本文將概略介紹 Cloud Monitoring 提供的服務。這些服務可協助您瞭解應用程式和其他 Google Cloud 服務的行為、健康狀態和效能。Cloud Monitoring 會自動收集及儲存大多數 Google Cloud 服務的效能資訊。 您可以使用 Google Cloud Managed Service for Prometheus 收集 Prometheus 指標。在 Compute Engine 虛擬機器 (VM) 上安裝作業套件代理程式後,即可從應用程式和第三方應用程式收集指標和記錄檔。
Cloud Monitoring 提供的快訊、測試和視覺化服務,可協助您解答下列重要問題:
- 我的服務負載為何?
- 我的網站是否正常回應?
- 我的服務表現如何?
- 我的 App Hub 應用程式健康狀態如何?
Cloud Monitoring 為大多數服務提供 Google Cloud 控制台和 API 支援。部分服務也支援 Google Cloud CLI 或 Terraform。Cloud Monitoring API 參考頁面 (例如 alertPolicies.list 頁面) 可讓您直接從參考頁面實驗 API 呼叫。
Cloud Monitoring 服務
Cloud Monitoring 提供各種服務,可協助您瞭解應用程式和所用其他 Google Cloud 服務的健康狀態和效能。
事件和通知
如要在成效指標值達到既定條件時收到通知,請制定快訊政策。警報政策包含通知接收者清單,其中列出使用者或群組。 Monitoring 支援常見的通知管道,包括電子郵件、Cloud Mobile App,以及 PagerDuty 或 Slack 等服務。舉例來說,您可以建立快訊政策,在 VM 的 CPU 使用率超過 80% 時收到通知。
每則通知都會提供故障的相關資訊,並附上事件的連結。事件是一種永久記錄,會儲存可用於排解故障問題的資訊。通常,記錄會列出事件狀態、記錄連結、記錄指標資料圖表、標籤和持續時間。
這項快訊服務已整合至多項 Google Cloud 服務。如果存在這些整合功能,您可能會看到列出建議快訊的面板,或圖表上的按鈕,可讓您建立快訊政策。在這兩種情況下,系統都會預先設定警告政策,您只需要指定要通知的人員或群組清單。
您可以使用 Google Cloud 控制台、Cloud Monitoring API、Google Cloud CLI 或 Terraform,建立及管理快訊政策。
主動監控和驗證
如要測試服務、應用程式、網頁和 API 的可用性、一致性和效能,請建立綜合監控器。舉例來說,您可以透過運作時間檢查,探查 HTTP、HTTPS 和 TCP 端點的回應情形,並在端點無法回應時收到通知。您也可以建立失效連結檢查工具,用來檢索網頁,並在偵測到失效連結時通知您。
您可以使用 Google Cloud 控制台、Cloud Monitoring API、Google Cloud CLI 或 Terraform,建立及管理合成監控器。
資料視覺化
