Latih, sesuaikan, dan sajikan di superkomputer AI
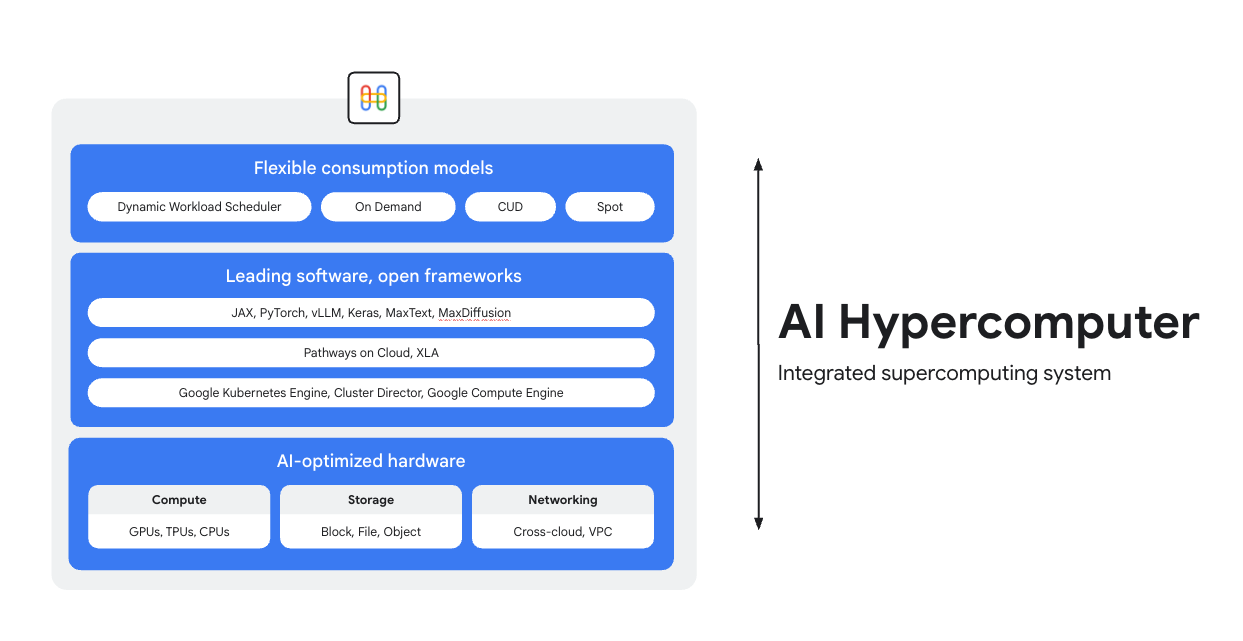
AI Hypercomputer adalah sistem superkomputer terintegrasi yang mendukung setiap workload AI di Google Cloud. Platform ini terdiri dari hardware, software, dan model konsumsi yang dirancang untuk menyederhanakan deployment AI, meningkatkan efisiensi tingkat sistem, dan mengoptimalkan biaya.
Ringkasan
Hardware yang dioptimalkan AI
Pilih berbagai opsi komputasi (termasuk akselerator AI), penyimpanan, dan jaringan yang dioptimalkan untuk tujuan tingkat workload yang terperinci, baik workload dengan throughput yang lebih tinggi, latensi yang lebih rendah, waktu penyiapan hasil yang lebih cepat, atau TCO yang lebih rendah. Pelajari lebih lanjut: Cloud TPU, GPU Cloud, serta yang terbaru dalam penyimpanan dan jaringan.
Software terkemuka, framework terbuka
Dapatkan hasil maksimal dari hardware Anda dengan software terkemuka di industri, yang terintegrasi dengan framework, library, dan compiler terbuka untuk membuat pengembangan, integrasi, dan pengelolaan AI menjadi lebih efisien.
- Dukungan untuk PyTorch, JAX, Keras, vLLM, Megatron-LM, NeMo Megatron, MaxText, MaxDiffusion, dan banyak lagi.
- Integrasi mendalam dengan compiler XLA memungkinkan interoperabilitas antara akselerator yang berbeda, sementara Pathways on Cloud memungkinkan Anda menggunakan runtime terdistribusi yang sama yang mendukung infrastruktur inferensi dan pelatihan berskala besar internal Google.
- Semua ini dapat di-deploy di lingkungan pilihan Anda, baik Google Kubernetes Engine, Cluster Director, maupun Google Compute Engine.
