このドキュメントでは、Monitoring Query Language(MQL)を例を挙げて説明します。ただしこのページは、この言語のすべての側面を説明するものではありません。Monitoring Query Language リファレンスに、MQL の詳細が記載されています。
MQL ベースのアラート ポリシーの情報については、MQL のアラート ポリシーをご覧ください。
特定のクエリをさまざまな形式で記述できます。言語は柔軟で、構文に慣れると、さまざまなショートカットが使用できるようになります。詳細については、厳密な形式のクエリをご覧ください。
準備
Metrics Explorer の使用時にコードエディタにアクセスするには、次の手順を行います。
-
Google Cloud コンソールで、[leaderboardMetrics Explorer] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] である結果を選択します。
- クエリビルダー ペインのツールバーで、[codeMQL] または [codeMQL] という名前のボタンを選択します。
- [MQL] 切り替えで [MQL] が選択されていることを確認します。言語切り替えボタンは、クエリの書式設定を行うのと同じツールバーにあります。
クエリを実行するには、クエリをエディタに貼り付けて、[クエリを実行] をクリックします。このエディタの概要については、MQL に対してコードエディタを使用するをご覧ください。
指標タイプ、モニタリング対象リソースタイプ、時系列など、Cloud Monitoring のコンセプトを十分に理解していると役立ちます。これらのコンセプトの概要については、指標、時系列、リソースをご覧ください。
データモデル
MQL クエリは Cloud Monitoring 時系列データベース内のデータを取得して操作します。このセクションでは、そのデータベースに関連するいくつかのコンセプトと用語を紹介します。詳細については、リファレンス トピックのデータモデルをご覧ください。
すべての時系列は 1 つのタイプのモニタリング対象リソースから発生し、1 つの指標タイプのデータを収集します。モニタリング対象リソース記述子によって、モニタリング対象リソースタイプが定義されます。同様に、指標記述子によって指標タイプが定義されます。たとえば、リソースタイプが gce_instance(Compute Engine 仮想マシン(VM))で、指標タイプが compute.googleapis.com/instance/cpu/utilization(Compute Engine VM の CPU 使用率)であるとします。
これらの記述子では、指標タイプまたはリソースタイプの他の属性に関する情報の収集に使用されるラベルのセットも指定します。たとえば、通常、リソースには zone ラベルが付けられ、リソースの地理的位置の記録に使用されます。
指標記述子とモニタリング対象リソース記述子のペアからラベルの値の組み合わせごとに 1 つの時系列が作成されます。
リソースタイプに使用可能なラベルは、モニタリング対象リソースのリストで見つけることができます(例: gce_instance)。指標タイプのラベルを見つけるには、指標の一覧(Compute Engine の指標など)をご覧ください。
Cloud Monitoring データベースは、特定の指標タイプとリソースタイプのすべての時系列を 1 つのテーブルに保存します。指標タイプとリソースタイプは、テーブルの識別子として機能します。以下の MQL クエリは、Compute Engine インスタンスの CPU 使用率を記録する時系列のテーブルをフェッチします。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
テーブルには、指標とリソースラベルの値の一意の組み合わせごとに時系列が 1 つあります。
MQL クエリは、これらのテーブルから時系列データを取得し、出力テーブルに変換します。これらの出力テーブルは、他のオペレーションに渡すことができます。たとえば、取得したテーブルを filter オペレーションへの入力として渡すことで、特定のゾーンまたはゾーンのセットのリソースによって書き込まれた時系列を分離できます。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
上記のクエリは、us-central で始まるゾーンのリソースからの時系列のみを含むテーブルになります。
MQL クエリは、1 つのオペレーションの出力を入力として次のオペレーションに渡すように構造化されます。このテーブルベースの方法では、オペレーションをリンクして、フィルタリング、選択、内部結合や外部結合などの他の使い慣れたデータベース オペレーションで、このデータを操作できます。データが、あるオペレーションから別のオペレーションに渡される際に、時系列内のデータに対してさまざまな関数を実行することもできます。
Monitoring Query Language リファレンスに、MQL で使用できるオペレーションと関数の詳細が記載されています。
クエリの構造
1 つのクエリは、1 つ以上のオペレーションで構成されます。オペレーションはリンクされるかパイプで渡されるため、オペレーションの出力は次のオペレーションの入力になります。そのため、クエリの結果はオペレーションの順序によって異なります。例として、次のような操作を行うことができます。
fetchまたはその他の選択オペレーションでクエリを開始する。- 複数のオペレーションをパイプでつないだクエリを作成する。
filterオペレーションに関する情報のサブセットを選択する。- 関連情報を
group_byオペレーションで集計する。 topオペレーションとbottomオペレーションで外れ値を確認する。- 複数のクエリを
