Consideraciones importantes antes de la migración de Aurora a Cloud SQL para MySQL
AWS de Google y Google Cloud de Amazon proporcionan servicios de bases de datos MySQL completamente administrados basados en la nube. Ambos proveedores de servicios en la nube tienen características y diferencias únicas en sus respectivas configuraciones predeterminadas. Estas diferencias pueden conducir a problemas inesperados de rendimiento o de funcionamiento después de una migración de un proveedor a otro. En este artículo, se proporciona un resumen de los problemas que pueden surgir durante esta migración y sus soluciones recomendadas. En particular, nos enfocaremos en las migraciones de los servicios de bases de datos de MySQL de Aurora MySQL a Cloud SQL para MySQL.
Consideraciones sobre la migración
Grupo de caracteres: problema de rendimiento
Aurora usa el servidor de grupos de caracteres predeterminado de latin1 (hasta MySQL v. 5.7). Esto es diferente de la configuración predeterminada de Cloud SQL para MySQL para bases de datos, tablas, procedimientos almacenados y funciones, que se crean con utf8 como el grupo de caracteres predeterminado durante una migración. Esto puede provocar situaciones que generen problemas de rendimiento.
Por ejemplo, un usuario puede terminar en una situación en la que las tablas se crean con el grupo de caracteres latin1 y los procedimientos o funciones almacenados se crean con el grupo de caracteres utf8 predeterminado de Cloud SQL. En tales casos, si el procedimiento almacenado o la función esperan variables como parámetros utf8 y compara esa variable con el valor de la columna, que está en el grupo de caracteres latin1, se generarán problemas de rendimiento porque de la comparación de dos grupos de caracteres y intercalaciones diferentes.
Puedes verificar el grupo de caracteres de las rutinas con el siguiente comando:
mysql> selecciona ROUTINE_NAME, ROUTINE_SCHEMA, CHARACTER_SET_NAME, COLLATION_NAME de information_schema.ROUTINES;
Si usabas el grupo de caracteres predeterminado en Aurora (hasta el v5.7) que es latin1, entonces el grupo de caracteres predeterminado debería cambiarse de utf8 a latin1 en Cloud SQL antes de importar los datos.
Otra solución podría ser cambiar todo a utf8. Sin embargo, en este caso, los usuarios deben probar la aplicación y el conjunto de datos completos, ya que los cambios en el grupo de caracteres pueden generar representaciones inesperadas de datos.
Los usuarios pueden editar esta configuración en la instancia de Cloud SQL en la sección de marcas como se ilustra a continuación.
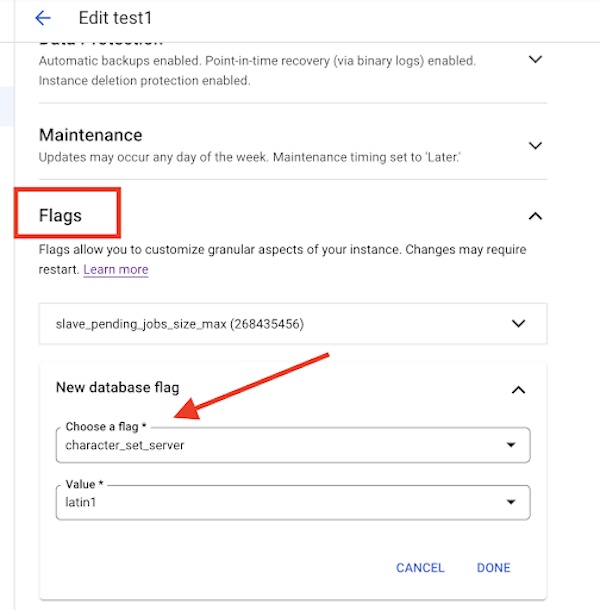
Grupo de caracteres: problema de incompatibilidad
Aurora MySQL 5.7 tiene muchas intercalaciones (por ejemplo, utf8mb4_0900_ai_ci para el conjunto de caracteres utf8mb4) que, por el momento, solo están disponibles en Cloud SQL para MySQL 8.0. Si usas alguna intercalación de ese tipo y, además, importas los datos en Cloud SQL para MySQL 5.7, recibirás un mensaje de error como “Error 'El grupo de caracteres '#255' no es un grupo de caracteres compilados'”. de Google Analytics.
La solución es cambiar esas intercalaciones a las intercalaciones disponibles en la versión 5.7 de MySQL.
Motor de almacenamiento: todas las tablas deben estar en InnoDB
A diferencia de Aurora, Cloud SQL para MySQL no es compatible con el motor MyISAM. Se recomienda convertir todas las tablas a InnoDB antes de comenzar la migración de Aurora a Cloud SQL.
Si existe una tabla en un motor que no sea InnoDB, los usuarios pueden cambiar el motor de la tabla con el comando “ALTER”:
mysql> alter table table_1 engine='Innodb' ;
Query OK, 0 rows affected (2.89 sec)
Records: 0 Duplicates: 0 Warnings: 0
Nota: El tiempo de la búsqueda depende del tamaño de la tabla y es posible que bloquee otras operaciones en la misma tabla. También puedes usar herramientas de cambios de esquema en línea, como pt-online-schema-change o gh-ost para modificar la tabla sin bloquear otras operaciones.