Model konsumsi yang fleksibel
Opsi konsumsi yang fleksibel memungkinkan pelanggan memilih biaya tetap dengan diskon abonemen atau model on-demand dinamis untuk memenuhi kebutuhan bisnis Anda. Dynamic Workload Scheduler dan Spot VM dapat membantu Anda mendapatkan kapasitas yang dibutuhkan tanpa alokasi berlebih. Selain itu, alat pengoptimalan biaya Google Cloud membantu mengotomatiskan penggunaan resource untuk mengurangi tugas manual bagi engineer.
Menyajikan model secara hemat biaya dalam skala besar
Memaksimalkan performa harga dan keandalan untuk workload inferensi
Inferensi dengan cepat menjadi lebih beragam dan kompleks, dan berkembang dalam tiga area utama:
- Pertama, cara kita berinteraksi dengan AI berubah. Percakapan kini memiliki konteks yang jauh lebih panjang dan beragam.
- Kedua, penalaran canggih dan inferensi multi-langkah membuat model Mixture-of-Experts (MoE) menjadi lebih umum. Hal ini mendefinisikan ulang cara memori dan komputasi diskalakan dari input awal hingga output akhir.
- Terakhir, jelas bahwa nilai sebenarnya bukan hanya tentang token mentah per dolar, tetapi kegunaan respons. Apakah model memiliki keahlian yang tepat? Apakah model menjawab pertanyaan bisnis penting dengan benar? Itulah sebabnya kami yakin pelanggan memerlukan pengukuran yang lebih baik, yang berfokus pada total biaya operasi sistem, bukan harga pemrosesnya.
Pelajari referensi Inferensi AI
- Apa itu inferensi AI? Panduan komprehensif kami tentang jenis, perbandingan, dan kasus penggunaan
- Jalankan resep inferensi praktik terbaik dengan Panduan Memulai Inferensi GKE
- Ikuti kursus tentang inferensi AI di Cloud Run
- Tonton video ini tentang rahasia inferensi AI yang hemat biaya
- Pelajari cara mempercepat workload inferensi AI
AI mengubah penggemar olahraga menjadi desainer kit
PUMA bekerja sama dengan Google Cloud pada infrastruktur AI terintegrasinya (AI Hypercomputer), sehingga mereka dapat menggunakan Gemini untuk menjalankan perintah pengguna bersama dengan Dynamic Workload Scheduler guna menskalakan inferensi secara dinamis pada GPU, yang mampu menghemat biaya dan waktu pembuatan secara signifikan.
Dampak:
- Mereka berhasil memangkas waktu pembuatan kit AI dari 2-5 menit menjadi hanya 30 detik. Hal ini mengubah platform menjadi pengalaman yang cepat dan benar-benar interaktif, yang membuat pengguna tetap aktif.
- Hanya dalam 10 hari, penggemar membuat 180.000 kit dan memberikan 1,7 juta rating.
- Project ini membuktikan cara baru bagi PUMA untuk terhubung dengan komunitasnya. PUMA berhasil mengubah penggemar menjadi rekan kreator aktif, sehingga melampaui hubungan brand-ke-konsumen yang sederhana. Hal ini memberi perusahaan insight langsung dan real-time tentang keinginan kreatif konsumennya yang paling antusias.



Petunjuk
Memaksimalkan performa harga dan keandalan untuk workload inferensi
Inferensi dengan cepat menjadi lebih beragam dan kompleks, dan berkembang dalam tiga area utama:
- Pertama, cara kita berinteraksi dengan AI berubah. Percakapan kini memiliki konteks yang jauh lebih panjang dan beragam.
- Kedua, penalaran canggih dan inferensi multi-langkah membuat model Mixture-of-Experts (MoE) menjadi lebih umum. Hal ini mendefinisikan ulang cara memori dan komputasi diskalakan dari input awal hingga output akhir.
- Terakhir, jelas bahwa nilai sebenarnya bukan hanya tentang token mentah per dolar, tetapi kegunaan respons. Apakah model memiliki keahlian yang tepat? Apakah model menjawab pertanyaan bisnis penting dengan benar? Itulah sebabnya kami yakin pelanggan memerlukan pengukuran yang lebih baik, yang berfokus pada total biaya operasi sistem, bukan harga pemrosesnya.
