Exploring Google Cloud networking enhancements for generative AI applications
Anna Berenberg
Engineering Fellow, Google Cloud
Muninder Sambi
VP, PM and GM, Networking, Google Cloud
Many enterprises are exploring ways to incorporate the benefits of generative AI (gen AI) into their business. The 2023 Gartner® report We Shape AI, AI Shapes Us: 2023 IT Symposium/Xpo Keynote Insights, 16 October 2023 states that “most organizations are using, or plan to use, everyday AI to boost productivity. In the 2024 Gartner CIO and Technology Executive Survey, 80% of respondents said they are planning adoption of generative AI within three years.“1
Enterprises looking to deploy large language models (LLMs) face a unique set of networking challenges compared with serving traditional web applications. That’s because generative AI applications exhibit significantly different behavior versus most other web applications.
For example, web applications usually exhibit predictable traffic patterns, with requests and responses being processed in relatively small amounts of time, typically measured in milliseconds. In contrast, due to their multimodal nature, gen AI inference applications exhibit varying request/response times, which can present some unique challenges. At the same time, an LLM query can often consume 100% of a GPU’s or TPU’s compute time vs. more typical request processing that runs in parallel. Due to the computational cost, inference latencies range from seconds to minutes.
As a result, traditional round-robin or utilization-based traffic management techniques are not generally suited for gen AI applications. To achieve the best end-user experience for gen AI applications, and to gain efficient use of limited and costly GPU and TPU resources, we recently announced several new networking capabilities that optimize traffic for AI applications.
Many of these innovations are built into Vertex AI. Now, they are available in Cloud Networking so you can use them regardless of which LLM platform you choose.
Let’s take a deeper look.
1. Accelerated AI training and inference with Cross-Cloud Network
According to an IDC report, 66% of enterprises list generative AI and AI/ML workloads as one of their top use cases for using multi cloud networking.2 This is because the data required for model training / fine-tuning, retrieval-augmented generation (RAG), or grounding, resides in many disparate environments. This data needs to be remotely accessed or copied so it is accessible to LLM models.
Last year, we introduced Cross-Cloud Network, which provides service-centric, any-to-any connectivity built on Google's global network, making it easier to build and assemble distributed applications across clouds.
Cross-Cloud Network includes products that provide reliable, secure and SLA-backed cross-cloud connectivity for high-speed data transfer between clouds, helping to move the vast volumes of data required for gen AI model training. Products in the solution include Cross-Cloud Interconnect, which offers a managed interconnect with 10 Gbps or 100 Gbps bandwidth, backed with a 99.99% SLA and end-to-end encryption.
Besides secure and reliable data transfer for AI training, Cross-Cloud Network also lets customers run AI model inferencing applications across hybrid environments. For example, you may access models running in Google Cloud from application services running in another Cloud environment.
