このドキュメントでは、今後の予測期間内にしきい値をまたぐことが予測される場合に、通知を送信するアラート ポリシーを Google Cloud コンソールを使用して作成する方法について説明します。予測は、将来の時間帯である予測ウィンドウ内で時系列がしきい値をまたぐかどうかを予測するものです。予測ウィンドウは、1 時間(3,600 秒)から 2.5 日間(216,000 秒)の間で設定できます。
このコンテンツは、ログベースのアラート ポリシーには適用されません。ログに特定のメッセージが表示されたときに通知する、ログベースのアラート ポリシーの詳細については、ログのモニタリングをご覧ください。
このドキュメントでは、以下については説明しません。
- 指標の値がしきい値を上回るかまたは下回ったときに通知する方法。詳細については、指標しきい値のアラート ポリシーを作成するをご覧ください。
- データの受信が停止したときに通知する方法。詳細については、指標不在のアラート ポリシーを作成するをご覧ください。
Cloud Monitoring API を使用してアラート ポリシーを作成する方法。詳細については、API を使用してアラート ポリシーを作成するをご覧ください。
条件に Monitoring Query Language(MQL)クエリが含まれるアラート ポリシーを作成する方法。こうしたポリシーでは、静的しきい値か動的しきい値を使用できます。詳細については、次のドキュメントをご覧ください。
予測条件について
ほとんどの指標のモニタリングでは、予測を使用できます。しかし、割り当て、ディスク容量、メモリ使用量など、制約があるリソースをモニタリングする場合は、予測条件により、しきい値をまたぐ前に通知されることがあります。この機能により、しきい値をまたぐ前に、制約があるリソースの使われ方に対応する時間を確保できます。
予測条件でモニタリングする各時系列について、条件により決定アルゴリズムがインスタンス化されます。そのアルゴリズムがトレーニングされた後は、条件を評価するたびに予測が生成されます。各予測は、時系列が予測ウィンドウ内でしきい値をまたぐか、またがないかというものです。モニタリング対象の時系列に規則的な周期性がある場合、その時系列の決定アルゴリズムは、その周期的な挙動を予測に織り込みます。
予測条件は、次のいずれか、または両方が発生したときに満たされます。
- 特定の再テスト ウィンドウの時系列のすべての値がしきい値をまたぐ。
- ある再テスト ウィンドウ内で行われた特定の時系列に対するすべての予測が、その時系列は予測ウィンドウ内でしきい値をまたぐと予測する。
決定アルゴリズムの初期トレーニング時間は、予測ウィンドウの長さの 2 倍です。たとえば、予測ウィンドウが 1 時間の場合は、2 時間のトレーニング時間が必要です。各時系列の決定アルゴリズムは個別にトレーニングされます。決定アルゴリズムのトレーニング中は、再テスト ウィンドウの値が指定された期間ウィンドウのしきい値をまたいだ場合にのみ条件を満たします。
最初のトレーニングが完了すると、各決定アルゴリズムは、予測ウィンドウの長さの 6 倍までのデータを使用して継続的にトレーニングされます。たとえば、予測ウィンドウが 1 時間の場合、継続的なトレーニングでは直近 6 時間のデータが使用されます。
予測条件を構成した後、10 分以上データが到着しなくなると、予測は無効になり、その条件は指標しきい値条件として動作します。
インシデントは、時系列が予測ウィンドウ内で条件のしきい値をまたぐと予測されたときに作成されます。Monitoring によって、時系列が予測ウィンドウ内でしきい値をまたがないと予測されたときに、インシデントが自動的にクローズされます。
始める前に
-
Google Cloud コンソールを使用してアラート ポリシーを作成および変更するために必要な権限を取得するには、プロジェクトに対する Monitoring 編集者(
roles/monitoring.editor)の IAM ロールの付与を管理者に依頼してください。 ロールの付与の詳細については、アクセス権の管理をご覧ください。必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
Cloud Monitoring のロールの詳細については、Identity and Access Management を使用してアクセスを制御するをご覧ください。
