本文說明如何使用 Google Cloud 主控台建立以指標為基礎的快訊政策,在指標值超過或低於特定重新測試時間範圍的門檻時傳送通知。舉例來說,如果 CPU 使用率超過 80% 至少五分鐘,快訊政策的條件可能就會符合。
這項內容不適用於以記錄檔為準的快訊政策。 如要瞭解記錄警告政策 (當記錄中出現特定訊息時,系統會通知您),請參閱「監控記錄」。
本文件未說明下列事項:
- 如何接收資料停止傳送的通知。詳情請參閱建立指標缺席快訊政策。
- 如何根據指標的預測值接收通知。詳情請參閱「建立預估指標值快訊政策」。
如何使用 Cloud Monitoring API 建立快訊政策。詳情請參閱「使用 API 建立快訊政策」。
瞭解如何建立快訊政策,並在條件中加入 Monitoring Query Language (MQL) 查詢。這些政策可使用靜態或動態門檻。如需詳細資訊,請參閱下列文件:
這項功能僅支援 Google Cloud 專案。 如果是 App Hub 設定,請選取 App Hub 主專案或管理專案。
事前準備
-
如要取得必要權限,以便使用 Google Cloud 控制台建立及修改快訊政策,請要求管理員授予您專案的 Monitoring 編輯者 (
roles/monitoring.editor) 身分與存取權管理角色。如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。如要進一步瞭解 Cloud Monitoring 角色,請參閱「使用 Identity and Access Management 控制存取權」。
請務必熟悉快訊政策的一般概念。如要瞭解這些主題,請參閱「快訊總覽」。
設定要用來接收通知的通知管道。為確保備援,建議您建立多種通知管道。詳情請參閱「建立及管理通知管道」。
建立警告政策
如要建立快訊政策,將該指標的值與靜態門檻進行比較,請按照下列步驟操作:
-
前往 Google Cloud 控制台的 notifications「Alerting」(警告) 頁面:
如果您是使用搜尋列尋找這個頁面,請選取子標題為「Monitoring」的結果。
- 在 Google Cloud 控制台的工具列中,選取您的 Google Cloud 專案。如要進行 App Hub 設定,請選取 App Hub 主專案或管理專案。
- 選取「建立政策」。
選取要監控的時間序列:
按一下「選取指標」,瀏覽選單選取資源類型和指標類型,然後按一下「套用」。
「選取指標」選單包含有助於尋找可用指標類型的功能:
- 如要尋找特定指標類型,請使用filter_list「篩選列」。舉例來說,如果您輸入
util,系統就會限制選單只顯示包含util的項目。如果項目通過不區分大小寫的「包含」測試,就會顯示。
- 如要顯示所有指標類型 (包括沒有資料的指標),請按一下「有效」。根據預設,選單只會顯示有資料的指標類型。詳情請參閱「選單中未列出指標」。
您可以監控任何內建指標或使用者定義的指標。
- 如要尋找特定指標類型,請使用filter_list「篩選列」。舉例來說,如果您輸入
選用:如要監控與您在上一個步驟中選取的指標和資源類型相符的部分時間序列,請按一下「新增篩選器」。在篩選器對話方塊中,依序選取篩選依據的標籤、比較器和篩選器值。舉例來說,篩選器
zone =~ ^us.*.a$會使用規則運算式,比對所有區域名稱開頭為us且結尾為a的時間序列資料。詳情請參閱「篩選所選時間序列」。選用:如要變更時間序列中點的對齊方式,請在「Transform data」(轉換資料) 部分設定「Rolling window」(滾動週期) 和「Rolling window function」(滾動週期函式) 欄位。
如果您監控的是以記錄為準的指標,建議將「滾動視窗」選單設為至少 10 分鐘。
這些欄位會指定如何合併視窗中記錄的點。舉例來說,假設時間視窗為 15 分鐘,而視窗函式為
max。對應的資料點是最近 15 分鐘內所有資料點的最大值。詳情請參閱「對齊:序列內正規化」。您也可以使用「滾動週期函式」欄位,將「百分比變化」設為「百分比變化」,監控指標值的變化率。詳情請參閱「監控變化率」。
選用:如要減少政策監控的時間序列數量,或只想監控一組時間序列,請合併時間序列。舉例來說,您可能想計算某個區域中所有 VM 的平均 CPU 使用率,然後監控該平均值,而不是監控每個 VM 執行個體的 CPU 使用率。根據預設,系統不會合併時間序列。如需一般資訊,請參閱「縮減:合併時間序列」。
