このドキュメントでは、プロジェクトで収集された時系列データを表示する一時的なグラフを構成する方法について説明します。Metrics Explorer は数値の時系列データのみを表示できます。
表示するデータを選択する
グラフに表示する時系列を構成するには、メニューから選択してクエリを作成するか、クエリを記述して作成します。クエリを記述するときに、クエリ言語を選択し、クエリエディタまたはテキストベースのインターフェースを使用します。
Prometheus Query Language(PromQL)クエリは、時系列と、その時系列をグループ化および配置する方法を指定します。PromQL インターフェースは、候補を表示するエディタをサポートしています。
通常、PromQL クエリを他のインターフェースが使用できる形式に変換することはできません。保存していないクエリは、[PromQL] タブを切り替えると破棄されます。
モニタリング フィルタクエリでは、時系列を指定しますが、グループ化ステートメントまたはアライメント ステートメントは含まれません。
Monitoring でグラフに表示できる時系列は、Monitoring フィルタを使用して指定できます。たとえば、VM で実行されているプロセス数をグラフに表示するには、関数を指定する Monitoring フィルタを使用する必要があります。
Monitoring フィルタは、他のインターフェースで必要な形式に変換できない場合があります。そのため、別のインターフェースに切り替えると、クエリが破棄されることがあります。
通常、クエリでは指標タイプ、リソースタイプ、フィルタを指定します。
指標タイプは、リソースから収集される測定値を示します。これには、測定対象と測定値がどのように解釈されるかについての説明が含まれます。指標タイプは、「指標」と呼ばれることもあります。指標の例としては「CPU 使用率」などがあります。概念的な詳細については、指標タイプをご覧ください。
リソースタイプは、指標データを取得するリソースを示します。リソースタイプは、「モニタリング対象リソースタイプ」や「リソース」と呼ばれることもあります。リソースの例としては、「Compute Engine 仮想マシン(VM)インスタンス」などがあります。概念的な詳細については、モニタリング対象リソースをご覧ください。
PromQL クエリには、グループ化のステートメントとアライメントのステートメントが含まれています。ただし、Monitoring フィルタを作成するか、メニューを使用してグラフ化する時系列を選択する場合は、メニューを使用してグループ化とアライメントの設定を構成します。
メニューからクエリを作成する
メニューからクエリを作成するのがデフォルトの構成です。通常、指標とフィルタを選択してから別のインターフェースに切り替えると、その選択内容が保持され、そのインターフェース向けに再フォーマットされます。つまり、メニューで作成されたクエリは PromQL クエリに変換できます。
tune(ビルダー)を選択すると、他のインターフェースからメニュー ドリブンのインターフェースに戻ることができます。ただし、クエリは破棄されます。つまり、PromQL クエリは同等のメニュー ドリブンのフォームに変換できません。
