의적인 욕망에 대한 직접적인 실시간 인사이트를 회사에 제공했습니다.
대규모 AI 학습 및 사전 학습 실행
강력하고 확장 가능하며 효율적인 AI 학습
학습 워크로드는 긴밀하게 결합된 클러스터의 수천 개 노드에서 고도로 동기화된 작업으로 실행되어야 합니다. 단일 노드의 성능 저하만으로도 전체 작업이 중단될 수 있으며, 이는 출시 지연으로 이어질 수 있습니다. 다음 작업을 수행해야 합니다.
- 클러스터가 빠르게 설정되고 해당 워크로드에 맞게 조정되었는지 확인합니다.
- 장애를 예측하고 신속하게 문제를 해결합니다.
- 장애가 발생하더라도 워크로드를 계속 진행합니다.
고객이 Google Cloud에서 학습 워크로드를 매우 쉽게 배포하고 확장할 수 있도록 지원하고자 합니다.
강력하고 확장 가능하며 효율적인 AI 학습
AI 클러스터를 만들려면 다음 튜토리얼 중 하나를 시작하세요.
- GPU(A4 VM) 및 Cluster Toolkit으로 Slurm 클러스터 만들기
- GKE용 Cluster Directo 또는 Cluster Toolkit으로 GKE 클러스터 만들기
Moloco, 매일 수십억 건의 요청을 처리하는 광고 게재 플랫폼 빌드
Moloco는 AI 하이퍼컴퓨터의 완전 통합 스택을 활용하여 TPU 및 GPU와 같은 고급 하드웨어에서 자동으로 확장할 수 있었고, 그 결과 Moloco 엔지니어의 업무 부담을 덜 수 있었습니다. 또한 Google의 업계 최고의 데이터 플랫폼과의 통합을 통해 AI 워크로드에 대한 일관된 엔드 투 엔드 시스템을 구축할 수 있었습니다.
첫 번째 딥러닝 모델을 출시한 후 Moloco는 2년 반 만에 5배 성장하고 수익을 달성하는 등 급격한 성장과 수익성을 경험했습니다.
- GKE의 Cloud TPU를 사용해 모델 학습 속도 10배 향상, 학습 비용 4배 절감
- 1,000명 이상의 내부 사용자에게 서비스를 제공할 수 있도록 확장되어 사용자가 자체 데이터에서 수익성 있는 성장을 찾을 수 있도록 지원하는 전 세계적 규모의 머신러닝 시스템에 액세스할 수 있습니다.




방법
강력하고 확장 가능하며 효율적인 AI 학습
학습 워크로드는 긴밀하게 결합된 클러스터의 수천 개 노드에서 고도로 동기화된 작업으로 실행되어야 합니다. 단일 노드의 성능 저하만으로도 전체 작업이 중단될 수 있으며, 이는 출시 지연으로 이어질 수 있습니다. 다음 작업을 수행해야 합니다.
- 클러스터가 빠르게 설정되고 해당 워크로드에 맞게 조정되었는지 확인합니다.
- 장애를 예측하고 신속하게 문제를 해결합니다.
- 장애가 발생하더라도 워크로드를 계속 진행합니다.
고객이 Google Cloud에서 학습 워크로드를 매우 쉽게 배포하고 확장할 수 있도록 지원하고자 합니다.
추가 리소스
강력하고 확장 가능하며 효율적인 AI 학습
AI 클러스터를 만들려면 다음 튜토리얼 중 하나를 시작하세요.
- GPU(A4 VM) 및 Cluster Toolkit으로 Slurm 클러스터 만들기
- GKE용 Cluster Directo 또는 Cluster Toolkit으로 GKE 클러스터 만들기
고객 사례
Moloco, 매일 수십억 건의 요청을 처리하는 광고 게재 플랫폼 빌드
Moloco는 AI 하이퍼컴퓨터의 완전 통합 스택을 활용하여 TPU 및 GPU와 같은 고급 하드웨어에서 자동으로 확장할 수 있었고, 그 결과 Moloco 엔지니어의 업무 부담을 덜 수 있었습니다. 또한 Google의 업계 최고의 데이터 플랫폼과의 통합을 통해 AI 워크로드에 대한 일관된 엔드 투 엔드 시스템을 구축할 수 있었습니다.