Referensi tambahan
Pelajari referensi Inferensi AI
- Apa itu inferensi AI? Panduan komprehensif kami tentang jenis, perbandingan, dan kasus penggunaan
- Jalankan resep inferensi praktik terbaik dengan Panduan Memulai Inferensi GKE
- Ikuti kursus tentang inferensi AI di Cloud Run
- Tonton video ini tentang rahasia inferensi AI yang hemat biaya
- Pelajari cara mempercepat workload inferensi AI
Contoh pelanggan
AI mengubah penggemar olahraga menjadi desainer kit
PUMA bekerja sama dengan Google Cloud pada infrastruktur AI terintegrasinya (AI Hypercomputer), sehingga mereka dapat menggunakan Gemini untuk menjalankan perintah pengguna bersama dengan Dynamic Workload Scheduler guna menskalakan inferensi secara dinamis pada GPU, yang mampu menghemat biaya dan waktu pembuatan secara signifikan.
Dampak:
- Mereka berhasil memangkas waktu pembuatan kit AI dari 2-5 menit menjadi hanya 30 detik. Hal ini mengubah platform menjadi pengalaman yang cepat dan benar-benar interaktif, yang membuat pengguna tetap aktif.
- Hanya dalam 10 hari, penggemar membuat 180.000 kit dan memberikan 1,7 juta rating.
- Project ini membuktikan cara baru bagi PUMA untuk terhubung dengan komunitasnya. PUMA berhasil mengubah penggemar menjadi rekan kreator aktif, sehingga melampaui hubungan brand-ke-konsumen yang sederhana. Hal ini memberi perusahaan insight langsung dan real-time tentang keinginan kreatif konsumennya yang paling antusias.
Menjalankan pelatihan dan prapelatihan AI berskala besar
Pelatihan AI yang andal, skalabel, dan efisien
Workload pelatihan perlu dijalankan sebagai tugas yang sangat tersinkronisasi di ribuan node dalam cluster yang terkait erat. Satu node yang rusak dapat mengganggu seluruh tugas, sehingga menunda waktu peluncuran produk. Anda harus:
- Memastikan cluster disiapkan dengan cepat dan disesuaikan untuk workload yang bersangkutan
- Memprediksi kegagalan dan memecahkannya dengan cepat
- Dan terus menjalankan workload, bahkan saat terjadi kegagalan
Kami ingin memudahkan pelanggan untuk men-deploy dan menskalakan workload pelatihan di Google Cloud.
Pelatihan AI yang andal, skalabel, dan efisien
Untuk membuat cluster AI, mulailah dengan salah satu tutorial kami:
- Membuat cluster Slurm dengan GPU (VM A4) dan Cluster Toolkit
- Membuat cluster GKE dengan Cluster Director untuk GKE atau Cluster Toolkit
Moloco membangun platform penayangan iklan untuk memproses miliaran permintaan setiap harinya
Moloco mengandalkan stack AI Hypercomputer yang terintegrasi sepenuhnya untuk menskalakan hardware canggih seperti TPU dan GPU secara otomatis, sehingga para engineer Moloco dapat berfokus pada hal yang lebih penting. Selain itu, integrasi dengan platform data terkemuka di industri Google menciptakan sistem end-to-end yang kohesif untuk workload AI.
Setelah meluncurkan model deep learning pertamanya, Moloco mengalami pertumbuhan dan profitabilitas yang pesat, dengan tumbuh sebesar 5 kali lipat dalam 2,5 tahun dan berhasil mencapainya.
- Pelatihan model 10x lebih cepat dengan Cloud TPU di GKE, serta penghematan biaya pelatihan sebesar 4x lipat
- Skala yang disesuaikan untuk melayani lebih dari 1.000 pengguna internal, memberi mereka akses ke sistem machine learning berskala global yang membantu mereka menemukan pertumbuhan yang menguntungkan dari data mereka sendiri


AssemblyAI
AssemblyAI menggunakan Google Cloud untuk melatih model dengan cepat dan dalam skala besar

LG AI Research memangkas biaya secara drastis dan mempercepat pengembangan sekaligus mematuhi persyaratan keamanan dan residensi data yang ketat

Anthropic mengumumkan rencana untuk mengakses hingga 1 juta TPU guna melatih dan menyajikan model Claude, yang bernilai puluhan miliar dolar. Namun, bagaimana cara mereka berjalan di Google Cloud? Tonton video ini untuk melihat cara Anthropic mendorong batas komputasi AI dalam skala besar dengan GKE.