メニューからクエリを作成するには、次のようにします。
-
Google Cloud コンソールで leaderboard [Metrics explorer] ページに移動します。
このページを検索バーで検索する場合は、小見出しが「Monitoring」の結果を選択します。
- Google Cloud コンソールのツールバーで、 Google Cloud プロジェクトを選択します。App Hub 構成の場合は、App Hub ホスト プロジェクトまたは管理プロジェクトを選択します。
クエリペインのツールバーで、次の操作を行います。
[指標] 要素で、[指標を選択] メニューを開きます。
[指標を選択] メニューでは、使用可能な指標タイプを探す際に役立つ機能を使用できます。
特定の指標タイプを探すには、フィルタバー filter_list を使用します。たとえば、「
util」と入力すると、utilを含むエントリのみが表示されるようにメニューが制限されます。大文字と小文字を区別せずに一致したエントリが表示されます。データが存在しない指標も含めて、すべての指標タイプを表示するには、[ アクティブ] をクリックします。デフォルトでは、データを含む指標タイプのみがメニューに表示されます。
[リソース] メニュー、[指標カテゴリ] メニュー、[指標] メニューから選択して、[適用] をクリックします。
たとえば、Compute Engine 仮想マシンの CPU 使用率をグラフ化するには、[VM インスタンス]、[インスタンス]、[CPU 使用率] の順に選択し、[適用] をクリックします。
[リソース] メニューには、データが収集されるリソースが一覧表示されます。リソースに対する指標を書き込まない場合は、[指定なし] を選択します。
リソースタイプと指標を選択すると、そのペアの使用可能なすべての時系列がグラフに表示されます。
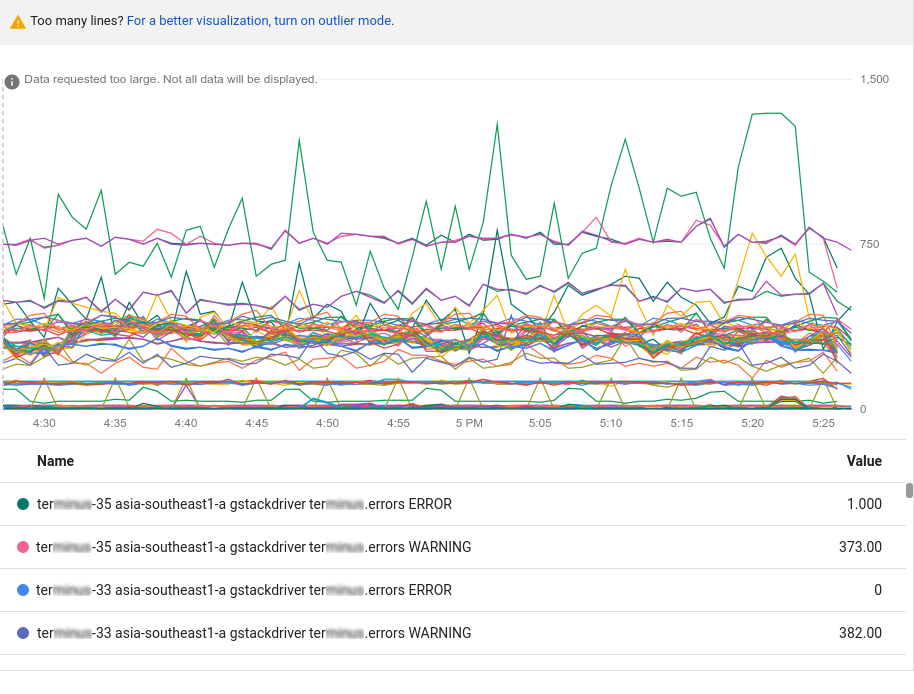
上記のグラフには、表示できる量より多くのデータが含まれています。グラフでは、表示可能な線の数が 50 に制限されています。表示するデータが多すぎるという通知がグラフに表示されます。データの量を減らすには、クエリ ツールバーで [並べ替えと制限] 要素を使用します。詳細については、外れ値を表示するをご覧ください。
また、フィルタや集計のオプションを使用して、グラフ化するデータの量を減らすこともできます。これらの手法により、診断や分析に役立つグラフを作成できます。また、ユーザー インターフェースのパフォーマンスや反応も改善されます。
省略可: フィルタを追加して、表示される時系列を限定します。次のセクションでは、フィルタリング オプションについて説明します。
省略可: 時系列のグループ化と配置の方法を構成します。詳細については、グラフ化したデータの表示方法を選択するをご覧ください。
グラフ化されたデータのフィルタ
フィルタにより、一定の条件を満たす時系列のみがグラフ化されるようになります。フィルタを適用すると、グラフ上の線の数が減り、グラフのパフォーマンスが向上します。グラフの応答性を向上させる別の方法として、集計オプションを構成し、表示される時系列を並べ替えて数を制限することもできます。詳細については、外れ値を表示するをご覧ください。