アラート ポリシーの一般的なコンセプトに精通していることを確認してください。 このトピックについては、アラートの概要をご覧ください。
アラートの受信に使用する通知チャンネルを構成します。冗長性を確保するために、複数のタイプの通知チャンネルを作成することをおすすめします。詳細については、通知チャンネルを作成して管理するをご覧ください。
アラート ポリシーを作成する
予測に基づいて通知を送信するアラート ポリシーを作成するには、次の操作を行います。
-
Google Cloud コンソールで、notifications [アラート] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Monitoring] である結果を選択します。
- [ポリシーを作成] を選択します。
モニタリング対象の時系列を選択します。
[指標の選択] をクリックし、メニューの操作でリソースタイプと指標タイプを選択して、[適用] をクリックします。
[指標を選択] メニューには、使用可能な指標タイプを見つける際に役立つ機能が用意されています。
- 特定の指標タイプを見つけるには、filter_list [フィルタバー] を使用します。たとえば、「
util」と入力すると、utilを含むエントリを表示するようにメニューが制限されます。エントリは、大文字と小文字を「区別しない」テストに合格した場合に表示されます。
- データが存在しないものも含めて、すべての指標タイプを表示するには、[ アクティブ] をクリックします。デフォルトでは、メニューにはデータがある指標タイプのみが表示されます。詳細については、メニューに指標が表示されないをご覧ください。
値の型が double や int64 で、制約指標であり Amazon VM インスタンスの指標ではない、組み込み指標、またはユーザー定義の指標をモニタリングできます。
64 を超える時系列がモニタリング対象になる指標タイプを選択した場合、Monitoring では、値がしきい値に最も近いかすでにしきい値をまたいでいる 64 の時系列について予測を行います。他の時系列については、その値がしきい値と比較されます。
- 特定の指標タイプを見つけるには、filter_list [フィルタバー] を使用します。たとえば、「
省略可: 前の手順で選択した指標タイプとリソースタイプに一致する時系列のサブセットをモニタリングするには、[フィルタを追加] をクリックします。フィルタ ダイアログで、フィルタに使用するラベル、比較対象、フィルタ値を選択します。たとえば、フィルタ
zone =~ ^us.*.a$はゾーン名がusで始まりaで終わるすべての時系列データに一致する正規表現を使用します。詳細については、選択した時系列をフィルタするをご覧ください。省略可: 時系列のポイントの配置方法を変更するには、データの変換セクションで、ローリング ウィンドウおよび ローリング ウィンドウ関数を設定します。
ログベースの指標をモニタリングする場合は、[ローリング ウィンドウ] メニューを 10 分以上に設定することをおすすめします。
これらのフィールドは、ウィンドウに記録されるポイントの組み合わせ方を指定します。たとえば、ウィンドウが 15 分で、ウィンドウ関数が
maxであるとします。整列されたポイントは、直近の 15 分間にあるすべてのポイントの最大値となります。詳細については、アライメント: 系列内の正則化をご覧ください。[ローリング ウィンドウ関数] フィールドを [percent change] にすることで、指標値の変化率をモニタリングすることもできます。詳細については、変化率のモニタリングをご覧ください。
省略可: ポリシーによってモニタリング対象の時系列の数を減らす場合や、時系列のコレクションのみをモニタリングする場合は、時系列を結合します。たとえば、各 VM インスタンスの CPU 使用率をモニタリングする代わりに、ゾーン内のすべての VM の CPU 使用率の平均を計算し、その平均値をモニタリングすることもできます。デフォルトでは、時系列は結合されません。一般的なことについては、縮小: 時系列の結合をご覧ください。
すべての時系列を結合するには、次の操作を行います。
- [時系列間] セクションで、expand_more [開く] をクリックします。
- [時系列集計] フィールドを