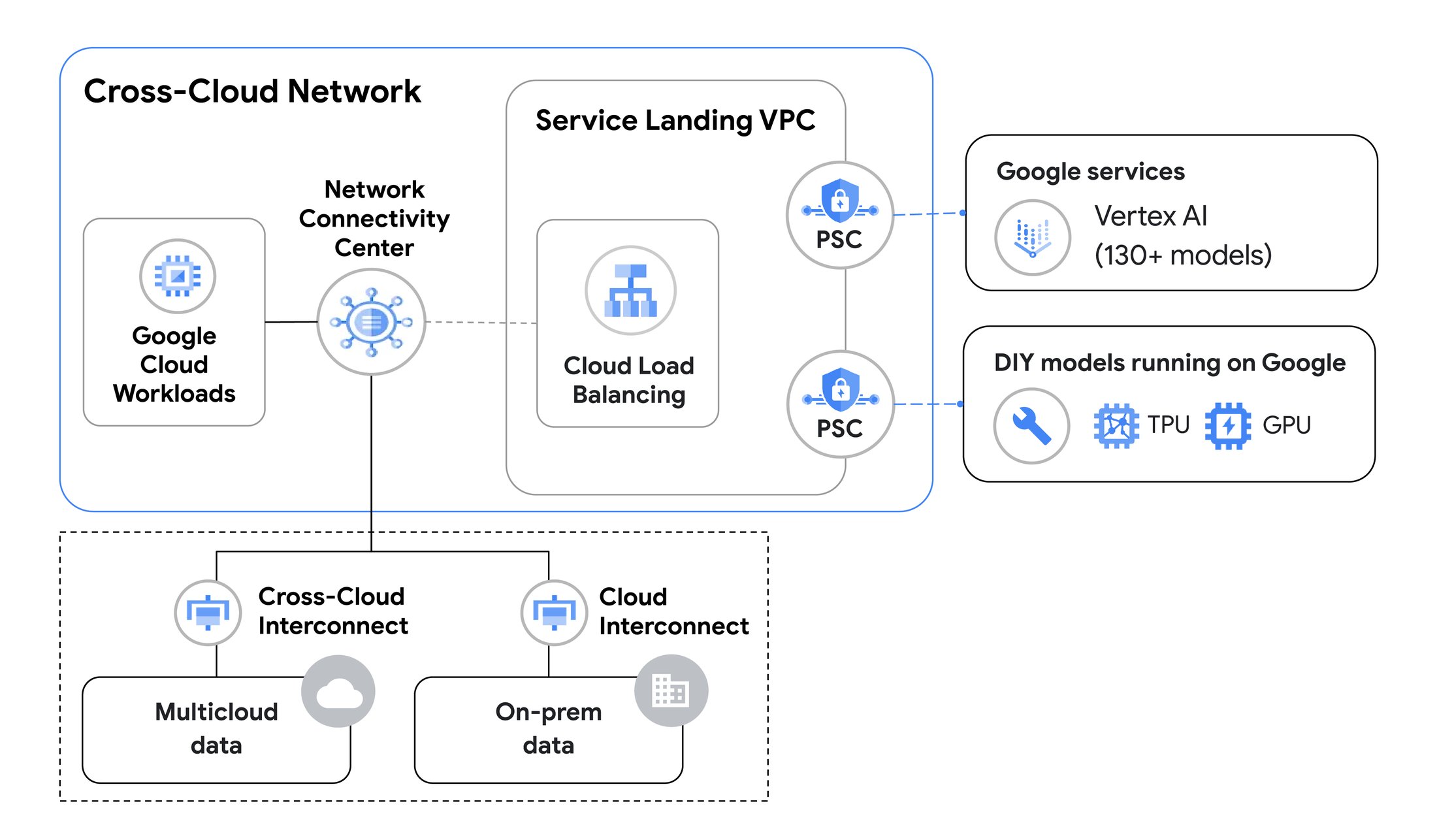
Cross Cloud Networking for gen AI training
2. Model as a Service Endpoint: a purpose-built solution for AI applications
The Model as a Service Endpoint is a solution to meet the unique requirements of AI inference applications. Due to the specialized nature of gen AI, in many organizations model creators present models as a service to be consumed by application development teams. The Model as a Service Endpoint is purpose-built to support this use case.