當您例項化 Google Cloud 資源或向 App Hub 註冊應用程式時,資訊主頁服務會自動建立 Google Cloud管理的資訊主頁。這些資訊主頁會顯示精選資訊,協助您瞭解資源和應用程式的健康狀態。舉例來說,如果是 App Hub 應用程式,系統會為應用程式,以及每個服務和工作負載建立資訊主頁。這些資訊主頁會顯示應用程式的記錄或指標資料,以及未解決的快訊數量等資訊。
Google Cloud 建立的資訊主頁可能提供足夠資訊,協助您完成調查。不過,這些工具可能無法提供您需要的確切資料,以利您查看趨勢、找出離群值,或查看資料的其他詳細資訊。如要完成這些工作,您可以使用資訊主頁和圖表服務:
如要控管要查看的資料和資料的顯示格式,請建立自訂資訊主頁。舉例來說,您可以匯入 Grafana 資訊主頁,或從範本安裝資訊主頁。
自訂資訊主頁可顯示下列內容。
- 顯示指標資料的圖表和表格
- 記錄資料和錯誤群組
- 快訊政策的圖表
- 快訊資訊
- 文字
- 事件,例如重新啟動或當機,會影響系統運作。
您可以使用 Google Cloud 控制台或 API 建立及管理資訊主頁。
圖表服務 Metrics Explorer 可讓您快速以視覺化方式呈現及探索時間序列資料。您可以在圖表設定中比較目前與先前的資料、顯示離群值和百分位數,以及顯示多項指標。您也可以將圖表儲存至自訂資訊主頁。
資料收集和儲存
Cloud Monitoring 會收集及儲存下列類型的指標資料:
- 服務產生的系統指標 Google Cloud 。 這些指標提供服務運作方式的相關資訊。
- 系統和應用程式指標:作業套件代理程式會收集 Compute Engine 執行個體上執行的系統資源和應用程式相關指標。您可以設定作業套件代理程式,從 第三方外掛程式收集指標,例如 Apache 或 Nginx 網路伺服器,或是 MongoDB 或 PostgreSQL 資料庫。
使用 Cloud Monitoring API 或 OpenTelemetry 等程式庫建立的使用者定義指標。
由某些開放原始碼程式庫或第三方供應商定義的外部指標。
由 Google Cloud Managed Service for Prometheus 收集的 Prometheus 指標,或使用作業套件代理程式和 Prometheus 接收器或 OTLP 接收器收集的指標。
- 記錄指標:記錄寫入 Cloud Logging 的記錄檔相關數值資訊。Google 定義的記錄指標包括服務偵測到的錯誤數量,以及 Google Cloud 專案收到的記錄項目總數。您也可以定義記錄指標。
查詢語言
建立快訊政策或圖表時,您必須提供查詢,說明要監控或繪製成圖表的資料:
Google Cloud 控制台:您可以從選單中選取項目來建構查詢,也可以自行編寫查詢。查詢編輯器適用於 Prometheus 查詢語言 (PromQL)。查詢編輯器提供語法檢查和建議。您也可以編寫 Monitoring 篩選器運算式。
Cloud Monitoring API:這項 API 支援 Prometheus 查詢語言 (PromQL) 和 Monitoring 篩選器運算式。
監控大型系統
本節說明如何以集合形式管理資源,以及如何監控儲存在多個 Google Cloud 專案中的指標。
以集合形式管理資源