none以外の値に設定します。たとえば、時系列の平均値を表示するには、meanを選択します。 - [時系列のグループ化の基準] フィールドが空であることを確認します。
ラベル値で時系列を結合またはグループ化するには、次の操作を行います。
- [時系列間] セクションで、expand_more [開く] をクリックします。
- [時系列集計] フィールドを
none以外の値に設定します。 - [時系列のグループ化の基準] フィールドで、グループ化するラベルを選択します。
たとえば、
zoneラベルでグループ化し、集計フィールドをmeanに設定すると、グラフには、データが存在するゾーンごとに 1 つの時系列が表示されます。特定のゾーンに表示される時系列は、そのゾーンを含むすべての時系列の平均です。[次へ] をクリックします。
条件のトリガーを構成します。
条件の種類は [予測] を選択します。
省略可: [Alert trigger] メニューを更新します。次の値が表示されます。
任意の時系列の違反: デフォルト設定。しきい値に違反する時系列、または再テスト ウィンドウ全体でしきい値に違反すると予測される時系列は、条件が満たされます。
時系列の違反の割合: 時系列の割合は、しきい値に違反するか、条件が満たされる前に再テスト ウィンドウ全体でしきい値に違反すると予測される必要があります。たとえば、モニタリング対象の時系列の 50% が再テスト ウィンドウ全体でしきい値に違反した場合に通知を受け取ることができます。
時系列の違反の数: 特定の数の時系列がしきい値に違反するか、条件が満たされる前に再テスト ウィンドウ全体のしきい値に違反することが予測されている必要があります。たとえば、モニタリング対象の時系列の 32% が再テスト ウィンドウ全体でしきい値に違反した場合に通知を受け取ることができます。
全時系列の違反: 全時系列は、しきい値に違反するか、条件が満たされる前に再テスト ウィンドウ全体でしきい値に違反すると予測される必要があります。
Monitoring が時系列データの調整と測定に使用する間隔については、アライメント期間と再テスト ウィンドウをご覧ください。
[予測期間] の値を選択します。選択した値は、予測のための未来の時間です。この値は、1 時間(3,600 秒)から 2.5 日間(216,000 秒)に設定する必要があります。
[しきい値の位置] と [しきい値] フィールドを使用して、選択した指標の予測値がしきい値をまたぐタイミングを入力します。たとえば、これらの値を [しきい値より上] と [
10] に設定すると、10より高い測定値はしきい値に違反します。省略可: [詳細オプション] を開き、[再テスト ウィンドウ] の値を設定します。このフィールドのデフォルト値は「再テストなし」です。
この項目は、10 分以上に設定することをおすすめします。
たとえば、任意の時系列が条件を満たすように予測条件を構成するとします。また、[再テスト ウィンドウ] を 15 分、[予測ウィンドウ] を 1 時間に設定し、しきい値をまたぐのは時系列の値が [Threshold](10 に設定)よりも高くなる場合と仮定します。次のいずれかが発生した場合、条件は満たされます。
- 時系列のすべての値が 10 を超え、15 分間以上継続する。
- 15 分間隔で、ある時系列のすべての予測が、今後 1 時間以内にしきい値 10 を超えると予測する。
省略可: データの受信が停止したときに Monitoring が条件を評価する方法を指定するには、[詳細オプション] を開いて [Evaluation missing data] メニューを使用します。
[再テスト ウィンドウ] の値が [再テストなし] の場合は、[評価の欠落データ] メニューが無効になります。
データが 10 分以上欠落している場合は、予測条件による予測が停止され、代わりに [評価の欠落データ] フィールドの値を使用してインシデントの管理方法が決まります。モニタリングが再開されると、予測が再開されます。
Google Cloud コンソール
[欠落データの評価] フィールド概要 詳細 欠落データがない 対応待ちのインシデントはオープンのままです。
新しいインシデントはオープンされません。条件が満たされている場合、データが到着しなくなっても、条件は引き続き満たされます。この条件でインシデントが対応待ちの場合、インシデントはオープンのままになります。インシデントが対応待ちで、データが送られてこない場合、自動クローズ タイマーは 15 分以上の時間をおいて開始されます。タイマーの期限が切れると、インシデントはクローズされます。
