本文档介绍了可以显示为注释的事件类型 事件是指影响 系统的运行。显示事件可帮助您 对来自不同来源的数据进行排查时 一个问题。
对于每项活动,我们都会提供指向参考文档或问题排查文档的链接 以及有关如何查询该事件的信息。 例如,通过分析日志识别事件时, 适合搭配日志浏览器或基于日志的 提醒政策。
要向图表添加注释,请配置信息中心或标签页 。例如,您可以将大多数信息中心 Google Cloud 控制台的信息中心页面上列出的项目,以显示事件。 同样,您可以配置一些服务专用的 Observability 标签页, 例如用于 Compute Engine 和 Google Kubernetes Engine 的容器,以显示事件。 如需了解配置信息,请参阅 在信息中心内显示事件。
下面的屏幕截图显示了一个图表,其中显示了 通过分析日志条目识别的事件; Service Health 事件:
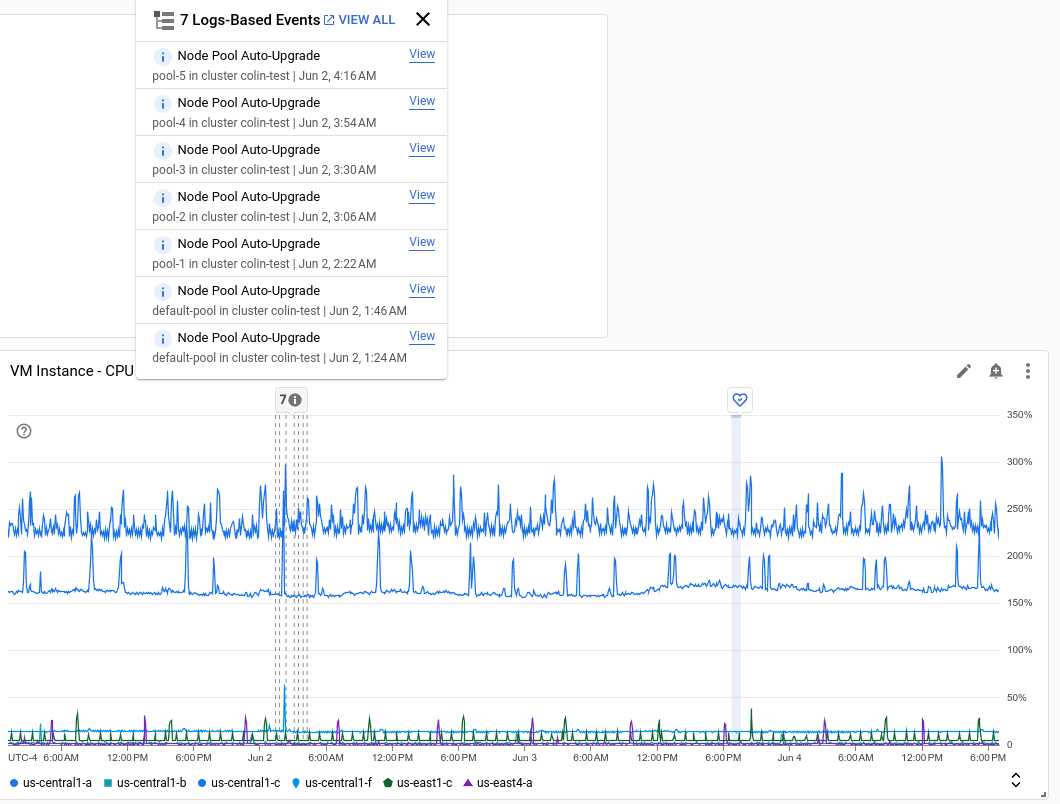
每个注解可以列出多个事件。在上一个屏幕截图中, 系统会列出 GKE 部署的事件
提醒事件类型
本部分介绍可在 信息中心。
提醒已打开
提醒已打开事件可帮助您将绘制成图表的数据与 突发事件。 当满足以下条件时,系统会显示提醒打开事件:
- 相应突发事件是在指定的时间范围内未结的 信息中心
- 相应的突发事件未关闭。
对于在 信息中心指定的时间范围不会显示。同样, 相应突发事件打开后,系统就不会显示提醒已打开事件 并在信息中心指定的时间范围内关闭。
提醒已打开事件的提示包含以下内容:
- 提醒政策的名称。
- 摘要信息(如果有)。例如, 信息可能包括阈值和测量值。
- 突发事件的时长以及日期和时间 创建相应的事件
- 指标和资源标签。提示可能不会显示所有标签。
- 查看按钮,点击此按钮可打开相应突发事件的详细信息页面。
Google Kubernetes Engine 事件类型
本部分介绍了可 信息中心
修补或更新的 GKE 工作负载
此事件类型可帮助您排查 GKE 问题 工作负载部署或 Statefulset 更改,因为这些事件可能与 性能下降或其他性能问题显示此事件类型 创建、更新或删除工作负载时触发
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.deployments.deletecollection OR io.k8s.apps.v1.statefulsets.create OR
io.k8s.apps.v1.statefulsets.patch OR io.k8s.apps.v1.statefulsets.update OR
io.k8s.apps.v1.statefulsets.delete OR io.k8s.apps.v1.statefulsets.deletecollection OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete OR
io.k8s.apps.v1.daemonsets.deletecollection
)
-protoPayload.authenticationInfo.principalEmail="system:addon-manager"
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system)
如需了解更多信息,请参阅 工作负载部署概览 和查看可观测性指标。
GKE Pod 崩溃
此事件类型可帮助您发现和排查问题 GKE Pod 崩溃。 Pod 崩溃可能是由内存耗尽或应用错误导致的。 出现以下任一情况时,系统会显示此事件类型:
- Pod 状态为
CrashLoopBackoff - Pod 终止并显示非零退出代码。
- Pod 终止时会出现内存不足的情况。
- Pod 被逐出。
- 就绪性/活跃性探测失败。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
有关问题排查信息,请参阅 问题排查:CrashLoopBackOff。
未能调度 GKE Pod
此事件类型可帮助您发现 进行调度当 Pod 调度失败时,系统会显示此事件类型 出于以下任何原因:
- 节点 CPU 不足。
- 节点内存不足。
- 没有针对污点或容忍设置的节点。
- 达到 Pod 数上限的节点。