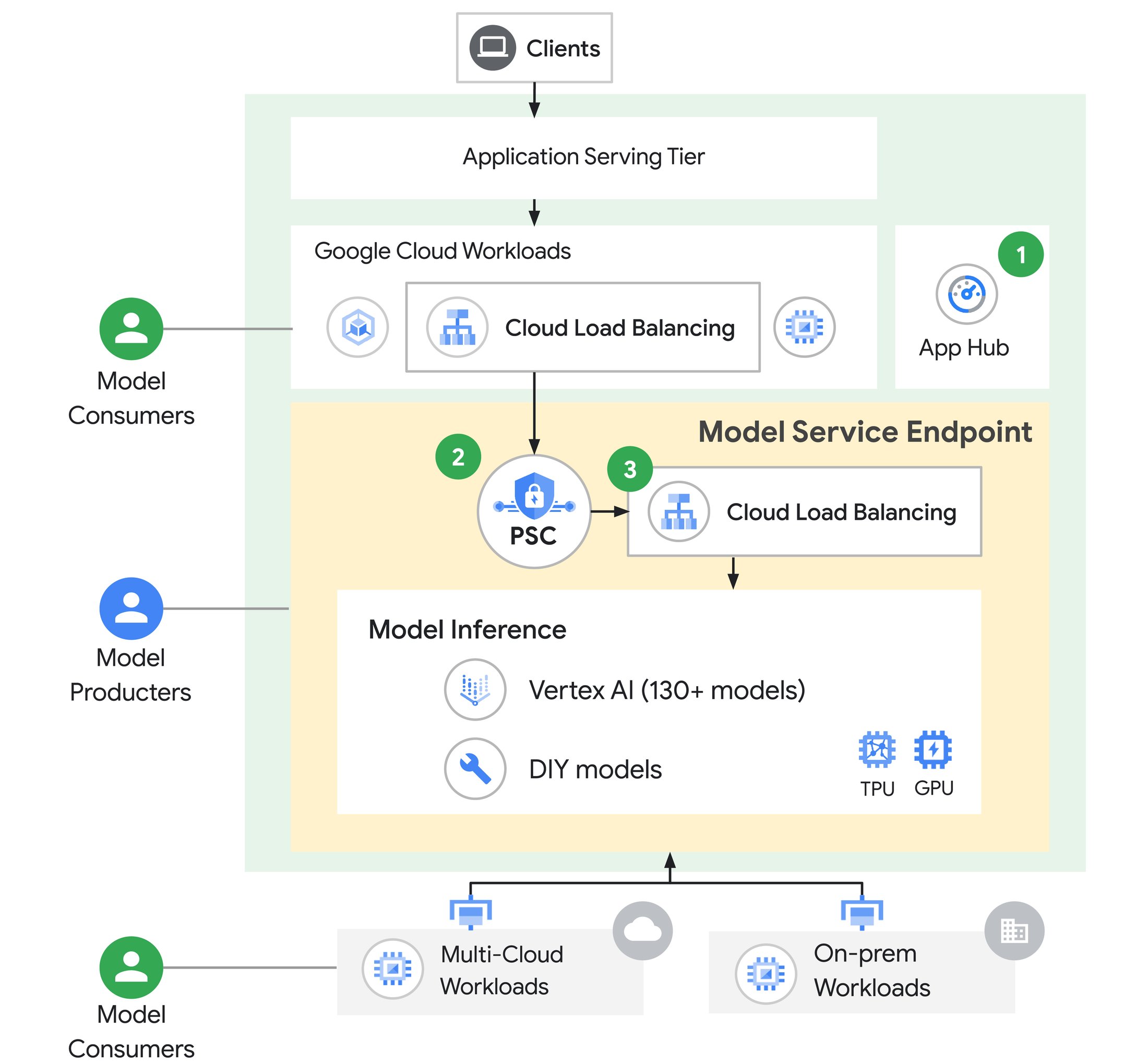
Model as a Service Endpoint
The Model as a Service Endpoint is an architectural best practice that is comprised of three major Cloud components:
-
App Hub recently launched to general availability. App Hub is a central place for tracking applications, services, and workloads across your Cloud projects. It maintains records of your services to enable their discoverability & reusability, including your AI applications and models.
-
Private Service Connect (PSC) for secure connectivity to AI models. This allows model producers to define a PSC service attachment that model consumers can connect to in order to access gen AI models for inference. The model producer defines policies on who can access the gen AI models. PSC also simplifies cross network access between consumer applications and producer models, including for consumers that reside outside Google Cloud.