{ ; }およびjoinオペレーションで組み合わせる。 valueオペレーションと関数を使用して、比率やその他の値を計算する。
すべてのクエリがこれらのオプションのすべてを使用するわけではありません。
これらの例では、使用可能なオペレーションと関数の一部のみを紹介しています。MQL クエリの構造の詳細については、リファレンス トピックのクエリ構造をご覧ください。
これらの例では、期間とアライメントを指定しません。以降のセクションで、その理由を説明します。
期間
コードエディタを使用する場合は、グラフの設定によりクエリの期間が定義されます。デフォルトでは、グラフの期間は 1 時間に設定されます。
グラフの期間を変更するには、期間範囲セレクタを使用します。たとえば、過去 1 週間のデータを表示する場合は、時間範囲セレクタから [過去 1 週間] を選択します。開始時間と終了時間を指定したり、表示時間を指定することもできます。
コードエディタでの期間の詳細については、期間、グラフ、コードエディタをご覧ください。
配置
これらの例で使用されているオペレーションの多く(join オペレーションや group_by オペレーションなど)は、定期的に発生するテーブル内のすべての時系列ポイントに依存します。すべてのポイントを定期的なタイムスタンプに揃える動作を、アライメントといいます。通常、アライメントは暗黙のうちに行われますが、ここで紹介する例ではそのようなことはありません。
必要に応じて、MQL では join オペレーションと group_by オペレーション用にテーブルが自動的に配置されますが、MQL では明示的に配置することもできます。
アライメントのコンセプトの一般的な情報については、アライメント: 系列内集計をご覧ください。
MQL でのアライメントの詳細については、リファレンス トピックのアライメントをご覧ください。アライメントは、
alignおよびeveryオペレーションを使用して明示的に制御できます。
データを取得してフィルタする
MQL クエリは、データの取得と選択、フィルタリングから始まります。このセクションでは、MQL を使用した基本的な取得とフィルタリングについて説明します。
時系列データを取得する
クエリは、常に fetch オペレーションで始まり、Cloud Monitoring から時系列を取得します。
最も単純なクエリは、単一の fetch オペレーションと、取得する時系列を識別する引数で構成されます。次に例を示します。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
引数は、モニタリング対象リソースタイプ gce_instance、2 つのコロン文字 ::、および指標タイプ compute.googleapis.com/instance/cpu/utilization で構成されます。
このクエリは、Compute Engine インスタンスによって書き込まれた指標タイプ compute.googleapis.com/instance/cpu/utilization の時系列を取得し、それらのインスタンスの CPU 使用率を記録します。
Metrics Explorer のコードエディタからクエリを実行すると、リクエストされた各時系列を示すグラフを取得します。
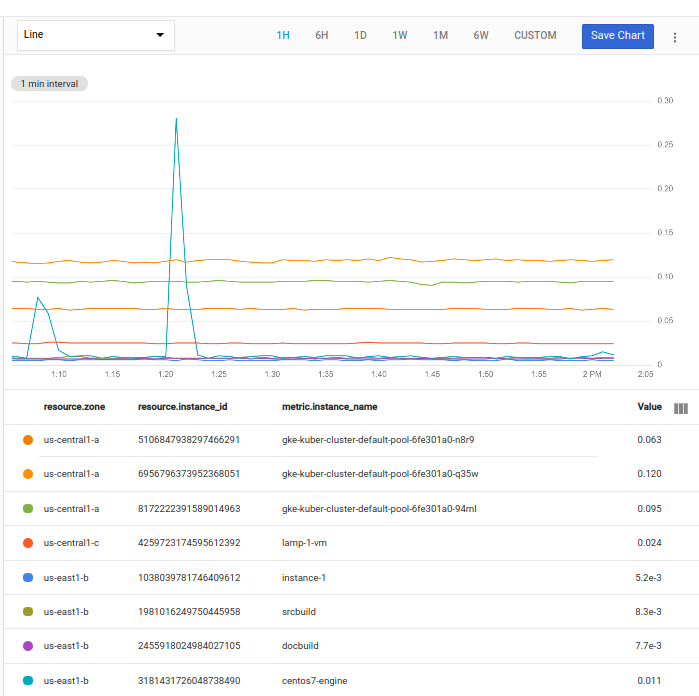
リクエストされた各時系列は、グラフ上に線で表示されます。各時系列には、このプロジェクトにある 1 つの VM インスタンスの CPU 使用率指標からのタイムスタンプ値のリストが含まれます。
Cloud Monitoring が使用するバックエンド ストレージでは、時系列がテーブルに保存されます。fetch オペレーションでは、指定されたモニタリング対象リソースと指標タイプの時系列がテーブルに整理され、そのテーブルが返されます。返されたデータはグラフに表示されます。
fetch オペレーションとその引数については、fetch リファレンス ページをご覧ください。オペレーションによって生成されるデータの詳細については、時系列とテーブルのリファレンス ページをご覧ください。
オペレーションをフィルタ
通常、クエリは、複数のオペレーションの組み合わせで構成されます。最も簡単な組み合わせは、パイプ演算子 | を使用して、あるオペレーションの出力を次のオペレーションの入力にパイプすることです。次の例では、パイプを使用してテーブルをフィルタ オペレーションに入力しています。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter instance_name =~ 'gke.*'
このクエリは、前の例で示した fetch オペレーションによって返されたテーブルをブール値に評価する式として受け取る filter オペレーションにパイプで渡します。この例での式は、「instance_name が gke で始まる」という意味です。
filter オペレーションは入力テーブルを取得し、フィルタが false である時系列を削除し、結果のテーブルを出力します。次のスクリーンショットは、結果のグラフを示しています。
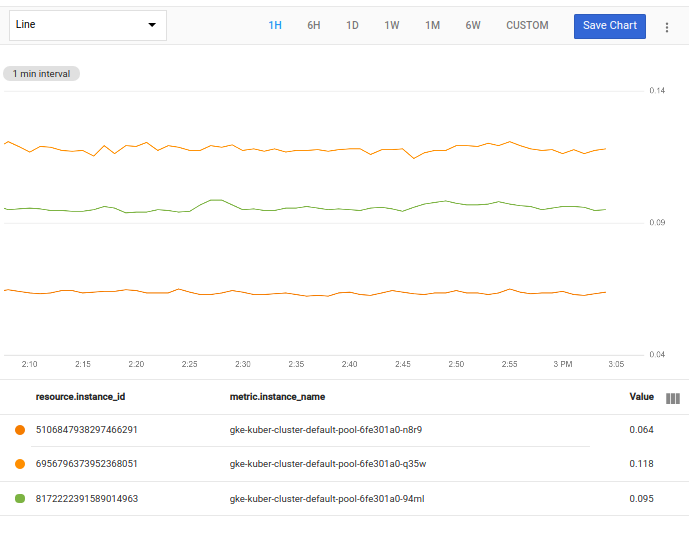
gke で始まるインスタンス名がない場合は、このクエリを試す前にフィルタを変更します。たとえば、名前の先頭に apache が付いた VM インスタンスがある場合は、次のフィルタを使用します。
| filter instance_name =~ 'apache.*'
filter 式は、入力時系列ごとに 1 回評価されます。式が true として評価されると、その時系列が出力に含まれます。この例では、フィルタ式は、各時系列の instance_name ラベルで正規表現 =~ を照合します。ラベルの値が正規表現 'gke.*' と一致する場合、出力には時系列が含まれます。そうでない場合、時系列は出力から削除されます。