- 节点池已达到大小上限。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
有关问题排查信息,请参阅 问题排查:Pod 无法调度。
未能创建 GKE 容器
此事件类型可帮助您识别故障并对其进行问题排查,从而创建 GKE 容器容器创建可能会由于以下原因失败: 例如卷装载失败或映像拉取失败。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
有关问题排查信息,请参阅 问题排查:ImagePullBackOff 和 ErrImagePull。
Pod 自动扩缩器纵向扩容和缩容
通过此事件,您可以了解 Pod 横向自动扩缩器的重新扩缩情况, 增加或减少工作负载的运行 Pod 数量。 如需了解详情,请参阅 Pod 横向自动扩缩。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
集群自动扩缩器进行纵向扩容和缩容
此事件可让您了解集群自动扩缩器何时纵向扩容或 减少集群节点池中的节点数量如需更多信息 请参阅关于集群自动扩缩 和查看集群自动扩缩器事件。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
集群创建和删除
此事件跟踪 GKE 集群创建和删除 操作。如需了解详情,请参阅 创建 Autopilot 集群。 创建可用区级集群 删除集群。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
集群更新
此事件可跟踪 GKE 集群的更新。更新内容包括 控制平面版本自动升级以及手动升级 集群配置更改。如需了解详情,请参阅 手动升级集群或节点池 和标准集群升级。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
节点池更新
此事件可跟踪 GKE 节点池的更新。更新包括自动节点池 版本升级以及手动升级、配置更改和调整大小。 如需了解详情,请参阅 手动升级集群或节点池 和标准集群升级。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Cloud Run 事件类型
本部分介绍可 信息中心
Cloud Run 部署
此事件类型可帮助您发现和排查问题 Cloud Run 部署失败。部署可能会由于以下原因而失败 例如,服务账号被删除、权限不正确、导入 容器故障或容器启动失败。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
有关问题排查信息,请参阅 问题排查:Cloud Run 问题。
Cloud SQL 事件类型
本部分介绍可 信息中心
Cloud SQL 故障切换
此事件类型可帮助您确定手动或自动故障切换发生的时间。 当实例或可用区发生故障时,就会发生故障切换 备用实例成为新的主实例。在故障切换期间 Cloud SQL 会自动切换为从备用实例传送数据。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
如需了解更多信息,请参阅 高可用性简介。
启动或停止 Cloud SQL
此事件类型可帮助您识别 Cloud SQL 实例已被手动 启动、停止或重新启动实例停止后,所有连接 打开的文件和正在运行的操作也会停止。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
如需了解更多信息,请参阅 高可用性简介和 启动、停止和重启实例。
Cloud SQL 存储
此事件类型可帮助您识别与 Cloud SQL 存储相关的事件, 包括何时数据库存储空间已满,以及数据库何时因 以及达到存储空间容量上限已用尽存储容量的数据库 可能会关闭自动存储,以防止数据损坏。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Compute Engine 事件类型
本部分介绍了可 信息中心
虚拟机终止
此事件类型可帮助您识别虚拟机 (VM) 终止, 包括手动触发的重置和停止、客机操作系统终止 维护终止和主机错误。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
如需了解更多信息,请参阅 停止和启动虚拟机 排查虚拟机关停和重新启动问题。