-
Cloud Load Balancing includes several innovations to efficiently route traffic to LLMs, including a new AI-aware Cloud Load Balancing capability that optimizes traffic distribution to your models. These capabilities can be used by model producers as well as AI application developers, and are covered in the following sections of this blog.
3. Minimized inference latency with custom AI-aware load balancing
Many LLM applications use their own platform-specific queues to accept user prompts before processing them. To keep end-user response times consistent, LLM applications need queue depths for pending prompts to be as short as possible. To achieve this, requests should be distributed to LLM models based on the queue depth.
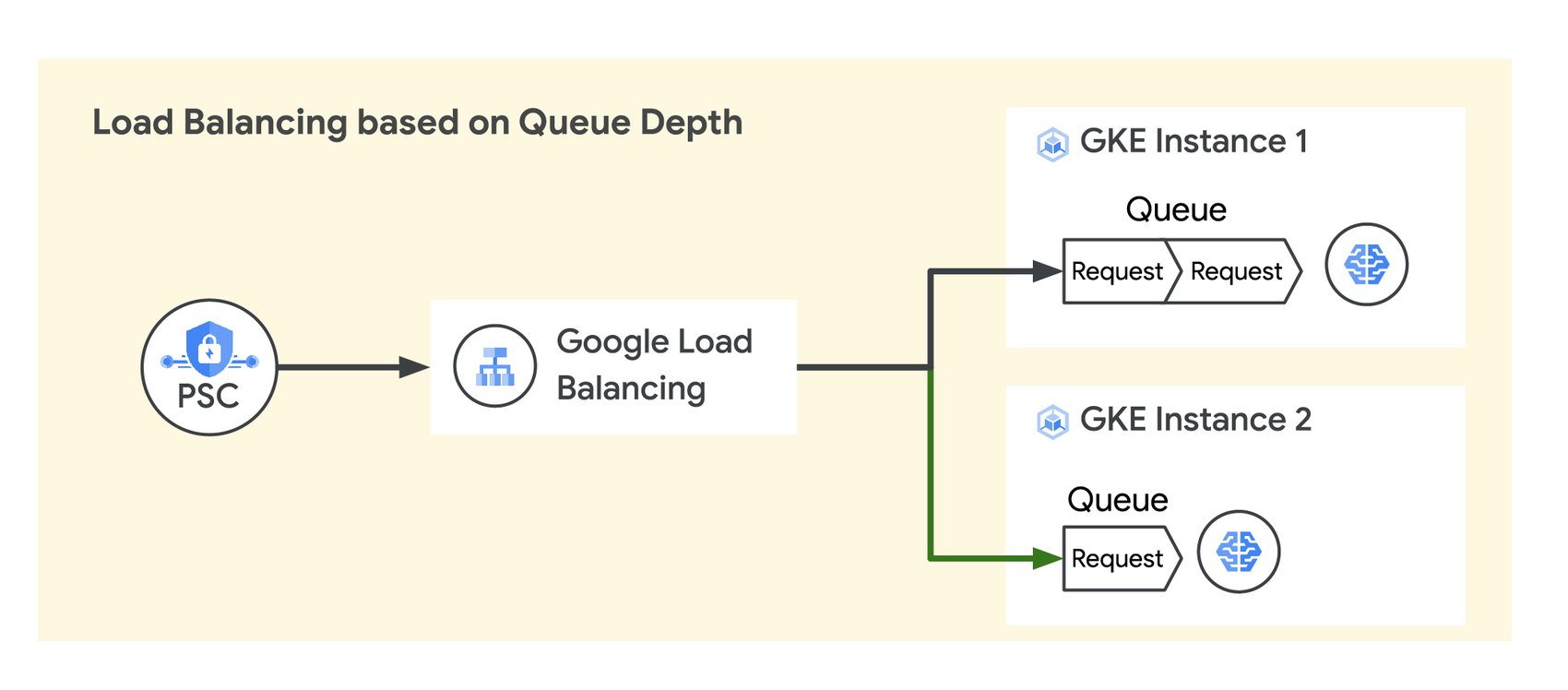
Traffic utilization based on queue depth
To enable traffic distribution to backend models based on LLM-specific metrics, e.g. queue depth, Cloud Load Balancing can now distribute traffic based on custom metrics. This capability allows application-level custom metrics to be reported to Cloud Load Balancing in response headers that use the Open Request Cost Aggregation (ORCA) standard. These metrics then influence traffic routing and backend scaling. For gen AI applications, the queue depth can be set as a custom metric, and traffic is automatically evenly distributed to keep queue depths as shallow as possible. This results in lower average and peak latency in inference serving. In fact, using the LLM queue depth as a key metric to distribute traffic can result in 5-10x improvement in latency for AI applications, as can be seen in this example demonstration. We’ll add traffic distribution based on custom metrics to Cloud Load Balancing later this year.