フィルタリングの詳細については、filter リファレンス ページをご覧ください。filter 述語は、ブール値を返す任意の式です。詳細については、式をご覧ください。
グループ化と集計
グループ化を行うと、特定のディメンションに沿って時系列をグループ化できます。集計は、グループ内のすべての時系列を 1 つの出力時系列に結合したものです。
次のクエリは、最初の fetch オペレーションの出力をフィルタリングして、us-central で始まるゾーンのリソースからの時系列のみを保持します。次に、時系列をゾーン別にグループ化し、mean 集計を使用してそれらを結合します。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
| group_by [zone], mean(val())
group_by オペレーションの結果テーブルには、ゾーンごとに 1 つの時系列があります。次のスクリーンショットは、結果のグラフを示しています。
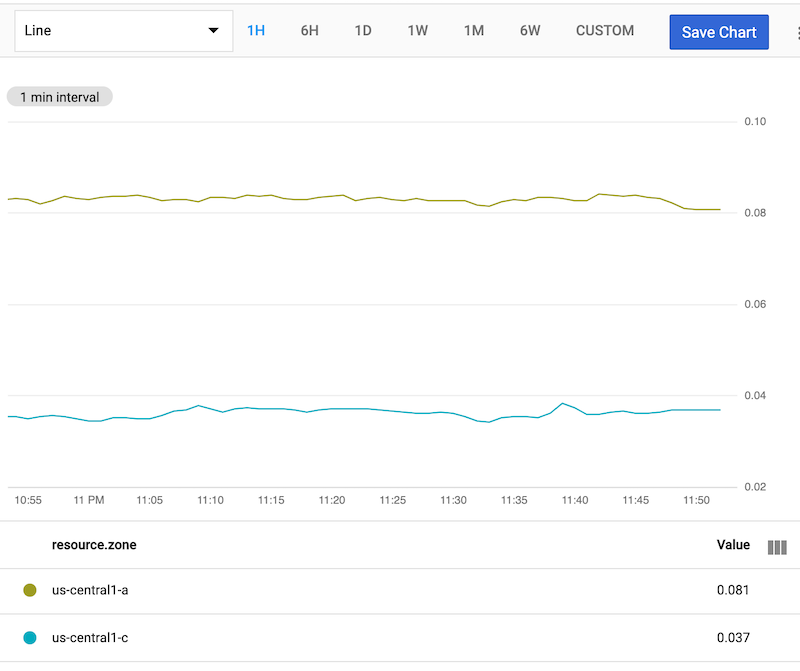
group_by オペレーションでは、2 つの引数をカンマ(,)で区切って指定します。これらの引数によって、グループ化の正確な動作が決まります。この例では、group_by [zone], mean(val()) は次のように機能します。
最初の引数
[zone]は、時系列のグループ化を決定する「マップ式」です。この例では、グループ化に使用するラベルを指定しています。グループ化の手順では、同じ出力zone値を持つすべての入力時系列を 1 つのグループに収集します。この例では、式により 1 つのゾーン内で Compute Engine VM から時系列が収集されます。出力時系列には
zoneラベルのみがあり、グループ内の入力時系列からコピーされた値が含まれます。入力時系列のその他のラベルが出力時系列から削除されます。マップ式は、リストラベル以外にも機能します。詳細については、
mapリファレンス ページをご覧ください。第 2 の引数(
mean(val()))は、各グループの時系列を 1 つの出力時系列に結合(集約)する仕組みを定めます。グループの出力時系列の各ポイントは、グループ内のすべての入力時系列から同じタイムスタンプを持つポイントを集約した結果です。集計関数(この例では
mean)によって、集計値が決まります。val()関数によって集計するポイントが返され、そのポイントに集計関数が適用されます。この例では、各出力時点でのゾーン内の仮想マシンの CPU 使用率の平均値を取得します。式
mean(val())は、集計式の例です。
group_by オペレーションは常にグループ化と集計を組み合わせます。グループ化を指定し、集計引数を省略すると、group_by はデータ型に適切な関数を選択するデフォルトの集計 aggregate(val()) を使用します。デフォルトの集計関数のリストについては、aggregate をご覧ください。
ログベースの指標で group_by を使用する
次のような文字列を含む長い一連のエントリから、処理されたデータポイントの数を抽出するために、分布ログベースの分布指標を作成したとします。
... entry ID 1 ... Processed data points 1000 ... ... entry ID 2 ... Processed data points 1500 ... ... entry ID 3 ... Processed data points 1000 ... ... entry ID 4 ... Processed data points 500 ...
処理されたすべてのデータポイントの数を示す時系列を作成するには、次のような MQL を使用します。
fetch global
| metric 'logging.googleapis.com/user/metric_name'
| group_by [], sum(sum_from(value))
ログベースの分布指標を作成するには、分布指標を構成するをご覧ください。
グループから列を除外する
マッピングで drop 修飾子を使用すると、グループから列を除外できます。たとえば、Kubernetes の core_usage_time 指標には 6 つの列があります。
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by [project_id, location, cluster_name, namespace_name, container_name]
pod_name をグループ化する必要がない場合は、drop を使用して除外できます。
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by drop [pod_name]
時系列の選択
このセクションの例では、入力テーブルから特定の時系列を選択する方法を紹介します。
上位または下位の時系列を選択する
プロジェクト内の CPU 使用率が最も高い 3 つの Compute Engine インスタンスの時系列データを表示するには、次のクエリを入力します。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3
次のスクリーンショットは、1 つのプロジェクトの結果を示しています。
CPU 使用率が最も低い時系列を取得するには、top を bottom に置き換えます。
top オペレーションは、入力テーブルから選択された時系列の指定した数を含むテーブルを出力します。出力に含まれる時系列は、ある局面で最大の値を持っています。