Petunjuk
Pelatihan AI yang andal, skalabel, dan efisien
Workload pelatihan perlu dijalankan sebagai tugas yang sangat tersinkronisasi di ribuan node dalam cluster yang terkait erat. Satu node yang rusak dapat mengganggu seluruh tugas, sehingga menunda waktu peluncuran produk. Anda harus:
- Memastikan cluster disiapkan dengan cepat dan disesuaikan untuk workload yang bersangkutan
- Memprediksi kegagalan dan memecahkannya dengan cepat
- Dan terus menjalankan workload, bahkan saat terjadi kegagalan
Kami ingin memudahkan pelanggan untuk men-deploy dan menskalakan workload pelatihan di Google Cloud.
Referensi tambahan
Pelatihan AI yang andal, skalabel, dan efisien
Untuk membuat cluster AI, mulailah dengan salah satu tutorial kami:
- Membuat cluster Slurm dengan GPU (VM A4) dan Cluster Toolkit
- Membuat cluster GKE dengan Cluster Director untuk GKE atau Cluster Toolkit
Contoh pelanggan
Moloco membangun platform penayangan iklan untuk memproses miliaran permintaan setiap harinya
Moloco mengandalkan stack AI Hypercomputer yang terintegrasi sepenuhnya untuk menskalakan hardware canggih seperti TPU dan GPU secara otomatis, sehingga para engineer Moloco dapat berfokus pada hal yang lebih penting. Selain itu, integrasi dengan platform data terkemuka di industri Google menciptakan sistem end-to-end yang kohesif untuk workload AI.
Setelah meluncurkan model deep learning pertamanya, Moloco mengalami pertumbuhan dan profitabilitas yang pesat, dengan tumbuh sebesar 5 kali lipat dalam 2,5 tahun dan berhasil mencapainya.
- Pelatihan model 10x lebih cepat dengan Cloud TPU di GKE, serta penghematan biaya pelatihan sebesar 4x lipat
- Skala yang disesuaikan untuk melayani lebih dari 1.000 pengguna internal, memberi mereka akses ke sistem machine learning berskala global yang membantu mereka menemukan pertumbuhan yang menguntungkan dari data mereka sendiri
AssemblyAI
AssemblyAI menggunakan Google Cloud untuk melatih model dengan cepat dan dalam skala besar
LG AI Research memangkas biaya secara drastis dan mempercepat pengembangan sekaligus mematuhi persyaratan keamanan dan residensi data yang ketat
Anthropic mengumumkan rencana untuk mengakses hingga 1 juta TPU guna melatih dan menyajikan model Claude, yang bernilai puluhan miliar dolar. Namun, bagaimana cara mereka berjalan di Google Cloud? Tonton video ini untuk melihat cara Anthropic mendorong batas komputasi AI dalam skala besar dengan GKE.
Men-deploy dan mengorkestrasi aplikasi AI
Memanfaatkan software orkestrasi AI terkemuka dan framework terbuka untuk memberikan pengalaman yang didukung teknologi AI
Google Cloud menyediakan image yang berisi sistem operasi, framework, library, dan driver umum. AI Hypercomputer mengoptimalkan image yang telah dikonfigurasi sebelumnya ini untuk mendukung workload AI Anda.
- Framework dan library AI dan ML: Gunakan image Docker Deep Learning Software Layer (DLSL) untuk menjalankan model ML seperti NeMO dan MaxText di cluster Google Kubernetes Engine (GKE)
- Deployment cluster dan orkestrasi AI: Anda dapat men-deploy workload AI di cluster GKE, cluster Slurm, atau instance Compute Engine. Untuk informasi selengkapnya, lihat Ringkasan pembuatan VM dan cluster
Pelajari referensi software
- Pathways on Cloud adalah sistem yang dirancang untuk memungkinkan pembuatan sistem machine learning berskala besar, multi-tugas, dan diaktifkan secara tersebar
- Optimalkan produktivitas ML Anda dengan memanfaatkan resep Goodput kami
- Menjadwalkan workload GKE dengan Topology Aware Scheduling
- Coba salah satu resep tolok ukur kami untuk menjalankan model DeepSeek, Mixtral, Llama, dan GPT di GPU
- Pilih opsi konsumsi untuk mendapatkan dan menggunakan resource komputasi dengan lebih efisien
Priceline: Membantu wisatawan menyeleksi pengalaman unik
"Melalui kerja sama dengan Google Cloud untuk mengintegrasikan kemampuan AI generatif, kami dapat membuat asisten perjalanan khusus di dalam chatbot kami. Kami ingin agar pelanggan dapat melakukan lebih dari sekadar merencanakan perjalanan dan membantu mereka memilih pengalaman perjalanan yang unik.” Martin Brodbeck, CTO, Priceline




Petunjuk
Memanfaatkan software orkestrasi AI terkemuka dan framework terbuka untuk memberikan pengalaman yang didukung teknologi AI
Google Cloud menyediakan image yang berisi sistem operasi, framework, library, dan driver umum. AI Hypercomputer mengoptimalkan image yang telah dikonfigurasi sebelumnya ini untuk mendukung workload AI Anda.