条件が満たされていない場合、データが到着しなくなっても、条件は引き続き満たされません。
欠落データポイントが、ポリシーに違反する値として扱われる 対応待ちのインシデントはオープンのままです。
新しいインシデントをオープンできます。条件が満たされている場合、データが到着しなくなっても、条件は引き続き満たされます。この条件でインシデントが対応待ちの場合、インシデントはオープンのままになります。インシデントが対応待ちで、自動クローズ期間に 24 時間を加えた期間にデータが到着しない場合、インシデントはクローズされます。
条件が満たされない場合は、この設定により、指標しきい値の条件が
metric-absence conditionのように動作します。再テストの時間枠で指定された時間内にデータを受信しない場合は、条件が満たされたと評価されます。条件が 1 つのアラート ポリシーでは、条件が満たされるとインシデントが開始されます。欠落データポイントが、ポリシーに違反しない値として扱われる 対応待ちのインシデントはクローズされます。
新しいインシデントはオープンされません。条件が満たされている場合、データの受信が停止すると、その条件は満たされなくなります。この条件のインシデントが対応待ちの場合、インシデントはクローズされます。
条件が満たされていない場合、データが到着しなくなっても、条件は引き続き満たされません。
[次へ] をクリックします。
省略可: 複数の条件を持つアラート ポリシーを作成します。
ほとんどのポリシーは、1 つの指標タイプをモニタリングします。たとえば、ポリシーで VM インスタンスに書き込まれたバイト数をモニタリングする場合があります。複数の指標タイプをモニタリングする場合は、複数の条件を含むポリシーを作成します。各条件で 1 つの指標タイプがモニタリングされます。条件を作成したら、条件の組み合わせ方法を指定します。詳細については、複数の条件を持つポリシーをご覧ください。
複数の条件を持つアラート ポリシーを作成するには、次の操作を行います。
- 追加する条件ごとに、[条件を追加] をクリックして条件を構成します。
- [次へ] をクリックして、条件の組み合わせ方を構成します。
- [次へ] をクリックして通知とドキュメントの設定に進みます。
通知を構成します。
[通知と名前] メニューを開いて通知チャネルを選択します。冗長性を確保するために、複数のタイプの通知チャンネルをアラート ポリシーに追加することをおすすめします。詳細については、通知チャンネルを管理するをご覧ください。
インシデントがクローズされたときに通知を受け取るには、[Notify on incident closure] を選択します。 デフォルトでは、Google Cloud コンソールでアラート ポリシーを作成すると、インシデントが作成されたときにのみ通知が送信されます。
省略可: データの受信が停止してからインシデントがクローズされるまでの Monitoring の待機時間を変更するには、[インシデントの自動クローズ期間] メニューからオプションを選択します。 デフォルトでは、データの受信が停止すると、Monitoring は対応待ちのインシデントがクローズされるまで 7 日間待機します。
[Policy severity level] メニューからオプションを選択します。インシデントと通知には重大度が表示されます。
省略可: アラート ポリシーにカスタムラベルを追加するには、[Policy user labels] セクションで、次の操作を行います。
- [ラベルを追加] をクリックして、[キー] フィールドにラベルの名前を入力します。ラベル名の先頭は小文字にする必要があり、小文字、数字、アンダースコア、ダッシュを使用できます。たとえば、「
severity」と入力します。 - [Value] をクリックし、ラベルの値を入力します。ラベルの値には、英小文字、数字、アンダースコア、ダッシュを使用できます。たとえば、「
critical」と入力します。
ポリシーラベルを使用して通知を管理する方法については、インシデントにラベルでアノテーションを付けるをご覧ください。
- [ラベルを追加] をクリックして、[キー] フィールドにラベルの名前を入力します。ラベル名の先頭は小文字にする必要があり、小文字、数字、アンダースコア、ダッシュを使用できます。たとえば、「