このクエリでは、時系列を並べ替える方法を指定していないため、最新のポイントが最も大きい値の時系列が返されます。どの時系列が最も大きい値かを決める方法を指定するには、top オペレーションに引数を指定します。たとえば、前述のクエリは、次のクエリと同等です。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, val()
val() 式は、適用される各時系列の最新のポイントの値を選択するため、クエリは最新のポイントの値が最も大きいものを返します。
時系列の一部またはすべてのポイントで集計を行う式を指定して、ソート値を指定できます。以下は、過去 10 分間のすべてのポイントの平均を取得します。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, mean(val()).within(10m)
within 関数を使用しない場合、mean 関数は時系列に表示されているすべてのポイントの値に適用されます。
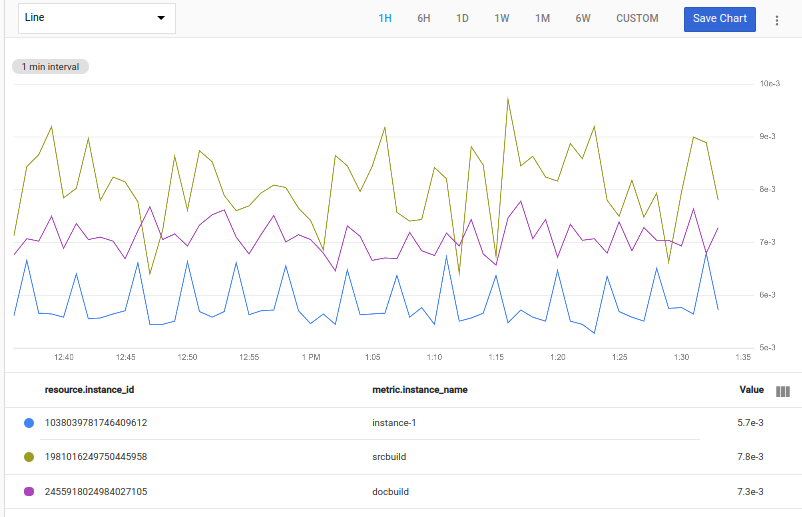
bottom オペレーションも同様に機能します。次のクエリは、max(val()) で各時系列の最大のポイントの値を検索します。それからその値が最小の 3 つの時系列を選択します。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| bottom 3, max(val())
次のスクリーンショットは、スパイクが最も少ないストリームを表示するグラフを示しています。
時系列の上位または下位の n 件の結果を除外する
多数の Compute Engine VM インスタンスがあるシナリオについて考えてみましょう。これらのインスタンスの一部では、大半のインスタンスよりも多くのメモリを消費するため、これらの外れ値により、大規模なグループでの使用パターンを確認するのが難しくなります。CPU 使用率グラフは次のようになります。
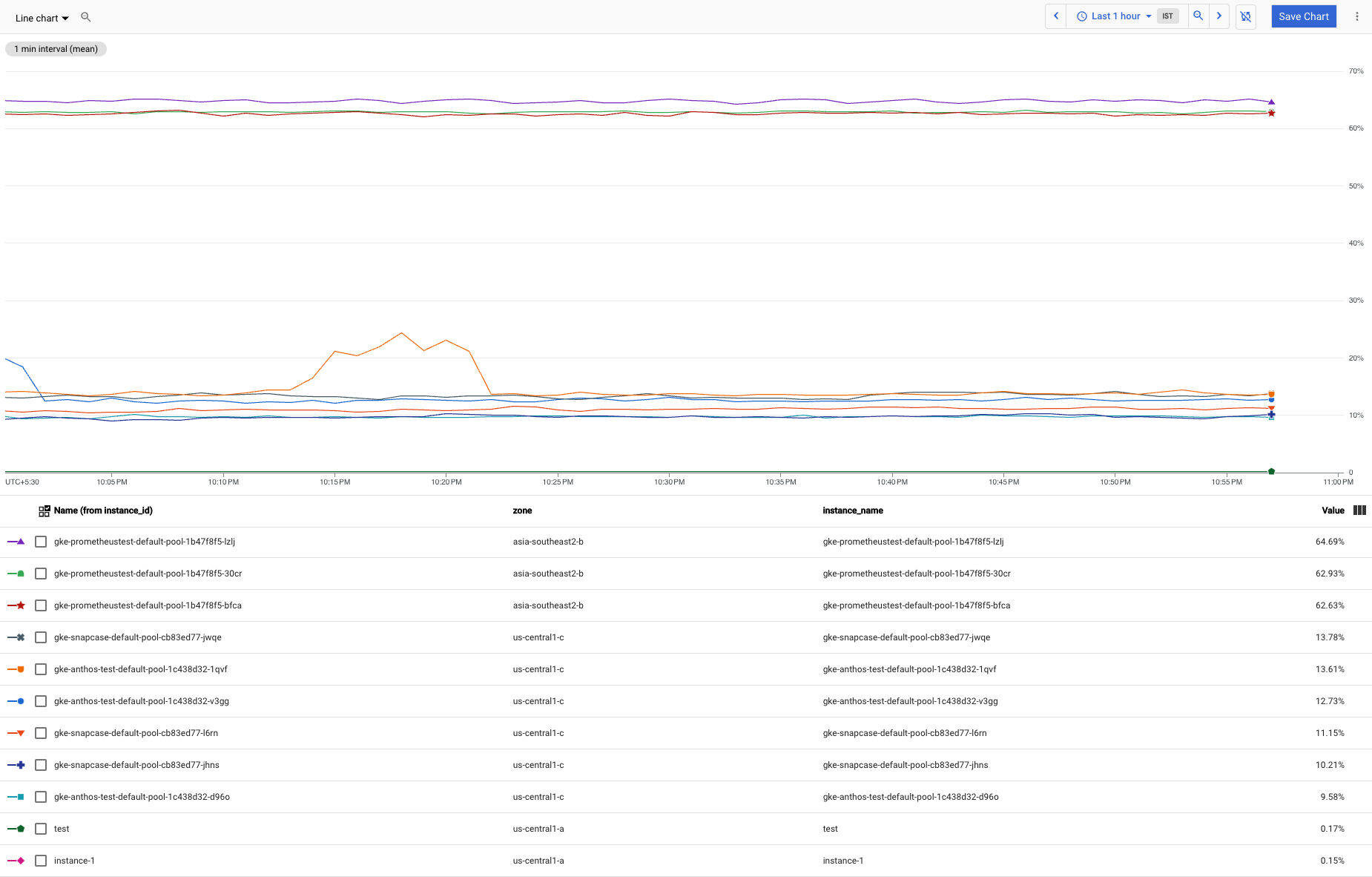
グラフから 3 つの外れ値を除外して、大規模なグループでのパターンをより明確に確認できるようにします。
Compute Engine の CPU 使用率の時系列を取得するクエリで上位 3 つの時系列を除外するには、top テーブル オペレーションを使用して時系列を識別し、outer_join テーブル オペレーションを使用して、識別された時系列を結果から除外します。次のクエリを使用できます。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 3 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
fetch オペレーションは、すべてのインスタンスからの CPU 使用率の時系列のテーブルを返します。このテーブルが処理されて次の 2 つのテーブルになります。
top nテーブル オペレーションは、値が高い上位 n 件の時系列を含むテーブルを出力します。この場合、n = 3 です。結果のテーブルには、除外する 3 つの時系列が含まれています。上位 3 つの時系列を含むテーブルは、
valueテーブル オペレーションにパイプされます。このオペレーションにより、上位 3 つのテーブルの各時系列に別の列が追加されます。この列is_default_valueには、上位 3 つのテーブルのすべての時系列に対してブール値falseが設定されます。identオペレーションは、パイプされた同じテーブル(CPU 使用率の時系列の元のテーブル)を返します。このテーブルの時系列にはis_default_value列はありません。
上位 3 つのテーブルと元のテーブルが outer_join テーブル オペレーションにパイプされます。上位 3 つのテーブルは結合の左側のテーブルで、取得されたテーブルは結合の右側のテーブルです。外部結合は、結合される行に存在しないフィールドの値として、値 true を指定するように設定されています。外部結合の結果は、値 false を持つ列 is_default_value を保持する上位 3 つのテーブルの行と、値 true を持つ列 is_default_value を保持する上位 3 つのテーブルにも含まれていない元のテーブルのすべての行がマージされたテーブルになります。
その後結合の結果のテーブルが filter テーブル オペレーションに渡され、is_default_value 列に false の値を持つ行が除外されます。結果のテーブルには、上位 3 つのテーブルの行を除いた、最初に取得されたテーブルの行が含まれます。このテーブルには、目的の時系列セットに加え、is_default_column が追加されています。
最後のステップは、結合によって追加された列 is_default_column を削除することです。これにより、出力テーブルには最初に取得されたテーブルと同じ列が含まれます。
次のスクリーンショットは、前のクエリのグラフを示しています。
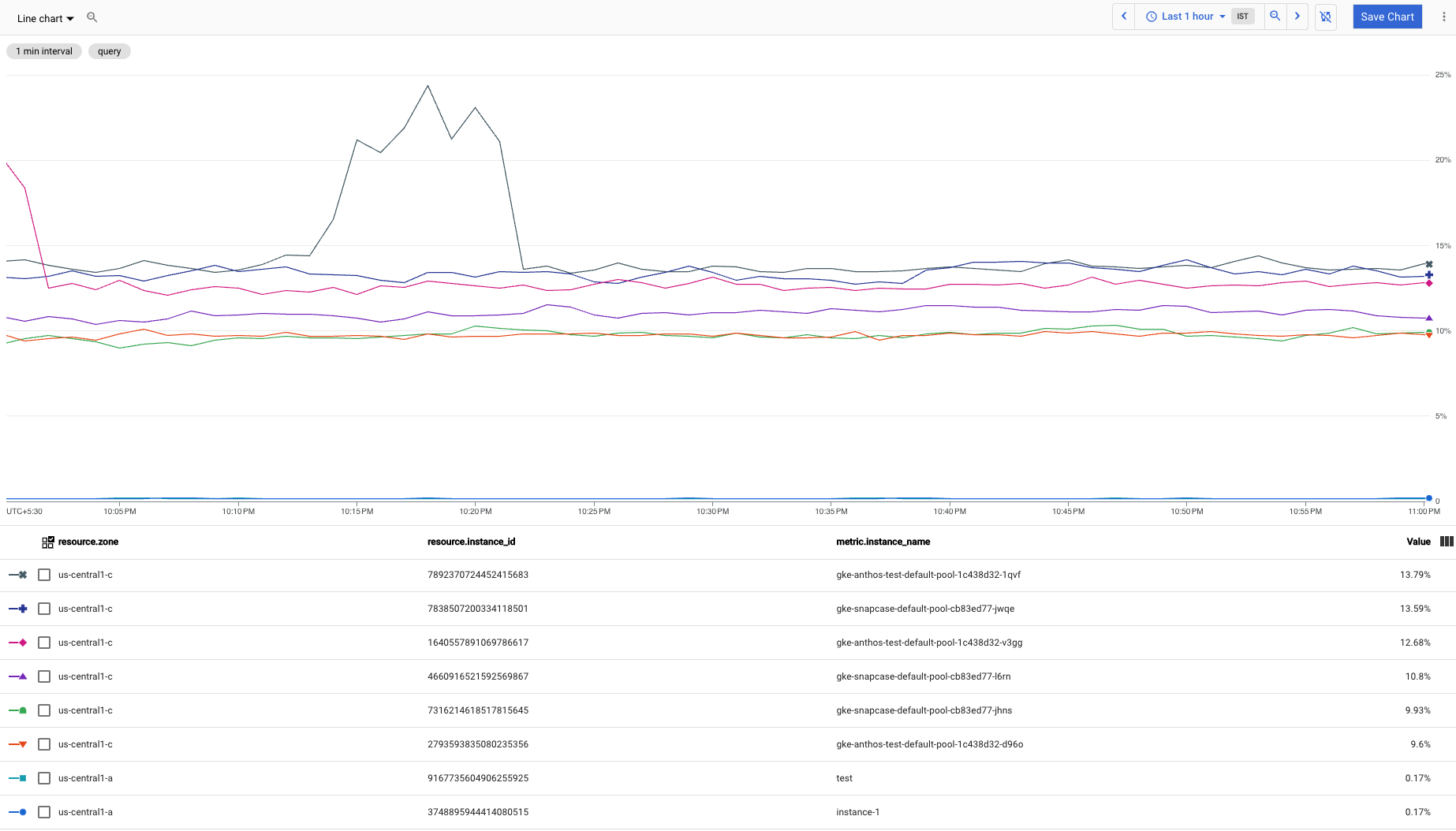
CPU 使用率が最も低い時系列を除外するクエリを作成するには、top n を bottom
n に置き換えます。
外れ値を除外する機能は、アラートを設定するものの、外れ値によって常にアラートがトリガーされないようにする場合に役立ちます。 次のアラートクエリは、前のクエリと同じ除外ロジックを使用して、上位 2 つの Pod を除外してから一連の Kubernetes Pod による CPU の使用率の上限をモニタリングします。
fetch k8s_container
| metric 'kubernetes.io/container/cpu/limit_utilization'