フィルタは、ラベル、コンパレータ、値で構成されています。たとえば、zone ラベルが "us-central1" で始まるすべての時系列を照合するには、正規表現を使用して比較を行うフィルタ zone=~"us-central1.*" を使用できます。コンパレータの演算子には次の 4 つがあります。
- 等しい、
= - 等しくない、
!= - 正規表現が一致、
=~ - 正規表現が一致しない、
!=~
プロジェクト ID またはリソース コンテナでフィルタする場合は、等号演算子 (=) を使用する必要があります。他のラベルでフィルタする場合は、サポートされている任意のコンパレータを使用できます。通常、指標ラベル、リソースラベル、リソース グループでフィルタできます。
複数のフィルタ条件を指定すると、対応するグラフには、すべての条件を満たす時系列だけが表示されます(論理 AND)。
Google Cloud コンソールのメニュー ドリブン インターフェースを使用してフィルタを追加するには、次の操作を行います。
[フィルタ] 要素で [フィルタを追加] をクリックし、メニューから選択します。
比較を変更するには、[コンパレータ] メニューから値を選択します。
[値] フィールドで、値を入力または選択します。
直接比較(
=や!=)の場合は、メニューから値を選択するか、値を入力して [OK] をクリックします。us-central1-aなどの値を入力することも、starts_withやends_withで始まるフィルタ文字列を作成することも可能です。たとえば、任意のus-central1ゾーンのデータを表示するには、フィルタ文字列「starts_with("us-central1")」を入力します。フィルタ文字列に関する詳細については、モニタリング フィルタをご覧ください。メニューのエントリは、受信した時系列から導出されるため、モニタリング対象リソースが選択した指標のデータを生成しない場合は、ラベルの値を入力する必要があります。
正規表現の比較(
=~または!=~)の場合は、[値] フィールドに RE2 正規表現を入力してから [OK] をクリックします。たとえば、正規表現us-central1-.*は任意のus-central1ゾーンと一致します。「a」で終わる US ゾーンと一致させるには、正規表現
^us.*.a$を使用します。正規表現を使用して
project_idリソースラベルをフィルタすることはできません。たとえば、
us-central1ゾーンのいずれかからの時系列のみを表示するには、zone=~"us-central1.*"フィルタを適用します。
複数のフィルタを追加する場合は、次の点に注意してください。
同じラベルを複数回使用できます。これにより、値の範囲に対してフィルタを指定できます。
すべてのフィルタ条件を満たす必要があります。これらは論理
ANDを構成します。
フィルタの値またはコンパレータを編集するには、フィルタ要素で [arrow_drop_down メニュー] をクリックし、変更してから [OK] をクリックします。
フィルタを削除するには、[cancel キャンセル] をクリックします。
PromQL クエリを作成する
PromQL クエリを入力するには、次の手順を実行します。