- Framework dan library AI dan ML: Gunakan image Docker Deep Learning Software Layer (DLSL) untuk menjalankan model ML seperti NeMO dan MaxText di cluster Google Kubernetes Engine (GKE)
- Deployment cluster dan orkestrasi AI: Anda dapat men-deploy workload AI di cluster GKE, cluster Slurm, atau instance Compute Engine. Untuk informasi selengkapnya, lihat Ringkasan pembuatan VM dan cluster
Referensi tambahan
Pelajari referensi software
- Pathways on Cloud adalah sistem yang dirancang untuk memungkinkan pembuatan sistem machine learning berskala besar, multi-tugas, dan diaktifkan secara tersebar
- Optimalkan produktivitas ML Anda dengan memanfaatkan resep Goodput kami
- Menjadwalkan workload GKE dengan Topology Aware Scheduling
- Coba salah satu resep tolok ukur kami untuk menjalankan model DeepSeek, Mixtral, Llama, dan GPT di GPU
- Pilih opsi konsumsi untuk mendapatkan dan menggunakan resource komputasi dengan lebih efisien
Contoh pelanggan
Priceline: Membantu wisatawan menyeleksi pengalaman unik
"Melalui kerja sama dengan Google Cloud untuk mengintegrasikan kemampuan AI generatif, kami dapat membuat asisten perjalanan khusus di dalam chatbot kami. Kami ingin agar pelanggan dapat melakukan lebih dari sekadar merencanakan perjalanan dan membantu mereka memilih pengalaman perjalanan yang unik.” Martin Brodbeck, CTO, Priceline
FAQ
Bagaimana perbandingan AI Hypercomputer dengan penggunaan layanan cloud individual?
Meskipun masing-masing layanan menawarkan kemampuan spesifik, AI Hypercomputer menyediakan sistem terintegrasi yang dirancang agar hardware, software, dan model konsumsi dapat bekerja secara optimal bersama-sama. Integrasi ini memberikan efisiensi tingkat sistem dalam hal performa, biaya, dan waktu pemasaran yang lebih sulit dicapai dengan menggabungkan layanan yang berbeda-beda. Ini menyederhanakan kompleksitas dan memberikan pendekatan holistik terhadap infrastruktur AI.
Dapatkah AI Hypercomputer digunakan di lingkungan hybrid atau multicloud?
Ya, AI Hypercomputer dirancang dengan mempertimbangkan fleksibilitas. Teknologi seperti Cross-Cloud Interconnect menyediakan konektivitas bandwidth tinggi ke pusat data lokal dan cloud lainnya, sehingga memfasilitasi strategi AI hybrid dan multicloud. Kami beroperasi dengan standar terbuka dan mengintegrasikan software pihak ketiga yang populer untuk memungkinkan Anda membangun solusi yang mencakup berbagai lingkungan, dan mengubah layanan sesuai keinginan Anda.
Bagaimana AI Hypercomputer menangani keamanan untuk workload AI?
Keamanan adalah aspek inti dari AI Hypercomputer. AI Hypercomputer diuntungkan oleh model keamanan berlapis Google Cloud. Fitur spesifiknya mencakup mikrokontroler keamanan Titan (memastikan sistem melakukan booting dari status tepercaya), Firewall RDMA (untuk jaringan zero-trust antara TPU/GPU selama pelatihan), dan integrasi dengan solusi seperti Model Armor untuk keamanan AI. Hal ini dilengkapi dengan kebijakan dan prinsip keamanan infrastruktur yang kuat seperti Secure AI Framework.
Apa cara termudah untuk menggunakan AI Hypercomputer sebagai infrastruktur?
- Jika Anda tidak ingin mengelola VM, sebaiknya mulai dengan Google Kubernetes Engine (GKE)
- Jika Anda perlu menggunakan beberapa penjadwal, atau tidak dapat menggunakan GKE, sebaiknya gunakan Cluster Director
- Jika Anda menginginkan kontrol penuh atas infrastruktur Anda, satu-satunya cara untuk mencapainya adalah dengan bekerja langsung dengan VM, dan untuk itu Compute Engine adalah opsi terbaik Anda
Apakah hanya berguna untuk workload berskala besar/tinggi?