| filter (resource.cluster_name == 'CLUSTER_NAME' &&
resource.namespace_name == 'NAMESPACE_NAME' &&
resource.pod_name =~ 'POD_NAME')
| group_by 1m, [value_limit_utilization_max: max(value.limit_utilization)]
| {
top 2 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
| every 1m
| condition val(0) > 0.73 '1'
グループの上位または下位を選択する
top テーブル オペレーションと bottom テーブル オペレーションは、入力テーブル全体から時系列を選択します。top_by オペレーションと bottom_by オペレーションは、時系列をテーブルにグループ化し、各グループからいくつかの時系列を選択します。
次のクエリは、ピーク値が最も大きい各ゾーンの時系列を選択します。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 1, max(val())
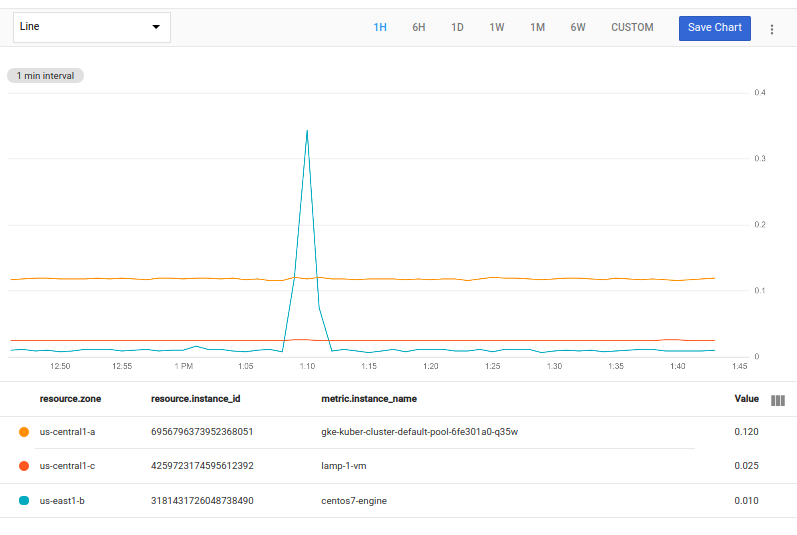
[zone] 式は、zone 列の値が同じ時系列からなるグループであることを示します。top_by の 1 は、各ゾーンのグループから選択する時系列の数を示します。max(val()) 式は、各時系列でグラフの時間範囲の最大値を探します。
max の代わりに、任意の集計関数を使用できます。たとえば、次の例では mean アグリゲータを使用し、within を使用して 20 分の並べ替えの範囲を指定しています。各ゾーンの上位 2 つの時系列が選択されます。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 2, mean(val()).within(20m)
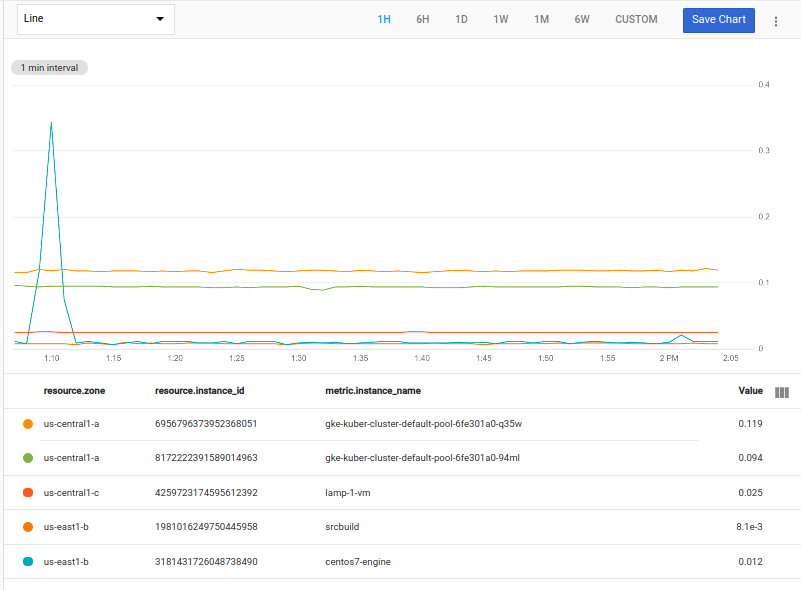
上に示した例では、ゾーン us-central-c にはインスタンスが 1 つのみ存在するため、返されるのは 1 つの時系列のみです。グループ内に「上位 2 つの時系列」は存在しません。
選択を union で組み合わせる
top や bottom のような選択操作を組み合わせて、両方を表示するグラフを作成できます。たとえば、次のクエリでは、最大値を持つ単一の時系列と最小値を持つ単一の時系列が返されます。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 1, max(val())
;
bottom 1, min(val())
}
| union
結果のグラフには、最も高い値を含む線と最も低い値を含む線の 2 つが表示されます。
中かっこ { } を使用すると、一連のオペレーションを指定して、出力として 1 つの時系列のテーブルを生成できます。個別のオペレーションはコロン ; で区切ります。
この例では、fetch オペレーションは単一のテーブルを返します。このテーブルは、一連の 2 つのオペレーションである top オペレーションと bottom オペレーションのそれぞれにパイプされます。これらの各オペレーションにより、同じ入力テーブルに基づく出力テーブルになります。union オペレーションは、2 つのテーブルを 1 つに結合し、グラフに表示します。
詳細については、リファレンス トピックのクエリ構造で { } を使用した場合のシーケンス オペレーションをご覧ください。
時系列を 1 つのラベルの異なる値と組み合わせる
同じ指標タイプに対して複数の時系列があり、その時系列のいくつかを結合するとします。1 つのラベルの値に基づいて時系列を選択する必要がある場合、Metrics Explorer のクエリビルダー インターフェースを使用してクエリを作成することはできません。同じラベルの 2 つの異なる値でフィルタする必要がありますが、クエリビルダー インターフェースでは、選択するすべてのフィルタに一致する時系列が必要です。ラベルの一致は AND テストです。同じラベルに 2 つの異なる値を持つ時系列はありませんが、クエリビルダーのフィルタで OR テストを作成することはできません。
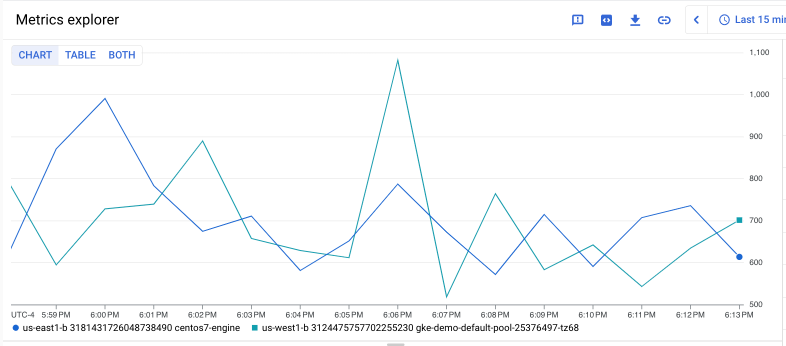
次のクエリは、2 つの特定の Compute Engine インスタンスで Compute Engine instance/disk/max_read_ops_count 指標の時系列を取得して、出力を 1 分間隔で並べます。
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| every 1m
次のグラフは、このクエリの有効な結果を示しています。
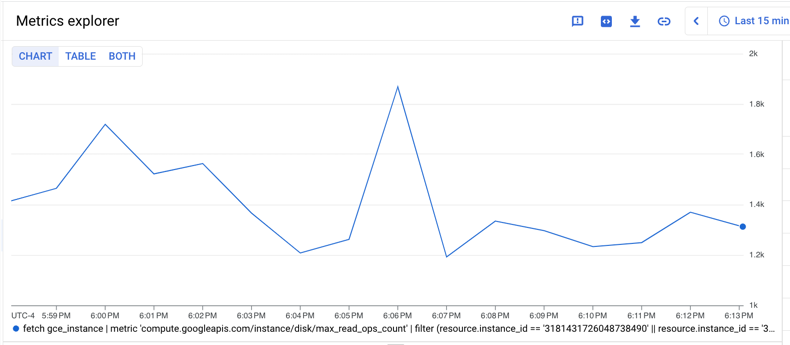
これら 2 つの VM で max_read_ops_count の最大値の合計を求める場合は、次のようにします。
- 各時系列の最大値を見つけるには、
group_byテーブル演算子を使用します。同じ 1 分間のアライメント期間を指定してmaxアグリゲータでその期間を集計し、出力テーブルにmax_val_of_read_ops_count_maxという名前の列を作成します。 group_byテーブル演算子とsumアグリゲータを使用して、max_val_of_read_ops_count_max列に時系列の合計を求めます。
クエリは次のとおりです。
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| group_by 1m, [max_val_of_read_ops_count_max: max(value.max_read_ops_count)]