첫 번째 딥러닝 모델을 출시한 후 Moloco는 2년 반 만에 5배 성장하고 수익을 달성하는 등 급격한 성장과 수익성을 경험했습니다.
- GKE의 Cloud TPU를 사용해 모델 학습 속도 10배 향상, 학습 비용 4배 절감
- 1,000명 이상의 내부 사용자에게 서비스를 제공할 수 있도록 확장되어 사용자가 자체 데이터에서 수익성 있는 성장을 찾을 수 있도록 지원하는 전 세계적 규모의 머신러닝 시스템에 액세스할 수 있습니다.
AI 애플리케이션 배포 및 조정
선도적인 AI 조정 소프트웨어와 개방형 프레임워크를 활용하여 AI 기반 환경 제공
Google Cloud는 일반적인 운영체제, 프레임워크, 라이브러리, 드라이버가 포함된 이미지를 제공합니다. AI 하이퍼컴퓨터는 이러한 사전 구성된 이미지를 최적화하여 AI 워크로드를 지원합니다.
- AI 및 ML 프레임워크와 라이브러리: 딥 러닝 소프트웨어 레이어(DLSL) Docker 이미지를 사용하여 Google Kubernetes Engine(GKE) 클러스터에서 NeMO 및 MaxText와 같은 ML 모델을 실행합니다.
- 클러스터 배포 및 AI 조정: AI 워크로드를 GKE 클러스터, Slurm 클러스터 또는 Compute Engine 인스턴스에 배포할 수 있습니다. 자세한 내용은 VM 및 클러스터 생성 개요를 참조하세요.
소프트웨어 리소스 살펴보기
- Pathways on Cloud는 대규모 멀티태스크 희소 활성화 머신러닝 시스템을 만들 수 있도록 설계된 시스템입니다.
- Google Cloud의 Goodput 레시피를 활용하여 ML 생산성을 최적화하세요.
- Topology Aware Scheduling으로 GKE 워크로드를 예약하세요.
- GPU에서 DeepSeek, Mixtral, Llama, GPT 모델을 실행하기 위한 벤치마킹 레시피 중 하나를 사용해 보세요.
- 소비 옵션을 선택하여 컴퓨팅 리소스를 보다 효율적으로 확보하고 사용하세요.
Priceline: 여행자가 특별한 경험을 누릴 수 있도록 지원
"Google Cloud와 협력하여 생성형 AI를 통합함으로써 챗봇 내에 맞춤형 여행 컨시어지를 만들 수 있게 되었습니다. 저희는 고객이 여행 계획을 세우는 것을 넘어서 취향을 반영한 특별한 여행을 경험할 수 있도록 돕고 싶습니다." 마틴 브로드벡, Priceline CTO




방법
선도적인 AI 조정 소프트웨어와 개방형 프레임워크를 활용하여 AI 기반 환경 제공
Google Cloud는 일반적인 운영체제, 프레임워크, 라이브러리, 드라이버가 포함된 이미지를 제공합니다. AI 하이퍼컴퓨터는 이러한 사전 구성된 이미지를 최적화하여 AI 워크로드를 지원합니다.
- AI 및 ML 프레임워크와 라이브러리: 딥 러닝 소프트웨어 레이어(DLSL) Docker 이미지를 사용하여 Google Kubernetes Engine(GKE) 클러스터에서 NeMO 및 MaxText와 같은 ML 모델을 실행합니다.
- 클러스터 배포 및 AI 조정: AI 워크로드를 GKE 클러스터, Slurm 클러스터 또는 Compute Engine 인스턴스에 배포할 수 있습니다. 자세한 내용은 VM 및 클러스터 생성 개요를 참조하세요.
추가 리소스
소프트웨어 리소스 살펴보기
- Pathways on Cloud는 대규모 멀티태스크 희소 활성화 머신러닝 시스템을 만들 수 있도록 설계된 시스템입니다.