-
Google Cloud コンソールで [leaderboard Metrics Explorer] のページに移動します。
このページを検索バーで検索する場合は、小見出しが「Monitoring」の結果を選択します。
- Google Cloud コンソールのツールバーで、 Google Cloud プロジェクトを選択します。App Hub 構成の場合は、App Hub ホスト プロジェクトまたは管理プロジェクトを選択します。
- クエリビルダー ペインのツールバーで、[codeMQL] または [codePROMQL] という名前のボタンを選択します。
- [言語] で [PromQL] が選択されていることを確認します。言語切り替えボタンは、クエリの書式設定と同じツールバーにあります。
- (省略可)[自動実行] の切り替えボタンを無効にします。
-
クエリエディタにクエリを入力します。たとえば、 Google Cloud プロジェクトの VM インスタンスの平均 CPU 使用率をグラフ化するには、次のクエリを使用します。
avg(compute_googleapis_com:instance_cpu_utilization)PromQL の使用の詳細については、Cloud Monitoring の PromQL をご覧ください。
[クエリを実行] をクリックします。
[自動実行] の切り替えが有効になっている場合、[クエリを実行] ボタンは表示されません。
モニタリング フィルタクエリを作成する
以下のいずれかを行う場合は、ダイレクト フィルタ モードを使用する必要があります。このモードでは、モニタリング フィルタを入力できます。
- サービスレベル目標(SLO)を表示します。
- 仮想マシン(VM)で動作しているプロセス数を表示します。
- まだデータがないカスタム指標を表示します。
- ラベルに基づいて、まだデータがない時系列をフィルタします。
モニタリング フィルタ(または同等の指標フィルタ)は、Monitoring がグラフに表示する時系列を識別する式です。たとえば、次の式の場合は、名前に nginx が含まれるプロセスの数を示すグラフが表示されます。
select_process_count("monitoring.regex.full_match(\".*nginx.*\")")
resource.type="gce_instance"
モニタリング フィルタを使用して、リソースタイプと指標タイプで時系列を識別することもできます。次の式により、us-east1-b ゾーンのすべての Google Cloud 仮想マシン インスタンスのログエントリ数を表示するグラフが表示されます。
metric.type="logging.googleapis.com/log_entry_count"
resource.type="gce_instance"
resource.label."zone"="us-east1-b"
モニタリング フィルタを入力する方法は次のとおりです。
-
Google Cloud コンソールで leaderboard [Metrics explorer] ページに移動します。
このページを検索バーで検索する場合は、小見出しが「Monitoring」の結果を選択します。
