この記事では、統合の仕組みを理解し、複雑なユースケースを解決するうえで役立つ、データ統合に関するアドバイスと詳細情報を提供します。この記事を最大限に活用するには、このトピックの他の記事で説明されているデータブレンドの基本を理解しておく必要があります。
使用可能なデータのサブセットのみを統合に含める必要がある
ベスト プラクティスとして、統合に基づくグラフで可視化する特定のフィールドのみを含めることをおすすめします。この点が重要な理由は次のとおりです。
- 統合を行うと、非常に大きなデータセットが作成され、BigQuery などの有料サービスでのパフォーマンス低下やクエリ費用の増加につながることがあります。
- 統合に基づくグラフでは、グラフ内で未使用であっても、統合内のすべての行が計算されます。
- たとえば、10 個のフィールドを含む統合を作成し、そのうち 1 個のフィールドのみを使用するグラフを定義するとします。Looker Studio は 10 個のフィールドを含む統合を計算し、統合の出力内にあるその 1 個のフィールドをクエリしてグラフを作成します。
- 再集計は、基になるデータのサブセットが統合に含まれている場合にのみ行われます。
統合を使用して指標を再集計する
基になるデータソースから含めた指標の数値は、統合では集計されません。基になるデータソースのフィールド セットの一部が統合に含まれていない場合、これらの数値は新しいデータに基づいて再集計されます。この方法で統合を使用すると、平均の平均の計算など、すでに集計されているフィールドに別の集計を適用する必要がある場合に役立ちます。
詳しくは、統合を使用してデータを再集計するをご覧ください。
単一のデータソースからブレンドを作成する
ブレンドでは、異なるデータソースを使用する必要はありません。同じデータソースの複数のテーブルを統合してデータを再集計することもできます。
たとえば、次の表に示すように、人口の多い米国の州の上位 3 つの郡の人口データを含むデータセットがあるとします。
| 状態 |
郡 |
人口(2023 年の推定値) |
|---|---|---|
| カリフォルニア |
ロサンゼルス郡 |
10,014,009 |
| カリフォルニア |
サンディエゴ郡 |
3,298,634 |
| カリフォルニア |
オレンジ カウンティ |
3,186,989 |
| テキサス |
ハリス郡 |
4,731,145 |
| テキサス |
ダラス郡 |
2,613,539 |
| テキサス |
タラント郡 |
2,110,640 |
| ニューヨーク |
キングス郡(ブルックリン) |
2,736,074 |
| ニューヨーク |
クイーンズ郡 |
2,405,464 |
| ニューヨーク |
ブロンクス郡 |
1,418,890 |
州内の各郡の人口の割合を計算したいのですが、そのためには、各州の総人口を独自のフィールドとして用意する必要があります。データセットでは、この指標は使用できませんが、人口データソースをそれ自体とブレンドすることで取得できます。手順は次のとおりです。
- ベース データセットを使用してデータソースを作成します。
- そのデータソースを使用するグラフをレポートに追加します。
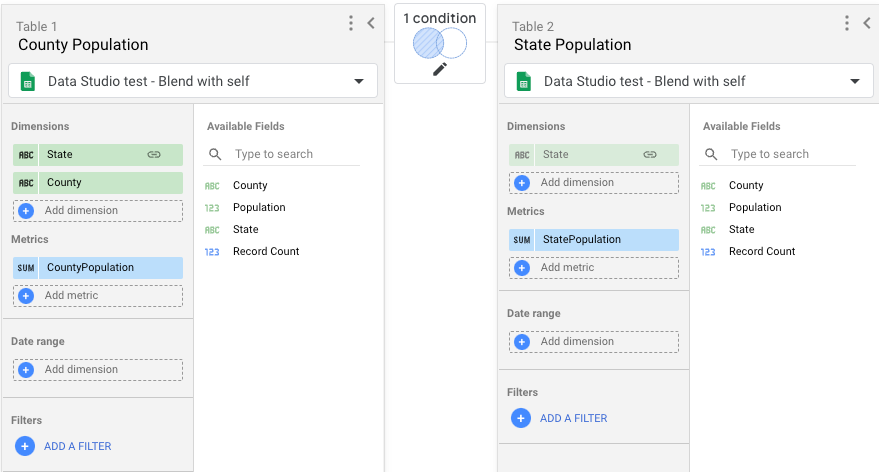
- 2 つのテーブルをブレンドします。各テーブルは、ステップ 1 で作成した同じデータソースを使用します。
- 表 1 には次のフィールドを含めます。
- 都道府県、郡、人口。
- Population の名前を CountyPopulation に変更します。
- テーブル 2 には [Population] フィールドのみを含め、そのフィールドの名前を [StatePopulation] に変更します。
- 表 1 には次のフィールドを含めます。
- 結合条件には、テーブル 1 の State をテーブル 2 の State にリンクする左外部結合を使用します。
- [保存] をクリックします。
- [X] をクリックして、レポート エディタに戻ります。
次に、レポートに新しいグラフ(表など)を追加し、次の手順でグラフのデータソースとしてブレンドを選択します。
- [State]、[County]、[CountyPopulation]、[StatePopulation] の各フィールドをグラフに追加します。
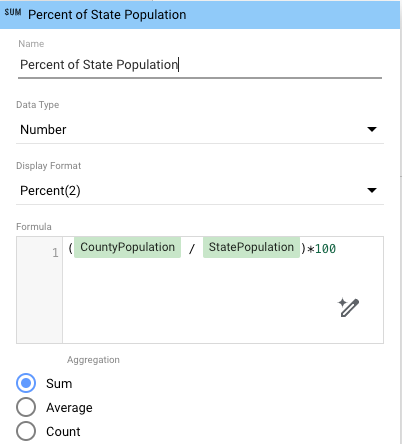
- 各郡の州人口の割合を計算するには、新しい再集計データを使用する計算フィールドをグラフに追加します。
- プロパティ パネルで、[指標を追加]、[フィールドを追加] の順にクリックします。
- フィールドに名前(例: Percent of State Population)を付けます。
- [計算式] ボックスに「
(CountyPopulation / StatePopulation)*100」と入力します。 - (省略可)[表示形式] を設定して、割合の値を特定のレベルまで表示します(たとえば、小数点以下 2 桁の場合は [割合(2)])。
完了すると、テーブルは次のようになります。
| 状態 |
郡 |
CountyPopulation |