- Google Cloud의 Goodput 레시피를 활용하여 ML 생산성을 최적화하세요.
- Topology Aware Scheduling으로 GKE 워크로드를 예약하세요.
- GPU에서 DeepSeek, Mixtral, Llama, GPT 모델을 실행하기 위한 벤치마킹 레시피 중 하나를 사용해 보세요.
- 소비 옵션을 선택하여 컴퓨팅 리소스를 보다 효율적으로 확보하고 사용하세요.
고객 사례
Priceline: 여행자가 특별한 경험을 누릴 수 있도록 지원
"Google Cloud와 협력하여 생성형 AI를 통합함으로써 챗봇 내에 맞춤형 여행 컨시어지를 만들 수 있게 되었습니다. 저희는 고객이 여행 계획을 세우는 것을 넘어서 취향을 반영한 특별한 여행을 경험할 수 있도록 돕고 싶습니다." 마틴 브로드벡, Priceline CTO
FAQ
AI 하이퍼컴퓨터는 개별 클라우드 서비스를 사용하는 것과 어떻게 다른가요?
개별 서비스는 특정 기능을 제공하지만 AI 하이퍼컴퓨터는 하드웨어, 소프트웨어, 소비 모델이 최적으로 함께 작동하도록 설계된 통합 시스템을 제공합니다. 이러한 통합은 서로 다른 서비스를 결합하여 달성하기 어려운 성능, 비용, TTM(time to market) 측면에서 시스템 수준의 효율성을 제공합니다. 복잡성을 간소화하고 AI 인프라에 대한 전체적인 접근 방식을 제공합니다.
AI 하이퍼컴퓨터를 하이브리드 또는 멀티 클라우드 환경에서 사용할 수 있나요?
예, AI 하이퍼컴퓨터는 유연성을 염두에 두고 설계되었습니다. Cross-Cloud Interconnect와 같은 기술은 온프레미스 데이터 센터와 다른 클라우드에 대한 고대역폭 연결을 제공하여 하이브리드 및 멀티 클라우드 AI 전략을 지원합니다. Google Cloud는 개방형 표준을 기반으로 운영되며 널리 사용되는 서드 파티 소프트웨어를 통합하여 여러 환경에 걸쳐 솔루션을 빌드하고 원하는 대로 서비스를 변경할 수 있도록 지원합니다.
AI 하이퍼컴퓨터는 AI 워크로드의 보안을 어떻게 처리하나요?
보안은 AI 하이퍼컴퓨터의 핵심 측면입니다. Google Cloud의 다층 보안 모델을 활용합니다. 특정 기능으로는 Titan 보안 마이크로컨트롤러(신뢰할 수 있는 상태에서 시스템 부팅 보장), RDMA 방화벽(학습 중 TPU/GPU 간 제로 트러스트 네트워킹 지원), AI 안전을 위한 Model Armor와 같은 솔루션과의 통합 등이 있습니다. 이러한 기능은 안전한 AI 프레임워크와 같은 강력한 인프라 보안 정책 및 원칙으로 보완됩니다.
AI 하이퍼컴퓨터를 인프라로 사용하는 가장 쉬운 방법은 무엇인가요?
- VM 관리를 원하지 않는 경우 Google Kubernetes Engine(GKE)으로 시작하는 것이 좋습니다.
- 여러 스케줄러를 사용해야 하거나 GKE를 사용할 수 없는 경우 Cluster Director를 사용하는 것이 좋습니다.
- 인프라를 완벽하게 제어하고 싶다면 VM을 직접 사용하는 방법밖에 없으며, 이를 위해서는 Compute Engine이 최적의 선택입니다.
대규모/고확장 워크로드에만 유용한가요?
아니요. AI 하이퍼컴퓨터는 모든 규모의 워크로드에 사용할 수 있습니다. 작은 규모의 워크로드도 효율성 및 간소화된 배포와 같은 통합 시스템의 모든 이점을 실현할 수 있습니다. AI 하이퍼컴퓨터는 소규모 개념 증명 및 실험부터 대규모 프로덕션 배포에 이르기까지 비즈니스 규모에 따라 고객을 지원합니다.