如要合併所有時間序列,請按照下列步驟操作:
- 在「Across time series」(跨時間序列) 部分中,按一下 expand_more「Expand」(展開)。
- 將「時間序列匯總」欄位設為
none以外的值。舉例來說,如要顯示時間序列的平均值,請選取mean。 - 確認「時間序列分組依據」欄位為空白。
如要依標籤值合併或分組時間序列,請按照下列步驟操作:
- 在「Across time series」(跨時間序列) 部分中,按一下 expand_more「Expand」(展開)。
- 將「時間序列匯總」欄位設為
none以外的值。 - 在「Time series group by」(時間序列分組依據) 欄位中,選取要分組的標籤。
舉例來說,如果依
zone標籤分組,然後將匯總欄位設為mean值,則圖表會針對有資料的每個區域顯示一個時間序列。特定區域顯示的時間序列是該區域所有時間序列的平均值。點選「下一步」。
設定條件觸發條件:
保留「Condition type」(條件類型) 欄位的預設值「Threshold」(門檻)。
選用步驟:更新「Alert trigger」選單,其中包含下列值:
任何時間序列違反條件時:預設設定。只要有任何時間序列在整個重新測試期間違反門檻,就會符合條件。
時間序列的百分比違反條件時:在整個重新測試期間,必須有一定百分比的時間序列違反門檻,條件才會成立。舉例來說,如果受監控的時間序列在整個重新測試期間,有 50% 違反門檻,您就會收到通知。
時間序列數量不符合條件時:必須有特定數量的時間序列在整個重新測試期間違反門檻,條件才會成立。舉例來說,如果受監控的 32 個時間序列在整個重新測試期間都違反門檻,您就會收到通知。
所有時間序列違反條件時:所有時間序列都必須在整個重新測試期間違反門檻,條件才會成立。
如要瞭解 Monitoring 用於對齊及測量時間序列資料的時間間隔,請參閱「對齊週期和重新測試時間範圍」。
使用「門檻位置」和「門檻值」欄位,輸入指標值違反門檻時的狀態。舉例來說,如果將這些值設為「高於門檻」和
0.3,則任何高於0.3的測量值都會違反門檻。選用:如要選取測量值必須違反閾值多久,監控服務才會傳送通知,請展開「進階選項」,然後使用「重新測試時間範圍」選單。
預設值為「No retest」(不重新測試)。啟用這項設定後,只要測量結果符合條件,系統就會發出通知。如需更多資訊和範例,請參閱「對齊週期和時間長度設定」。
選用步驟:如要指定 Monitoring 在資料停止傳送時評估條件的方式,請展開「Advanced options」(進階選項),然後使用「Evaluation missing data」(評估缺少資料) 選單。
如果「重新測試週期」的值為「不重新測試」,系統會停用「評估缺少資料」選單。
Google Cloud 控制台
「評估缺少資料」欄位摘要 詳細資料 缺少資料為空白 未結案的事件仍會保持開啟。
系統不會開啟新事件。如果條件已符合,即使資料停止傳送,條件仍會維持符合狀態。如果此條件的事件處於開啟狀態,事件就會保持開啟。如果事件處於開啟狀態,且沒有資料送達,自動關閉計時器會在延遲至少 15 分鐘後啟動。如果計時器到期,事件就會關閉。
如果條件未達成,資料停止傳送時,條件仍不會達成。
缺少的資料點會視為違反政策條件的值 未結案的事件仍會保持開啟。
可以開啟新事件。如果條件已符合,即使資料停止傳送,條件仍會維持符合狀態。如果此條件的事件處於開啟狀態,事件就會保持開啟。如果事件處於開啟狀態,且在自動關閉時間加上 24 小時後仍未收到任何資料,系統就會關閉事件。
如果未達到條件,這項設定會導致指標門檻值條件的行為類似於
metric-absence condition。如果資料未在重新測試時間範圍內送達,系統就會評估條件是否符合。如果快訊政策只有一個條件,只要符合該條件,就會開啟事件。缺少的資料點會視為未違反政策條件的值 未結案的事件已關閉。
系統不會開啟新事件。如果符合條件,但資料停止傳送,條件就會不再符合。如果這個條件有未結事件,系統就會關閉該事件。
如果條件未達成,資料停止傳送時,條件仍不會達成。
點選「下一步」。
選用:建立具有多項條件的快訊政策。