- Google Cloud コンソールのツールバーで、 Google Cloud プロジェクトを選択します。App Hub 構成の場合は、App Hub ホスト プロジェクトまたは管理プロジェクトを選択します。
[指標] 要素で [help_outline ヘルプ] をクリックし、[ダイレクト フィルタモード] を選択します。
[指標] 要素と [フィルタ] 要素が削除され、テキストを入力できる [フィルタ] 要素が作成されます。
[ダイレクト フィルタモード] モードに切り替える前にリソースタイプ、指標、またはフィルタを選択した場合は、これらの設定が [フィルタ] 要素に表示されます。
[フィルタ] 要素のテキスト領域に、モニタリング フィルタ式を入力します。詳細については、次のドキュメントをご覧ください。
ダイレクト フィルタ モードを使用しており、フィルタを満たすデータがない場合は、エラーが表示されます。よく発生するエラー メッセージには、「
Chart definition invalid」や「No data is available for the selected timeframe.」があります。省略可: 時系列のグループ化と配置の方法を構成します。詳細については、グラフ化したデータの表示方法を選択するをご覧ください。
メニュー ドリブンのインターフェースに戻るには、tune(ダイレクト フィルタモードを終了します)をクリックします。
グラフ化されたデータの表示方法を選択する
このセクションでは、集計フィールドを設定して選択したデータを表示する方法について説明します。集計は、時系列内のデータポイントのアライメントと、異なる時系列の組み合わせで構成されます。集計の詳細については、フィルタリングと集計: 時系列の操作をご覧ください。
- 表示オプションについては、グラフの表示オプションを設定するをご覧ください。
- グラフの使い方の詳細については、グラフデータの確認をご覧ください。
このセクションの内容は、PromQL を使用してグラフに表示するデータを選択した場合は適用されません。
時系列を結合する
異なる時系列を組み合わせることで、指標に対して返されるデータの量を減らすことができます。複数の時系列を組み合わせるには、通常、1 つ以上のラベルと関数を指定します。指定したすべてのラベルに対して同じ値を持つ時系列がグループ化され、指定した関数がそれらの時系列を新しい時系列に結合します。
[集計] 要素の設定では、グラフに表示される時系列の数を変更できます。この要素のデフォルトは、選択した指標タイプによって決まります。表示を変更するには、次のいずれかを行います。
すべての時系列を表示するには、[集計] 要素で最初のメニューを [未集計] に設定し、2 つ目のメニューを [なし] に設定します。
時系列を結合するには、[集計] 要素で次の操作を行います。
最初のメニューを開いて関数を選択します。
グラフが更新され、単一の時系列が表示されます。たとえば、[平均] を選択すると、表示される時系列はすべての時系列の平均になります。
関数のメニューには、平均、最小値、最大値、合計などの一般的な代数関数が用意されています。[時系列をカウント] オプションは、指標とフィルタの設定に一致する時系列の数をカウントします。パーセンタイル オプション(99 パーセンタイルなど)は、指標とフィルタの設定に一致する時系列から導出された統計値です。
