将 Aurora 迁移到 Cloud SQL for MySQL 之前需要注意的重要事项
Amazon 的 AWS 和 Google Cloud 均提供基于云端的全托管式 MySQL 数据库服务。两种云服务提供商在各自的默认配置中都有独特的功能和差异。在从一个提供商迁移到另一个提供商后,这些差异可能会导致意外的性能或操作问题。本文将总结此类迁移过程中可能出现的问题及其推荐的解决方案。本文将重点论述从 Aurora MySQL 迁移到 Cloud SQL for MySQL 的 MySQL 数据库服务迁移。
迁移注意事项
字符集:性能问题
Aurora 使用默认字符集服务器 latin1(直到 MySQL v5.7 为止)。这与 Cloud SQL for MySQL 对数据库、表、存储过程和函数的默认配置不同,后者在迁移过程中使用 utf8 作为默认字符集创建。这可能会导致出现性能问题的情况。
例如,用户可能会遇到这样一种情况:使用 latin1 字符集创建表,使用 Cloud SQL 默认 utf8 字符集创建存储过程或函数。在这种情况下,如果存储过程或函数需要变量作为 utf8 参数,并将该变量与 latin1 字符集中的列值进行比较,则会因为两种不同字符集和排序规则的比较而导致性能问题。
您可以使用以下命令检查例程的字符集:
mysql> select ROUTINE_NAME, ROUTINE_SCHEMA, CHARACTER_SET_NAME, COLLATION_NAME from information_schema.ROUTINES;
如果您使用的是 Aurora(直到 v5.7)中的默认字符集 latin1,则应在导入数据之前在 Cloud SQL 中将默认字符集从 utf8 更改为 latin1。
另一种解决方案可能是将所有字符集更改为 utf8,但在这种情况下,用户应测试完整的应用和数据集,因为对字符集的更改可能会导致意外的数据表示。
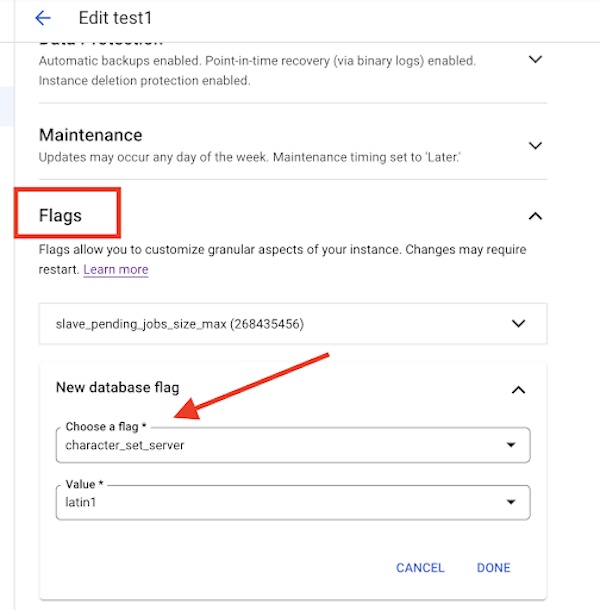
用户可以在 Cloud SQL 实例中的标志部分下修改此设置,如下图所示。
字符集:不兼容问题
Aurora MySQL 5.7 提供了许多排序规则(例如用于字符集 utf8mb4 的 utf8mb4_0900_ai_ci),这些排序规则目前仅在 Cloud SQL for MySQL 8.0 中提供。如果您使用任何此类排序规则并在 Cloud SQL for MySQL 5.7 中导入数据,则会收到类似“字符集‘#255’不是已编译的字符集”的错误消息。
解决方案是将这些排序规则更改为 MySQL 5.7 版中的可用排序规则。
存储引擎:所有表都必须位于 InnoDB 中
与 Aurora 不同,Cloud SQL for MySQL 不支持 MyISAM 引擎。建议您先将所有表转换为 InnoDB,然后再开始从 Aurora 迁移到 Cloud SQL。
如果 InnoDB 以外的引擎中存在表,用户可以使用“ALTER”命令更改表的引擎:
mysql> alter table table_1 engine='Innodb' ;
查询正常,0 行受到影响(2.89 秒)
记录:0 重复:0 警告:0
注意:查询时间取决于表的大小,而且可能会锁定对同一表的其他操作。您还可以使用在线架构更改工具(如 pt-online-schema-change 或 gh-ost)在不阻止其他操作的情况下更改表。
用于读取连接的端点