| every 1m
| group_by [], [summed_value: sum(max_val_of_read_ops_count_max)]
次のグラフは、このクエリの有効な結果を示しています。
時間全体およびストリーム間のパーセンタイル統計を計算する
スライディング ウィンドウに対するパーセンタイル ストリーム値をストリームごとに個別に計算するには、時間的な group_by オペレーションを使用します。たとえば、次のクエリは、1 時間のスライディング ウィンドウに対するストリームの 99 パーセンタイル値を計算します。
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by 1h, percentile(val(), 99) | every 1m
1 つのストリーム内の時間全体ではなく、複数のストリームのある時点における同じパーセンタイル統計を計算するには、空間 group_by オペレーションを使用します。
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by [], percentile(val(), 99)
比率を計算する
Compute Engine VM インスタンスで実行され、Cloud Load Balancing を使用する分散ウェブサービスを構築したとします。
リクエストの合計数に対する HTTP 500 レスポンス(内部エラー)を返すリクエストの比率を示すグラフを表示します。つまり、リクエスト失敗率です。このセクションでは、リクエスト失敗率を計算するいくつかの方法について説明します。
Cloud Load Balancing は、モニタリング対象リソースタイプ http_lb_rule を使用します。http_lb_rule モニタリング対象リソースタイプには、ルールに定義された URL の接頭辞を記録する matched_url_path_rule ラベルがあります。デフォルト値は UNMATCHED です。
loadbalancing.googleapis.com/https/request_count 指標タイプには response_code_class ラベルがあります。このラベルは、レスポンス コードのクラスを取得します。
outer_join と div を使用する
次のクエリは、プロジェクト内にある各 http_lb_rule モニタリング対象リソースの matched_url_path_rule ラベルの各値に対する 500 レスポンスを決定します。次に、この失敗カウント テーブルを元のテーブルと結合します。このテーブルにはすべてのレスポンス数が含まれ、値を除算して合計レスポンスに対する失敗したレスポンスの割合を示します。
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| outer_join 0
| div
次のグラフは、1 つのプロジェクトの結果を示しています。
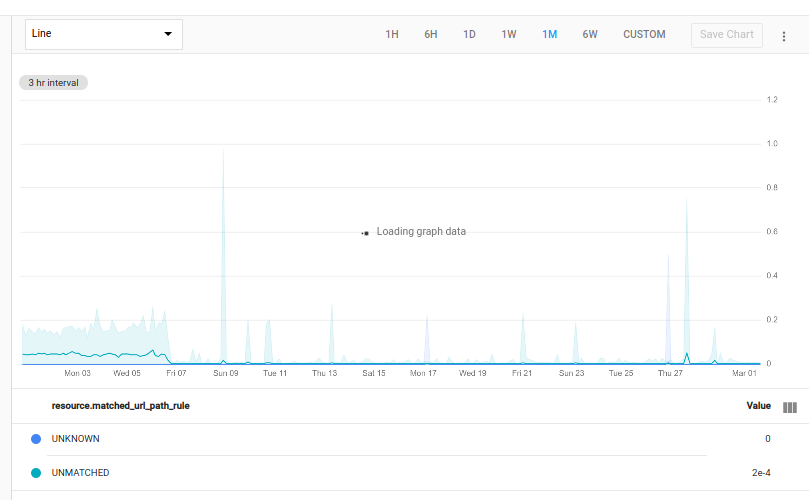
グラフ線の近傍にある網掛け部分は最小 / 最大バンドです。詳細については、最小 / 最大バンドをご覧ください。
fetch オペレーションは、すべての負荷分散クエリのリクエスト数を含む時系列のテーブルを出力します。このテーブルは、中かっこ内の 2 つのオペレーション シーケンスによって 2 つの方法で処理されます。
filter response_code_class = 500は、response_code_classラベルが値500を持つ時系列のみを出力します。結果の時系列は、HTTP 5xx(エラー)レスポンス コードを持つリクエストをカウントします。このテーブルは比率の分子です。
identオペレーションまたは identity オペレーションは入力を出力するため、最初に取得されたテーブルが返されます。これは、各レスポンス コードのカウントを持つ時系列を含むテーブルです。このテーブルは比率の分母です。
filter オペレーションと ident オペレーションによってそれぞれ生成された、分子テーブルと分母テーブルは、group_by オペレーションによって別々に処理されます。group_by オペレーションは、各テーブルの時系列を matched_url_path_rule ラベルの値でグループ化し、ラベルの各値の数を合計します。この group_by オペレーションはアグリゲータ関数を明示的に指定しないため、デフォルトの sum が使用されます。
フィルタリングされたテーブルの場合、
group_byの結果はmatched_url_path_rule値ごとに500レスポンスを返すリクエストの数です。ID テーブルの場合、
group_byの結果は各matched_url_path_rule値のリクエストの合計数になります。
これらのテーブルは outer_join オペレーションにパイプ処理され、2 つの入力テーブルのそれぞれから、一致するラベル値を持つ時系列をペア設定します。ペアの時系列は、1 つの時系列の各ポイントのタイムスタンプを他の時系列のポイントのタイムスタンプと一致させることで圧縮されます。一致したポイントのペアごとに、outer_join は 2 つの値を持つ 1 つの出力ポイントを、各入力テーブルから生成します。圧縮された時系列は、2 つの入力時系列と同じラベルでの結合によって出力されます。
外部結合では、2 番目のテーブルのポイントが最初のテーブルのポイントに一致しない場合は、代用値を指定する必要があります。この例では、値が 0 のポイント(outer_join オペレーションの引数)が使用されます。