如要以集合形式管理資源,而非個別管理,請建立資源群組。 資源群組是符合您所提供條件的動態資源集合。當您新增及移除資源 (例如將 Compute Engine VM 執行個體新增至Google Cloud 專案) 時,群組成員資格會自動變更。以下是資源群組的範例:
- 名稱開頭為字串
prod-的 Compute Engine 執行個體。 - 含有
test-cluster標記的資源。 - 位於 A 區域或 B 區域的 Amazon EC2 執行個體。
定義資源群組後,您可以監控該群組,就像監控單一資源一樣。舉例來說,您可以設定運作時間檢查,監控資源群組。如果是圖表和快訊政策,您也可以依群組名稱篩選。
詳情請參閱「設定資源群組」。
監控多項 Google Cloud 專案的指標
如要透過單一介面查看及監控多個Google Cloud 專案和 AWS 帳戶的時間序列資料,請設定多專案指標範圍。
根據預設, Google Cloud 控制台中的 Cloud Monitoring 頁面只會提供對範圍界定專案中儲存的時間序列的存取權。範圍界定專案是指您使用Google Cloud 控制台專案選擇工具選取的專案。設定範圍專案會儲存您設定的快訊、綜合監控、資訊主頁和監控群組。
限定範圍專案也會代管指標範圍。指標範圍會定義指標可供範圍專案查看的專案和帳戶。您可以設定指標範圍,納入其他 Google Cloud 專案和 AWS 帳戶的時間序列資料。如要瞭解如何修改指標範圍,請參閱「為多個專案設定指標範圍」。
Cloud Monitoring 資料模型
本節將介紹 Cloud Monitoring 資料模型:
「指標類型」是指計量項目,指標類型範例包括虛擬機器的 CPU 使用率,以及磁碟使用百分比。
「時間序列」是一種資料結構,含有加上時間戳記的指標評估結果,以及這些評估結果的來源和意義相關資訊。
以下是時間序列包含的內容:
points陣列包含加上時間戳記的評估結果。以下是含有兩個值的
points陣列範例:"points": [ { "interval": { "startTime": "2020-07-27T20:20:21.597143Z", "endTime": "2020-07-27T20:20:21.597143Z" }, "value": { "doubleValue": 0.473005 } }, { "interval": { "startTime": "2020-07-27T20:19:21.597239Z", "endTime": "2020-07-27T20:19:21.597239Z" }, "value": { "doubleValue": 0.473025 } }, ],如要瞭解值的意義,請參閱時間序列中包含的其他資料,以及這些資料的定義。
resource欄位說明要監控的硬體或軟體元件。在 Cloud Monitoring 中,硬體或軟體元件稱為「受監控資源」。受監控的資源範例包括 Compute Engine 執行個體和 App Engine 應用程式。如需受監控資源清單,請參閱受控資源清單。以下是
resource欄位的範例:"resource": { "type": "gce_instance", "labels": { "instance_id": "2708613220420473591", "zone": "us-east1-b", "project_id": "sampleproject" } }「