在 Aurora 中,用户可以在单个端点后面设置多个读取器,但 Cloud SQL for MySQL 用户没有这种开箱即用的功能。Cloud SQL for MySQL 中的每个读取副本都有自己的 IP 地址,用户需要使用 ProxySQL 等将流量拆分到多个读取副本实例。
Aurora 没有更改缓冲区
更改缓冲区是一种特殊的数据结构,当二级索引页面不在缓冲区池中时,会将其更改缓存起来,然后在这些页面通过其他读取操作加载到缓冲区池时将其合并。如需了解详情,请参阅更改缓冲区。
在工作负载对具有二级索引的表执行大量写入操作的用例中,Aurora 的执行速度可能比 Cloud SQL for MySQL 慢,后者使用默认的 InnoDB 更改缓冲区功能将更新推迟到后续阶段。用户应根据其应用工作负载对性能进行基准测试。
查询缓存可能会影响性能
查询缓存将 select 命令及其结果存储在中间存储层。如果稍后收到相同的语句,服务器将检查查询缓存并从中检索结果,而不会再次执行该命令。查询缓存在会话之间共享,因此所有会话都可以从其他会话中已执行的语句缓存的结果中受益。详细了解查询缓存。
Aurora 默认启用查询缓存,但是,MySQL 社区在 5.7 版本中停用了查询缓存,而在 8.0 版本中将其彻底移除,Cloud SQL MySQL 也是这样。如果您的查询依赖于 Aurora 的查询缓存功能,则 Cloud SQL MySQL 中的性能可能会有所不同。建议通过将执行时间与 Aurora 进行比较来测试您在 Cloud SQL MySQL 中的查询性能。
复制机制可能会影响性能
对于一个区域内的读取副本,Aurora 使用集群卷的概念,即在该区域内的三个可用性区域中备有数据的副本。Aurora 的复制延迟时间通常不到 100 毫秒,因为同一数据库集群中的主实例和副本都会将集群卷中的数据视为一个逻辑卷。此外,对于跨区域读取副本,Aurora 使用基于磁盘的跨区域数据同步,而不是基于二进制日志的复制。
简而言之,复制由 Aurora 中的存储层处理,而在 Cloud SQL for MySQL 中,标准复制机制是将二进制日志转移到副本实例,然后在副本 MySQL 实例中重放这些日志。我们可以通过在 Cloud SQL 中配置并行复制来提高复制性能。阅读详细了解如何设置并行复制功能。
虽然复制延迟时间取决于应用和网络在主实例和副本实例之间更改的数据量,但大多数应用都可以在 Aurora 和 Cloud SQL for MySQL 中正常运行,而不会出现明显的延迟。但是,如果是写入密集型应用,且该应用从副本读取数据,我们建议在迁移之前对 AWS Aurora 和 CloudSQL MySQL 中的复制延迟进行基准比较。
基于全局事务标识符 (GTID) 的复制
Cloud SQL for MySQL 使用 GTID 复制,这与 AWS Aurora 使用基于磁盘的数据同步不同。用户应在迁移前检查下面列出的 GTID 的限制,如果应用工作流依赖于这些功能中的任何一个,则在其应用中进行任何必要的更改:
- 使用基于 GTID 的复制时,不允许使用 CREATE TABLE ... SELECT 语句。
- 事务、过程、函数和触发器不支持 CREATE TEMPORARY TABLE 和 DROP TEMPORARY TABLE 语句。您可以在启用 GTID 的情况下使用这些语句,但只能在事务之外使用,并且只能在 autocommit=1 时使用。
如需详细了解基于 GTID 的限制,请参阅 GTID 中的限制。
相关产品和服务
Google Cloud 提供旨在满足您业务需求的托管式 MySQL 数据库,可以完成包括弃用本地数据中心、运行 SaaS 应用和迁移核心业务系统在内的各种任务。


