最後に、div オペレーションは 2 つの値を持つ各ポイントを受け取り、値を除算して単一の出力ポイント(各 URL マップのすべてのレスポンスに対する 500 レスポンスの比率)を生成します。
文字列 div は、実際には div 関数の名前で、2 つの数値を除算します。ここではオペレーションとして使用されます。オペレーションとして使用する場合、div のような関数は、各入力ポイントに 2 つの値(この join が保証する)を想定し、対応する出力ポイントに単一の値を生成します。
クエリの | div 部分は | value val(0) / val(1) のショートカットです。value オペレーションでは、入力テーブルの値列に対して任意の式を使用して、出力テーブルの値列を生成できます。詳細については、value オペレーションと式のリファレンス ページをご覧ください。
ratio を使用する
div 関数は、2 つの値に対する任意の関数に置き換えることができますが、比率が頻繁に使用されるため、MQL には比率を直接計算する ratio テーブル オペレーションが用意されています。
次のクエリは、outer_join と div を使用した上記のバージョンと同等です。
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| ratio
このバージョンでは、以前のバージョンの outer_join 0 | div オペレーションが ratio オペレーションに置き換えられ、同じ結果が生成されます。
ratio は、分子と分母の入力の両方が、MQL outer_join が必要とする各時系列を識別する同じラベルがある場合に、分子の 0 を指定するために outer_join を使用するだけです。分子の入力に追加のラベルがある場合、分母に欠落しているポイントの出力はありません。
group_by と / を使用する
すべてのレスポンスに対するエラー レスポンスの割合を計算する方法は他にもあります。この場合、割合の分子と分母が同じ時系列から導出されるため、グループ化するだけで割合を計算できます。次のクエリは、このアプローチを示しています。
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| group_by [matched_url_path_rule],
sum(if(response_code_class = 500, val(), 0)) / sum(val())
このクエリでは、次の 2 つの合計の比率に基づいて作成された集計式が使用されます。
最初の
sum関数は、if関数を使用して 500 の値を持つラベルをカウントし、ほかのラベルはカウントしません。sum関数は、500 を返したリクエストの数を計算します。2 番目の
sumは、すべてのリクエストの数val()を加算したものです。
この 2 つの合計は除算され、すべてのレスポンスに対する 500 の値を持つレスポンスの比率になります。このクエリは、outer_join と div の使用および ratio の使用におけるクエリと同じ結果を生成します。
filter_ratio_by を使用する
比率は多くの場合、同じテーブルから取得した 2 つの合計を除算して計算されるため、MQL ではこの目的のために filter_ratio_by オペレーションが用意されています。次のクエリは、前のバージョンと同じことを行います。つまり合計を明示的に除算します。
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| filter_ratio_by [matched_url_path_rule], response_code_class = 500
filter_ratio_by オペレーションの第 1 オペランド(ここでは [matched_url_path_rule])は、レスポンスをグループ化する方法を示します。2 番目のオペレーション(ここでは response_code_class = 500)は、分子のフィルタリング式として機能します。
- 分母テーブルは、取得されたテーブルを
matched_url_path_ruleでグループ化し、sumを使用して集計した結果です。 - 分子テーブルは取得されたテーブルです。これは HTTP レスポンス コード 5xx で時系列をフィルタリングし、
matched_url_path_ruleでグループ化され、sumを使用して集計されます。
比率と割り当て指標
割り当ての使用状況をモニタリングするために、serviceruntime 割り当て指標とリソース固有の割り当て指標に対してクエリとアラートを設定するには、MQL を使用します。使用例などの詳細については、割り当て指標の使用をご覧ください。
算術計算
データをグラフ化する前に、算術演算の実行が必要になることもあります。たとえば、時系列の縮尺の変更、データのログスケールへの変換、2 つの時系列の合計のグラフ化などを行いたい場合があります。MQL で使用できる算術関数の一覧については、算術をご覧ください。
時系列の縮尺を変えるには、mul 関数を使用します。たとえば、次のクエリでは、時系列を取得して各値に 10 を掛けます。
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/read_bytes_count'
| mul(10)
2 つの時系列を合計するには、時系列の 2 つのテーブルをフェッチして、それらの結果を結合した後、add 関数を呼び出すようにクエリを構成します。次の例では、Compute Engine インスタンスから読み取られたバイト数と書き込まれたバイト数の合計を計算するクエリを示します。
fetch gce_instance
| { metric 'compute.googleapis.com/instance/disk/read_bytes_count'