Tidak. AI Hypercomputer dapat digunakan untuk workload dengan ukuran apa pun. Workload berukuran lebih kecil tetap mendapatkan semua manfaat dari sistem terintegrasi, seperti efisiensi dan deployment yang disederhanakan. AI Hypercomputer juga mendukung pelanggan seiring dengan pertumbuhan bisnis mereka, mulai dari eksperimen dan bukti konsep kecil hingga deployment produksi skala besar.
Apakah AI Hypercomputer adalah cara termudah untuk memulai Workload AI di Google Cloud?
Bagi sebagian besar pelanggan, platform AI terkelola seperti Vertex AI adalah cara termudah untuk mulai menggunakan AI karena platform ini memiliki semua alat, template, dan model yang terintegrasi. Selain itu, Vertex AI didukung oleh AI Hypercomputer di balik layar dengan cara yang dioptimalkan untuk Anda. Vertex AI adalah cara termudah untuk memulai karena merupakan pengalaman yang paling sederhana. Jika Anda lebih suka mengonfigurasi dan mengoptimalkan setiap komponen infrastruktur, Anda dapat mengakses komponen AI Hypercomputer sebagai infrastruktur dan merakitnya sesuai kebutuhan Anda.
Karena AI Hypercomputer adalah sistem yang dapat disusun, ada banyak opsi. Apakah Anda memiliki praktik terbaik untuk setiap kasus penggunaan?
Ya, kami sedang membangun library resep di GitHub. Anda juga dapat menggunakan Cluster Toolkit untuk blueprint cluster yang telah dibuat sebelumnya.
Apa saja opsi yang tersedia saat saya menggunakan AI Hypercomputer sebagai IaaS?
Hardware yang dioptimalkan AI
Penyimpanan
- Pelatihan: Managed Lustre ideal untuk pelatihan AI yang menuntut dengan throughput tinggi dan kapasitas skala PB. GCS Fuse (opsional dengan Anywhere Cache) cocok untuk kebutuhan kapasitas yang lebih besar dengan latensi yang lebih fleksibel. Keduanya terintegrasi dengan GKE dan Cluster Director.
- Inferensi: GCS Fuse dengan Anywhere Cache menawarkan solusi sederhana. Untuk performa yang lebih tinggi, pertimbangkan Hyperdisk ML. Jika menggunakan Managed Lustre untuk pelatihan di zona yang sama, Managed Lustre juga dapat digunakan untuk inferensi.
Jaringan
- Pelatihan: Manfaatkan teknologi seperti jaringan RDMA di VPC, serta Cloud dan Cross-Cloud Interconnect bandwidth tinggi untuk transfer data yang cepat.
- Inferensi: Manfaatkan solusi seperti GKE Inference Gateway dan Cloud Load Balancing yang ditingkatkan untuk inferensi dengan latensi rendah. Model Armor dapat diintegrasikan untuk keamanan dan keselamatan AI.
Komputasi: Akses TPU Google Cloud (Trillium), GPU NVIDIA (Blackwell), dan CPU (Axion). Hal ini memungkinkan pengoptimalan berdasarkan kebutuhan workload tertentu untuk throughput, latensi, atau TCO.
Software dan framework terbuka yang terkemuka
- Framework dan Library ML: PyTorch, JAX, TensorFlow, Keras, vLLM, JetStream, MaxText, LangChain, Hugging Face, NVIDIA (CUDA, NeMo, Triton), dan banyak lagi opsi open source dan pihak ketiga.
- Compiler, Runtime, dan Alat: XLA (untuk performa dan interoperabilitas), Pathways on Cloud, Multislice Training, Cluster Toolkit (untuk blueprint cluster bawaan), dan banyak lagi opsi open source dan pihak ketiga.
- Orkestrasi: Google Kubernetes Engine (GKE), Cluster Director (untuk Slurm, Kubernetes yang tidak terkelola, penjadwal BYO), dan Google Compute Engine (GCE).
Model konsumsi:
- On Demand: Bayar sesuai penggunaan.
- Diskon Abonemen (DA): Hemat secara signifikan (hingga 70%) untuk komitmen jangka panjang.
- Spot VM: Ideal untuk tugas batch fault-tolerant, dan menawarkan diskon besar (hingga 91%).
- Dynamic Workload Scheduler (DWS): Hemat hingga 50% untuk tugas batch/fault-tolerant.