4. Optimized traffic distribution for AI inference applications
Google Cloud Networking has many built-in capabilities to enhance the reliability, efficacy, and efficiency of gen AI applications. Let’s take a look at these one by one.
Improving inference reliability.
Occasionally models become unavailable due to issues somewhere in the serving stack, and when this occurs the user experience suffers. To reliably serve users’ LLM prompts, traffic must be sent to models that are actively running and healthy. Cloud Networking has multiple solutions to support this:
-
Internal Application Load Balancer with Cloud health checks: For model producers, it is important that their model service endpoint maintains high availability. This is done by adding an Internal Application Load Balancer with Cloud health checks enabled to access individual model instances. The health of models is automatically monitored, and requests are routed only to healthy models.
-
Global load balancing with health checks: For model consumers, it is important to access model service endpoints that are available and running in close-proximity to client requests, for optimal latency. Many LLM stacks run within individual Google Cloud regions. To ensure requests are being directed to model service endpoints in healthy regions, you can use global load balancing with health checks to access individual model service endpoints. This routes traffic to the closest possible model service endpoint running in a healthy region. You can also extend this technique to work with clients or endpoints running outside of Google Cloud for multi-cloud or on-premises deployments.
-
Google Cloud Load Balancing weighted traffic splitting: To improve model efficacy, Google Cloud Load Balancing weighted traffic splitting enables portions of traffic to be diverted to different models or model versions. Using this technique, you may test the effectiveness of different models using A/B testing, or assure new model versions are working correctly as they are progressively being rolled out with blue/green deployments.
-
Load Balancing for Streaming: Gen AI requests can take highly variable amounts of time to process, sometimes taking seconds or minutes to execute. This is especially true when requests include images. To enable the best user experience and most efficient use of backend resources for long-running requests (> 10s), we recommend distributing traffic based on how many requests a backend can handle. The new Load Balancing for Streaming is specifically designed to optimize traffic for long-running requests, distributing traffic based on the number of streams an individual backend can process. Load Balancing for Streaming will be available in Cloud Load Balancing later this year.
5. Enhance gen AI serving with Service Extensions
Finally, we’re excited to announce that Service Extensions callouts for Google Cloud Application Load Balancers are now generally available, and will be available in Cloud Service Mesh later this year. Service Extensions allow integration of SaaS solutions or programmable customizations in the data path, for example to perform custom logging or header transformations.
Service Extensions can be used with gen AI applications in several ways to improve the user experience. For example, you can implement prompt blocking with Service Extensions, to prevent unwanted prompts from reaching the backend models and consuming scarce GPU and TPU processing time. You can also use Service Extensions to route requests to specific backend models based on which model is best suited to respond to the prompts. To do this, Service Extensions analyzes information in the request header, and determines the best model to serve the request.