AI 하이퍼컴퓨터는 Google Cloud에서 AI 워크로드를 시작하는 가장 쉬운 방법인가요?
대부분의 고객에게는 모든 도구, 템플릿, 모델이 내장되어 있는 Vertex AI와 같은 관리형 AI 플랫폼이 AI를 시작하는 가장 쉬운 방법입니다. 또한 Vertex AI는 사용자를 위해 최적화된 방식으로 내부적으로 AI 하이퍼컴퓨터를 기반으로 작동합니다. Vertex AI는 가장 간단한 경험을 제공하므로 가장 쉽게 시작할 수 있는 방법입니다. 인프라의 모든 구성요소를 구성하고 최적화하려는 경우 AI 하이퍼컴퓨터의 구성요소를 인프라로 액세스하여 필요에 맞게 구성할 수 있습니다.
AI 하이퍼컴퓨터는 구성 가능한 시스템이므로 다양한 옵션이 있습니다. 각 사용 사례에 대한 권장사항이 있나요?
예, Github에서 레시피 라이브러리를 빌드하고 있습니다. Cluster Toolkit을 사용하여 사전 빌드된 클러스터 청사진을 만들 수도 있습니다.
AI 하이퍼컴퓨터를 IaaS로 사용할 때 어떤 옵션을 사용할 수 있나요?
AI 최적화 하드웨어
스토리지
- 학습: Managed Lustre는 높은 처리량과 PB 규모의 용량으로 까다로운 AI 학습에 이상적입니다. GCS Fuse(원하는 경우 Anywhere Cache 포함)는 지연 시간이 더 여유로운 대용량 요구사항에 적합합니다. 두 제품 모두 GKE 및 Cluster Director와 통합됩니다.
- 추론: Anywhere Cache가 포함된 GCS Fuse는 간단한 솔루션을 제공합니다. 더 높은 성능을 원한다면 Hyperdisk ML을 고려해 보세요. 동일한 영역에서 학습에 Managed Lustre를 사용하는 경우 추론에도 사용할 수 있습니다.
네트워킹
- 학습: VPC의 RDMA 네트워킹, 고대역폭 클라우드 및 Cross-Cloud Interconnect와 같은 기술을 활용하여 데이터를 빠르게 전송합니다.
- 추론: GKE Inference Gateway 및 향상된 Cloud Load Balancing과 같은 솔루션을 활용하여 지연 시간이 짧은 서빙을 제공합니다. Model Armor는 AI 안전 및 보안을 위해 통합될 수 있습니다.
컴퓨팅: Google Cloud TPU(Trillium), NVIDIA GPU(Blackwell), CPU(Axion)에 액세스합니다. 이를 통해 처리량, 지연 시간 또는 TCO에 대한 특정 워크로드 요구사항에 따라 최적화할 수 있습니다.
선도적인 소프트웨어 및 개방형 프레임워크
- ML 프레임워크 및 라이브러리: PyTorch, JAX, TensorFlow, Keras, vLLM, JetStream, MaxText, LangChain, Hugging Face, NVIDIA(CUDA, NeMo, Triton), 기타 다양한 오픈소스 및 서드 파티 옵션
- 컴파일러, 런타임, 도구: XLA(성능 및 상호 운용성), Pathways on Cloud, 멀티슬라이스 학습, Cluster Toolkit(사전 빌드된 클러스터 청사진), 기타 다양한 오픈소스 및 서드 파티 옵션
- 조정: Google Kubernetes Engine(GKE), Cluster Director(Slurm, 비관리형 Kubernetes, BYO 스케줄러용), Google Compute Engine(GCE)
소비 모델:
- 주문형: 사용한 만큼만 지불합니다.
- 약정 사용 할인(CUD): 장기 약정 시 최대 70%까지 대폭 할인됩니다.
- 스팟 VM: 내결함성 일괄 작업에 적합하며 최대 91%의 높은 할인 혜택을 제공합니다.
- 동적 워크로드 스케줄러(DWS): 일괄/내결함성 작업의 비용을 최대 50% 절감할 수 있습니다.