type」欄位會將受監控的資源列為gce_instance,表示這些測量結果是在 Compute Engine VM 執行個體上取得。labels欄位包含鍵/值組合,可提供受監控資源的額外資訊。如果是gce_instance類型,標籤會識別受監控的 VM 執行個體。
metric欄位會說明要評估的內容。以下是
metric欄位的範例:"metric": { "labels": { "instance_name": "test" }, "type": "compute.googleapis.com/instance/cpu/utilization" },- 如果是 Google Cloud 服務,
type欄位會指定服務和監控內容。在本例中,Compute Engine 服務會測量 CPU 使用率。如果type欄位開頭為custom或external,則該指標為自訂指標或第三方定義的指標。
labels欄位包含鍵/值組合,提供有關評估的額外資訊。這些標籤是MetricDescriptor的一部分,這個資料結構會定義所測量資料的屬性。指標MetricDescriptorcompute.googleapis.com/instance/cpu/utilization的MetricDescriptor包含標籤instance_name。
- 如果是 Google Cloud 服務,
「
metricKind」欄位說明時間序列中相鄰測量值之間的關係:GAUGE指標會儲存特定時間點的測量值,例如每小時的溫度記錄。CUMULATIVE指標會儲存特定時間點所測量的累積值,例如車輛的里程表。DELTA指標會儲存指定期間內所測量項目的值變化,例如顯示股票盈虧的股票摘要。
valueType欄位會說明測量資料的資料類型:INT64、DOUBLE、BOOL、STRING或DISTRIBUTION。
- 您可以顯示每個 VM 執行個體的 CPU 使用率。
- 您可以篩選
instance_id標籤的單一值,顯示特定 VM 執行個體的 CPU 使用率。 您可以依據
machine_type標籤將 VM 執行個體分組,然後顯示平均 CPU 使用率。下圖為設定完成的圖表: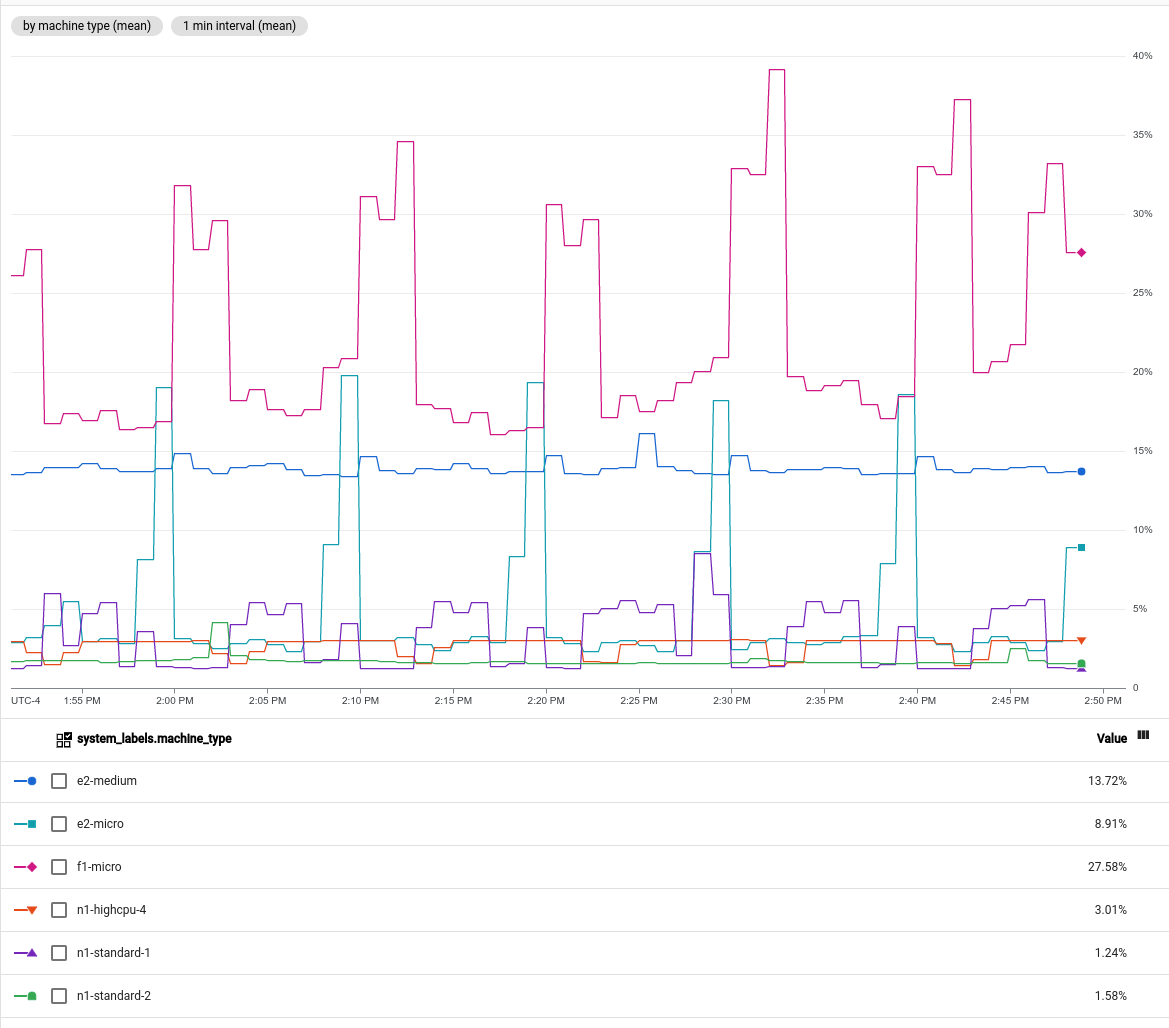
定價
一般來說,Cloud Monitoring 系統指標是免費的,但外部系統、代理程式或應用程式的指標則否。系統會根據擷取的位元組數或樣本數,對可計費指標收費。
詳情請參閱 Google Cloud Observability 定價頁面的 Cloud Monitoring 部分。
後續步驟
- 如要探索 Cloud Monitoring,請參閱監控 Compute Engine 執行個體的快速入門導覽課程。
- 如要瞭解如何設定 Google Cloud 專案,以便查看多個 Google Cloud 專案和 AWS 帳戶的指標,請參閱「指標範圍總覽」。
如要瞭解 Cloud Monitoring 資料模型,請參閱指標、時間序列和資源。
如要瞭解 Cloud Monitoring API,請參閱「API 和參考資料」。