省略可: [ドキュメント] セクションで、通知に含めるコンテンツを入力します。
ドキュメントのフォーマットには、書式なしテキスト、Markdown、変数を使用できます。内部ハンドブック、Google Cloud ダッシュボード、外部ページへのリンクなど、ユーザーがインシデントをデバッグするためのリンクを含めることもできます。たとえば、次のドキュメント テンプレートは、
gce_instanceリソースの CPU 使用率インシデントを表し、アラート ポリシーと条件 REST リソースを参照するためのいくつかの変数が含まれています。ドキュメント テンプレートは、デバッグに役立つ外部ページにユーザーを誘導します。通知が作成されると、Monitoring によってドキュメント変数が通知の値に置き換えられます。この値は通知でのみ変数に置き換えられます。Google Cloud コンソールのプレビュー ペインやその他の場所では、Markdown の書式設定のみが表示されます。
プレビュー
## CPU utilization exceeded ### Summary The ${metric.display_name} of the ${resource.type} ${resource.label.instance_id} in the project ${resource.project} has exceeded 90% for over 15 minutes. ### Additional resource information Condition resource name: ${condition.name} Alerting policy resource name: ${policy.name} ### Troubleshooting and Debug References Repository with debug scripts: example.com Internal troubleshooting guide: example.com ${resource.type} dashboard: example.com通知の形式
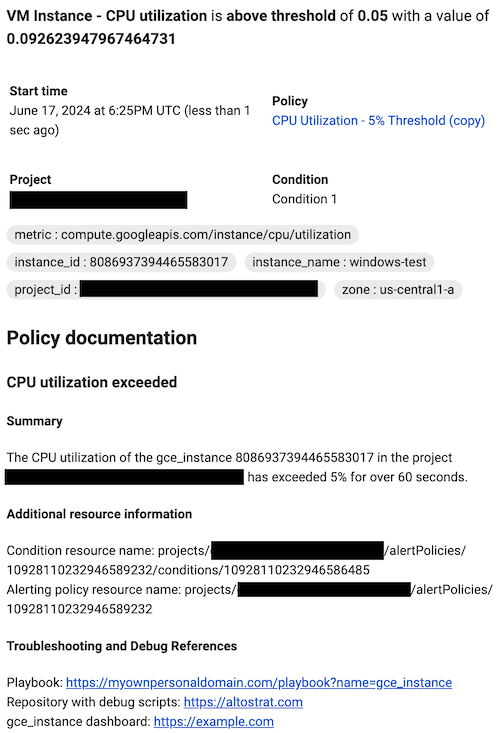
詳細については、ユーザー定義のドキュメントで通知にアノテーションを付けるとチャネル コントロールの使用をご覧ください。
[アラート名] をクリックして、アラート ポリシーの名前を入力します。
[ポリシーを作成] をクリックします。
選択した時系列をフィルタする
フィルタにより、一定の条件を満たす時系列のみがモニタリングされるようになります。フィルタを適用すると、グラフ上の線の数が減り、グラフのパフォーマンスが向上します。また、集計を適用して、モニタリング対象のデータの量を減らすこともできます。フィルタにより、一定の条件を満たす時系列のみが使用されるようになります。フィルタを適用すると、評価する時系列が少なくなり、アラートのパフォーマンスが向上します。
フィルタは、ラベル、比較、値で構成されます。たとえば、zone ラベルが "us-central1" で始まるすべての時系列を照合するには、正規表現を使用して比較を行うフィルタ zone=~"us-central1.*" を使用できます。
プロジェクト ID またはリソース コンテナでフィルタする場合は、等価演算子 (=) を使用する必要があります。他のラベルでフィルタする場合は、サポートされている任意のコンパレータを使用できます。
通常、指標とリソースラベル、およびリソース グループでフィルタリングできます。
複数のフィルタ条件を指定すると、全条件を満たす時系列のみがモニタリングされます。
フィルタを追加するには、[フィルタを追加] をクリックし、ダイアログの項目を入力して、[完了] をクリックします。ダイアログで [フィルタ] フィールドを使用し、フィルタリング条件を選択し、比較演算子を選択して、値を選択します。次の表の各行には、比較演算子とその意味、例が示されています。
| 演算子 | 意味 | 例 |
|---|---|---|
= |
平等 | resource.labels.zone = "us-central1-a" |
!= |
不等 | resource.labels.zone != "us-central1-a" |
=~ |