大多數政策都會監控單一指標類型,例如政策可能會監控寫入 VM 執行個體的位元組數。如要監控多種指標類型,請建立包含多個條件的政策。每個條件都會監控一種指標類型。建立條件後,請指定條件的合併方式。詳情請參閱「具有多項條件的政策」。
如要建立含有多個條件的快訊政策,請按照下列步驟操作:
- 如要新增條件,請按一下「新增快訊條件」,然後設定該條件。
- 按一下「下一步」,然後設定條件合併方式。
- 按一下「下一步」,即可前往設定通知和說明文件。
設定通知並新增使用者標籤:
展開「Notifications and name」(通知和名稱) 選單,然後選取通知管道。為確保備援,建議您在快訊政策中新增多種通知管道。詳情請參閱「管理通知管道」。
選用:如要在通知中使用自訂主旨行,而非預設主旨行,請更新「通知主旨行」欄位。
選用:如要在事件關閉時收到通知,請選取「Notify on incident closure」(事件關閉時通知)。根據預設,如果您是透過 Google Cloud 控制台建立警告政策,系統只會在事件產生時傳送通知。
選用:如要變更監控服務在資料停止傳送後關閉事件前等待的時間,請從「事件自動關閉期限」選單中選取所需選項。根據預設,如果資料停止傳送,Monitoring 會等待七天,然後關閉未結事件。
選用:如要將警告政策與 App Hub 應用程式建立關聯,請在「應用程式標籤」部分選取應用程式,以及服務或工作負載。事件和通知會顯示這些標籤。
選用:從「政策嚴重程度」選單中選取選項。 事件和通知會顯示嚴重性等級。
選用步驟:如要為快訊政策新增自訂標籤,請在「政策使用者標籤」部分執行下列操作:
- 按一下「新增標籤」,然後在「鍵」欄位中輸入標籤名稱。標籤名稱開頭須為小寫英文字母,且只能包含小寫英文字母、數字、底線和破折號。例如輸入
severity。 - 按一下「值」,然後輸入標籤值。標籤值可以包含小寫字母、數字、底線和破折號。例如輸入
critical。
如要瞭解如何使用政策標籤管理通知,請參閱「使用標籤註解事件」一文。
- 按一下「新增標籤」,然後在「鍵」欄位中輸入標籤名稱。標籤名稱開頭須為小寫英文字母,且只能包含小寫英文字母、數字、底線和破折號。例如輸入
選用:在「Documentation」(說明文件) 區段中,輸入要隨通知一併傳送的內容。
如要格式化說明文件,可以使用純文字、Markdown 和變數。您也可以加入連結,協助使用者偵錯事件,例如內部劇本、 Google Cloud 資訊主頁和外部網頁的連結。舉例來說,下列說明文件範本說明
gce_instance資源的 CPU 使用率事件,並包含多個變數,可參照警報政策和條件 REST 資源。然後,文件範本會將讀者導向外部頁面,協助進行偵錯。建立通知時,Monitoring 會將說明文件變數替換為相應的值。這些值只會取代通知中的變數。 Google Cloud 控制台中的預覽窗格和其他位置只會顯示 Markdown 格式。
預覽
## CPU utilization exceeded ### Summary The ${metric.display_name} of the ${resource.type} ${resource.label.instance_id} in the project ${resource.project} has exceeded 90% for over 15 minutes. ### Additional resource information Condition resource name: ${condition.name} Alerting policy resource name: ${policy.name} ### Troubleshooting and Debug References Repository with debug scripts: example.com Internal troubleshooting guide: example.com ${resource.type} dashboard: example.com通知中的格式
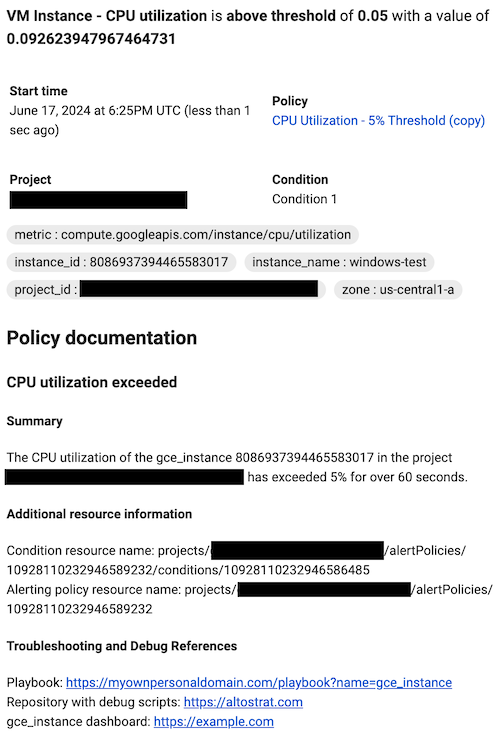
詳情請參閱「使用使用者定義的註解標註通知」和「使用管道控制項」。
按一下「快訊名稱」,然後輸入快訊政策的名稱。
按一下「建立政策」。
篩選所選時間序列
篩選器可確保系統只監控符合特定條件的時間序列。套用篩選器後,圖表上的線條可能會減少,進而提升圖表效能。您也可以套用匯總功能,減少監控的資料量。篩選器可確保只使用符合某組條件的時間序列。套用篩選條件後,可評估的時間序列會減少,進而提升快訊的效能。