; metric 'compute.googleapis.com/instance/disk/write_bytes_count' }
| outer_join 0
| add
上の式で、読み取りバイト数から書き込みバイト数を減算するには、add を sub に置き換えます。
MQL では、1 回目のフェッチと 2 回目のフェッチで返された一連のテーブル内のラベルを使用して、テーブルの結合方法を決定します。
最初のテーブルに、2 つ目のテーブルで見つからないラベルが含まれている場合は、MQL で
outer_joinオペレーションを実行できないため、エラーが報告されます。たとえば、次のクエリでは、最初のテーブルにmetric.instance_nameラベルが存在しますが、2 つ目のテーブルには存在しないためエラーが発生します。fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' } | outer_join 0 | addこの種のエラーを解決する方法の一つは、2 つのテーブルが同じラベルを持つようにグループ化句を適用することです。たとえば、すべての時系列のラベルをグループ化できます。
fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' | group_by [] ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' | group_by [] } | outer_join 0 | add2 つのテーブルのラベルが一致する場合や、最初のテーブルにないラベルが 2 つ目のテーブルに含まれている場合は、外部結合が許可されます。たとえば、次のクエリでは、
metric.instance_nameラベルが 2 つ目のテーブルには存在し、最初のテーブルには存在しませんが、エラーは発生しません。fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/write_bytes_count' } | outer_join 0 | sub最初のテーブルで見つかった時系列に 2 つ目のテーブルの複数の時系列と一致するラベル値が含まれている可能性があるため、MQL はペアごとに減算を実行します。
タイムシフト
現在の状況と過去の状況を比較したい場合があります。MQL には、過去から現在の期間にデータを移動させる time_shift テーブル オペレーションが用意されているため、過去のデータと現在のデータとの比較が可能です。
経時的な化率
次のクエリでは、time_shift、join、div を使用して、現在から過去 1 週間における各ゾーンの平均使用率を計算します。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by [zone], mean(val())
| {
ident
;
time_shift 1w
}
| join | div
次のグラフは、このクエリの有効な結果を示しています。
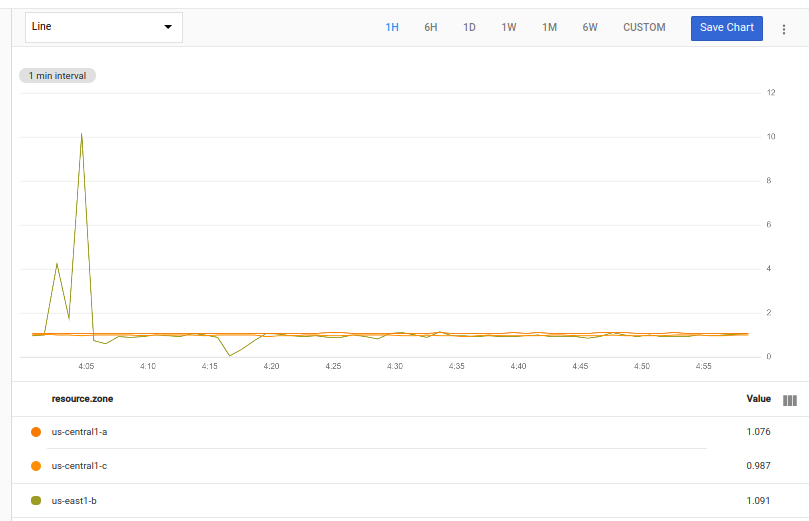
最初の 2 つのオペレーションは、時系列を取得し、ゾーンごとにグループ化し、それぞれの平均値を計算します。結果のテーブルは 2 つのオペレーションに渡されます。最初のオペレーション ident は、変更なしでテーブルを渡します。
2 番目のオペレーション time_shift は、テーブルのタイムスタンプの値に期間(1 週間)を追加します。これにより、1 週間前にデータがシフトします。この変更により、2 番目のテーブルの古いデータのタイムスタンプが、最初のテーブルにある現在のデータのタイムスタンプと同じになります。
変更されていないテーブルとタイムシフトされたテーブルは、内部 join を使用して結合されます。join は、各ポイントが現在の使用率と 1 週間前の使用率の 2 つの値を持つ時系列のテーブルを生成します。次に、クエリは div オペレーションを使用して、現在の値と 1 週間前の値の比率を計算します。
過去と現在のデータ
time_shift と union を組み合わせることで、過去と現在のデータを同時に表示するグラフを作成できます。たとえば、次のクエリは、今と 1 週間前の全体的な平均使用率を返します。union を使用すると、これら 2 つの結果を同じグラフに表示できます。
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by []
| {
add [when: "now"]
;
add [when: "then"] | time_shift 1w
}
| union
次のグラフは、このクエリの有効な結果を示しています。
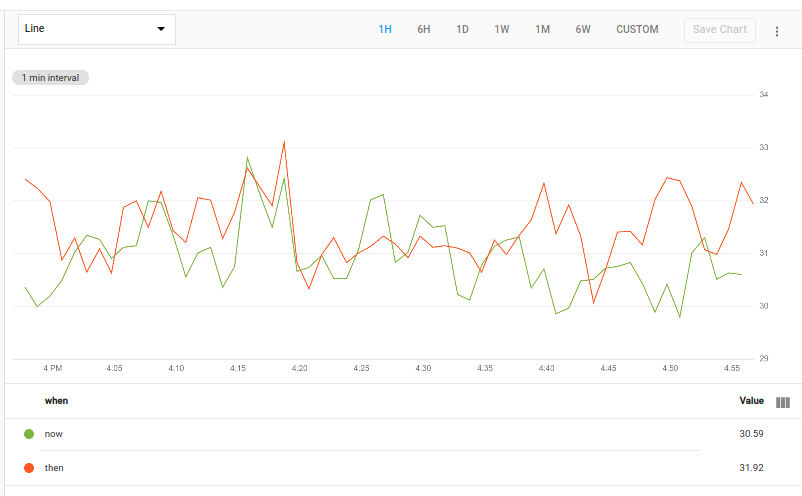
このクエリは、時系列を取得し、group_by [] を使用してラベルなしの単一の時系列に結合し、CPU 使用率データポイントを残します。この結果は 2 つのオペレーションに渡されます。最初に、値 now を持つ when という新しいラベルの列を追加します。2 番目に、値 then を持つ when というラベルを追加し、結果を time_shift オペレーションに渡して値を 1 週間シフトします。このクエリは add マップ修飾子を使用します。詳しくは、マップをご覧ください。
それぞれの単一の時系列データを含む、2 つのテーブルが union に渡され、両方の入力テーブルの時系列を含む 1 つのテーブルが生成されます。
次のステップ
MQL 言語構造の概要について、MQL 言語の概要を確認する。
MQL の詳細について、Monitoring Query Language リファレンスを確認する。
グラフの操作について、グラフの操作を確認する。