同じラベル値を持つ時系列を結合するには、2 番目のメニューを開いてラベルを選択します。
グラフが更新され、ラベル値の一意の組み合わせごとに 1 つの時系列が表示されます。たとえば、ゾーンごとに時系列を表示するには、2 番目のメニューを [ゾーン] に設定します。
データポイントの間隔を構成するには、add [クエリ要素を追加] をクリックし、[最小間隔] を選択して、値を入力します。
たとえば、関数を [Sum] に設定し、ラベル「user_labels.version」を選択した場合、ラベル「user_labels.version」の値ごとに 1 つの時系列が存在します。各時系列のデータポイントは、特定バージョンの個別の時系列のすべての値の合計から計算されます。
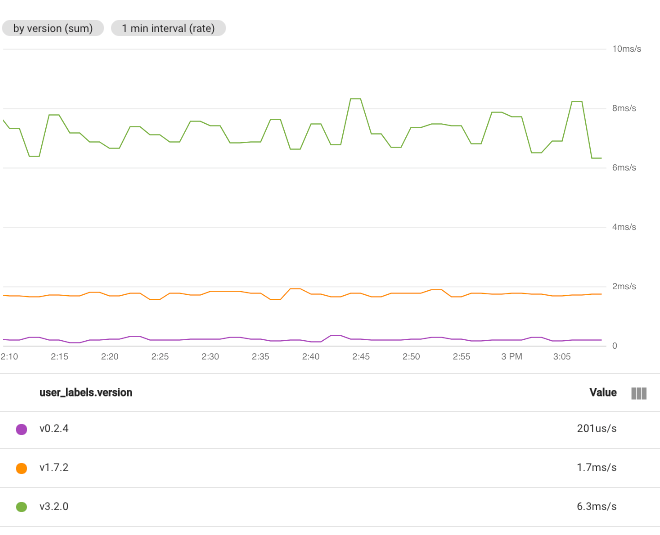
複数のラベルを選択すると、選択したラベルに対して同じ値を持つ時系列が結合されます。結果のグラフには、ラベル値の組み合わせごとに 1 つの時系列が表示されます。ラベルを指定する順序は問題になりません。次のスクリーンショットは、時系列を user_labels.version ラベルと system_labels.machine_image ラベルで結合したグラフを示しています。
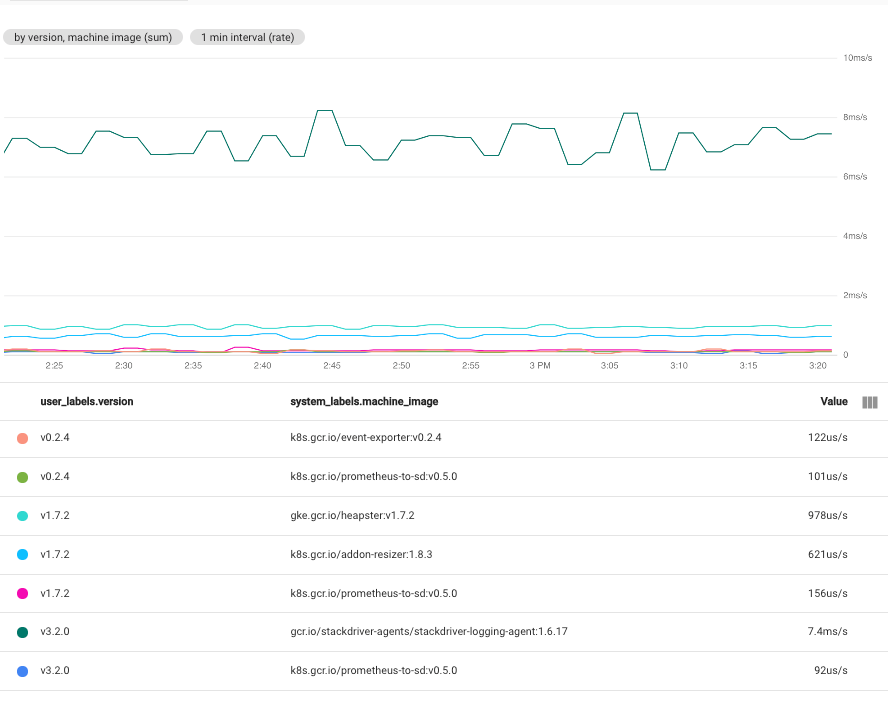
グラフには、ラベル値の組み合わせごとに 1 つの時系列が表示されます。この方法では、ラベルの組み合わせごとに時系列が作成されるため、1 つのグラフで通常作成する場合よりも多くのデータが作成されます。
すべての時系列を表示する
すべての時系列を表示するには、[集計] 要素で、最初のメニューを [未集計]、2 番目のメニューを [なし] に設定します。
時系列を調整する
アライメントは、Monitoring によって受信された時系列データを、固定間隔でデータポイントを持つ新しい時系列に変換するプロセスです。アライメントのプロセスは、一定時間内に受信したすべてのデータポイントを収集し、それらのデータポイントを結合する関数を適用して、結果にタイムスタンプを割り当てます。この関数では、すべてのサンプルの平均を計算することも、すべてのサンプルの最大値を抽出することもできます。
アライメント間隔を設定する
結合するポイントの固定時間を指定するには、クエリペインで [add クエリ要素を追加] をクリックして、[最小間隔] を選択し、ダイアログを完了します。
たとえば、サンプリング期間が 1 分の指標について考えてみましょう。1 時間のデータを表示するようにグラフが構成されている場合、グラフには 60 個のデータポイントすべてを表示できます。[最小間隔] フィールドが 10 minutes に設定されている場合、グラフには 6 個のデータポイントが表示されます。この状態で、1 週間のデータを表示するようにグラフを構成するには、グラフに表示するポイントが多すぎるため、ポイントの結合間隔が自動的に変更されます。この例では、変更後の間隔は 1 時間です。