虚拟机实例启动失败
此事件会跟踪 Compute Engine 虚拟机实例启动失败问题。活动 显示由于资源短缺、IP 空间耗尽、超出配额而导致的启动失败, 或安全强化型虚拟机完整性错误
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
虚拟机实例客机操作系统错误
此事件跟踪特定的 Compute Engine 虚拟机实例客户机操作系统错误,如 由串行控制台日志记录跟踪的错误包括:磁盘已满、文件 系统装载失败,且启动失败,导致激活了 Linux 紧急模式。
若要显示这些事件,您必须启用将串行端口输出记录到
在虚拟机或serial-port-logging-enable=true
项目元数据。如需了解详情,请参阅
启用和停用串行端口输出日志记录。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
托管式实例组更新
此事件类型可帮助您确定代管式实例组 (MIG) 何时 已更新。例如,添加或移除了一些虚拟机 或者限制已更新如需了解详情,请参阅在 MIG 中自动应用虚拟机配置更新。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
如需了解更多信息,请参阅 使用代管式实例 排查代管式实例组问题。
代管式实例组自动扩缩器
此事件跟踪 MIG 的自动伸缩器做出的伸缩决策。 这些决策可能包括更改 MIG 的建议大小、 或者自动扩缩器本身的状态变化。如需了解详情,请参阅自动扩缩实例组。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Personalized Service Health 事件类型
本部分介绍了可以显示的 Personalized Service Health 类型 信息中心
Google Cloud 突发事件
在排查问题时,您可能想要区分 这部分故障是由您拥有的服务引起的, 您使用的 Google Cloud 服务。启用 信息中心上的 Personalized Service Health 注释; 您可以查看服务中断情况或服务健康状况 。与 Google Cloud 集成的 Service Health,请参阅 支持的 Google 产品。
与其他事件类型不同,Google Cloud 突发事件无法通过分析 生成自己的日志条目如果你希望在这些事件发生时收到通知,那么 创建提醒政策。您可以选择预配置的提醒政策 Service Health 信息中心页面上的选项监控。如需更多信息 请参阅快速入门:设置提醒。
Monitoring 可识别 Google Cloud 突发事件 方法是向 Service Health API 发出请求,然后过滤 应对与您正在查看的数据相关的突发事件。 该请求具有以下配置:
Relevance枚举设置为RELATED、IMPACTED或PARTIALLY_RELATED。 此限制可确保您的信息中心 会显示 Google Cloud 项目使用的资源。DetailedState枚举未设置为FALSE_POSITIVE。
Service Health 注释会显示开始时间 以及时长系统会通过更改背景颜色来显示时长 。关于 Google Cloud 突发事件的提示 用于标识以下各项:
- Google Cloud 服务。
- 突发事件是处于待处理状态还是已解决。
- 活动的日期和时间。
- 显示受影响商品和营业地点数量的条状标签。 要列出受影响的商品或位置,请将鼠标指针悬停在 相应条状标签。
- 一个查看按钮,选中该按钮后,系统会打开 事件。
有关如何向 Service Health API,请参阅 使用 Service Health 检查服务中断情况。
有关问题排查信息,请参阅 排查 Service Health 中的常见问题。
拨测事件类型
本部分介绍可在 信息中心。
拨测失败
此事件类型可帮助您识别由所配置的拨测导致的 区域。
如果您想 为此,创建基于日志的提醒政策 事件类型,请使用以下查询:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
如需了解问题排查信息,请参阅对合成监控和拨测进行问题排查。
后续步骤
如需了解如何在信息中心显示事件,请参阅 在信息中心内显示事件。