Extremos para conexiones de lectura
En Aurora, los usuarios pueden configurar varios lectores en un único extremo. Sin embargo, los usuarios de Cloud SQL para MySQL no tienen esta función lista para usar. Cada réplica de lectura en Cloud SQL para MySQL tiene su propia IP y los usuarios deben usar algo como ProxySQL para dividir el tráfico entre varias instancias de réplica de lectura.
Aurora no tiene un búfer de cambio.
El búfer de cambio es una estructura de datos especial que almacena en caché los cambios en las páginas de índice secundarias cuando esas páginas no están en el grupo de búferes y se combinan más tarde cuando otras páginas las cargan en el grupo de búferes. Para obtener más información, consulta Cómo cambiar el búfer.
Para el caso práctico en el que la carga de trabajo tiene muchas escrituras en las tablas con índices secundarios, Aurora puede funcionar más lento que Cloud SQL para MySQL, que usa la función de búfer de cambio de InnoDB predeterminada para diferir esas actualizaciones a más adelante. Los usuarios deben comparar el rendimiento según la carga de trabajo de su aplicación.
La caché de la consulta puede afectar el rendimiento
La caché de consultas almacena el comando de selección junto con su resultado en una capa de almacenamiento intermedio. Si se recibe una declaración idéntica más adelante, el servidor verifica y recupera los resultados de la caché de la consulta en lugar de ejecutar ese comando nuevamente. La caché de consultas se comparte entre sesiones, por lo que todas las sesiones pueden beneficiarse de los resultados almacenados en caché por las declaraciones ya ejecutadas de otras sesiones. Obtén más información sobre la caché de consultas.
Aurora habilita la caché de consultas de forma predeterminada. Sin embargo, la comunidad de MySQL inhabilitó la caché de consultas en la versión 5.7 y la quitó por completo en la versión 8.0. Cloud SQL MySQL también hizo lo mismo. Si tus consultas dependen de la característica de caché de consultas de Aurora, el rendimiento puede variar en MySQL de Cloud SQL. Se recomienda que pruebes el rendimiento de tus consultas en MySQL de Cloud SQL mediante la comparación del tiempo de ejecución con Aurora.
El mecanismo de replicación puede afectar el rendimiento
Para las réplicas de lectura dentro de una región, Aurora usa el concepto de volumen de clústeres que tiene copias de los datos en tres zonas de disponibilidad dentro de esa región. El retraso de replicación en Aurora suele ser de menos de 100 milisegundos porque la instancia principal y las réplicas dentro del mismo clúster de base de datos ven los datos del volumen de clúster como un solo volumen lógico. Además, para la réplica de lectura entre regiones, Aurora usa la sincronización de datos basada en disco entre regiones en lugar de la replicación basada en registros binarios.
En resumen, la replicación se maneja con la capa de almacenamiento en Aurora, mientras que en Cloud SQL para MySQL, el mecanismo de replicación estándar de la transferencia del registro binario a la instancia de réplica y, a continuación, vuelve a reproducir esos registros en la réplica Se usan las instancias de MySQL. Podemos mejorar el rendimiento de la replicación si configuras la replicación paralela en Cloud SQL. Lee los detalles sobre la configuración de la replicación paralela.
Aunque el retraso de replicación depende de la cantidad de datos que cambiaron la aplicación y la red entre la instancia principal y la réplica, la mayoría de las aplicaciones funcionan bien sin un retraso notable en Aurora y Cloud SQL para MySQL. Sin embargo, si la aplicación tiene mucha escritura y la aplicación lee desde las réplicas, sugerimos comparar el retraso de replicación en AWS Aurora y Cloud SQL MySQL antes de la migración.
Replicación basada en identificador de transacciones globales (GTID)
A diferencia de AWS Aurora, que usa la sincronización de datos basada en disco, Cloud SQL para MySQL usa la replicación GTID. Antes de migrar, los usuarios deben verificar las limitaciones de GTID que se enumeran a continuación y hacer los cambios necesarios en sus aplicaciones si el flujo de trabajo de la aplicación depende de alguna de esas funciones:
- Las instrucciones CREATE TABLE…SELECT no están permitidas cuando se usa la replicación basada en GTID.
- Las instrucciones CREATE TEMPORARY TABLE y DROP TEMPORARY TABLE no son compatibles con transacciones, procedimientos, funciones y activadores. Es posible usar estas declaraciones con GTID habilitados, pero solo fuera de cualquier transacción y solo con autocommit=1.
Para obtener más información sobre las limitaciones basadas en GTID, consulta Limitaciones en GTID.
Productos y servicios relacionados
Google Cloud ofrece una base de datos administrada de MySQL que se adapta a las necesidades de tu empresa, desde la eliminación de tu centro de datos local hasta la ejecución de aplicaciones SaaS y la migración de los sistemas empresariales principales.
Da el siguiente paso
Comienza a desarrollar en Google Cloud con el crédito gratis de $300 y los más de 20 productos del nivel Siempre gratuito.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos


