次のスクリーンショットは、特定の Google Cloud プロジェクトの Compute Engine VM インスタンスの CPU 使用率を示しています。この画像では、[最小間隔] フィールドが 1 minute に設定されています。
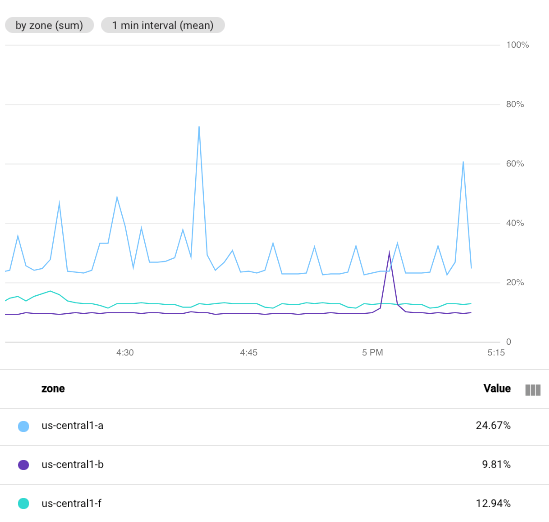
比較のため、次のスクリーンショットでは、間隔を 1 minute から 5 minutes に変更した場合の影響を示しています。
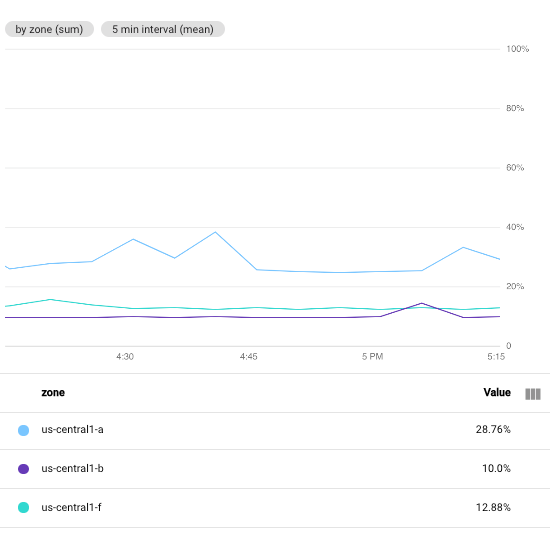
期間を長くすることにより、結果のグラフのポイントが少なくなり、時系列あたり 60 ポイントから時系列あたり 10 ポイントに減ります。[最小間隔] フィールドの値を大きくすると、より多くのポイントが結合され、プロットされるデータが滑らかになります。
アライメント関数を設定する
集計用の関数を選択すると、Cloud Monitoring でアライメント関数が選択されます。Cloud Monitoring では、選択した指標タイプと集計関数の選択に基づいて、最適なアライメント関数が決定されます。ただし、アライメント関数を指定して、Cloud Monitoring による選択をオーバーライドできます。
アライメント関数を指定するには、次の操作を行います。
- [集計] 要素で最初のメニューを開いて、[整列指定子を構成] を選択します。[アライメント関数] と [グループ化] 要素が追加されます。
- [アライメント関数] 要素を開いて、選択を行います。
サポートされているアライメント関数のほとんどは一般的な数学関数を実行しますが、中にはより複雑なアクションを実行するものもあります。
次に古い: アライメント期間内で最新のサンプルのみを保持するには、[次に古い] を選択します。この関数は、稼働時間チェックでよく使用されます。最新の値のみを対象とする場合は、適切な選択肢です。
この関数は、ゲージ指標にのみ有効です。
パーセンタイル: 折れ線グラフ、積み上げ面グラフ、積み上げ棒グラフなどのプロトタイプで分布指標を表示するには、表示する分布でのパーセンタイルを選択する必要があります。このパーセンタイルを指定する方法の一つに、パーセンタイル関数の選択があります。5、50、95、99 パーセンタイルを選択できます。整列データポイントは、アライメント期間内のすべてのデータポイントを使用して指定されたパーセンタイルを計算して決定されます。
この機能は、分布データ型を持つゲージ指標とデルタ指標に対してのみ有効です。
デルタ: 累積指標またはデルタ指標を、アライメント期間ごとのサンプルが 1 つであるデルタ指標に変換するには、この関数を使用します。この関数を使用すると、データの補間が発生することがあります。例については、種類、タイプ、変換をご覧ください。
この関数は、累積指標とデルタ指標にのみ有効です。
レート: 累積指標またはデルタ指標をゲージ指標に変換するには、この関数を使用します。この関数を選択した場合、時系列がデルタ関数と同様に変換され、アライメント期間で除算されると考えることができます。たとえば、元の時系列の単位が MiB で、アライメント期間の単位が秒の場合、グラフの単位は MiB/秒になります。詳細については、種類、タイプ、変換をご覧ください。