正規表現 2 等式 | monitoring.regex.full_match("^us.*") |
!=~ |
正規表現 2 に一致しない | monitoring.regex.full_match("^us.*") |
starts_with |
値の先頭に次の項目が配置されている | resource.labels.zone = starts_with("us") |
ends_with |
値の末尾に次の項目が配置されている | resource.labels.zone = ends_with("b") |
has_substring |
値が次の項目を含む | resource.labels.zone = has_substring("east") |
one_of |
次のいずれか | resource.labels.zone = one_of("asia-east1-b", "europe-north1-a") |
!starts_with |
値の先頭に次の項目が配置されていない | resource.labels.zone != starts_with("us") |
!ends_with |
値が次の項目で終わらない | resource.labels.zone != ends_with("b") |
!has_substring |
値が次の項目を含まない | resource.labels.zone != has_substring("east") |
!one_of |
値が次の項目のいずれにも一致しない | resource.labels.zone != one_of("asia-east1-b", "europe-north1-a") |
トラブルシューティング
このセクションでは、トラブルシューティングのヒントを示します。
利用可能な指標のメニューに指標が表示されない
[指標を選択] メニューに表示されていない指標をモニタリングするには、次のいずれかを行います。
Google Cloud 指標をモニタリングするアラート ポリシーを作成するには、[指標を選択] メニューを開いて、[ アクティブ] をクリックします。無効にすると、Google Cloud サービスのすべての指標とデータのあるすべての指標がメニューに表示されます。
カスタム指標タイプの条件を、カスタム指標タイプによってデータが生成される前に構成するには、Monitoring フィルタを使用して指標タイプを指定する必要があります。
- [?] を選択して[指標の選択] ヘッダーをクリックして、ツールチップの [ダイレクト フィルタモード] を選択します。
モニタリング フィルタまたは時系列セレクタを入力します。構文の詳細については、次のドキュメントをご覧ください。
変化率のモニタリング
指標値の変化率をモニタリングするには、[ローリング ウィンドウ関数] フィールドを [変化率] に設定します。条件が評価されると、モニタリングでは指標の変化率をパーセンテージとして計算し、そのパーセンテージを条件のしきい値と比較します。この比較プロセスは、次の 2 つのステップで行います。
- 時系列に
DELTAまたはCUMULATIVEの指標の種類がある場合、その時系列はGAUGEの指標の種類を持つ時系列に変換されます。変換の詳細については、種類、タイプ、コンバージョンをご覧ください。 - モニタリングでは、直近 10 分間のスライディング ウィンドウの平均値を、アライメント期間の開始前の 10 分間のスライディング ウィンドウの平均値と比較することで変化率を計算します。
変化率アラート ポリシーで比較に使用される 10 分間のスライディング ウィンドウは変更できません。ただし、条件を作成するときにアライメント期間を指定できます。
制限事項
- 条件は、Google Cloud コンソールのメニュー形式のインターフェースか Monitoring フィルタを使用して構成できます。Monitoring Query Language や PromQL を使用して条件を構成することはできません。
- double 型または int64 型の値の型を持つすべての指標がサポートされていますが、Amazon VM インスタンスからの指標はサポートされていません。
次のステップ
- 時系列の値と動的しきい値を比較するポリシーを作成するには、MQL を使用する必要があります。詳細については、MQL を使用して動的な重大度を作成するをご覧ください。