StatePopulation |
州の人口に占める割合 |
|---|---|---|---|---|
| カリフォルニア |
ロサンゼルス郡 |
10014009 |
16499632 |
60.69 |
| テキサス |
ハリス郡 |
4731145 |
9455324 |
50.04 |
| カリフォルニア |
サンディエゴ郡 |
3298634 |
16499632 |
19.99 |
| カリフォルニア |
オレンジ カウンティ |
3186989 |
16499632 |
19.32 |
| ニューヨーク |
キングス郡(ブルックリン) |
2736074 |
6560428 |
41.71 |
| テキサス |
ダラス郡 |
2613539 |
9455324 |
27.64 |
| ニューヨーク |
クイーンズ郡 |
2405464 |
6560428 |
36.67 |
| テキサス |
タラント郡 |
2110640 |
9455324 |
22.32 |
| ニューヨーク |
ブロンクス郡 |
1418890 |
6560428 |
21.63 |
統合内のテーブルの順序
Looker Studio では、統合内の結合設定が左端から順に評価されます。それから、右側にある次の結合に各結合の結果が適用されます。たとえば、3 つのテーブルの統合の場合、テーブル 1(左端)とテーブル 2(中央)間の結合設定が評価され、次に、その結果がテーブル 2 とテーブル 3(右端)間の結合設定で使用されます。
自動作成された統合のテーブルの順序
選択したグラフを統合すると、Looker Studio によってグラフごとにテーブルが作成され、対応するテーブルにグラフ内のフィールドが追加されます。統合内のテーブルの順序は、グラフを選択する順序と一致します。つまり、最初に選択したグラフが最初(左端)のテーブルになり、2 番目に選択したグラフが 2 番目のテーブルになるということです。
また、Looker Studio では各テーブルの結合設定が自動的に作成され、左外部結合タイプが使用されます。
デフォルト設定が意図したとおりになっていない場合や、テーブル間に明確な関連付けがない場合は、目標に合わせて統合を編集できます。
テーブルは統合の前に作成される
統合内の各テーブルのデータは、そのデータが最終統合に結合される前にクエリされます。結合が実行される前に、テーブルを生成するクエリに対してテーブルの期間、フィルタ、計算フィールドが適用されます。これらの要因により、統合テーブルに含まれるデータが影響を受け、統合の出力が変更される場合があります。
統合すると元のデータよりも多くの行が含まれる場合がある
統合グラフには、統合を構成する個々のデータソースに基づくグラフよりも多くのデータが表示されることがあります。結果は、データと、統合に選択した結合設定によって異なります。たとえば、左外部結合には、左側のテーブルにあるすべてのレコードと、結合条件で同じ値を共有する右側のテーブルのレコードすべてが含まれています。結合条件に一致が複数ある場合、統合データには一番左のデータソースにあるよりも多くの行が表示される可能性があります。
統合と明示的な期間およびフィルタ
統合内の行数を制限するには、期間の使用またはフィルタの適用という 2 つの方法があります。行の制限は、統合に基づくグラフ、または統合を構成するテーブルで行うことができます。このプロセスは、「統合前」と「統合後」のどちらであるかを考えると参考になります。
期間またはフィルタを統合内のテーブルに適用した場合は、統合内の他のテーブルと統合する前に反映されます。期間外の行や、フィルタによって除外された行には、結合クエリを適用できません。
統合に基づくグラフに期間やフィルタを適用する場合は、統合が作成された後(「統合後」)にデータに適用されます。
この違いは、データと統合の設定によっては、グラフに表示される結果に大きく影響する場合があります。
統合と継承フィルタ
統合では、統合前または統合後のデータとフィルタとの互換性がある限り、レポート、ページ、またはグループ単位のフィルタが継承されます。統合で使用される基となるデータソースとの互換性がある場合、そのフィルタは統合前のデータに適用されます。それ以外の場合、フィルタは統合後のデータに適用されます。統合前または統合後のデータとの互換性がない場合には、そのフィルタは無視されます。
詳しくは、フィルタの継承をご覧ください。
統合に基づくグラフが継承フィルタの適用対象である場合、Looker Studio では、データが 5 段階のステップで処理されます。
(事前ブレンド):
- ステップ 1: データが [データの統合] パネルで指定されたディメンションに基づいてグループ化され、集計されます。
- ステップ 2: 継承されたディメンション フィルタおよび互換性のある指標フィルタが、[データの統合] パネルに含まれるデータソースに適用されます。
(ブレンド):
- ステップ 3: データが指定された結合設定を使って統合されます。
(ブレンド後):
- ステップ 4: データがグラフのディメンションに基づいてグループ化され、集計されます。
- ステップ 5: 統合データと互換性のある指標フィルタが、グラフに適用されます。