この関数は、累積指標とデルタ指標にのみ有効です。
使用可能なアライメント関数についての詳細は、API リファレンスの Aligner をご覧ください。
二次グループ化とアライメント
複数の時系列ですでに集計が表されている場合は、セカンダリ アグリゲータを選択することで、グラフのすべての時系列を 1 つの時系列に削減できます。たとえば、データをゾーンごとにグループ化すると、グラフにはゾーンごとに 1 つの時系列が表示されます。1 つの時系列でグラフを作成するには、二次集計フィールドを使用します。
一部の指標タイプでは、データを変換するオプションを利用できます。このオプションが使用可能で、[変換] フィールドを [なし] 以外の値に設定すると、他のすべてのフィールドは二次集計の設定になります。
二次集計フィールドを構成できる場合、これらのフィールドにアクセスするには次の操作を行います。
- [add クエリ要素を追加] をクリックし、[二次集計] を選択します。
- [二次集計] 要素を構成します。
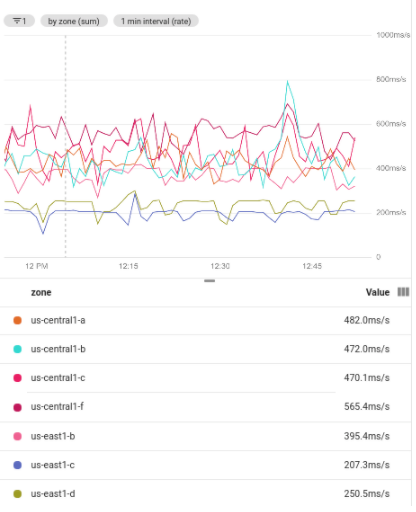
次のスクリーンショットでは、フィルタリングされたデータセットをグループ化した結果として、複数の時系列が表示されています。グループ化を使用するには集計が必要で、各行のグループが 1 つにまとめられます。次のスクリーンショットでは、ゾーンでグループ化した時系列が表示されています。
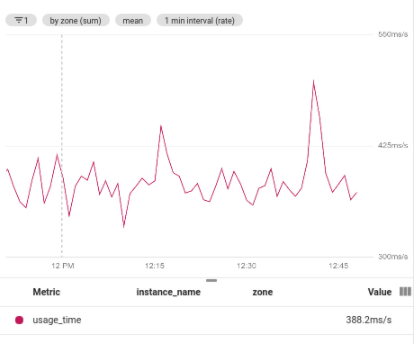
次のスクリーンショットは、二次集計を使用して、グループ化された時系列の平均値を求めた結果を表しています。
凡例列の名前を構成する
[凡例のエイリアス] フィールドを使用して、グラフの時系列の説明をカスタマイズできます。この説明は、グラフのツールチップと [Name] 列のグラフの凡例に表示されます。デフォルトでは、凡例の説明は時系列のさまざまなラベルの値から自動的に作成されます。システムによってラベルが選択されるため、結果が適切ではない場合があります。説明のテンプレートを作成するには、このフィールドを使用します。
[凡例のエイリアス] フィールドには書式なしテキストとテンプレートを入力できます。テンプレートを追加するときに、凡例が表示される際に評価される式を追加します。
凡例テンプレートをグラフに追加するには、次のようにします。
- [表示] ペインで、expand_more [凡例のエイリアス] を開きます。
- add [テンプレート変数の候補を表示] をクリックし、メニューからエントリを選択します。たとえば、
zoneを選択すると、テンプレート${resource.labels.zone}が追加されます。
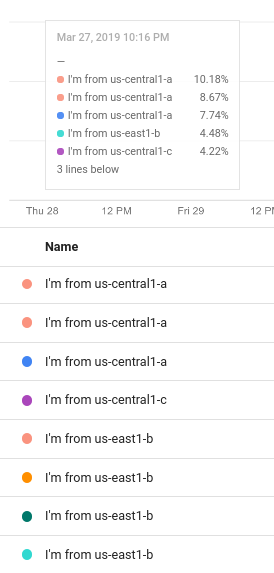
たとえば、次のスクリーンショットは、書式なしテキストと式 ${resource.labels.zone} を含む凡例テンプレートを示しています。

グラフの凡例では、テンプレートから生成された値が [Name] という見出しの列とツールチップに表示されます。
複数のテキスト文字列とテンプレートを含む凡例テンプレートを構成することはできますが、ツールチップで表示できるスペースは限られています。