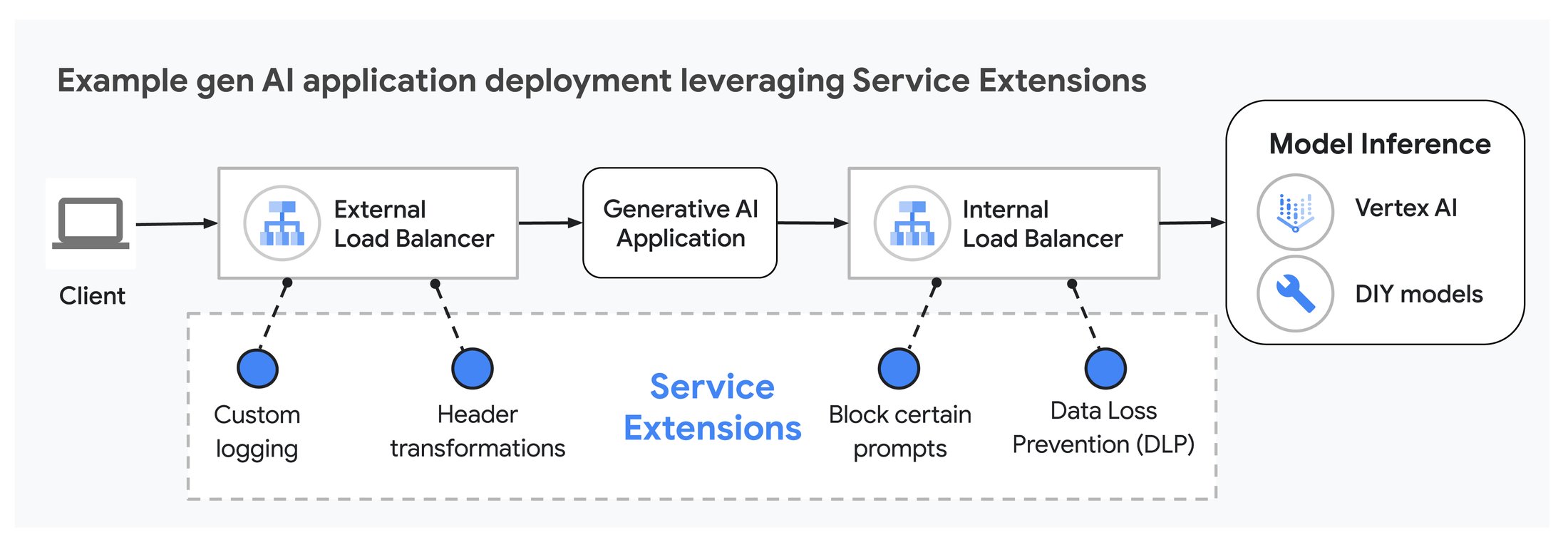
Service Extensions provide programmability in the AI application data path
Service Extensions callouts are customizable, so they can be programmed to the unique needs of your gen AI applications. You may read more about Service Extensions callouts for Cloud Load Balancing in our public documentation here.
"Google Cloud, combined with our custom software, provides a low-latency, high-reliability infrastructure for our platform to deliver the best performance and scale for our users. We are excited about Service Extensions callouts to help integrate and scale our software, unlock future data plane customizations, and enable developers to deploy AI-powered applications.” - Scott Kennedy, Head of Infrastructure, Replit.
Unlock the potential of gen AI with Google Cloud Networking
These innovations outlined here are a testament to our commitment to delivering cutting-edge solutions that empower businesses to unlock the full potential of AI. By leveraging Google Cloud's advanced suite of networking capabilities, we can help you address the unique challenges faced by AI applications.
1. We Shape AI, AI Shapes Us: 2023 IT Symposium/Xpo Keynote Insights, 16 October 2023. GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved
2. IDC, Multicloud Networking Starting to Inflect - Top Use Cases Include application and Business Resiliency, Improved Cybersecurity Posture, and Global-Scale Delivery of Internet-Facing Applications, Doc # US51795623, January 2024