篩選器由標籤、比較器和值組成。舉例來說,如要比對 zone 標籤開頭為 "us-central1" 的所有時間序列,可以使用 zone=~"us-central1.*" 篩選器,該篩選器會使用規則運算式執行比較。
依專案 ID 或資源容器篩選時,必須使用等號運算子 (=)。如要依其他標籤篩選,可以使用任何支援的比較子。通常可以篩選指標和資源標籤,以及資源群組。
如果提供多個篩選條件,系統只會監控符合「所有」條件的時間序列。
如要新增篩選器,請按一下「新增篩選條件」,完成對話方塊,然後按一下「完成」。在對話方塊中,使用「篩選」欄位選取篩選條件,然後選取比較運算子,並選取或輸入值。下拉式選單只會列出過去一週內出現的值,但您可以輸入任何值。下表中的每一列都會列出比較運算子、其意義和範例:
| 運算子 | 意義 | 範例 |
|---|---|---|
= |
平等 | resource.labels.zone = "us-central1-a" |
!= |
不平等 | resource.labels.zone != "us-central1-a" |
=~ |
規則運算式 2 相等 | monitoring.regex.full_match("^us.*") |
!=~ |
規則運算式 2 不等式 | monitoring.regex.full_match("^us.*") |
starts_with |
值開頭為 | resource.labels.zone = starts_with("us") |
ends_with |
值結尾為 | resource.labels.zone = ends_with("b") |
has_substring |
值中含有特定值 | resource.labels.zone = has_substring("east") |
one_of |
下列其中一項權限: | resource.labels.zone = one_of("asia-east1-b", "europe-north1-a") |
!starts_with |
值開頭不是 | resource.labels.zone != starts_with("us") |
!ends_with |
值結尾不是 | resource.labels.zone != ends_with("b") |
!has_substring |
值不包含 | resource.labels.zone != has_substring("east") |
!one_of |
值不是下列其中一個 | resource.labels.zone != one_of("asia-east1-b", "europe-north1-a") |
疑難排解
本節提供疑難排解提示。
指標未列在可用指標選單中
如要監控「選取指標」選單中未列出的指標,請採取下列任一做法:
如要建立監控 Google Cloud 指標的快訊政策,請展開「選取指標」選單,然後按一下「啟用」。 如果停用,選單會列出Google Cloud 服務的所有指標,以及所有含有資料的指標。
如要在自訂指標類型產生資料前設定條件,請使用 Monitoring 篩選器指定指標類型:
- 選取「?」「選取指標」部分標題,然後在工具提示中選取「直接篩選器模式」。
輸入監控篩選條件或時間序列選取器。 如需語法相關資訊,請參閱下列文件:
監控變化率
如要監控指標值的變化率,請將「滾動週期函式」欄位設為「百分比變化」。評估條件時,Monitoring 會計算指標的變更率 (以百分比表示),然後將該百分比與條件的門檻進行比較。這項比較程序包含兩個步驟:
- 如果時間序列具有
DELTA或CUMULATIVE指標類型,則時間序列會轉換為具有GAUGE指標類型。如要瞭解轉換,請參閱「種類、類型和轉換」。 - 監控功能會比較最近 10 分鐘滑動視窗的平均值,與對齊期開始前 10 分鐘滑動視窗的平均值,計算出變更百分比。
您無法變更變動率快訊政策中用於比較的 10 分鐘滑動視窗。不過,您可以在建立條件時指定對齊週期。
後續步驟
- 如要建立政策,比較時間序列的值與動態門檻,請務必使用 MQL。詳情請參閱「使用 MQL 建立動態嚴重程度層級」。
本頁的指示適用於任何警告政策。下列文件提供特定設定的指引: